一、论文
- 研究领域:全监督3D语义分割(室内,室外RGB,kitti)
- 论文:RandLA-Net: Efficient Semantic Segmentation of Large-Scale Point Clouds
-
CVPR 2020
-
牛津大学、中山大学、国防科技大学
- 论文链接
- 论文github
二、论文概要
2.1 主要思路
现有的语义分割网络几乎所有都限于极小的3D点云(例如,4k个点或1×1米块),并且不能直接扩展到更大的点云;即使最近有工作已经开始解决直接处理大规模点云的任务,他们的预处理和体素化步骤的计算量太大,部署在实时应用程序。
RandLA-Net中,我们的目标是设计一个内存和计算效率高的神经架构,它能够直接处理大规模的3D点云,而不需要任何预/后处理步骤,如体素化,块分区或图形构建。
我们的方法的关键是使用随机点采样。虽然计算和存储效率非常高,但随机采样可能会偶然丢弃关键特征。为了克服这一点,我们引入了一种新的局部特征聚合模块,以逐步增加每个3D点的感受野,从而有效地保留几何细节。
2.1.1 实现步骤
随机点采样:
新的局部特征聚合模块:
2.2 主要贡献
RandLA-Net在三个方面有所区别:
1)它仅依赖于网络内的随机采样,从而需要少得多的存储器和计算;
2)所提出的局部特征聚合器通过显式地考虑局部空间关系和点特征,可以获得连续更大的感受野,从而对学习复杂的局部模式更加有效和鲁棒;
3)整个网络仅由共享的MLP组成,而不依赖于任何昂贵的操作,例如图构建和核化,因此对于大规模点云非常有效。
2.3 实验表现
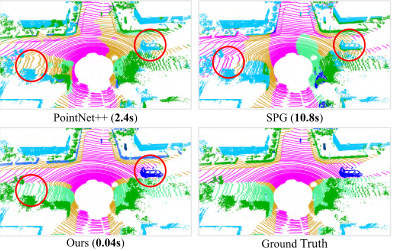
PointNet++ [44],SPG [26]和我们在SemanticKITTI [3]上的方法的语义分割结果。我们的RandLA-Net仅需0.04s即可直接处理3D空间中超过150×130×10米的105个点的大型点云,比SPG快200倍。红色圆圈突出了我们的方法的上级分割精度。
三、论文全文
RandLA-Net:大规模点云的高效语义分割
- 摘要
研究了大规模三维点云数据的高效语义分割问题。由于依赖于昂贵的采样技术或计算量大的预/后处理步骤,大多数现有方法只能在小规模点云上进行训练和操作。在本文中,我们介绍了RandLA-Net,这是一种高效且轻量级的神经架构,可以直接推断大规模点云的逐点语义。我们的方法的关键是使用随机点采样,而不是更复杂的点选择方法。虽然计算和存储效率非常高,但随机采样可能会偶然丢弃关键特征。为了克服这一点,我们引入了一种新的局部特征聚合模块,以逐步增加每个3D点的接收场,从而有效地保留几何细节。大量的实验表明,我们的RandLA-Net可以在单次通过中处理100万个点,比现有方法快200倍。此外,我们的RandLA-Net在两个大型基准Semantic 3D和SemanticKITTI上明显超过了最先进的语义分割方法。
- Introduction
大规模三维点云的有效语义分割是实时智能系统(如自动驾驶和增强现实)的基本和必要能力。一个关键的挑战是深度传感器获取的原始点云通常是不规则采样的、非结构化的和无序的。尽管深度卷积网络在结构化2D计算机视觉任务中表现出出色的性能,但它们不能直接应用于这种类型的非结构化数据[下图参考]。

最近,开创性的工作PointNet [43]已经成为直接处理3D点云的有前途的方法。它使用共享多层感知器(MLP)学习每点特征。这在计算上是高效的,但无法捕获每个点的更广泛的上下文信息。为了学习更丰富的局部结构,许多专用的神经模块随后被迅速引入。这些模块通常可分类为:1)相邻特征池化[44,32,21,70,69],2)图形消息传递[57,48,55,56,5,22,34],3)基于内核的卷积[49,20,60,29,23,24,54,38],以及4)基于注意力的聚合[61,68,66,42]。尽管这些方法实现了对象识别和语义分割的令人印象深刻的结果,但是它们中的几乎所有都限于极小的3D点云(例如,4k个点或1×1米块),并且不能直接扩展到更大的点云(例如,数百万个点和高达200×200米),而无需预处理步骤,如块分割。这种限制的原因有三方面。
