文章目录
- Faker介绍
- Faker安装
- Faker使用
- 基本使用方法
- 随机生成人物相关的基础信息
- 随机生成地理相关的信息
- 随机生成网络相关的信息
- 随机生成日期相关的信息
- 随机生成数字/字符串/文本
- 随机生成列表/元组/字典/集合/迭代器/json
- 随机生成文件相关的信息
- 随机生成颜色/表情
- 每次请求获取相同的数据
- Faker的应用
- 结合pymysql库将数据插入到数据库中
- 结合openpyxl库将数据导出到Excel中
- 在Pytest中使用Faker随机生成入参
Faker介绍
在软件测试过程中,我们经常需要使用一些测试数据,通常都是只能使用已有的系统数据,但可能会因权限或其它原因不可使用,又或者手工编造一些数据,但数据量较大时影响测试效率,Faker就解决这个问题,Faker是python的一个第三方库,主要是用来创造伪数据的,只需要调用Faker提供的相关api即可完成数据的生成
Faker安装
pip install faker
Faker使用
-
基本使用方法
from faker import Faker # 导入faker库的Faker方法 # ↓默认为en_US,只有使用了相关语言才能生成相对应的随机数据 fk=Faker(locale="zh_CN") # ↓也可使用多种语言 # fk = Faker(["zh_CN", "en_US", "zh_TW"]) # ↓随机生成姓名+身份ID +手机号,因为已指定locale为中文,所以生成的数据都是符合中国环境的数据 for i in range(10): print(fk.name() + "," + fk.ssn() + "," + fk.phone_number()) -
随机生成人物相关的基础信息
print("随机生成一个姓:", fk.last_name()) print("随机生成一个女性常用姓:", fk.last_name_female()) print("随机生成一个男性常用姓:", fk.last_name_male()) print("随机生成一个名:", fk.first_name()) print("随机生成一个女性常用名:", fk.first_name_female()) print("随机生成一个男性常用名:", fk.first_name_male()) print("随机生成一个姓名:", fk.name()) print("随机生成一个罗马文的姓名(当英文使用):", fk.romanized_name()) print("随机生成一个女性全名:", fk.name_female()) print("随机生成一个男性全名:", fk.name_male()) print("随机生成一个手机号号段:", fk.phonenumber_prefix()) print("随机生成一个手机号:", fk.phone_number()) print("随机生成一个的身份ID:", fk.ssn()) print("随机生成一个生日日期:", fk.date_of_birth()) print("随机生成一个生日日期(20~30岁之间):", fk.date_of_birth(minimum_age=20, maximum_age=30)) print("随机生成一个信用卡号:", fk.credit_card_number()) print("随机生成一个完整的信用卡信息:", fk.credit_card_full()) print("随机生成一份简略的个人信息:", fk.simple_profile()) print("随机生成一份详细的个人信息:", fk.profile()) print("随机生成一个车牌号:", fk.license_plate()) print("随机获取一个银行名称:", fk.bank()) print("随机生成一个银行账号:", fk.bban()) print("随机获取一个国际银行账号:", fk.iban()) print("随机生成一个邮箱:", fk.email()) print("随机生成一个公司邮箱:", fk.company_email()) print("随机生成一个免费邮箱:", fk.free_email()) print("随机生成一个安全邮箱:", fk.safe_email()) print("随机生成一个邮箱后缀:", fk.free_email_domain()) print("随机生成一个完整的公司名称:", fk.company()) print("随机生成一个公司名:", fk.company_suffix()) print("随机生成一个公司性质:", fk.company_prefix()) print("随机生成一个职位名称:", fk.job()) -
随机生成地理相关的信息
