文章目录
- 概述
- KMeans
- KMeans参数&接口
- n_clusters
- 质心
- inertia
- 模型评估指标
- 轮廓系数
- Calinski-Harabaz Index
- 重要参数init & random_state & n_init:初始质心怎么放好?
- 重要参数max_iter & tol:让迭代停下来
- 重要属性与重要接口
概述
聚类 VS 分类
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-08cI8jam-1691915535493)(https://img1.imgtp.com/2023/08/12/TLpVN5O2.png)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Puxawm50-1691915535494)(https://img1.imgtp.com/2023/08/12/HAO6YrvZ.png)]
有监督学习 VS 无监督学习
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-BaTynru2-1691915535495)(https://img1.imgtp.com/2023/08/12/HKAWFoT5.png)]
sklearn中的聚类算法
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-x7TFKj9Y-1691915535495)(https://img1.imgtp.com/2023/08/12/R9mPETa6.png)]
KMeans
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-iECYm0e1-1691915535496)(https://img1.imgtp.com/2023/08/12/66yZOqS6.png)]
KMeans参数&接口
n_clusters
n_clusters就是KMeans中的K就是告诉模型,要让模型帮助我们分成几类,这个一般是我们必填的一个参数,sklearn中默认为8,通常我们希望这个数是小于8
生成数据
from sklearn.datasets import make_blobs
import matplotlib.pyplot as plt
#自己创建数据集
X, y = make_blobs(n_samples=500,n_features=2,centers=4,random_state=1)
fig, ax1 = plt.subplots(1)
ax1.scatter(X[:, 0], X[:, 1]
,marker='o' #点的形状
,s=8 #点的大小
)
plt.show()
#如果我们想要看见这个点的分布,怎么办?
color = ["red","pink","orange","gray"]
fig, ax1 = plt.subplots(1)
for i in range(4):
ax1.scatter(X[y==i, 0], X[y==i, 1]
,marker='o' #点的形状
,s=8 #点的大小
,c=color[i]
)
plt.show()
from sklearn.cluster import KMeans
cluster = KMeans(n_clusters=n_clusters, random_state=0).fit(X)
y_pred = cluster.labels_
y_pred
pre = cluster.fit_predict(X)
pre == y_pred
我们只先用一部分数据进行fit然后再predict得到的结果和我们用全部数据进行fit的结果是否相同
# 当数据量非常大的时候我们就需要用predict或者fit_predict()
cluster_smallsub = KMeans(n_clusters=n_clusters, random_state=0).fit(X[:200])
y_pred_ = cluster_smallsub.predict(X)
y_pred == y_pred_
当数据量比较小时结果可能不太好,当数据量比较大时效果比较好但是依然不会完全一样
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-g4q9gfb5-1691915535496)(https://img1.imgtp.com/2023/08/13/e8IE7cUI.png)]
质心
centroid = cluster.cluster_centers_
centroid
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-u2DbJWZB-1691915535496)(https://img1.imgtp.com/2023/08/13/uWuTeNL3.png)]
inertia
inertia = cluster.inertia_
inertia
返回总距离的平方和
color = ["red", "pink", "orange", "gray"]
fig, ax1 = plt.subplots(1)
for i in range(n_clusters):
ax1.scatter(X[y_pred == i, 0], X[y_pred == i, 1]
,marker='o' #点的形状
,s=8 #点的大小
,c=color[i] #点的颜色
)
ax1.scatter(centroid[:,0], centroid[:,1]
,marker='x' #点的形状
,s=8 #点的大小
,c="black" #点的颜色
)
plt.show()
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-WZfJ1PAi-1691915535497)(https://img1.imgtp.com/2023/08/13/kfHq0GvO.png)]
n_clusters = 4
cluster_ = KMeans(n_clusters=n_clusters, random_state=0).fit(X)
inertia_ = cluster_.inertia_
inertia_
结果:908.3855684760614
可以看到我们inertia的结果变小了
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-1C8GW9bM-1691915535497)(https://img1.imgtp.com/2023/08/13/qqJeJcj0.png)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-npyn7iwW-1691915535497)(https://img1.imgtp.com/2023/08/13/8tp8YV7U.png)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Ncw7uPbJ-1691915535498)(https://img1.imgtp.com/2023/08/13/5Ck4FssG.png)]
我们要inertia最小化的前提是在我们限制一个K的前提下最小化
模型评估指标
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-9pO3Hhjk-1691915535498)(https://img1.imgtp.com/2023/08/13/My2zUF0F.png)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-rCa8AE84-1691915535498)(https://img1.imgtp.com/2023/08/13/6C2vWwkH.png)]
轮廓系数
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-vkSjxKxe-1691915535499)(https://img1.imgtp.com/2023/08/13/gi5TFFRk.png)]
轮廓系数取值再在[-1, 1]越接近1越好
from sklearn.metrics import silhouette_score
from sklearn.metrics import silhouette_samples
silhouette_score(X, cluster_.labels_)
silhouette_samples(X, cluster_.labels_)
silhouette_score返回轮廓系数的均值
silhouette_samples返回每一个样本的轮廓系数
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-zJCdwpL8-1691915535499)(https://img1.imgtp.com/2023/08/13/dwiHrQYQ.png)]
Calinski-Harabaz Index
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-KSOXAeoi-1691915535499)(https://img1.imgtp.com/2023/08/13/gYDaXhS5.png)]
虽然Calinski-Harabaz Index没有界但是相较于轮廓系数而言,其计算快得多
from sklearn.metrics import calinski_harabaz_score
X
y_pred
calinski_harabaz_score(X, y_pred)
重要参数init & random_state & n_init:初始质心怎么放好?