1)这些网络常用的点采样方法要么计算量大,要么内存效率低。例如,广泛采用的最远点采样[44]需要超过200秒才能对100万个点中的10%进行采样。
2)大多数现有的局部特征学习器通常依赖于计算昂贵的核化或图构造,从而无法处理大量的点。
3)对于通常由数百个对象组成的大规模点云,现有的局部特征学习器要么无法捕获复杂结构,要么效率低下,因为它们的感受野大小有限
PointNet 只能处理小规模点云
最近的一些工作已经开始解决直接处理大规模点云的任务。SPG [26]在应用神经网络学习每个超点语义之前,将大型点云预处理为超级图。FCPN [45]和PCT [7]都联合收割机了体素化和点级网络来处理大量点云。虽然它们实现了体面的分割精度,预处理和体素化步骤的计算量太大,部署在实时应用程序。
在本文中,我们的目标是设计一个内存和计算效率高的神经架构,它能够直接处理大规模的3D点云在一个单一的通行证,而不需要任何预/后处理步骤,如体素化,块分区或图形构建。然而,这项任务极具挑战性,因为它需要:
1)存储器和计算上高效的采样方法,以逐步下采样大规模点云,以适应当前GPU的限制,以及2)有效的局部特征学习器,以逐步增加感受野大小,以保留复杂的几何结构。为此,我们首先系统地证明了随机采样是深度神经网络有效处理大规模点云的关键因素。然而,随机采样可能会丢弃关键信息,特别是对于具有稀疏点的对象。为了对抗随机采样的潜在不利影响,我们提出了一个新的和有效的本地特征聚合模块来捕获复杂的局部结构逐渐变小的点集。
- 现有方法的预处理和体素化步骤的计算量太大
在现有的采样方法中,最远点采样和逆密度采样最常用于小规模点云[44,60,33,70,15]。由于点采样是这些网络中的一个基本步骤,我们在第3.2节中研究了不同方法的相对优点,在那里我们看到常用的采样方法限制了对大型点云的扩展,并成为实时处理的一个重要瓶颈。然而,我们认为随机采样是迄今为止最适合大规模点云处理的组件,因为它速度快,扩展效率高。随机采样不是没有成本的,因为突出的点特征可能会被偶然丢弃,并且它不能直接用于现有网络而不引起性能损失。为了克服这个问题,我们在第3.3节中设计了一个新的局部特征聚合模块,该模块能够通过逐步增加每个神经层中的感受野大小来有效地学习复杂的局部结构。具体地,对于每个3D点,我们首先引入局部空间编码(LocSE)单元来显式地保留局部几何结构。其次,我们利用细心的池自动保持有用的本地功能。第三,我们堆叠多个LocSE单元和注意力池作为一个扩张的残留块,大大增加了每个点的有效感受野。注意,所有这些神经组件都被实现为共享的MLP,因此具有显著的存储器和计算效率。
- 最远点采样和逆密度采样最常用于小规模点云
- 随机采样是迄今为止最适合大规模点云处理的组件,因为它速度快,扩展效率高
随机采样会使得 突出的点特征可能会被偶然丢弃,设计了一个新的局部特征聚合模块,该模块能够通过逐步增加每个神经层中的感受野大小来有效地学习复杂的局部结构
总的来说,基于简单随机采样和有效的局部特征聚合器的原则,我们的高效神经架构RandLA-Net不仅比现有的大规模点云方法快200倍,而且还超过了Semantic 3D [17]和SemanticKITTI [3]基准测试中最先进的语义分割方法。图1显示了我们的方法的定性结果。我们的主要贡献是:
- 我们分析和比较现有的采样方法,确定随机采样作为最合适的组件,有效地学习大规模点云。
- 我们提出了一个有效的局部特征聚合模块,通过逐渐增加每个点的感受野来保留复杂的局部结构。
- 我们在基线上展示了显着的内存和计算增益,并在多个大规模基准测试中超越了最先进的语义分割方法。
- Related Work
为了从3D点云中提取特征,传统方法通常依赖于手工制作的特征[11,47,25,18]。最近的基于学习的方法[16,43,37]主要包括基于投影,基于体素和基于点的方案,这里概述了这些方案。

基于投影的网络。
为了利用2D CNN的成功,许多作品[30,8,63,27]将3D点云投影/展平到2D图像上,以解决对象检测的任务。然而,在投影期间可能丢失几何细节。
基于体素的网络
可以将点云体素化为3D网格,然后在[14,28,10,39,9]中应用强大的3D CNN。虽然它们在语义分割和目标检测方面取得了领先的结果,但其主要局限性是计算量大,尤其是在处理大规模点云时。
