西姆兰吉特·辛格
一、介绍
欢迎来到“机器学习终极指南”的第二部分。在第一部分中,我们讨论了探索性数据分析 (EDA),这是机器学习管道中的关键步骤。在这一部分中,我们将深入研究特征工程,这是机器学习过程的另一个重要方面。
特征工程是将原始数据转换为有意义的特征的过程,机器学习算法可以使用这些特征进行准确的预测。它涉及选择、提取和转换特征以增强模型的性能。良好的特征工程会对模型的准确性产生巨大影响,而糟糕的特征工程会导致性能不佳。

图例.1 — 特征工程
在本指南中,我们将介绍特征工程中常用的一系列技术。我们将从特征选择和提取开始,这涉及识别数据中最重要的特征。然后,我们将继续对分类变量进行编码,这是处理非数值数据时必不可少的步骤。我们还将介绍缩放和归一化、创建新特征、处理不平衡数据、处理偏度和峰度、处理稀有类别、处理时间序列数据、特征转换、独热编码、计数和频率编码、分箱、分组和文本预处理。
在本指南结束时,您将全面了解特征工程技术以及如何使用它们来提高机器学习模型的性能。让我们开始吧!
目录
- 特征选择和提取
- 编码分类变量
- 缩放和规范化
- 创建新功能
- 处理不平衡的数据
- 处理偏度和峰度
- 处理稀有类别
- 处理时间序列数据
- 文本预处理
二、特征选择和提取
特征选择和提取是机器学习的重要组成部分,涉及从数据集中选择最相关的特征以提高模型的准确性和效率。在这里,我们将讨论一些流行的功能选择和提取方法,以及 Python 代码片段。
2.1. 主成分分析 (PCA):PCA
是一种降维技术,它通过查找一组捕获数据中最大方差的新特征来减少数据集中的特征数量。新要素称为主成分,彼此正交,可用于重建原始数据集。
让我们看看如何使用scikit-learn对数据集执行PCA:
from sklearn.decomposition import PCA
# create a PCA object
pca = PCA(n_components=2)
# fit and transform the data
X_pca = pca.fit_transform(X)
# calculate the explained variance ratio
print("Explained variance ratio:", pca.explained_variance_ratio_)在这里,我们创建一个 PCA 对象并指定要提取的组件数。然后,我们拟合并转换数据以获得新的特征集。最后,我们计算解释的方差比率,以确定每个主成分捕获的数据方差量。
2. 2 线性判别分析(LDA):
LDA是一种监督学习技术,用于分类问题中的特征提取。它的工作原理是查找一组新的特征,以最大程度地分离数据中的类。
让我们看看如何使用scikit-learn对数据集执行LDA:
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis
# create an LDA object
lda = LinearDiscriminantAnalysis(n_components=1)
# fit and transform the data
X_lda = lda.fit_transform(X, y)在这里,我们创建一个 LDA 对象并指定我们要提取的组件数。然后,我们拟合并转换数据以获得新的特征集。
3. 相关性分析:相关性分析用于识别数据集中特征之间的相关性。可以从数据集中移除彼此高度相关的要素,因为它们提供了冗余信息。
让我们看看如何使用熊猫对数据集执行相关性分析:
import pandas as pd
# calculate the correlation matrix
corr_matrix = df.corr()
# select highly correlated features
high_corr = corr_matrix[abs(corr_matrix) > 0.8]
# drop highly correlated features
df = df.drop(high_corr.columns, axis=1) 在这里,我们使用熊猫计算相关矩阵并选择高度相关的特征。然后,我们使用该方法从数据集中删除高度相关的特征。drop
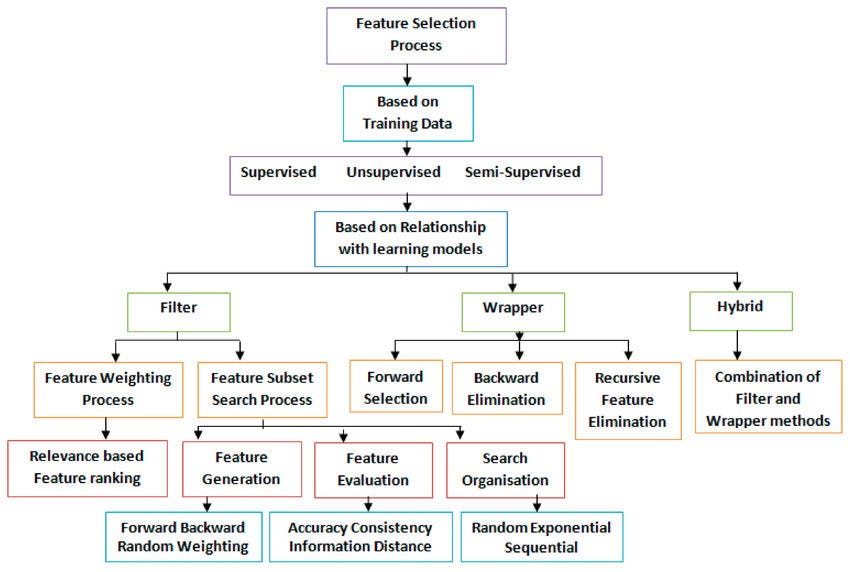
图2 — 特征选择措施
4. 递归特征消除(RFE):RFE是一种通过递归考虑越来越小的特征子集来选择特征的方法。在每次迭代中,都会根据其余特征对模型进行训练,并对每个特征的重要性进行排名。然后消除最不重要的特征,并重复该过程,直到获得所需数量的特征。
下面是使用 RFE 进行要素选择的示例:
from sklearn.feature_selection import RFE
from sklearn.linear_model import LinearRegression
from sklearn.datasets import load_boston