print("随机生国际语言:", fk.language_name()) print("随机生成一个国家名称:", fk.country()) print("获取当前所在国家名称:", fk.current_country()) print("随机生成一个行政单位:", fk.administrative_unit()) print("随机生成一个省份:", fk.province()) print("随机生成一个城市:", fk.city()) print("随机生成一个城市名:", fk.city_name()) print("随机生成一个城市名的后缀(即市县区):", fk.city_suffix()) print("随机生成一个县/区:", fk.district()) print("随机生成一个街道名称:", fk.street_name()) print("随机生成一个街道名的后缀(即街路):", fk.street_suffix()) print("随机生成一个街道地址:", fk.street_address()) print("随机生成一个楼号:", fk.building_number()) print("随机生成一个详情地址:", fk.address()) print("随机生成一个邮编:", fk.postcode()) print("随机生成一个地理坐标(纬度):", fk.latitude()) print("随机生成一个地理坐标(经度):", fk.longitude()) -
随机生成网络相关的信息
print("随机生成一个域名:", fk.domain_name()) print("根据给定日期随机生成一个3位的域名:", fk.dga(year=2023, month=7, day=31, length=3)) print("随机生成一个IPv4地址:", fk.ipv4()) print("随机生成一个IPv6地址:", fk.ipv6()) print("随机生成一个端口:", fk.port_number()) print("随机生成一个MAC地址:", fk.mac_address()) print("随机生成一个网址文件路径:", fk.uri_path()) print("随机生成一个网址文件:", fk.uri_page()) print("随机生成一个网址文件后缀:", fk.uri_extension()) print("随机生成一个uri地址:", fk.uri()) print("随机生成一个url地址:", fk.url()) print("随机生成一个图片url地址:", fk.image_url()) print("随机生成一个域名后缀:", fk.tld()) print("随机生成一个用户名:", fk.user_name()) print("随机生成一个用户ID:", fk.uuid4()) print("随机生成一个HTTP请求方法:", fk.http_method()) print("随机生成一个user_agent:", fk.user_agent()) print("随机生成一个IOS的user_agent:", fk.ios_platform_token()) print("随机生成一个安卓的user_agent:", fk.android_platform_token()) print("随机生成一个Linux的user_agent:", fk.linux_platform_token()) print("随机生成一个Windows的user_agent:", fk.windows_platform_token()) print("随机生成一个MAC的user_agent:", fk.mac_platform_token()) print("随机生成一个IE的user_agent:", fk.internet_explorer()) print("随机生成一个Firefox的user_agent:", fk.firefox()) print("随机生成一个Opera的user_agent:", fk.opera()) print("随机生成一个Safari的user_agent:", fk.safari()) print("随机生成一个Chrome的user_agent:", fk.chrome()) # ↓指定随机生成一个Chrome的user_agent并指定浏览器版本范围 print(fk.chrome(version_from=95, version_to=116, build_from=5500, build_to=5800)) print("随机生成一个NIME类型:", fk.mime_type()) # ↓支持的类别:application/image/model/multipart/text/message/video/audio print("随机生成一个指定类别的NIME类型:", fk.mime_type(category="application")) print("随机生成Ture或False:", fk.boolean()) print("随机生成None、Ture或False:", fk.null_boolean()) print("随机生成Ture或False(25%概率为True):", fk.boolean(chance_of_getting_true=25)) print("随机生成一个密码:", fk.password()) print("随机生成一个12位的密码:", fk.password(length=12)) print("随机生成一个MD5:", fk.md5()) print("随机生成一个SHA1:", fk.sha1()) print("随机生成一个SHA256:", fk.sha256()) -
