目录
MySQL 背景知识
数据库基础操作
1.创建数据库
2.查看所有数据库
3.选中指定的数据库
4.删除数据库
数据库表操作
MySQL的数据类型
1.创建表
3.查看指定表的结构
4.删除表
增删改
新增操作
修改(Updata)
删除语句
面试题
查询操作
指定列查询
查询的列为表达式
给查询结果的列,指定别名(使用as)
查询的时候 针对列进行去重(把有重复的记录,给合并成一个)
针对查询结果进行排序
排序还可以指定多个列来进行排序
条件查询
MySQL 背景知识
MySQL是 客户端-服务器结构的程序
数据是存储在服务器硬盘(外存)上的
MySQL 存储数据的结构(关系型数据库):数据库服务器--多个数据库--多个数据表--多行记录(行)--多列字段(列)
数据库基础操作
1.创建数据库
create database 数据库名

create 和 database 都是 SQL 中的关键字,这里的关键字不区分大小写,数据库的名字不能是 SQL 中的关键字
创建数据库的时候,也可以指定数据库的字符集
create database 数据库名 charset 字符集名

2.查看所有数据库
show databases

3.选中指定的数据库
use 数据库名
![]()
选择数据库后,后续操作都是针对这个数据库来展开的
4.删除数据库
drop database 要删除的数据库名
![]()
这个操作非常危险,一旦删除数据库,就真的删除了,没有回收站
数据库表操作
MySQL的数据类型
数值类型

常用类型 int,double,decimal
M表示有效数字的位数,D表示小数点后保留几位
字符串类型

varchar 最常用表示字符串的类型,带有一个参数,约定了最大存储的空间,比如varchar(128),就表示这个列最多存128个字符,因此可以根据实际需求,来设置多长合适.
text,和mediumtext 适用于更长的字符串
日期类型

数据库表操作
1.创建表
create table 表名(列名 类型,列名 类型,......) ;
![]()
表名和列名不能和SQL的关键字重复,如果必须要这样做,可以使用 反引号` `
![]()
注释可以使用 -- 表示 类似 //
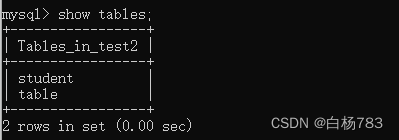
2.查看指定数据库下的所有表
show tables;
3.查看指定表的结构
desc 表名;
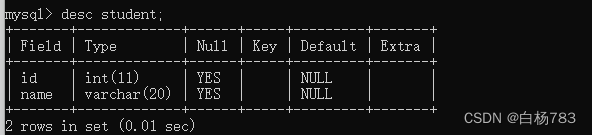
Field表示字段,Type表示字段的类型,NULL表示该字段是否允许为空(必选还是选题),Key表示约束,Defalult表示这一列的默认值,Extra表示额外的描述信息
4.删除表
drop table 表名

删除表操作和删除数据库操作一样,都是非常危险的,删除了就真的删除了
增删改
新增操作
insert into 表名 values(列,列,列......);
SQL中使用Insert 关键字表示新增,每次新增都是新增一行
![]()
values 后面()内容,个数和类型要和表的结构匹配
对指定列(一个或多个)进行插入
insert into 表名(列名) values(列名)
![]()
一次指定插入多行
Insert 语句,values后面的()可以有多组,每一组就对应到一行(一行记录)

修改(Updata)
updata 表名 set 列名 = 值 +(一些子句比如 where,oder by,limit 当然也可以不加)
将王五同学的语文成绩修改成80分
update student2 set chinese = 80 where name = "王五";

where子句描述了哪些行需要进行修改,set描述了哪些列需要进行修改.
修改操作,可以使用表达式进行修改
把所有同学的语文成绩-5;
update student2 set chinese = chinese-5;


update 可以修改多个列,多个列使用逗号隔开
给李四的语文成绩修改为70 数学成绩修改为80
update student2 set chinese = 70,math = 80 where name = "李四";