data = load_boston()
X, y = data.data, data.target
model = LinearRegression()
rfe = RFE(model, n_features_to_select=5)
rfe.fit(X, y)
selected_features = data.feature_names[rfe.support_]
print(selected_features)5. 基于树的方法:决策树和随机森林是用于此目的的流行的基于树的方法。在这些方法中,基于对预测目标变量最重要的特征创建树结构。每个特征的重要性是通过根据该特征拆分数据而导致的杂质减少来计算的。
在决策树中,选择信息增益最高的特征作为根节点,并根据该特征拆分数据。此过程以递归方式重复,直到满足停止条件,例如最大树深度或每片叶子的最小样本数。
在随机森林中,使用特征和数据的随机子集构建多个决策树。每个特征的重要性计算为所有树木中杂质的平均减少量。这有助于减少模型的方差并提高其泛化性。
from sklearn.ensemble import RandomForestRegressor
# Load the data
X, y = load_data()
# Create a random forest regressor
rf = RandomForestRegressor(n_estimators=100, random_state=42)
# Fit the model
rf.fit(X, y)
# Get feature importances
importances = rf.feature_importances_
# Print feature importances
for feature, importance in zip(X.columns, importances):
print(feature, importance)基于树的方法也可用于特征提取。在这种情况下,我们可以根据树的决策边界提取新特征。例如,我们可以将决策树的叶节点用作新的二进制特征,指示数据点是否属于特征空间的该区域。
6. 包装方法:这是一种特征选择方法,其中模型在不同的特征子集上进行训练和评估。针对每个特征子集测量模型的性能,并根据模型的性能选择最佳子集。
下面是如何在scikit-learn中使用递归特征消除(RFE)和支持向量机(SVM)分类器实现包装器方法的示例:
from sklearn.svm import SVC
from sklearn.feature_selection import RFE
from sklearn.datasets import load_iris
# load the iris dataset
data = load_iris()
X = data.data
y = data.target
# create an SVM classifier
svm = SVC(kernel='linear')
# create a feature selector using RFE with SVM
selector = RFE(svm, n_features_to_select=2)
# fit the selector to the data
selector.fit(X, y)
# print the selected features
print(selector.support_)
print(selector.ranking_) 在此示例中,我们首先加载鸢尾花数据集并将其拆分为特征 (X) 和目标 (y)。然后我们创建一个带有线性内核的 SVM 分类器。然后,我们使用 RFE 和 SVM 创建一个特征选择器,并将其拟合到数据中。最后,我们使用选择器的 and 属性打印所选特征。support_ranking_
前向选择: 前向选择是一种包装方法,它涉及一次迭代地向模型添加一个特征,直到模型的性能停止提高。以下是它在Python中的工作方式:
from sklearn.feature_selection import SequentialFeatureSelector
from sklearn.linear_model import LinearRegression
# Load the dataset
X, y = load_dataset()
# Initialize the feature selector
selector = SequentialFeatureSelector(LinearRegression(), n_features_to_select=5, direction='forward')
# Fit the feature selector
selector.fit(X, y)