随机生成日期相关的信息
from datetime import date, datetime print("随机生成一个年份:", fk.year()) print("随机生成一个月份:", fk.month()) print("随机生成一个月份名称:", fk.month_name()) print("随机生成一个天数:", fk.day_of_month()) print("随机生成一个年月日:", fk.date()) print("指定格式随机生成一个年月日:", fk.date(pattern="%Y年%m月%d日")) print("随机生成一个星期数:", fk.day_of_week()) print("随机生成AM/PM:", fk.am_pm()) print("随机生成一个时间:", fk.time()) print("指定格式随机生成一个时间:", fk.time(pattern="%H:%M")) print("随机生产一个日期和时间:", fk.date_time()) print("随机生成过去某天:", fk.date_between()) print("指定范围内随机生成过去某天(5年前~今天):", fk.date_between(start_date="-5y")) print("指定范围内随机生成过去某天(至30天前):", fk.date_between(end_date="-30d")) print("指定范围内随机生成某天(5天前~30天后):", fk.date_between(start_date="-5d", end_date="+30d")) print("使用date对象在指定范围内随机生成日期和时间:", fk.date_time_between_dates(datetime_start=date(2020, 6, 6), datetime_end=date(2023, 8, 8))) print("使用datetime对象在指定范围内随机生成日期和时间:", fk.date_time_between_dates(datetime_start=datetime(2020, 6, 6, 9, 30, 20), datetime_end=datetime(2023, 8, 8, 10, 30, 50))) print("随机生成未来某天:", fk.future_date()) print("随机生成未来某个日期和时间:", fk.future_datetime()) print("随机生成未来30天内的某个日期:", fk.future_date(end_date="+30d")) print("随机生成未来30天内的某个日期和时间:", fk.future_datetime(end_date="+30d")) print("随机生成过去某天:", fk.past_date()) print("随机生成过去某个日期和时间:", fk.past_datetime()) print("随机生成过去5年内的日期:", fk.past_date(start_date="-5y")) print("随机生成过去15天内的日期和时间:", fk.past_datetime(start_date="-15d")) print("获取今天的日期:", fk.date_between_dates()) print("获取今天的日期和时间:", fk.date_time_between_dates()) print("随机生成今年的某个月份:", fk.date_this_year()) print("随机生成一个早于当前时间的日期和时间(即过去的时间):", fk.date_time_this_year(before_now=True)) print("随机生成一个晚于当前时间的日期和时间(即未来的时间):", fk.date_time_this_year(after_now=True)) print("随机生成本月的某天:", fk.date_this_month()) print("随机生成unix时间戳:", fk.unix_time()) print("随机生成ISO8601时间戳:", fk.iso8601()) print("随机时区:", fk.timezone()) -
随机生成数字/字符串/文本
