1.系统设计
系统设计是一个定义系统架构、功能模块、服务及接口和数据存储等满足特定需求的过程。
与面向对象设计不同的是,面向对象设计通常是对于某个特定功能模块的设计,通常要求设计类图关系、接口关系、实现关系等涉及具体代码层面的设计,如:电梯设计、游戏设计。
系统设计是在面向对象设计的基础上更高层次的设计,关注整个系统的架构、组件之间的协作和通信,以及满足系统需求的实现。关键点在于:满足实际需求、具备可拓展性、稳定性等,常见如Twitter、网约车系统设计。
2.设计之道:4S分析法
系统设计常用的方法和设计思路是4S分析法:Scenes、Service、Storage、Scale
- Scenes:需求场景。当前需要解决的问题是什么、需要有哪里功能、当前体量及未来可预见性的体量
- DAU、平均QPS、峰值QPS等需求指标
- Service:系统服务。为了解决这些需求场景,需要提供哪些关键服务及关键接口
- HTTP服务、RPC服务、具体接口及各服务间的核心交互
- Storage:系统存储。定义系统服务的数据如何存储、如何访问
- Schema、NoSQL、关系式存储、事务、一致性、存储体量等考量
- Scale:系统拓展。解决当前及未来系统可能出现的问题
- 可拓展性、稳定性、降级、熔断、监控等
系统设计并不总是一步到位的最优方案,而是要符合当前场景下的最适合方案。尽可能在满足当前需求场景下选选择最简单的架构设计、存储设计,并对可预见的增长进行一定的拓展设计。系统设计本身是在权衡各类技术来解决核心的诉求。
3.实际的例子
设计一个MVP版本的Twitter系统。
3.1.Scenes
Twitter系统包含很多需求,首先进行需求定义,明确要做什么:
- 用户注册登陆
- 账号信息查看、修改
- 推文查看、搜素、上传
- 最新/最热/关注的推文Feed展示
- 推文点赞、订阅
- 用户关注、取消关注等
分析当前MVP版本最需要的核心需求及优先级:
- P0 用户注册登陆
- P0 推文查看、搜素、上传
- P0 最新/最热/关注的推文Feed展示
- P1 账号信息查看、修改
- P1 推文点赞、订阅
- P2 用户关注、取消关注等
基本数据指标估算:
