讲在前面,chatgpt出来的时候就想过将其利用在信息抽取方面,后续也发现了不少基于这种大语言模型的信息抽取的论文,比如之前收集过的:
-
https://github.com/cocacola-lab/GPT4IE
-
https://github.com/RidongHan/Evaluation-of-ChatGPT-on-Information-Extraction
-
https://github.com/cocacola-lab/ChatIE
-
Unified Text Structuralization with Instruction-tuned Language Models
接下来继续介绍另一篇论文。
GPT-NER:通过大型语言模型的命名实体识别
GPT-NER: Named Entity Recognition via Large Language Models
https://arxiv.org/pdf/2304.10428v1.pdf
https://github.com/ShuheWang1998/GPT-NER
Part1前言
为什么使用大语言模型在NER上的表现仍然明显低于普遍的基线?
由于NER和LLMs这两个任务之间的差距:前者本质上是一个序列标记任务,而后者是一个文本生成模型。
怎么解决上述的问题呢?
-
GPT-NER通过将序列标签任务转换 为一个可以被LLMs轻松适应的生成任务来弥补这一差距,例如, 在输入文本Columbus是一个城市中寻找位置实体的任务被转换为生成文本序列@@Columbus##是一个城市,其中特殊标记@@##标志着要提取的实体。
-
为了有效地解决LLMs的幻觉问题,即LLMs有一个强烈的倾向,即过度自信地将NULL输入标记为实体,我们提出了一个自我验证策略,即提示LLMs询问自己所提取的实体是否符合标记的实体标签。
Part2介绍
GPTNER遵循语境学习的一般范式,可以分解为三个步骤:
-
(1)构建提示:对于一个给定的输入句子X,我们为X构建一个提示(用Prompt(X) 来表示);
-
(2)将提示输入到大语言模型得到生成的文本序列W = {w1 ,..., wn };
-
(3)将文本序列W转化为实体标签序列,以获得最终的结果。

如图所示:第一句话:你是一个优秀的语言学家;第二句话:任务是从给定的句子中标记xxx实体。接下来是一些例子,然后给树了一些例子。最后再输入自己想要提取实体的句子得到结果。很容易发现,每次只能提取一种实体,因此要提取出所有的实体,必须遍历实体列表。例如GPT-3,对提示的长度有 一个硬性的限制(例如GPT-3的4096个tokens)。鉴于这种有限的标记数量,我们不可能在一个提示中包括对所有实体类型的描述和演示。
1怎么提供实例样本?

如图所示:
-
1、一个已经训练好的ner模型提取训练数据中的实体,并为每一个实体构建(实体,句子)对。
-
2、将句子输入的模型中并获取实体的表示。
-
3、通过knn找到和实体向量最接近的几个邻居,将得到的句子视为样例。
2怎么进行自我验证?
Prompt:
I am an excellent linguist. The task is to label location entities in the given sentence.
Below are some examples.
Input:Columbus is a city
Output:@@Columbus## is a city
Input:Rare Hendrix song sells for $17
Output:
GPT-3 Output:
Rare @@Hendrix## song sells for $17
过度预测是指将不是实体的预测为实体。如上面的例子:Hendrix被识别为一个location实体,这显然是不对的。自我验证策略:给定一个由LLM提取的实体,我们要求LLM进一步验证该提取的实体是否正确,用是或否回答。比如:
“The task is to verify whether the word is a location entity extracted from the given sentence”
(1) “The input sentence: Only France and Britain backed Fischler’s proposal”,
(2) “Is the word "France" in the input sentence a location entity? Please answer with yes or no”.
(3) Yes

同样的,也是根据之前的策略选择样例。
Part3实验
-
模型:GPT-3 (Brown et al., 2020) (davinci-003)
-
最大长度:512
-
温度:0
-
top_p:1
-
frequency_penalty:0
-
presence_penalty:0
-
best_of:1
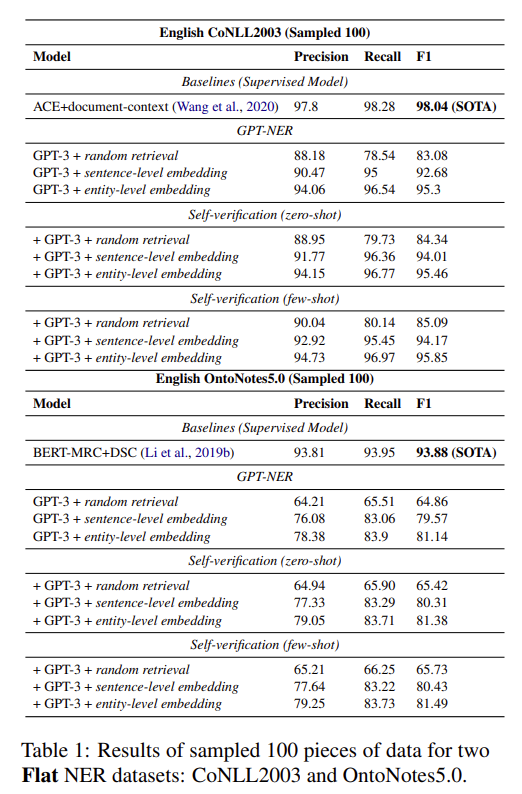


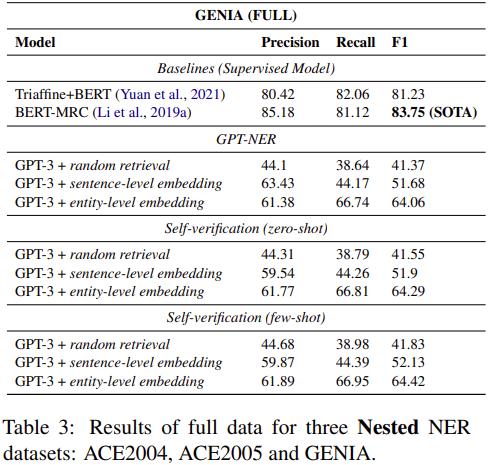
总结一下,利用大语言模型进行信息抽取,大多数都是采用这种类似问答的方式进行的,也就是分为多个步骤。






![【深度学习】遗传算法[选择、交叉、变异、初始化种群、迭代优化、几何规划排序选择、线性交叉、非均匀变异]](https://img-blog.csdnimg.cn/9b328783005d4848ab6b2df48e8d03bd.png)