print("随机生整一个整数:", fk.pyint()) print("指定范围内随机生成一个奇数:", fk.pyint(min_value=1, max_value=10, step=2)) print("随机生成一个字符串:", fk.pystr()) print("随机生成一个带前缀和后缀的8位的字符串:", fk.pystr(min_chars=2, max_chars=8, prefix="dyd-", suffix="-123")) print("指定范围内随机生成一个奇数:", fk.pyint(min_value=1, max_value=10, step=2)) # ↓随机生成一个小数(整数部分3位,小数2位,只生成负数) print(fk.pyfloat(left_digits=3, right_digits=2, positive=False, min_value=1, max_value=10)) print("随机生成一个decimal数据:", fk.pydecimal()) # ↓随机生成一个1~10的decimal数据(整数部分3位,小数2位,只生成负数) print(fk.pydecimal(left_digits=3, right_digits=2, positive=False, min_value=1, max_value=10)) print("随机生成一组dict数据:", fk.pydict()) print("生成一个3位随机数:", fk.numerify()) print("生成一个指定位数的随机数:", fk.random_number(digits=5)) print("生成一个0-9的随机数:", fk.random_digit()) print("生成一个1-9的随机数:", fk.random_digit_not_null()) print("生成一个0-9999随机数:", fk.random_int()) print("指定范围内生成一个随机数:", fk.random_int(min=60, max=100)) print("随机生成一个字符(a~z小写):", fk.random_element()) print("指定字符内随机生成一个字符:", fk.random_element(elements=("a", "b", "1", "D"))) print("随机生成多个字符:", fk.random_elements()) print("指定字符内随机生成3个字符且元素不可重复:", fk.random_elements(elements=("a", "B", "c", "D"), unique=True, length=3)) print("随机生成一个ASCII字母(a~z大小写):", fk.random_letter()) print("随机生成一个长度为16的二进制编码:", fk.binary(length=16)) print("随机生成一个词语:", fk.word()) print("随机生成多个词语(默认3个):", fk.words()) print("指定范围内随机选择2个词语:", fk.words(ext_word_list=["啊", "哈哈", "gaga", "嘿嘿"], nb=2)) print("随机生成一条句子:", fk.sentence()) print("随机生成一条2个词组成的句子:", fk.sentence(nb_words=2)) print("指定范围内随机组合生成1句话:", fk.sentence(ext_word_list=["abc", "def", "ghi", "jkl"])) print("随机生成多条句子(默认3条):", fk.sentences()) print("指定范围内随机组合生成3句话:", fk.sentences(ext_word_list=["abc", "def", "ghi", "jkl"])) print("随机生成一个段落(默认3句):", fk.paragraph()) print("随机生成一个5句话的段落:", fk.paragraph(nb_sentences=5)) print("指定范围内随机组合生成3个段落:", fk.paragraph(ext_word_list=["abc", "def", "ghi", "jkl"])) print("随机生成多个段落(默认3个):", fk.paragraphs()) print("随机生成5个段落:", fk.paragraphs(nb=5)) print("指定范围内随机组合生成3个段落:", fk.paragraphs(ext_word_list=["abc", "def", "ghi", "jkl"])) print("随机生成一段文本:", fk.text()) print("随机生成160个字:", fk.text(max_nb_chars=160)) print("指定范围内随机组合生成80个字:", fk.text(ext_word_list=["abc", "def", "ghi", "jkl"], max_nb_chars=80)) -
随机生成列表/元组/字典/集合/迭代器/json
