前言:Hello大家好,我是小哥谈。数据集标注完成之后,下一步就是对这些数据集进行划分了。面对繁杂的数据集,如果手动划分的话,不仅麻烦而且不能保持随机性。本节课就给大家介绍一种方法,即使用代码去划分数据集。那现在就让我们开始今天的学习吧!🌈
![]() 前期回顾:
前期回顾:
YOLOv5入门实践(1)— 手把手教你使用labelimg标注数据集(附安装包+使用教程)
YOLOv5入门实践(2)— 手把手教你使用make sense标注数据集(附工具地址+使用教程)
目录
🚀1.训练集、验证集和测试集
🚀2.数据集划分原则
🚀3.准备数据集
步骤1:创建数据集文件夹
步骤2:标注数据集
步骤3:创建划分后数据集的文件夹
🚀4.划分代码
步骤1:在YOLOv5项目目录下创建split.py文件
步骤2:将代码复制到split.py文件中
步骤3:设置路径并设置划分比例

🚀1.训练集、验证集和测试集
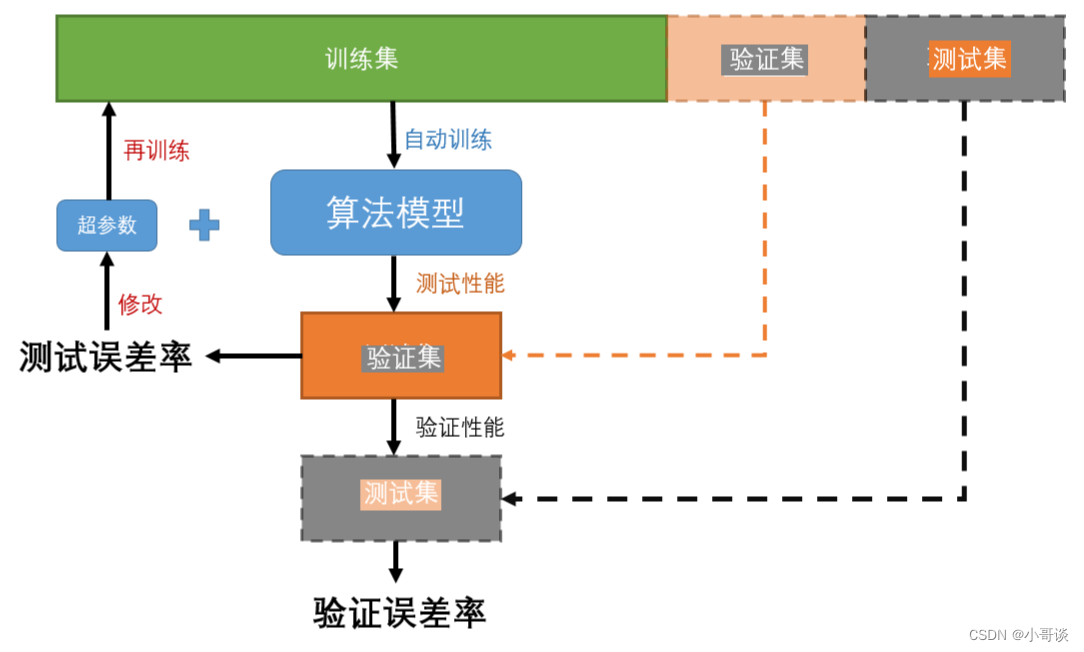
数据集标注完成之后,我们通常需要把数据集划分为三类:训练集、验证集和测试集。🌺
举个例子:模型的训练与学习,类似于老师教学生知识的过程。
训练集(train set):用于训练模型(拟合参数),即模型拟合的数据样本集合。相当于老师上课教学生知识的过程。
验证集(validation set):用于确定网络结构或者控制模型复杂程度的超参数(拟合超参数),是模型训练过程中单独留出的样本集,它可以用于调整模型的超参数和用于对模型的能力进行初步评估。 通常用来在模型迭代训练时,用以验证当前模型泛化能力(准确率,召回率等),防止过拟合的现象出现,以决定如何调整超参数。相当于上完课后的课后练习题,用于帮助学生查漏补缺。
测试集(test set):用来评估最终模型的性能如何(评价模型好坏),测试集没有参于训练,主要是测试训练好的模型的准确能力等,但不能作为调参、选择特征等算法相关的选择的依据,说白了就只是用于评价模型好坏的一个数据集。相当于期末考试,真正地去检验学生的学习效果。

说明:♨️♨️♨️
参数:指由模型通过学习得到的变量,如权重和偏置。✅
超参数:指根据经验设定的参数,如迭代次数、隐藏层数、每层神经元的个数、学习率等。✅
🚀2.数据集划分原则
数据集划分的方法并没有明确的规定,不过可以参考3个原则:
1.对于小规模样本集(几万量级),常用的分配比例是 70% 训练集、20% 验证集、10% 测试集。
2.对于大规模样本集(百万级以上),只要验证集和测试集的数量足够即可,例如有 100w 条数据,那么留 1w 验证集,1w 测试集即可。1000w 的数据,同样留 1w 验证集和 1w 测试集。
3.超参数越少,或者超参数很容易调整,那么可以减少验证集的比例,更多的分配给训练集。

🚀3.准备数据集
步骤1:创建数据集文件夹
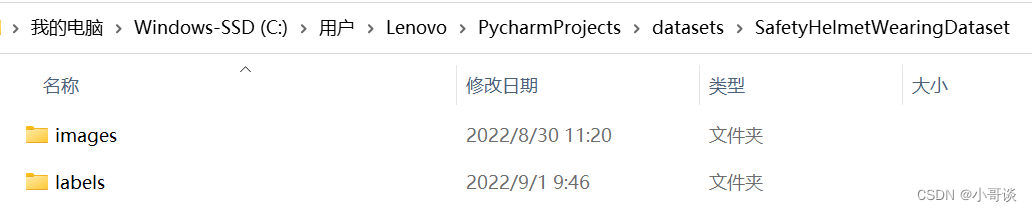
在与项目文件同级目录的datasets文件夹中,创建SafetyHelmetWearingDataset文件夹接着在该文件夹下创建images和labels文件夹。
- images:存放需要打标签的图片文件
- labels:存放标注的标签文件
说明:♨️♨️♨️
1.也可以在YOLOv5项目目录下创建数据集文件夹并命名,其性质是一样的。✅
2.datasets 和 SafetyHelmetWearingDataset是我自己命名的,是为后期训练安全帽佩戴检测模型做准备,此处名字可以自定义。✅
步骤2:标注数据集
说明:
关于数据集的标注,可以参考我的另外两篇标注数据集的文章。♨️♨️♨️
YOLOv5入门实践(1)— 手把手教你使用labelimg标注数据集(附安装包+使用教程)