基于点的网络。
受PointNet/PointNet++ [43,44]的启发,许多最近的作品引入了复杂的神经模块来学习每个点的局部特征。这些模块通常可以被分类为1)相邻特征池化[32,21,70,69],2)图形消息传递[57,48,55,56,5,22,34,31],3)基于内核的卷积[49,20,60,29,23,24,54,38],以及4)基于注意力的聚合[61,21,70,69]。68、66、42]。虽然这些网络在小的点云上显示出有希望的结果,但由于其高计算和内存成本,它们中的大多数不能直接扩展到大的场景。
与它们相比,我们提出的RandLA-Net在三个方面有所区别:
1)它仅依赖于网络内的随机采样,从而需要少得多的存储器和计算;
2)所提出的局部特征聚合器通过显式地考虑局部空间关系和点特征,可以获得连续更大的感受野,从而对学习复杂的局部模式更加有效和鲁棒;
3)整个网络仅由共享的MLP组成,而不依赖于任何昂贵的操作,例如图构建和核化,因此对于大规模点云非常有效。
学习大规模点云。
SPG [26]将大型点云预处理为超点图以学习每个超点语义。
最近的FCPN [45]和PCT [7]应用基于体素和基于点的网络来处理大量点云。然而,图分区和体素化两者在计算上都是昂贵的。相比之下,我们的RandLA-Net是端到端可训练的,不需要额外的前/后处理步骤。
- RandLA-Net
Overview
如图2所示,给定一个具有数百万个点的大规模点云,跨越数百米,要用深度神经网络处理它,不可避免地需要在每个神经层中对这些点进行渐进和有效的下采样,而不会丢失有用的点特征。在我们的RandLA-Net中,我们建议使用简单快速的随机采样方法来大大降低点密度,同时应用精心设计的局部特征聚合器来保留突出的特征。这允许整个网络在效率和有效性之间实现极好的权衡。

在RandLA-Net的每一层中,大规模的点云被显著地下采样,但能够保留精确分割所必需的特征。
The quest for efficient sampling

现有的点采样方法[44,33,15,12,1,60]可以大致分为启发式和基于学习的方法。然而,仍然没有标准的采样策略,是适合于大规模的点云。因此,我们分析和比较它们的相对优点和复杂性如下。
启发式抽样
最远点采样(FPS):为了从具有N个点的大规模点云P中采样K个点,FPS返回度量空间{p1 · · · pk · · · pK}的重新排序,使得每个pk是距离前k − 1个点最远的点。FPS在[44,33,60]中被广泛用于小点集的语义分割。虽然它有一个很好的覆盖整个点集,其计算复杂度为O(N2)。对于大规模点云(N 106),FPS在单个GPU上处理需要200秒1。这表明FPS不适合大规模点云。
逆密度重要性抽样(IDIS):为了从N个点中采样K个点,IDIS根据每个点的密度对所有N个点进行重新排序,然后选择前K个点[15]。其计算复杂度约为O(N)。根据经验,处理106个点需要10秒。与FPS相比,IDIS更有效,但对离群值更敏感。然而,它对于在实时系统中使用仍然太慢。
随机采样(RS):随机采样从原始N个点中均匀地选择K个点。它的计算复杂度是O(1),这与输入点的总数无关,即,它是恒定时间且因此固有地可缩放。与FPS和IDIS相比,无论输入点云的规模如何,随机采样都具有最高的计算效率。处理106个点只需要0.004s。
Learning-based Sampling
基于发生器的采样(GS):GS [12]学习生成一个小的点集来近似表示原始的大点集。然而,FPS通常用于在推理阶段将生成的子集与原始集合进行匹配,从而产生额外的计算。在我们的实验中,对106个点中的10%进行采样需要长达1200秒。
基于连续松弛的采样(CRS):CRS方法[1,66]使用重新参数化技巧将采样操作放松到连续域以进行端到端训练。特别地,基于全点云上的加权和来学习每个采样点。当使用一遍矩阵乘法同时对所有新点进行采样时,它会导致大的权重矩阵,从而导致无法负担的存储器成本。例如,估计需要超过300GB的内存占用来对106个点的10%进行采样。
基于策略梯度的采样(PGS):PGS将采样操作公式化为马尔可夫决策过程[62]。它顺序地学习概率分布来采样点。然而,当点云较大时,由于极大的探索空间,学习概率具有较高的方差。例如,对106个点的10%采样,探索空间是C105 106,并且不太可能学习有效的采样策略。我们经验发现,如果PGS用于大的点云,网络是难以收敛 。