print("随机生成一组list数据:", fk.pylist()) # ↓随机生成一组指定数据类型的3组数据组成的list并指定允许使用的数据类型 print(fk.pylist(nb_elements=3, value_types=[int, str, tuple], allowed_types=[bool, str, float, int])) print("随机生成一组tuple数据:", fk.pytuple()) # ↓随机生成一组指定数据类型的2组数据组成的tuple并指定允许使用的数据类型 print(fk.pytuple(nb_elements=2, value_types=[str, float], allowed_types=[bool, str, float])) print("随机生成一组dict数据:", fk.pydict()) # ↓随机生成一组指定数据类型的3组数据组成的dict并指定允许使用的数据类型 print(fk.pydict(nb_elements=2, value_types=[int, str, list], allowed_types=[bool, str, float, int])) print("随机生成一组set数据:", fk.pyset()) # ↓随机生成一组指定数据类型的3组数据组成的set并指定允许使用的数据类型 print(fk.pyset(nb_elements=3, value_types=str, allowed_types=[bool, str, float])) print("随机生成一组iterable数据:", fk.pyiterable()) # ↓随机生成一组指定数据类型的3组数据组成的iterable并指定允许使用的数据类型 print(fk.pyiterable(nb_elements=3, value_types=[int, str], allowed_types=[int, str, float])) print("随机生成一份10组json数据组成的列表:", fk.json()) # ↓随机生成一份指定内容的1组json数据 print(fk.json( data_columns={"userId": "uuid4", "token": "md5", "Info": {"name": "user_name", "telephone": "phone_number"}}, num_rows=1)) # ↓随机生成一份指定内容的缩进为2的1组json数据 print(fk.json(data_columns={"userId": "uuid4", "Info": ["user_name", "ssn", "phone_number"]}, num_rows=1, indent=2)) # ↓随机生成一份指定内容的1组字节形式的json数据 print(fk.json_bytes(data_columns={"Info": ["uuid4", "user_name", "ssn", "phone_number"]}, num_rows=1)) # ↓随机生成3行name为20pyint为3的固定宽度的数据并居中对齐,默认left,可设置middle、right print(fk.fixed_width(data_columns=[(20, "name"), (3, "pyint", {"min_value": 80, "max_value": 120})], align="middle", num_rows=3)) -
随机生成文件相关的信息
# ↓随机生成3行带表头的有编号的以逗号分隔的数据 print(fk.csv(header=("姓名", "地址", "身份ID", "手机号"), data_columns=("{{name}}", "{{address}}", "{{ssn}}", "{{phone_number}}"), num_rows=3, include_row_ids=True)) # ↓随机生成5行带表头的无编号的以管道符分隔的数据 print(fk.psv(header=("员工编号", "员工姓名", "手机号"), data_columns=("{{random_number}}", "{{name}}", "{{phone_number}}"), num_rows=5, include_row_ids=False)) # ↓随机生成2行无编号的以制表符分隔的数据 print(fk.tsv(data_columns=("{{phone_number}}", "{{name}}", "{{ssn}}"), num_rows=2, include_row_ids=True)) # ↓随机生成3行无编号的以csv.excel分隔的数据,其实也是逗号分隔,只是数据无双引号 print( fk.dsv(dialect="excel", data_columns=("{{phone_number}}", "{{name}}", "{{ssn}}"), num_rows=3, include_row_ids=True)) # ↓随机生成3行无编号的以csv.excel分隔的数据,也是制表符分隔,只是数据无双引号 print(fk.dsv(dialect="excel-tab", data_columns=("{{phone_number}}", "{{name}}", "{{ssn}}"), num_rows=3, include_row_ids=True)) -
随机生成颜色/表情