给总成绩倒数三名的数学成绩+5
update student2 set math = math+5 order by chinese+math+english asc limit 3;


删除语句
delete from 表名 where 条件
如果没有条件,就是把整个表中所有的记录都删除
删除student2表中所有的记录;
delete from student2;
面试题
在mysql 中,一次插入一条记录,分别插入十次,效率要低于一次把10条记录一起插入
原因:1.由于网络请求和响应需要时间开销(插入十次就需要十次的请求和响应,插入一次只需要一次)
2. 数据库服务器是把数据保存在硬盘上的,在进行io(输入输出)操作的时候,数据量对效率的影响不是很大,而io操作的次数影响比较大
3.mysql 为关系型数据库,每次进行sql,内部都会开启一个事务,每次开启事务会有一定的时间开销
查询操作
全列查询(查询表里的所有列)
select * from 表名
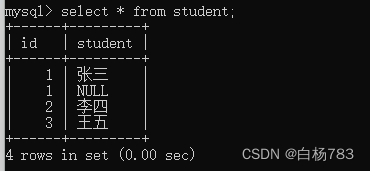
此处的 * 是通配符,代表了所有的列
注意此处的 select * 操作非常危险,这里的查询操作,会遍历表里面的所有数据,把数据从硬盘上读出来,通过网卡进行发送.
如果数据非常大,就很容易把硬盘IO吃满,或者把网络带宽吃满
指定列查询
select 列名 from 表名
查询的列为表达式
在查询的过程中进行一个简单的计算(列和列之间)
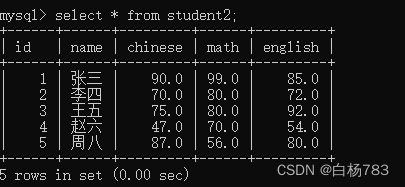
现在有一个student2表(方便后面展示)

查询所有同学英语成绩+10
select name,english+10 from student2;
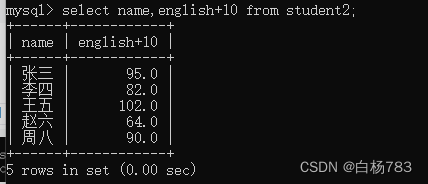
注意:进行表达式查询的时候,查询结果是一个临时表,这个表是不写入硬盘当中的,临时表的类型不和原始的表完全一致,会尽可能的把数据给表示进去..因此,这里102.0是可以存进这个临时表的,而如果是原来的表是存不进102.0的(原来的语数英类型是decimal(3,1))
查询所有同学的总分(三门课相加)
select name,chinese+math+english from student2;

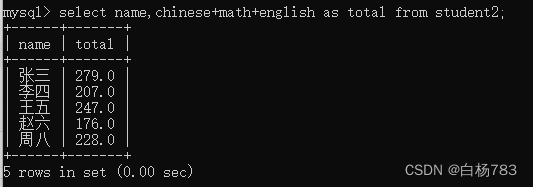
给查询结果的列,指定别名(使用as)
使用表达式查询的时候,写的表达式就是查询临时表的列名,比较丑,我可以起个别名
select name,ch inese+math+english as total from student2;
查询的时候 针对列进行去重(把有重复的记录,给合并成一个)
distinct(可以指定某一个列进行去重)
比如这里的李四和赵六的数学都是70分
select distinct math from student2;

注意这里的70只出现了一次,因此是去了重的
针对查询结果进行排序
order by 字句
比如我们要针对语文这一列进行升序排序
select name,chinese from student2 order by chinese asc;

asc 为升序, desc 为降序
针对语文这一列进行降序排序
select name,chinese from student2 order by chinese desc;