总体而言,FPS、IDIS和GS在计算上过于昂贵,不能应用于大规模点云。CRS方法具有过多的内存占用,PGS很难学习。相比之下,随机抽样具有以下两个优点:
1)它是显著的计算效率,因为它对输入点的总数是不可知的,
2)它不需要额外的存储器用于计算。因此,我们安全地得出结论,随机采样是迄今为止最适合的方法处理大规模点云相比,所有现有的替代方案。然而,随机采样可能导致许多有用的点特征被丢弃。为了克服这个问题,我们提出了一个强大的本地特征聚合模块,在下一节中介绍。
3.3. Local Feature Aggregation局部特征聚合
如图3所示,我们的局部特征聚合模块并行应用于每个3D点,它由三个神经单元组成:
1)局部空间编码(LocSE)
2)注意池化
3)扩张的残余块
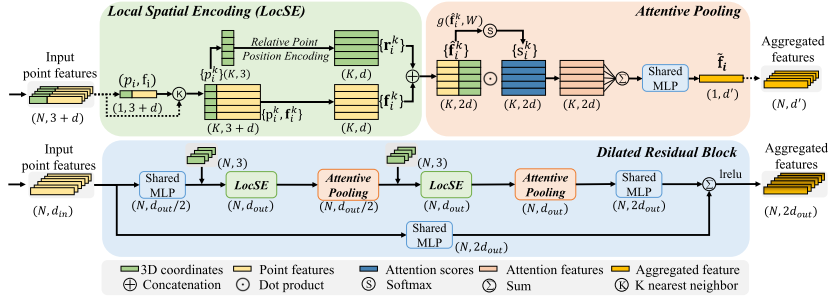
提出的局部特征聚合模块。顶部面板示出了提取特征的位置空间编码块,以及基于局部上下文和几何形状对最重要的相邻特征加权的注意池化机制。下图示出了这些组件中的两个如何链接在一起,以增加残余块内的感受野大小。
Local Spatial Encoding
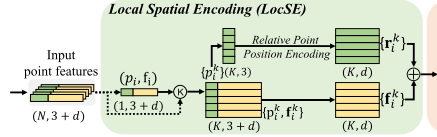
给定点云P连同每点特征(例如,原始RGB,或中间学习特征),该局部空间编码单元显式地嵌入所有相邻点的x-y-z坐标,使得对应的点特征总是知道它们的相对空间位置。这允许LocSE单元显式地观察局部几何图案,从而最终有利于整个网络有效地学习复杂的局部结构。特别地,该单元包括以下步骤:
1 Finding Neighbouring Points
对于第i个点,它的相邻点首先通过简单的K近邻(KNN)算法收集效率。KNN基于逐点欧氏距离。
2 Relative Point Position Encoding
对于中心点pi的最接近的K个点{p1 i · · · pk i · ·pKi}中的每一个,我们如下明确地对相对点位置进行编码:
![]()
其中pi和pk,i是点的x-y-z位置,是级联操作,并且||·||计算相邻点和中心点之间的欧几里得距离。
似乎rk i是从冗余点位置编码的。有趣的是,这往往有助于网络学习本地特征,并在实践中获得良好的性能。
3 Point Feature Augmentation.
对于每个相邻点pk i,将编码的相对点位置rki与其对应的点特征fki连接,从而获得增强的特征向量(fki)。
最后,LocSE单元的输出是一组新的相邻特征(Fi = {f1 i · · ·fk i · ·fKi},其明确地编码中心点pi的局部几何结构。我们注意到最近的工作[36]也使用点位置来改进语义分割。然而,在[36]中,位置用于学习点得分,而我们的LocSE显式地编码相对位置以增强相邻点特征。
Attentive Pooling

该神经单元用于聚合相邻点特征的集合(Fi)。现有作品[44,33]通常使用最大/平均池化来硬集成相邻特征,导致大部分信息丢失。相比之下,我们转向强大的注意力机制来自动学习重要的局部特征。特别是,受[65]的启发,我们的专注池单元包括以下步骤。
1 Computing Attention Scores.
给定局部特征集合Fi = {f1 i · · · ·fk i · · ·fK i },我们设计一个共享函数g()来学习每个特征的唯一注意力分数。基本上,函数g()由共享MLP和softmax组成。其正式定义如下:
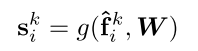
其中W是共享MLP的可学习权重。
在机器学习中,注意力机制是一种常见的神经网络技术,可以为每个输入特征赋予不同的权重,从而使得网络更加关注对于当前任务更为重要的特征。其中的
- 注意力分数:指为每个特征分配的权重,它可以体现每个特征对于当前任务的重要性程度。
- 共享函数g学习每个特征的唯一注意力分数,说明该函数能够学习到每个特征应该被分配的权重,并将这些权重应用于网络的后续计算中,从而提高网络的性能。
Weighted Summation.