print("随机生成一种颜色:", fk.color()) print("随机生成一种颜色:", fk.color_name()) # ↓支持的颜色选项:yellow/blue/orange/green/pink/purple/monochrome print("随机生成一种不同色调的红色:", fk.color(hue="red")) # ↓支持的亮度选项:light/dark/bright/random print("随机生成一种不同亮度的颜色:", fk.color(luminosity="light")) print("随机生成一个三元组颜色:", fk.hex_color()) print("随机生成一种RGB格式颜色色值:", fk.rgb_color()) print("随机生成一种CSS格式的RGB颜色色值:", fk.rgb_css_color()) print("随机生成一个安全色名称:", fk.safe_color_name()) print("随机生成一个安全色色值:", fk.safe_hex_color()) print("随机生成一个emoji表情:", fk.emoji())以上所有入参均可为空,类似功能的参数基本一致,未详尽之处请自行尝试
-
每次请求获取相同的数据
以上每个字段生成的数据都是随机的,但是了解编程的都明白计算机的这种随机只是一种伪随机,其随机性是可复现的,所以若想要每次生成的数据都是相同的,可通过固定住类方法的随机种子进而获得相同数据。在所需位置上方加上一条
Faker.seed(num)即可,使用seed(num)函数且给定同一个num值时,无论执行多少次获取随机数操作,得到的均为同一个数,比如:# 创建test1.py from faker import Faker fk = Faker(locale="zh_CN") print("随机生产一个日期和时间:", fk.date_time()) # 2003-07-08 04:23:08 Faker.seed(666) print("随机生成一个姓:", fk.last_name()) # 孙 print("随机生成一个女性常用姓:", fk.last_name_female()) # 鲁 print("随机生成一个男性常用姓:", fk.last_name_male()) # 周如上,每次请求的时间都会变更,而3个获取姓氏的结果都不会变,之后可通过使用
seed_instance()方法切换到自己的randomRandom实例,不影响test1.py的文件内容,比如:# 创建test2.py from faker import Faker fk = Faker(locale="zh_CN") print("随机生产一个日期和时间:", fk.date_time()) fk.seed_instance(666) print("随机生成一个姓:", fk.last_name()) # 孙 print("随机生成一个女性常用姓:", fk.last_name_female()) # 鲁 print("随机生成一个男性常用姓:", fk.last_name_male()) # 周 print("随机生成一个姓名:", fk.name())以上每次请求的时间都会变更,但3个获取姓氏的结果会与
test1.py中的结果一致,之后获取姓名的结果也会是固定数据 -
Faker的应用
-
结合pymysql库将数据插入到数据库中
关于
pymysql的具体使用方法可通过查看官方文档了解,遇到个报错RuntimeError: 'cryptography' package is required for sha256_password or caching_sha2_password auth methods,意思是此两种加密方式需要cryptography包,所以执行命令pip install cryptography安装即可# 创建test3.py import pymysql.cursors from faker import Faker fk = Faker(locale="zh_CN") class SQLFaker(): def __init__(self): try: self.db = pymysql.connect( # 连接数据库信息 host="192.166.66.45", port=3306, user='root', password="usTxxxxd&0", database="test", charset="utf8mb4") except pymysql.Error as e: print(f'连接数据库失败!