如果要排序的列中,有NULL,NULL视为最小值
排序也可以针对别名进行排序
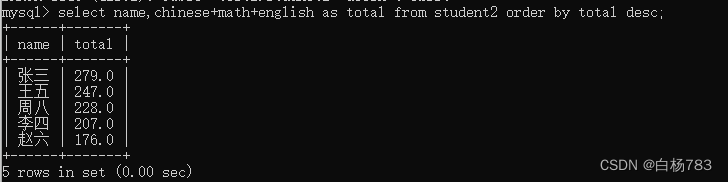
比如针对总成绩进行降序排序
select name,chinese+math+english as total from student2 order by total desc;
排序还可以指定多个列来进行排序
排序指定多个列的时候,先以第一列为准,再比较第二列
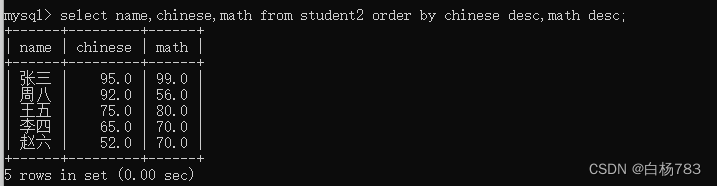
比如这里来语文和数学来排序,语文高的排在前面,当语文分数一样时,再比较数学,数学高的排前面
select name,chinese,math from student2 order by chinese desc,math desc;
条件查询
where 查询的结果按行进行删选,通过where指定一个条件,判断查询到的每一行,是否满足条件,把条件为真的行保留(作为临时表结果)
在sql中,"="号,就是比较相等的意思,不是赋值(这个符号如果左右俩边都是NULL结果为false,此时我们可以使用<=>避免这个问题)
查询英语不及格的同学
select * from student2 where english<60;
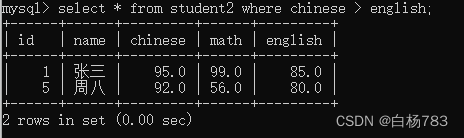
查询哪些同学语文成绩好于英语成绩
select * from student2 where chinese > english;
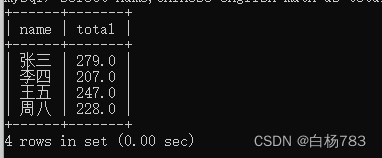
查询总分在200分以上的同学
select name,chinese+english+math as total from student2 where chinese+english+math > 200;
注意这里where子句,不能使用列的别名来比较,比如这里不能用total代替chinese+english+math
查询语文成绩大于80,并且英语成绩也大于80的学生
select name,chinese,english from student2 where chinese > 80 and english > 80;

查询语文成绩大于80,或者英语成绩大于80的学生
select name,chinese,english from student2 where chinese > 80 or english > 80;

如果一个条件中同时有and和or,先计算and后计算or,当然我们也可以写括号来定义优先级
between...and...
查询语文成绩在70到80之间的同学
select * from student2 where chinese between 70 and 80;

in
查询语文成绩为95或者80或者75或者60的同学
select * from student2 where chinese in(95,80,75,60);

like
查询 姓张 的同学的成绩(开头第一个字是张)
select * from student2 where name like "张%";
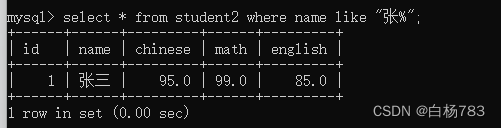
这里%分号的含义是通配符的意思可以表示0个或多个字符,也就是说以张开头的内容,都能查询出来
使用下划线_ 匹配一个字符(__匹配俩个,依次类推)
比如查询 姓张,并且名称是俩个字的同学
select * from student2 where name like "张_";
使用like的查询是模糊查询,查询的开销比较大
limit
查询结果中,引入一个limit来限制查询结果的数量
在查询结果末尾,加上limit 指定N,N就表示这次查询最大结果的数量
比如现在只查询总分前3名同学的记录
select *,chinese+math+english as total from student2 order by total desc limit 3;

limit offset
如果直接使用limit n,查到的是前N行(第一页)的东西,如果搭配offset 就可以指定第几条开始进行筛选,
比如我们要排除掉第一行的张三,查看其它同学中总分前三名的记录
select *,chinese+math+english as total from student2 order by total desc limit 3 offset 1;