# Print the selected features
print(selector.support_)在上面的代码中,我们首先加载数据集,然后使用线性回归模型和指定我们要选择的特征数量的参数n_features_to_select初始化 SequentialFeatureSelector 对象。然后,我们将选择器拟合到数据集上并打印所选特征。
向后淘汰: 向后消除是一种包装器方法,它涉及一次从模型中迭代删除一个特征,直到模型的性能停止提高。以下是它在Python中的工作方式:
from sklearn.feature_selection import SequentialFeatureSelector
from sklearn.linear_model import LinearRegression
# Load the dataset
X, y = load_dataset()
# Initialize the feature selector
selector = SequentialFeatureSelector(LinearRegression(), n_features_to_select=5, direction='backward')
# Fit the feature selector
selector.fit(X, y)
# Print the selected features
print(selector.support_)在上面的代码中,我们使用线性回归模型和参数 direction='backward' 初始化 SequentialFeatureSelector 对象以执行向后消除。然后,我们将选择器拟合到数据集上并打印所选特征。
详尽搜索: 穷举搜索是一种过滤方法,涉及评估所有可能的特征子集并根据评分标准选择最佳子集。以下是它在Python中的工作方式:
from itertools import combinations
from sklearn.metrics import r2_score
from sklearn.linear_model import LinearRegression
# Load the dataset
X, y = load_dataset()
# Initialize variables
best_score = -float('inf')
best_features = None
# Loop over all possible subsets of features
for k in range(1, len(X.columns) + 1):
for subset in combinations(X.columns, k):
# Train a linear regression model
X_subset = X[list(subset)]
model = LinearRegression().fit(X_subset, y)
# Compute the R2 score
score = r2_score(y, model.predict(X_subset))
# Update the best subset of features
if score > best_score:
best_score = score
best_features = subset
# Print the best subset of features
print(best_features)在上面的代码中,我们首先加载数据集,然后使用 itertools.combination 函数遍历所有可能的特征子集。对于每个子集,我们训练线性回归模型并计算 R2 分数。然后,我们根据最高 R2 分数更新最佳特征子集并打印所选特征。
7. 嵌入式方法:这些方法涉及选择特征作为模型训练过程的一部分。示例包括套索回归和岭回归,它们为损失函数添加惩罚项以鼓励稀疏特征选择。
套索回归: 套索回归还向损失函数添加了一个惩罚项,但它使用模型系数的绝对值而不是平方。这导致了更积极的特征选择过程,因为某些系数可以精确地设置为零。套索回归在处理高维数据时特别有用,因为它可以有效地减少模型中使用的特征数量。
from sklearn.linear_model import Lasso
from sklearn.datasets import load_boston
from sklearn.preprocessing import StandardScaler
data = load_boston()
X = data.data
y = data.target
# Standardize the features
scaler = StandardScaler()
X = scaler.fit_transform(X)
# Fit the Lasso model
lasso = Lasso(alpha=0.1)
lasso.fit(X, y)
# Get the coefficients
coefficients = lasso.coef_岭回归: 岭回归为损失函数添加一个惩罚项,鼓励模型选择对预测目标变量更重要的较小特征集。惩罚项与模型系数大小的平方成正比,因此它倾向于将系数缩小到零,而不将它们精确地设置为零。