假设当前MVP版本DAU(日活)为10万,每个用户平均每日触发后端API接口100次
- 系统均值QPS:DAU * 100 / (24 * 60 * 60) = 115 QPS
- 系统峰值QPS:假设为均值3倍,则Max QPS = 3 * QPS = 345 QPS
- 每个用户平均每日阅读50篇推文,则推文读取接口平均QPS为:DAU * 50 / (24 * 60 * 60) = 57 QPS,峰值171 QPS
- 每个用户平均发3篇推文,则推文发送接口平均QPS为:DAU * 3 / (24 * 60 * 60) = 3.5 QPS,峰值10.5 QPS
- 同理可分析出日均存储数据量、月均及年均存储数据量等指标
系统QPS及存储量级是系统的服务选型、存储选型的重要指标之一:
- 100QPS:一台普通服务器就够了,存储考虑MySQL等关系式数据库
- 1000QPS:几台中等服务器就够了,存储考虑MySQL或Redis等数据库
- 10万QPS:几十台中等服务器组成集群,存储考虑Redis进行缓存、MongoDB或MySQL存储数据
3.2.Service
有了核心的需求后,需要设计核心的服务及接口来实现这些需求:
- 用户登陆注册:UserService,接口:Login、Register等
- 推文发送及查看:TwitterService,接口:PostTwitter、GetTwitter、FeedTwitter等
- 用户关注/取消关注:AccountService,接口:Follow、UnFollow、FollowUsers
核心服务关系:
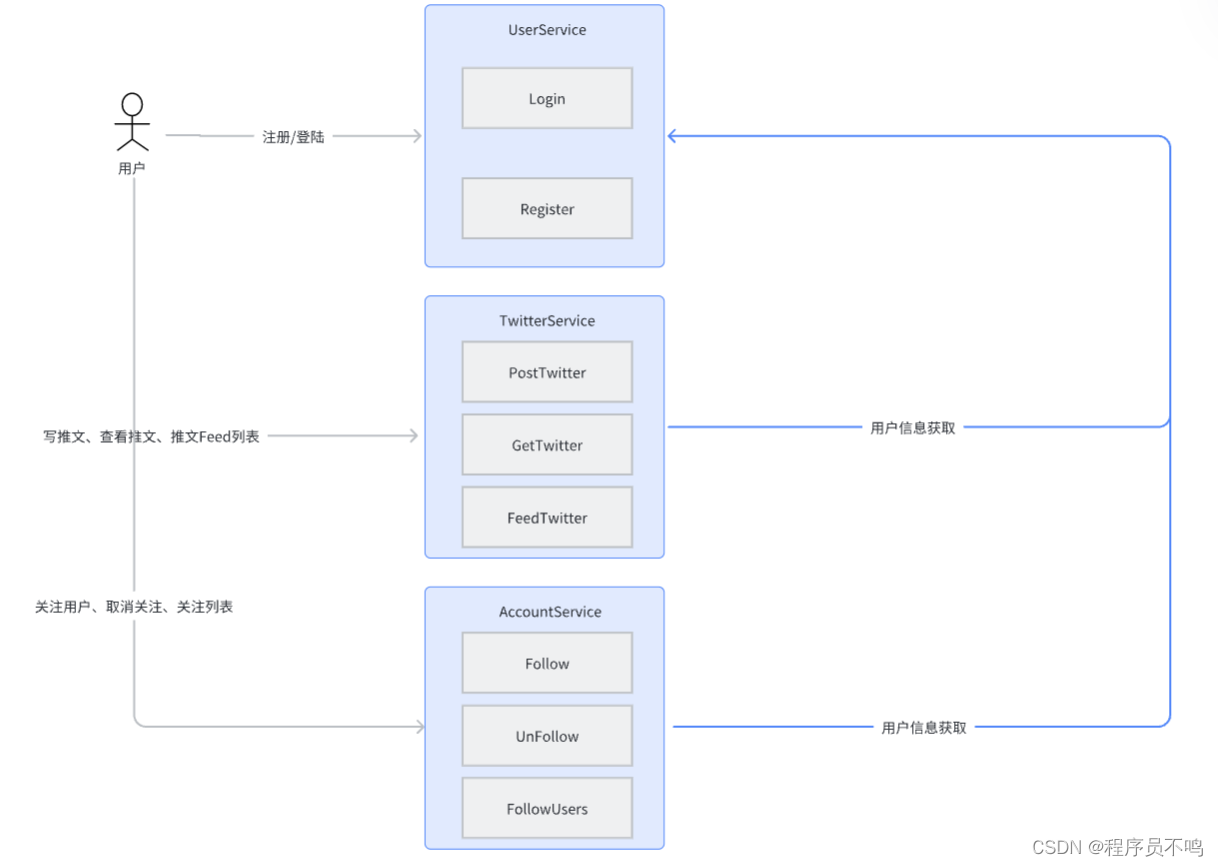
服务接口划分及聚合:对于接口功能上的不同应进行划分,划分出不同的服务来聚合这些接口,一个服务只提供相应的接口能力。
3.3.Storage
有了核心服务及核心接口后,需要考量如何存储及访问对应的数据:
- UserService:存储用户数据。
- 存储量级:当前DAU为10万,假设总用户量为DAU * 10,则总存储量级为百万级别
- 读写压力:该服务内外部都需要调用,会随着业务增长读写压力会被大量放大
