Reinforcement Learning with Code【Code 6. Advantage Actor-Critic(A2C)】
This note records how the author begin to learn RL. Both theoretical understanding and code practice are presented. Many material are referenced such as ZhaoShiyu’s Mathematical Foundation of Reinforcement Learning.
文章目录
- Reinforcement Learning with Code【Code 6. Advantage Actor-Critic(A2C)】
- 1. Actor-Criti's Various Forms
- 2. Review Advantage Actor-Critic (A2C)
- 3. A2C Code
- Reference
1. Actor-Criti’s Various Forms

2. Review Advantage Actor-Critic (A2C)
首先先了解传统的AC算法(详见 Reinforcement Learning with Code 【Chapter 10. Actor Critic】),A2C算法就是在传统的AC算法上增加了baseline减小了拟合的方差,正好这个增加的baseline是价值函 v π ( s ) v_\pi(s) vπ(s),那么就得到了优势函数的定义
δ
π
(
S
,
A
)
=
q
π
(
S
,
A
)
−
v
π
(
S
)
\textcolor{red}{\delta_\pi(S,A) = q_\pi(S,A) - v_\pi(S)}
δπ(S,A)=qπ(S,A)−vπ(S)
描述的是,在当前状态选择的动作,相比于平均状态值的优劣程度。完整的A2C算法可以参考Reinforcement Learning with Code 【Chapter 10. Actor Critic】


3. A2C Code
在实现A2C时,仍然采用gym中的CartPole-v1环境。
import gym
import torch
import torch.nn as nn
import torch.nn.functional as F
from tqdm import tqdm
import matplotlib.pyplot as plt
import numpy as np
# Policy Network
class PolicyNet(nn.Module):
def __init__(self, state_dim, hidden_dim, action_dim):
super(PolicyNet, self).__init__()
self.fc1 = nn.Linear(state_dim, hidden_dim)
self.fc2 = nn.Linear(hidden_dim, action_dim)
def forward(self, observation):
x = F.relu(self.fc1(observation))
return F.softmax(self.fc2(x), dim=1)
# State Value Network
class ValueNet(nn.Module):
def __init__(self, state_dim, hidden_dim):
super(ValueNet, self).__init__()
self.fc1 = nn.Linear(state_dim, hidden_dim)
self.fc2 = nn.Linear(hidden_dim, 1)
def forward(self, observation):
x = F.relu(self.fc1(observation))
return self.fc2(x)
# # Q Value Network
# class QValueNet(nn.Module):
# def __init__(self, state_dim, hidden_dim, action_dim):
# super(QValueNet,self).__init__()
# self.fc1 = nn.Linear(state_dim, hidden_dim)
# self.fc2 = nn.Linear(hidden_dim, action_dim)
# def forward(self, observation):
# x = F.relu(self.fc1(observation))
# return self.fc2(x)
# QAC & A2C
class ActorCritic():
def __init__(self, state_dim, hidden_dim, action_dim, actor_lr, critic_lr, gamma, ac_type, device):
self.ac_type = ac_type
if ac_type == "A2C":
self.critic = ValueNet(state_dim, hidden_dim).to(device)
elif ac_type == "QAC":
self.critic = QValueNet(state_dim, hidden_dim, action_dim).to(device)
self.actor = PolicyNet(state_dim, hidden_dim, action_dim).to(device)
self.actor_optimizer = torch.optim.Adam(self.actor.parameters(), lr=actor_lr)
self.critic_optimizer = torch.optim.Adam(self.critic.parameters(), lr=critic_lr)
self.gamma = gamma
self.device = device
def choose_action(self, state):
state = torch.tensor([state], dtype=torch.float).to(self.device)
probs = self.actor(state)
action_dist = torch.distributions.Categorical(probs)
action = action_dist.sample().item()
return action
def learn(self, transition_dict):
states = torch.tensor(transition_dict['states'], dtype=torch.float).to(self.device)
rewards = torch.tensor(transition_dict['rewards'], dtype=torch.float).view(-1,1).to(self.device)
actions = torch.tensor(transition_dict['actions'], dtype=torch.int64).view(-1,1).to(self.device)
next_states = torch.tensor(transition_dict['next_states'], dtype=torch.float).to(self.device)
dones = torch.tensor(transition_dict['dones'], dtype=torch.float).view(-1,1).to(self.device)
if self.ac_type == 'A2C':
td_target = rewards + self.gamma * self.critic(next_states) * (1-dones)
td_delta = td_target - self.critic(states)
log_probs = torch.log(self.actor(states).gather(dim=1, index=actions))
actor_loss = torch.mean(- log_probs * td_delta.detach())