from sklearn.linear_model import Ridge
from sklearn.datasets import load_boston
from sklearn.preprocessing import StandardScaler
data = load_boston()
X = data.data
y = data.target
# Standardize the features
scaler = StandardScaler()
X = scaler.fit_transform(X)
# Fit the Ridge model
ridge = Ridge(alpha=0.1)
ridge.fit(X, y)
# Get the coefficients
coefficients = ridge.coef_ 在这两种情况下,正则化参数控制惩罚项的强度。较高的 alpha 值将导致要素选择更稀疏。alpha
2.3 编码分类变量
编码分类变量是特征工程中的关键步骤,涉及将分类变量转换为机器学习算法可以理解的数字形式。以下是用于编码分类变量的一些常用技术:
1. 独热编码:
独热编码是一种将分类变量转换为一组二进制特征的技术,其中每个特征对应于原始变量中的唯一类别。在此技术中,为每个类别创建一个新的二进制列,如果类别存在,则值设置为 1,如果不存在,则设置为 0。
下面是一个使用熊猫库的示例:
import pandas as pd
# create a sample dataframe
df = pd.DataFrame({
'color': ['red', 'blue', 'green', 'red', 'yellow', 'blue']
})
# apply one-hot encoding
one_hot_encoded = pd.get_dummies(df['color'])
print(one_hot_encoded)2. 标签编码:
标签编码是一种为原始变量中的每个类别分配唯一数值的技术。在此技术中,为每个类别分配一个数字标签,其中标签是根据变量中类别的顺序分配的。
下面是一个使用 scikit-learn 库的示例:
from sklearn.preprocessing import LabelEncoder
# create a sample dataframe
df = pd.DataFrame({
'color': ['red', 'blue', 'green', 'red', 'yellow', 'blue']
})
# apply label encoding
label_encoder = LabelEncoder()
df['color_encoded'] = label_encoder.fit_transform(df['color'])
print(df)
图 3 — 编码数据
3. 序数编码:
序号编码是一种根据原始变量中每个类别的顺序或等级为其分配数值的技术。在此技术中,类别根据特定条件进行排序,并根据类别在顺序中的位置分配数值。
下面是使用 category_encoders 库的示例:
import category_encoders as ce
# create a sample dataframe
df = pd.DataFrame({
'size': ['S', 'M', 'L', 'XL', 'M', 'S']
})
# apply ordinal encoding
ordinal_encoder = ce.OrdinalEncoder(cols=['size'], order=['S', 'M', 'L', 'XL'])
df = ordinal_encoder.fit_transform(df)
print(df)三、缩放和规范化
缩放和规范化是特征工程中的重要步骤,可确保特征具有相似的比例和相似的范围。这有助于提高某些机器学习算法的性能,并使优化过程更快。下面是用于缩放和规范化的一些常用技术:
1. 标准化:标准化对特征进行缩放,使其具有零均值和单位方差。这是通过从每个值中减去平均值,然后将其除以标准差来完成的。结果值的平均值为 <>,标准差为 <>。
以下是使用scikit-learn进行标准化的示例:
from sklearn.preprocessing import StandardScaler
# Create a StandardScaler object
scaler = StandardScaler()
# Fit and transform the data
X_scaled = scaler.fit_transform(X)2. 最小-最大缩放:最小-最大缩放将要素缩放到固定范围,通常在 0 到 1 之间。这是通过从每个值中减去最小值,然后除以范围来完成的。