YOLOv5入门实践(2)— 手把手教你使用make sense标注数据集(附工具地址+使用教程)
步骤3:创建划分后数据集的文件夹
创建一个名为imageSets的文件夹,用来保存稍后划分好的训练集、验证集和测试集。🌱
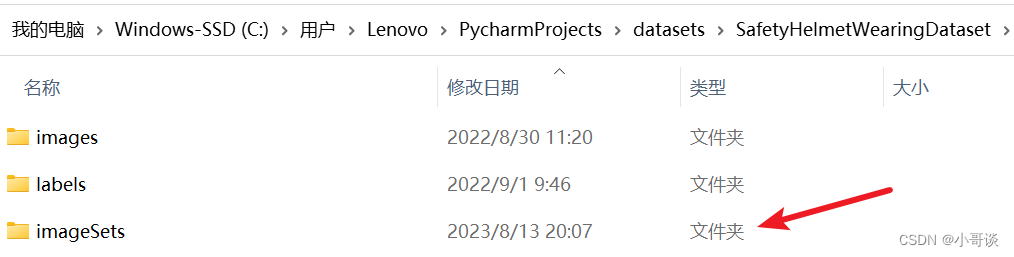
说明:♨️♨️♨️
1.所有训练所需的图片存于一个文件夹中(指images),所有训练所需的标签存于一个文件夹中(指labels)。✅
2.图片名与标签名要一一对应。✅
🚀4.划分代码
步骤1:在YOLOv5项目目录下创建split.py文件
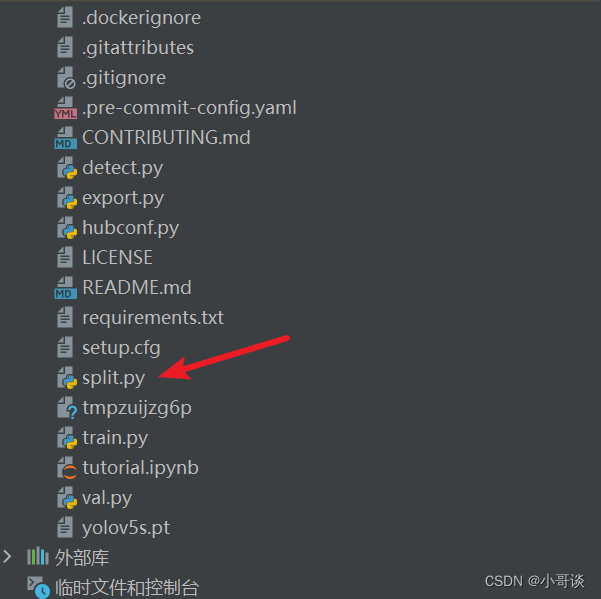
步骤2:将代码复制到split.py文件中
import os
import shutil
import random
random.seed(0)
def split_data(file_path,xml_path, new_file_path, train_rate, val_rate, test_rate):
each_class_image = []
each_class_label = []
for image in os.listdir(file_path):
each_class_image.append(image)
for label in os.listdir(xml_path):
each_class_label.append(label)
data=list(zip(each_class_image,each_class_label))
total = len(each_class_image)
random.shuffle(data)
each_class_image,each_class_label=zip(*data)
train_images = each_class_image[0:int(train_rate * total)]
val_images = each_class_image[int(train_rate * total):int((train_rate + val_rate) * total)]
test_images = each_class_image[int((train_rate + val_rate) * total):]
train_labels = each_class_label[0:int(train_rate * total)]
val_labels = each_class_label[int(train_rate * total):int((train_rate + val_rate) * total)]
test_labels = each_class_label[int((train_rate + val_rate) * total):]
for image in train_images:
print(image)
old_path = file_path + '/' + image
new_path1 = new_file_path + '/' + 'train' + '/' + 'images'
if not os.path.exists(new_path1):
os.makedirs(new_path1)
new_path = new_path1 + '/' + image
shutil.copy(old_path, new_path)
for label in train_labels:
print(label)
old_path = xml_path + '/' + label
new_path1 = new_file_path + '/' + 'train' + '/' + 'labels'