学习的注意力分数可以被视为自动选择重要特征的软掩模。形式上,这些特征被加权求和如下:
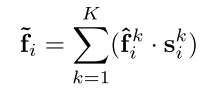
总之,给定输入点云P,对于第i个点pi,我们的LocSE和注意力池单元学习聚合其K个最近点的几何图案和特征,并最终生成信息特征向量~ fi。
Dilated Residual Block 残差块

由于大的点云将被基本上下采样,因此期望显著地增加每个点的感受场,使得输入点云的几何细节更可能被保留,即使一些点被丢弃。如图3所示,受成功的ResNet [19]和有效的扩张网络[13]的启发,我们将多个LocSE和Attentive Pooling单元与跳过连接堆叠为扩张的残差块。
感受野(Receptive Field)指的是神经网络中的某个神经元对于输入的局部感受范围,即它能接受到的输入数据的区域大小。在卷积神经网络中,每个卷积层的神经元都会通过卷积核在输入图像上扫描得到一个输出值,同时也会受到前一层神经元输出的影响。由于神经网络在不同层次提取不同抽象层次的特征,因此每一层的感受野大小不同,通常随着网络层数增加而增大。
具体来说,感受野可以分为三种类型:局部感受野、全局感受野和有效感受野。
- 局部感受野是指单个神经元对于输入数据的局部区域,
- 全局感受野是指整个网络对于输入数据的完整感受范围,
- 而有效野可以理解为神经元实际上能够接受到的输入数据的范围,通常比全局感受野要小。通过了解感受野的大小和类型,可以更好地设计和优化神经网络的结构,从而提高模型的性能。
为了进一步说明我们的扩张残差块的能力,图4示出了红色3D点在第一LocSE/Attentive Pooling操作之后观察K个相邻点,并且然后能够从多达K2个相邻点,即,第二个之后的两个街区。
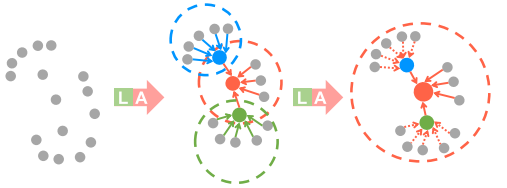
扩张的残余块的图示,其显著增加了每个点的感受野(虚线圆),彩色点表示聚合特征。L:局部空间编码,A:注意力集中。
这是一种通过特征传播扩大感受野和扩大有效邻域的廉价方式。从理论上讲,我们堆叠的单位越多,这个方块的威力就越大,因为它的范围越来越大。然而,更多的单元将不可避免地牺牲整体计算效率。此外,整个网络很可能会过度装配。在我们的RandLA-Net中,我们简单地堆叠两组LocSE和Attentive Pooling作为标准残差块,实现了效率和有效性之间的满意平衡。
总体而言,我们的本地功能聚合模块的目的是有效地保留复杂的本地结构,通过明确考虑相邻的几何形状和显着增加的感受野。此外,该模块仅由前馈MLP组成,因此计算效率高。
Implementation
我们通过堆叠多个本地特征聚合模块和随机采样层来实现RandLA-Net。详细的体系结构见附录。我们使用带有默认参数的Adam优化器。初始学习率被设置为0.01,并且在每个时期之后降低5%。最近点的数量K被设置为16。为了并行训练我们的RandLA-Net,我们从每个点云中采样固定数量的点(105)作为输入。在测试过程中,整个原始点云被馈送到我们的网络中,以推断每个点的语义,而无需进行几何或块划分等预/后处理。所有实验均在NVIDIA RTX 2080 Ti GPU上进行。
- Experiments
Efficiency of Random Sampling
在本节中,我们对现有采样方法(包括FPS、IDIS、RS、GS、CRS和PGS)的效率进行了实证评估,这些方法已在第3.2节中讨论。具体地,我们进行了以下4组实验。