以下是使用 scikit-learn 进行最小-最大缩放的示例:
from sklearn.preprocessing import MinMaxScaler
# Create a MinMaxScaler object
scaler = MinMaxScaler()
# Fit and transform the data
X_scaled = scaler.fit_transform(X)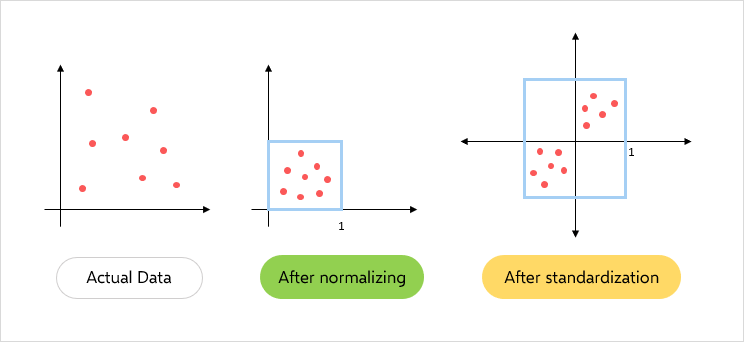
图例.4 — 标准化和规范化
3. 稳健缩放:稳健缩放类似于标准化,但它使用中位数和四分位数范围而不是平均值和标准偏差。这使得它对数据中的异常值更加可靠。
下面是一个使用 scikit-learn 进行健壮扩展的示例:
from sklearn.preprocessing import RobustScaler
# Create a RobustScaler object
scaler = RobustScaler()
# Fit and transform the data
X_scaled = scaler.fit_transform(X)4. 归一化:归一化将每个观测值缩放为具有单位范数,这意味着每个特征值的平方和为 1。这对于某些需要对所有样本具有相似比例的算法非常有用。
下面是一个使用 scikit-learn 进行规范化的示例:
from sklearn.preprocessing import Normalizer
# Create a Normalizer object
scaler = Normalizer()
# Fit and transform the data
X_scaled = scaler.fit_transform(X)四、创建新要素
创建新特征是特征工程中的重要步骤,涉及从现有数据创建新变量或列。这有助于捕获特征之间的复杂关系并提高模型的准确性。
以下是创建新要素的一些技术:
1. 交互特征:通过将两个或多个现有特征相乘来创建交互特征。这有助于捕获要素的联合效应并发现数据中的新模式。例如,如果我们有两个特征,“年龄”和“收入”,我们可以通过将这两个特征相乘来创建一个名为“age_income”的新交互特征。
以下是在 Python 中使用 Pandas 创建交互功能的示例:
import pandas as pd
# create a sample data frame
data = pd.DataFrame({'age': [25, 30, 35],
'income': [50000, 60000, 70000]})
# create a new interaction feature
data['age_income'] = data['age'] * data['income']
# display the updated data frame
print(data)2. 多项式特征:多项式特征是通过将现有特征提高到更高的幂来创建的。这有助于捕获特征之间的非线性关系并提高模型的精度。例如,如果我们有一个特征“age”,我们可以通过对这个特征进行平方来创建一个名为“age_squared”的新多项式特征。
以下是在Python中使用Scikit-learn创建多项式特征的示例:
from sklearn.preprocessing import PolynomialFeatures
import numpy as np
# create a sample data set
X = np.array([[1, 2],
[3, 4]])
# create polynomial features up to degree 2
poly = PolynomialFeatures(degree=2)
X_poly = poly.fit_transform(X)
# display the updated feature matrix
print(X_poly)3. 分箱:分箱涉及将连续值分组为离散类别。这有助于捕获非线性关系并减少数据中异常值的影响。例如,如果我们有一个特征“age”,我们可以通过将年龄分组为不同的类别(例如“0-18”、“18-25”、“25-35”、“35-50”和“50+”)来创建一个名为“age_group”的新分箱特征。
以下是在 Python 中使用 Pandas 创建分箱功能的示例:
import pandas as pd
# create a sample data frame
data = pd.DataFrame({'age': [20, 25, 30, 35, 40, 45, 50, 55]})
# create bins for different age groups
bins = [0, 18, 25, 35, 50, float('inf')]
labels = ['0-18', '18-25', '25-35', '35-50', '50+']