if not os.path.exists(new_path1):
os.makedirs(new_path1)
new_path = new_path1 + '/' + label
shutil.copy(old_path, new_path)
for image in val_images:
old_path = file_path + '/' + image
new_path1 = new_file_path + '/' + 'val' + '/' + 'images'
if not os.path.exists(new_path1):
os.makedirs(new_path1)
new_path = new_path1 + '/' + image
shutil.copy(old_path, new_path)
for label in val_labels:
old_path = xml_path + '/' + label
new_path1 = new_file_path + '/' + 'val' + '/' + 'labels'
if not os.path.exists(new_path1):
os.makedirs(new_path1)
new_path = new_path1 + '/' + label
shutil.copy(old_path, new_path)
for image in test_images:
old_path = file_path + '/' + image
new_path1 = new_file_path + '/' + 'test' + '/' + 'images'
if not os.path.exists(new_path1):
os.makedirs(new_path1)
new_path = new_path1 + '/' + image
shutil.copy(old_path, new_path)
for label in test_labels:
old_path = xml_path + '/' + label
new_path1 = new_file_path + '/' + 'test' + '/' + 'labels'
if not os.path.exists(new_path1):
os.makedirs(new_path1)
new_path = new_path1 + '/' + label
shutil.copy(old_path, new_path)
if __name__ == '__main__':
file_path = "C:\Users\Lenovo\PycharmProjects\datasets\SafetyHelmetWearingDataset\images"
xml_path = "C:\Users\Lenovo\PycharmProjects\datasets\SafetyHelmetWearingDataset\labels"
new_file_path = "C:\Users\Lenovo\PycharmProjects\datasets\SafetyHelmetWearingDataset\imageSets"
split_data(file_path,xml_path, new_file_path, train_rate=0.7, val_rate=0.2, test_rate=0.1)步骤3:设置路径并设置划分比例
file_path:图片所在位置的绝对路径,即 images。
xml_path:标签所在位置的绝对路径,即 labels。
new_file_path:划分后三个文件的保存位置,即 imageSets。
最后一行是划分比例,大家可以根据实际情况来划分,这里我划分的是7:2:1。