第1组。给定一个小规模的点云(大约103个点),我们使用每种采样方法对其进行逐步下采样。具体地,点云通过五个步骤进行下采样,其中在单个GPU上的每个步骤中仅保留25%的点,即四倍抽取比。这意味着最后只剩下(1/4)5 × 103个点。这种下采样策略模拟了PointNet++ [44]中使用的过程。对于每种采样方法,我们总结其时间和内存消耗以进行比较。
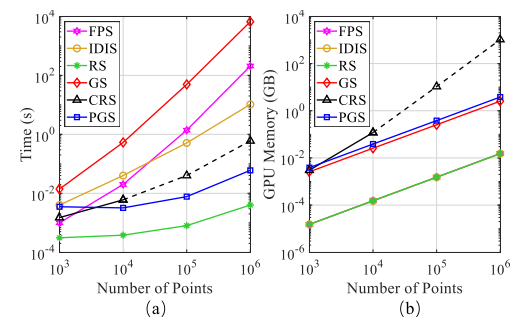
图5 不同采样方法的时间和内存消耗。虚线表示由于有限的GPU存储器而估计的值。
第2/3/4组。点的总数向大规模增加,即,分别为104、105和106点。我们使用与第1组相同的五个采样步骤。
图5比较了处理不同比例点云的每种采样方法的总时间和内存消耗。可以看出:
1)对于小规模点云(103),所有采样方法往往具有相似的时间和内存消耗,并且不太可能引起沉重或有限的计算负担。
2)对于大规模的点云(106),FPS/IDIS/GS/CRS/PGS要么非常耗时,要么占用内存。相比之下,随机采样总体上具有上级的时间和内存效率。该结果清楚地表明,大多数现有网络[44,33,60,36,70,66]只能在小块点云上进行优化,主要是因为它们依赖于昂贵的采样方法。基于此,我们在RandLA-Net中使用了高效的随机采样策略。
Efficiency of RandLA-Net
在本节中,我们系统地评估了我们的RandLA-Net在真实世界的大规模点云语义分割上的整体效率。特别地,我们在SemanticKITTI [3]数据集上评估RandLA-Net,获得我们的网络在Sequence 08上的总时间消耗,其中共有4071个点云扫描。我们还评估了在同一数据集上最近的代表性作品[43,44,33,26,54]的时间消耗。为了公平的比较,我们馈送相同数量的点(即,81920)从每个扫描到每个神经网络。
此外,我们还评估了RandLA-Net的内存消耗和基线。特别是,我们不仅报告每个网络的参数总数,而且还测量每个网络可以在单次传递中作为输入的最大3D点数量,以推断每个点的语义。注意,所有实验都在具有AMD 3700X@3.6GHz CPU和NVIDIA RTX 2080 Ti GPU的同一机器上进行。
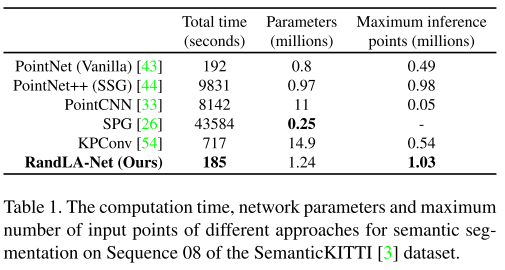
表1定量地显示了不同方法的总时间和内存消耗。可以看出,
1)SPG [26]具有最少的网络参数,但由于昂贵的几何划分和超级图构造步骤,处理点云所花费的时间最长;
2)PointNet++ [44]和PointCNN [33]在计算上也很昂贵,主要是因为FPS采样操作;
3)PointNet [43]和KPConv [54]无法获取非常大规模的点云(例如106个点),这是由于它们的存储器低效操作。
4)由于简单的随机采样和高效的基于MLP的本地特征聚合器,我们的RandLA-Net花费最短的时间(平均185秒,平均4071帧→大约22 FPS)来推断每个大规模点云(最多106个点)的语义标签。
Semantic Segmentation on Benchmarks
在本节中,我们评估了RandLA-Net在三个大规模公共数据集上的语义分割:室外Semantic 3D [17]和SemanticKITTI [3],以及室内S3 DIS [2]。
Evaluation on Semantic3D.