data['age_group'] = pd.cut(data['age'], bins=bins, labels=labels)
# display the updated data frame
print(data)五、处理不平衡数据
处理不平衡的数据是机器学习的一个重要方面。不平衡数据是指目标变量的分布不均匀,并且与另一个类相比,一个类的代表性不足。这可能导致模型中偏向多数类,并且模型在少数类上的表现可能很差。处理不平衡数据的一些技术是:
1. 上采样:上采样涉及通过对现有样本进行替换重新采样,为少数类创建更多样本。这可以使用模块中的函数来完成。resamplesklearn.utils
from sklearn.utils import resample
# Upsample minority class
X_upsampled, y_upsampled = resample(X_minority, y_minority, replace=True, n_samples=len(X_majority), random_state=42) 2. 缩减采样:缩减采样涉及从多数类中删除一些样本以平衡分布。这可以使用模块中的函数来完成。resamplesklearn.utils
from sklearn.utils import resample
# Downsample majority class
X_downsampled, y_downsampled = resample(X_majority, y_majority, replace=False, n_samples=len(X_minority), random_state=42)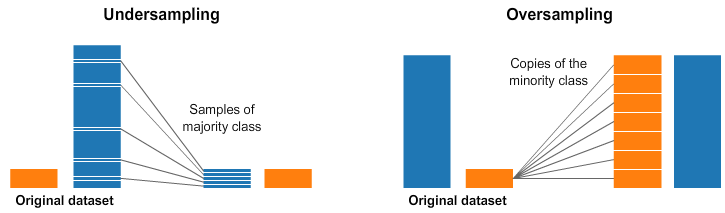
图 4 — 欠采样和过采样
3. 合成少数过采样技术 (SMOTE):SMOTE 涉及基于现有样本为少数类创建合成样本。这可以使用模块中的函数来完成。SMOTEimblearn.over_sampling
from imblearn.over_sampling import SMOTE
# Use SMOTE to upsample minority class
sm = SMOTE(random_state=42)
X_resampled, y_resampled = sm.fit_resample(X, y) 4. 类加权:类加权涉及为模型中的每个类分配一个权重以解决不平衡。这可以使用模型中的参数来完成。class_weight
from sklearn.linear_model import LogisticRegression
# Use class weighting to handle imbalance
clf = LogisticRegression(class_weight='balanced', random_state=42)
clf.fit(X_train, y_train) 5. 异常检测:异常检测涉及识别数据中的异常值并将其删除。这可以使用模块中的函数来完成。异常检测可识别数据集中明显偏离预期或正常行为的罕见事件或观测值。对于不平衡数据,其中一个类中的观测值数量远低于另一个类,则异常检测可用于识别少数类中的罕见观测值并将其标记为异常。这有助于平衡数据集并提高机器学习模型的性能。IsolationForestsklearn.ensemble
在不平衡数据中进行异常检测的一种常见方法是使用无监督学习技术,例如聚类,其中少数类观察根据其相似性聚类为不同的组。少数类中不属于任何这些聚类的观测值可以标记为异常。
另一种方法是使用监督学习技术,例如单类分类,其中模型在多数类数据上训练以学习数据的正常行为。然后,明显偏离学习正常行为的少数类观察结果被标记为异常。
from sklearn.ensemble import IsolationForest
# Use anomaly detection to handle imbalance
clf = IsolationForest(random_state=42)
clf.fit(X_train)
X_train = X_train[clf.predict(X_train) == 1]
y_train = y_train[clf.predict(X_train) == 1] 6. 成本敏感学习:成本敏感学习涉及为模型中的每种类型的错误分配不同的成本以解释不平衡。这可以使用模型中的参数来完成。sample_weight
from sklearn.tree import DecisionTreeClassifier
# Use cost-sensitive learning to handle imbalance
clf = DecisionTreeClassifier(random_state=42)
clf.fit(X_train, y_train, sample_weight=class_weights)