X
y
plus = KMeans(n_clusters = 10).fit(X)
plus.n_iter_
random = KMeans(n_clusters = 10,init="random",random_state=420).fit(X)
random.n_iter_
重要参数max_iter & tol:让迭代停下来

random = KMeans(n_clusters = 10,init="random",max_iter=10,random_state=420).fit(X)
y_pred_max10 = random.labels_
silhouette_score(X,y_pred_max10)
random = KMeans(n_clusters = 10,init="random",max_iter=20,random_state=420).fit(X)
y_pred_max20 = random.labels_
silhouette_score(X,y_pred_max20)
一般当我们的数据量比较大的时候使用这两个参数可以让模型快一点停下来
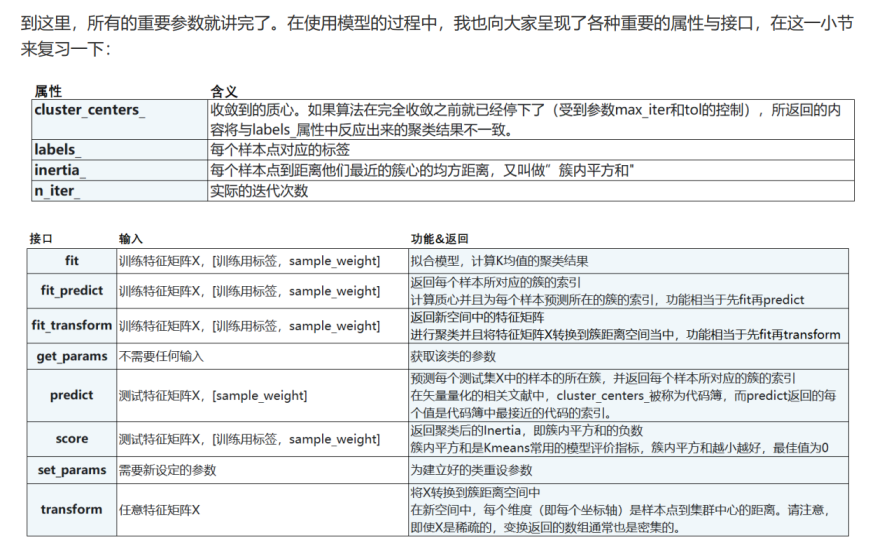
重要属性与重要接口


![[C++ 网络协议编程] TCP/IP协议](https://img-blog.csdnimg.cn/343ca3bde2004853a4bdf2ba96fdf2a2.png)