Semantic3D数据集[17]由15个用于训练的点云和15个用于在线测试的点云组成。每个点云最多有10^8个点,在真实世界的3D空间中覆盖160×240×30米。原始3D点属于8类,并且包含3D坐标、RGB信息和强度。我们只使用3D坐标和颜色信息来训练和测试我们的RandLANet。所有类别的平均相交度(mIoU)和总体准确度(OA)被用作标准度量。为了进行公平比较,我们仅包括最近发表的强基线结果[4,52,53,46,69,56,26]和当前最先进的方法KPConv [54]。
表2给出了不同方法的定量结果。RandLA-Net在mIoU和OA方面明显优于所有现有方法。值得注意的是,RandLANet还在八个类别中的六个类别上实现了上级的性能,除了低植被和扫描艺术。
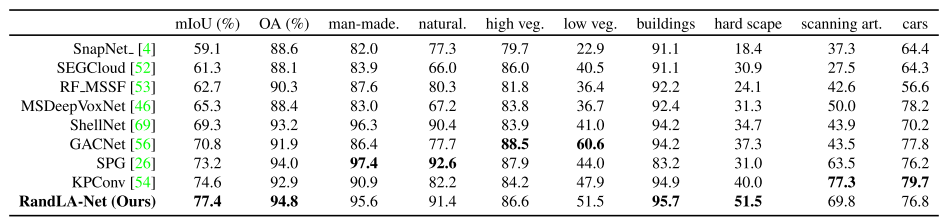
表2. Semantic 3D上不同方法的定量结果(减少-8)[17]。只有最近公布的方法进行比较。于二零二零年三月三十一日查阅。
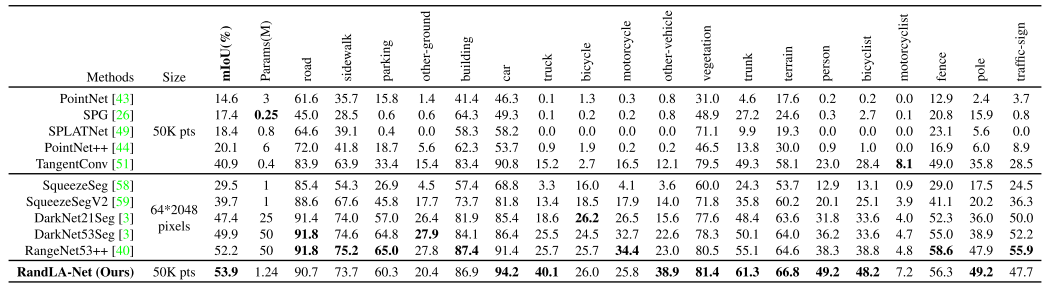
SemanticKITTI上不同方法的定量结果[3]。仅比较最近发表的方法,并且从在线单扫描评估轨道获得所有分数。于二零二零年三月三十一日查阅。
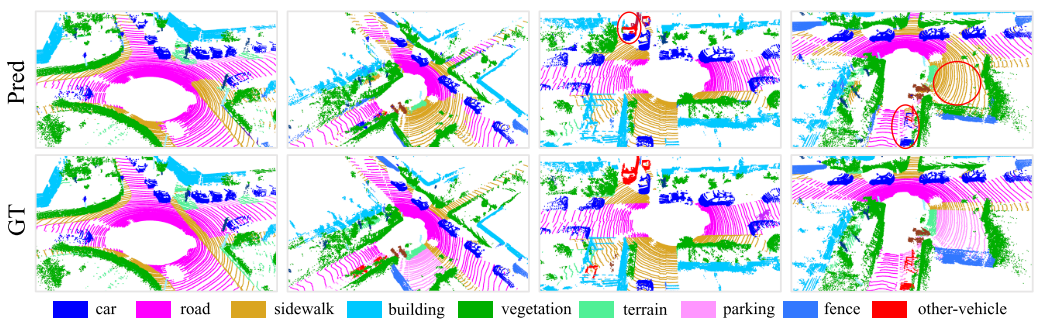
RandLA-Net在SemanticKITTI [3]验证集上的定性结果。红色圆圈表示失败案例。
Evaluation on SemanticKITTI.