{e}') self.cursor = self.db.cursor() # 使用cursor()方法创建一个游标对象,用于操作数据库 def createDabate(self): try: sql = """CREATE TABLE `employees` ( `userid` varchar(50) UNIQUE COMMENT '员工id', `ename` VARCHAR (50) NOT NULL COMMENT '姓名', `username` VARCHAR (20) NOT NULL COMMENT '用户名', `password` VARCHAR (50) NOT NULL COMMENT '登录密码', `gender` VARCHAR (50) DEFAULT '-1' COMMENT '1表示男,0表示女,-1表示未知', `IDNum` VARCHAR (50) NOT NULL UNIQUE COMMENT '身份ID', `phoneNum` VARCHAR (50) NOT NULL COMMENT '手机号码', `email` VARCHAR (50) COMMENT '邮箱', `birthday` DATE COMMENT '生日', `createtime` DATETIME COMMENT '创建时间' ) DEFAULT CHARSET = utf8mb4 COMMENT = '员工信息表'""" self.cursor.execute(sql) # 执行SQL语句,创建数据表 print("employees表创建成功!") except pymysql.Error as e: if str(e).split(",")[0] == "(1050": print("employees表已存在,将尝试直接插入数据!") else: print(f'创建数据表失败!{e}') # 否则抛出异常 def insertFakedata(self, num): try: for i in range(num): sql = """INSERT INTO `employees` VALUES('%s','%s','%s','%s','%s','%s','%s','%s','%s','%s')""" % ( fk.uuid4(), # 用户id fk.name(), # 用户姓名 fk.user_name(), # 用户名 fk.password(), # 密码 fk.random_int(min=-1, max=1), # 性别 fk.ssn(), # 身份ID fk.phone_number(), # 手机号码 fk.free_email(), # 邮箱 fk.date_of_birth(minimum_age=20, maximum_age=30) # 生日,20~30岁之间 fk.date_time_between_dates() # 创建时间 ) self.cursor.execute(sql) # 执行SQL语句,插入数据 self.db.commit() # 提交插入的数据,若缺少即使执行成功,数据库也不会显示数据 print(f"成功插入{num}条数据!") except pymysql.Error as e: print(f'插入数据失败!{e}') self.cursor.close() # 关闭游标对象 self.db.close() # 关闭数据库 if __name__ == '__main__': SQLFaker().createDabate() # 执行创建数据库 SQLFaker().insertFakedata(500) # 执行插入500条数据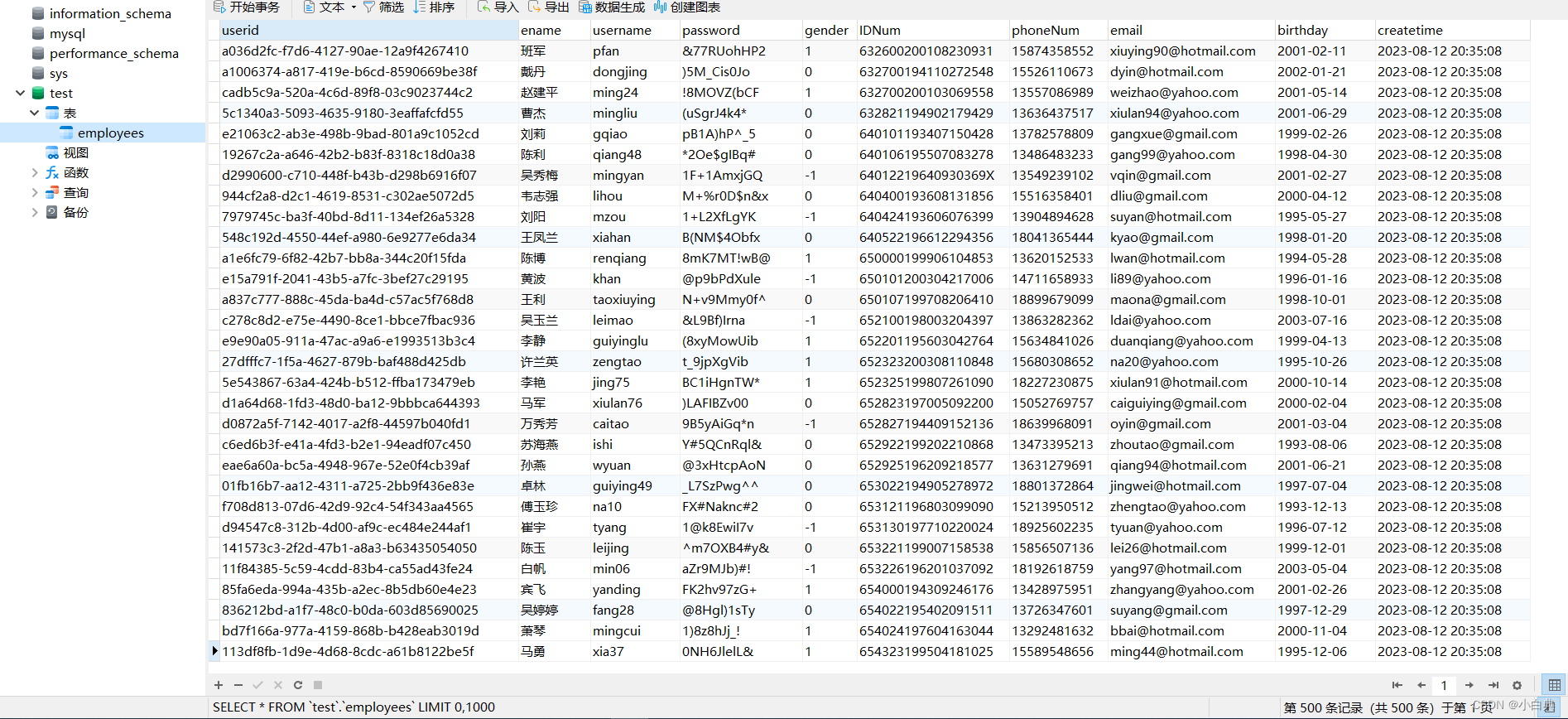
-
结合openpyxl库将数据导出到Excel中
# 创建test4.py from faker import Faker from openpyxl import load_workbook from openpyxl.styles import Font, PatternFill from openpyxl.utils import get_column_letter from openpyxl.styles.alignment import Alignment from openpyxl.styles.borders import Border, Side fk = Faker("zh_CN") def save_to_excel(): wb = load_workbook("E:/Fakerdata.xlsx") # 打开Excel文件 sheet = wb[wb.sheetnames[0]] # 选择表1 side = Side(style='thin', color="000000") # 设置单元格边框线条样式 # ↓配置标题信息 excel_header = ["编号", "姓名", "身份ID", "手机号", "邮箱", "所属公司", "是否在职"] for h in range(len(excel_header)): sheet.cell(row=1, column=h + 1, value=excel_header[h]) sheet.freeze_panes = "A2" # 冻结表头 # ↓设置标题背景色、字体样式、大小并垂直居中,通过将数字转换为字母获取设置的单元格 sheet[f"{get_column_letter(h + 1)}1"].font = Font(name=u"楷体", bold=True, size=13) sheet[f"{get_column_letter(h + 1)}1"].alignment = Alignment(horizontal="center", vertical="center") sheet[f"{get_column_letter(h + 1)}1"].border = Border(left=side, right=side, top=side, bottom=side) sheet[f"{get_column_letter(h + 1)}1"].fill = PatternFill(fill_type="solid", fgColor="FCFC0C") # 随机生成1000条数据,同时设置单元格样式 for i in range(1000): for h in range(len(excel_header)): id = fk.random_number(digits=5) # 随机生成5位数 name = fk.name() # 随机生成姓名 ssn = fk.ssn() # 随机生成身份ID phone = fk.phone_number() # 随机生成手机号 email = fk.email() # 随机生成邮箱 company = fk.company() # 随机生成公司名称 status = fk.words(ext_word_list=["在职", "已离职"], nb=1)[0] # 在指定两个字中随机选择一个 sheet.cell(row=i + 2, column=1, value=id) sheet.cell(row=i + 2, column=2, value=name) sheet.cell(row=i + 2, column=3, value=ssn) sheet.cell(row=i + 2, column=4, value=phone) sheet.cell(row=i + 2, column=5, value=email) sheet.cell(row=i + 2, column=6, value=company) sheet.cell(row=i + 2, column=7, value=status) # ↓设置生成内容的字体样式、大小并上下居中靠左对齐,通过将数字转换为字母获取设置的单元格 sheet[f"{get_column_letter(h + 1)}{i + 2}"].font = Font(name=u"宋体", size=11) sheet[f"{get_column_letter(h + 1)}{i + 2}"].alignment = Alignment(horizontal="left", vertical="center") sheet[f"{get_column_letter(h + 1)}{i + 2}"].border = Border(left=side, right=side, top=side, bottom=side) wb.save("E:/Fakerdata.xlsx") # 保存Excel文件 if __name__ == '__main__': save_to_excel()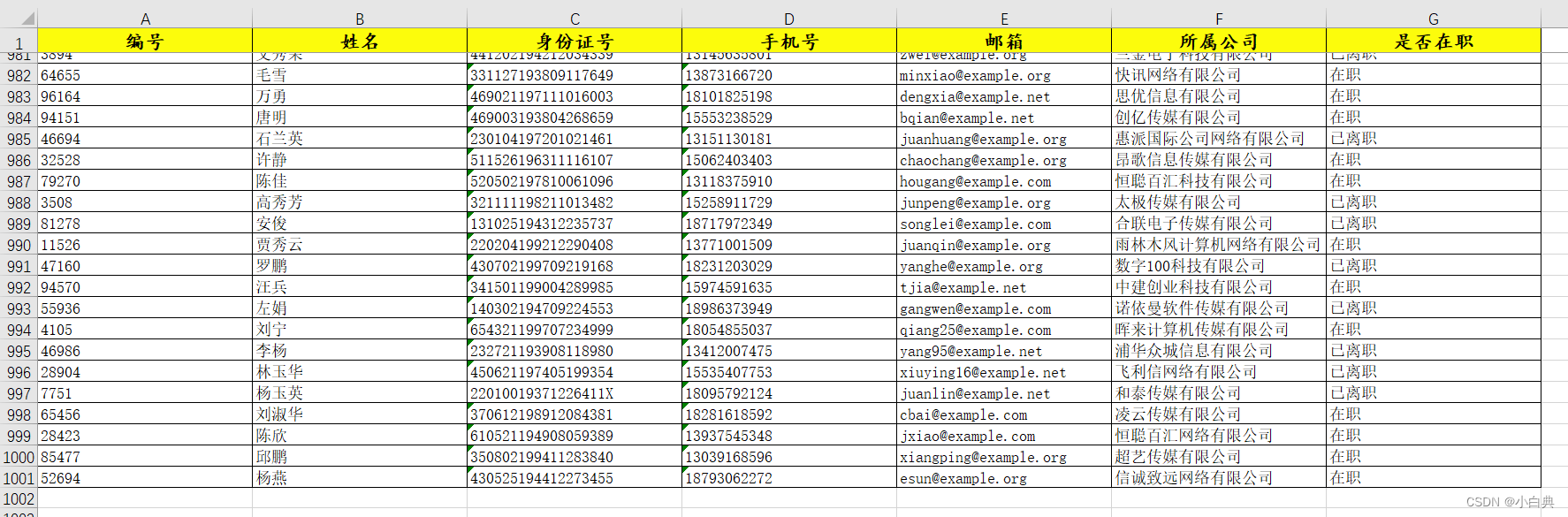
-
在Pytest中使用Faker随机生成入参
# 创建test5.py from faker import Faker import pytest, requests fk = Faker(locale="zh_CN") # Faker.seed(1) # 测试创建同名文章接口响应情况时,使用seed获取相同结果即可 @pytest.mark.repeat(5) # 使用装饰器设置执行次数 def test_art(): res_url = "http://192.166.66.45:8090/api/admin/posts" header = {"Admin-Authorization": "xxxxxx91f43942b0b74803445771cfee"} # 定义传参,入参由Faker随机生成 art_data = { "title": fk.sentence(), "originalContent": fk.text(200), "status": fk.words(ext_word_list=["DRAFT", "PUBLISHED"], nb=1)[0], # 在指定两个单词中随机选择一个 "slug": fk.pystr(), "tagIds": [fk.random_int(min=1, max=6)], "categoryIds": [1] } r_art = requests.request(method="post", url=res_url, headers=header, json=art_data) assert r_art.json()["message"] == "OK" and r_art.status_code == 200 # 断言 if __name__ == "__main__": pytest.main(["-sv", "test5.py"])
-
在使用这些伪数据时,需要注意数据的格式,请根据实际情况进行数据格式转换,关于Faker更多详细的介绍及参数请查看官方文档