- 可靠性要求:用户数据为系统最核心和关键的信息,不容许丢失
- 额外考量:需要有索引、事务支持,一致性要求高
- 数据库选型:选择常见的MySQL数据库
- TwitterService:存储推文数据。
- 存储量级:每个用户日均发送3篇推文,则年均存储量DUA * 3 * 30 * 12,量级为亿级别
- 额外考量:读QPS远大于写QPS,对于推特内容的读取一致性要求不是特别高,允许一定量的丢失
- 数据库选型:推文数据通常存储成文档形式,推文内容可存储至文档数据库MongoDB中,对应的媒体信息如图片、视频等可以采用对象存储数据库如Ceph、Hdfs等
选定存储系统后,设计对应的Scheme(存储格式或约束):
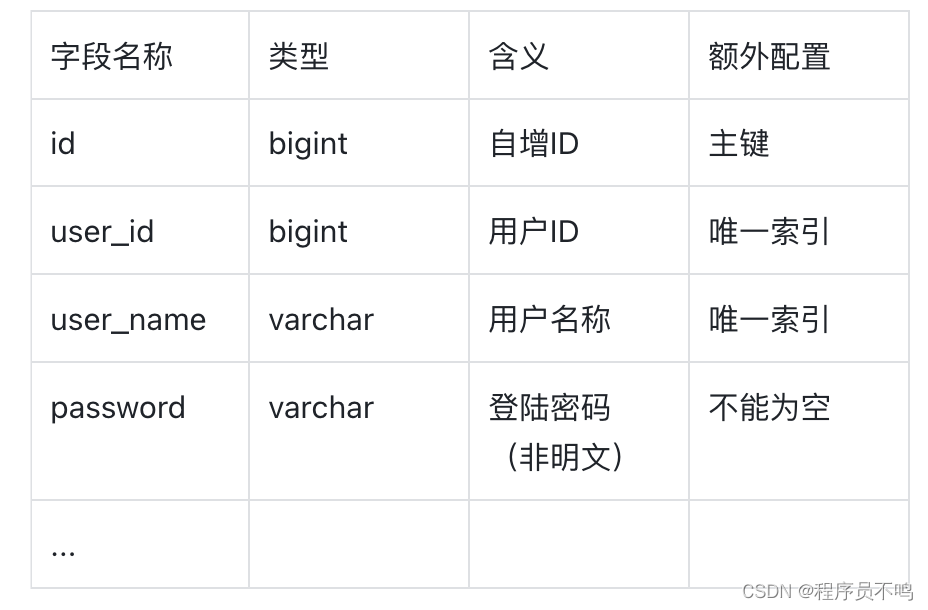
- UserService
- MySQL:User表
- TwitterService
- MongoDB:Twitters集合,每个文档Key为user_id,每个文档存储了用户发送的推文
[
{
'_id': 'xxxxxxxxx', // mongodb唯一文档id,也是推文唯一id
'title': '推文标题',
'content': '推文内容',
'create_time': 6161611717,
'modify_time': 6117171717
}
]
- Ceph/Hdfs:Media库,存储视频、图片等数据,Key为URL,值为对应的媒体内容序列化数据
3.4.Scale
设计完服务、接口及对应存储后,思考可能存在的一些问题及后续的可拓展性、可维护性及稳定性:
- User表使用MySQL作为数据库,当前为百万量级用户量,单库能力完全能承载,若后续用户量增长到千万甚至亿级,可考虑分库分表迁移
- 可拓展方面:MongoDB及Hdfs/Ceph天然支持水平拓展,无需考虑额外的分库分表
- 读写压力方面:考虑采用Redis作为缓存,减少打到MySQL的请求量
- 稳定性方面:对核心环节上报打点,对核心存储及服务设置监控告警,保障接口SLA X个9
- 降级限流措施:可考虑引入消息队列、断路器等实现流量平滑、非关键接口降级等,保障核心服务不被打挂