SemanticKITTI [3]由属于21个序列的43552个密集注释的LIDAR扫描组成。每个扫描是一个大规模的点云,包含10^5个点,在3D空间中跨度高达160×160×20米。正式地,序列00 07和09 10(19130次扫描)用于训练,序列08(4071次扫描)用于验证,序列11 21(20351次扫描)用于在线测试。原始3D点仅具有3D坐标而不具有颜色信息。超过19个类别的mIoU分数被用作标准度量。
表3显示了我们的RandLANet与两个最近方法家族的定量比较,即1)基于点的方法[43,26,49,44,51]和2)基于投影的方法[58,59,3,40],图6显示了RandLA-Net在验证分割上的一些定性结果。可以看出,我们的RandLA-Net大大超过了所有基于点的方法[43,26,49,44,51]。我们还优于所有基于投影的方法[58,59,3,40],但并不显著,主要是因为RangeNet++ [40]在小对象类别(如交通标志)上实现了更好的结果。然而,我们的RandLA-Net的网络参数比RangeNet++ [40]少40倍,并且计算效率更高,因为它不需要昂贵的前/后投影步骤。
Evaluation on S3DIS.
S3DIS数据集[2]由属于6个大区域的271个房间组成。每个点云都是一个中等大小的单间(20×15×5米),其中包含密集的3D点。为了评估我们的RandLA-Net的语义分割,我们在实验中使用标准的6折交叉验证。比较了总共13个类别的平均IoU(mIoU)、平均类别准确度(mAcc)和总体准确度(OA)。
如表4所示,我们的RandLA-Net实现了与最先进的方法同等或更好的性能。注意,这些基线[44,33,70,69,57,6]中的大多数倾向于使用复杂但昂贵的操作或采样来优化小块上的网络(例如,1×1米)的点云,而相对较小的房间在它们的优势被分成小块。相比之下,RandLA-Net将整个房间作为输入,并且能够在单次传递中高效地推断每点语义。
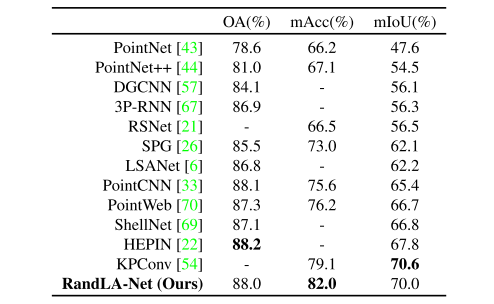
S3DIS数据集上不同方法的定量结果[2](6倍交叉验证)。仅包括最近公布的方法。
Ablation Study 消融研究
由于在第4.1节中充分研究了随机采样的影响,因此我们对局部特征聚合模块进行了以下消融研究。所有消融的网络都在序列00 07和09 10上训练,并在SemanticKITTI数据集的序列08上测试[3]。
(1) Removing local spatial encoding (LocSE).
该单元使每个3D点能够明确地观察其局部几何形状。在移除locSE之后,我们直接将局部点特征馈送到后续的关注池中。
(2∼4) Replacing attentive pooling by max/mean/sum pooling.
注意池化单元学习自动联合收割机所有局部点特征。相比之下,广泛使用的最大值/平均值/总和池往往难以选择或联合收割机特征,因此它们的性能可能是次优的。
(5) Simplifying the dilated residual block.
扩张的残余块堆叠多个LocSE单元和注意池,基本上扩张每个3D点的感受野。通过简化该块,我们每层仅使用一个LocSE单元和注意池化,即我们不像在原始RandLA-Net中那样链接多个块。
表5比较了所有消融网络的mIoU评分。由此可见:
1)最大的影响是由链式空间嵌入和注意池化块的移除引起的。这在图4中突出显示,图4示出了使用两个链式块如何允许信息从更宽的邻域传播,即,大约K2点,而不是只有K点。这对于随机采样尤其重要,因为不能保证保留特定的点集。
2)局部空间编码单元的去除示出了对性能的下一个最大影响,表明该模块对于有效地学习局部和相对几何上下文是必要的。
3)移除注意力模块由于不能有效地保留有用的特征而降低了性能。从这项消融研究中,我们可以看到所提出的神经单元如何相互补充,以达到我们最先进的性能。

- Conclusion
在本文中,我们证明了它是可能的,有效地分割大规模的点云,通过使用一个轻量级的网络架构。与依赖于昂贵的采样策略的大多数当前方法相反,我们在我们的框架中使用随机采样来显着减少内存占用和计算成本。还引入了一个局部特征聚合模块,以有效地保留有用的功能,从广泛的邻里。在多个基准上的大量实验证明了我们的方法的高效率和最先进的性能。通过借鉴最近的工作[64]以及实时动态点云处理[35],扩展我们的框架用于大规模点云上的端到端3D实例分割将是有趣的。
致谢:这项工作得到了中国国家留学基金管理理事会(CSC)奖学金的部分支持。国家自然科学基金项目(No. 61972435)、广东省自然科学基金(2019A1515011271)、深圳市科技创新委员会。