critic_loss = torch.mean(F.mse_loss(td_target.detach(), self.critic(states)))
# elif self.ac_type == 'QAC':
# td_target = rewards + self.gamma * self.critic(next_states).gather(dim=1, index=actions) * (1-dones)
# td_delta = self.critic(states).gather(dim=1, index=actions)
# log_probs = torch.log(self.actor(states).gather(dim=1, index=actions))
# actor_loss = torch.mean(- log_probs * td_delta.detach())
# critic_loss = torch.mean(F.mse_loss(td_target, td_delta))
# clear gradient cumulation
self.actor_optimizer.zero_grad()
self.critic_optimizer.zero_grad()
# calculate gradient
actor_loss.backward()
critic_loss.backward()
# update parameters
self.actor_optimizer.step()
self.critic_optimizer.step()
def train_on_policy_agent(env, agent, num_episodes, seed):
return_list = []
for i in range(10):
with tqdm(total = int(num_episodes/10), desc="Iteration %d"%(i+1)) as pbar:
for i_episode in range(int(num_episodes/10)):
episode_return = 0
transition_dict = {
'states': [],
'actions': [],
'next_states': [],
'rewards': [],
'dones': []
}
observation, _ = env.reset(seed=seed)
done = False
while not done:
if render:
env.render()
action = agent.choose_action(observation)
observation_, reward, terminated, truncated, _ = env.step(action)
done = terminated or truncated
# save one episode experience into a dict
transition_dict['states'].append(observation)
transition_dict['actions'].append(action)
transition_dict['next_states'].append(observation_)
transition_dict['rewards'].append(reward)
transition_dict['dones'].append(done)
# swap state
observation = observation_
# compute one episode return
episode_return += reward
return_list.append(episode_return)
agent.learn(transition_dict)
if((i_episode + 1) % 10 == 0):
pbar.set_postfix({
'episode': '%d'%(num_episodes / 10 * i + i_episode + 1),
'return': '%.3f'%(np.mean(return_list[-10:]))
})
pbar.update(1)
env.close()
return return_list
def moving_average(a, window_size):
cumulative_sum = np.cumsum(np.insert(a, 0, 0))
middle = (cumulative_sum[window_size:] - cumulative_sum[:-window_size]) / window_size
r = np.arange(1, window_size-1, 2)
begin = np.cumsum(a[:window_size-1])[::2] / r
end = (np.cumsum(a[:-window_size:-1])[::2] / r)[::-1]
return np.concatenate((begin, middle, end))
def plot_curve(return_list, mv_return, algorithm_name, env_name):
episodes_list = list(range(len(return_list)))
plt.plot(episodes_list, return_list, c='gray', alpha=0.6)
plt.plot(episodes_list, mv_return)
plt.xlabel('Episodes')
plt.ylabel('Returns')
plt.title('{} on {}'.format(algorithm_name, env_name))
plt.show()
if __name__ == "__main__":
# reproducible
seed_number = 0
np.random.seed(seed_number)
torch.manual_seed(seed_number)
num_episodes = 1000 # episodes length
hidden_dim = 256 # hidden layers dimension
gamma = 0.98 # discounted rate
device = torch.device('cuda' if torch.cuda.is_available() else 'gpu')
env_name = 'CartPole-v1'
ac_type = 'A2C' # Actor-Critic Type: QAC or A2C
# Attention Learning Rate Is Important
actor_lr = 1e-3 # learning rate of actor
if ac_type == 'A2C':
critic_lr = 1e-2 # learning rate of critic
# elif ac_type == 'QAC':
# critic_lr = 1e-3
render = False
if render:
env = gym.make(id=env_name, render_mode='human')
else:
env = gym.make(id=env_name)
state_dim = env.observation_space.shape[0]
action_dim = env.action_space.n
agent = ActorCritic(state_dim, hidden_dim, action_dim, actor_lr, critic_lr, gamma, ac_type, device)
return_list = train_on_policy_agent(env, agent, num_episodes, seed_number)
mv_return = moving_average(return_list, 9)
plot_curve(return_list, mv_return, ac_type, env_name)
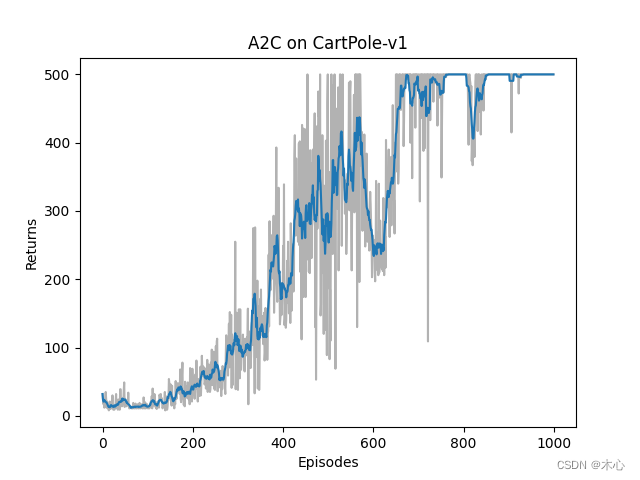
最终的学习曲线如图所示
Reference
赵世钰老师的课程
Hands on RL
Reinforcement Learning with Code 【Chapter 10. Actor Critic】