Hadoop 概述
Hadoop 是一个由Apache 软件基金会开发的分布式基础架构。用户可以在不了解分布式底层细节的情况下,开发分布式程序,充分利用集群的威力进行高速运算和存储。
Hadoop 实现一个分布式文件系统(Hadoop Distributed File System, HDFS)。HDFS具有高容错性的特点,并设计它用来部署在廉价的硬件上,而且它提供高吞吐量来访问应用程序的数据,适合那些有着超大数据集的应用程序。Hadoop 框架的核心设计是HDFS和MapReduce。HDFS为海量数据提供了存储,而MapReduce则为海量的数据提供了计算。
Hadoop 核心三大组件
- HDFS
- MapReduce
- Yarn
基于Linux 安装Hadoop 3 伪分布式版本/单机版本
请参考文章:Centos7 安装Hadoop3 单机版本(伪分布式版本)
HDFS 原理
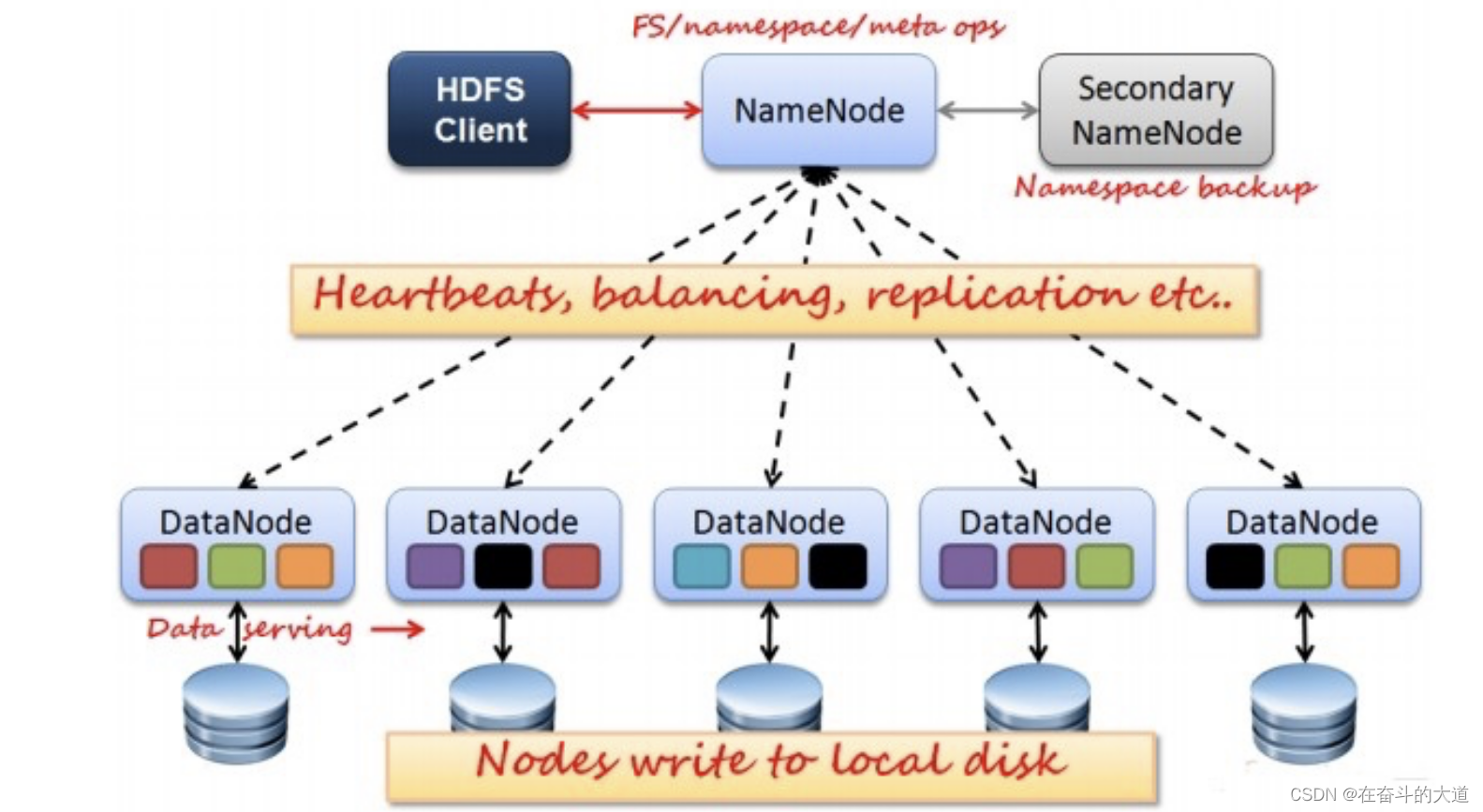
HDFS采用Master/Slave架构。
- 一个HDFS集群包含一个单独的NameNode和多个DataNode。
- NameNode作为Master服务,它负责管理文件系统的命名空间和客户端对文件的访问。NameNode会保存文件系统的具体信息,包括文件信息、文件被分割成具体block块的信息、以及每一个block块归属的DataNode的信息。对于整个集群来说,HDFS通过NameNode对用户提供了一个单一的命名空间。
- DataNode作为Slave服务,在集群中可以存在多个。通常每一个DataNode都对应于一个物理节点。DataNode负责管理节点上它们拥有的存储,它将存储划分为多个block块,管理block块信息,同时周期性的将其所有的block块信息发送给NameNode。
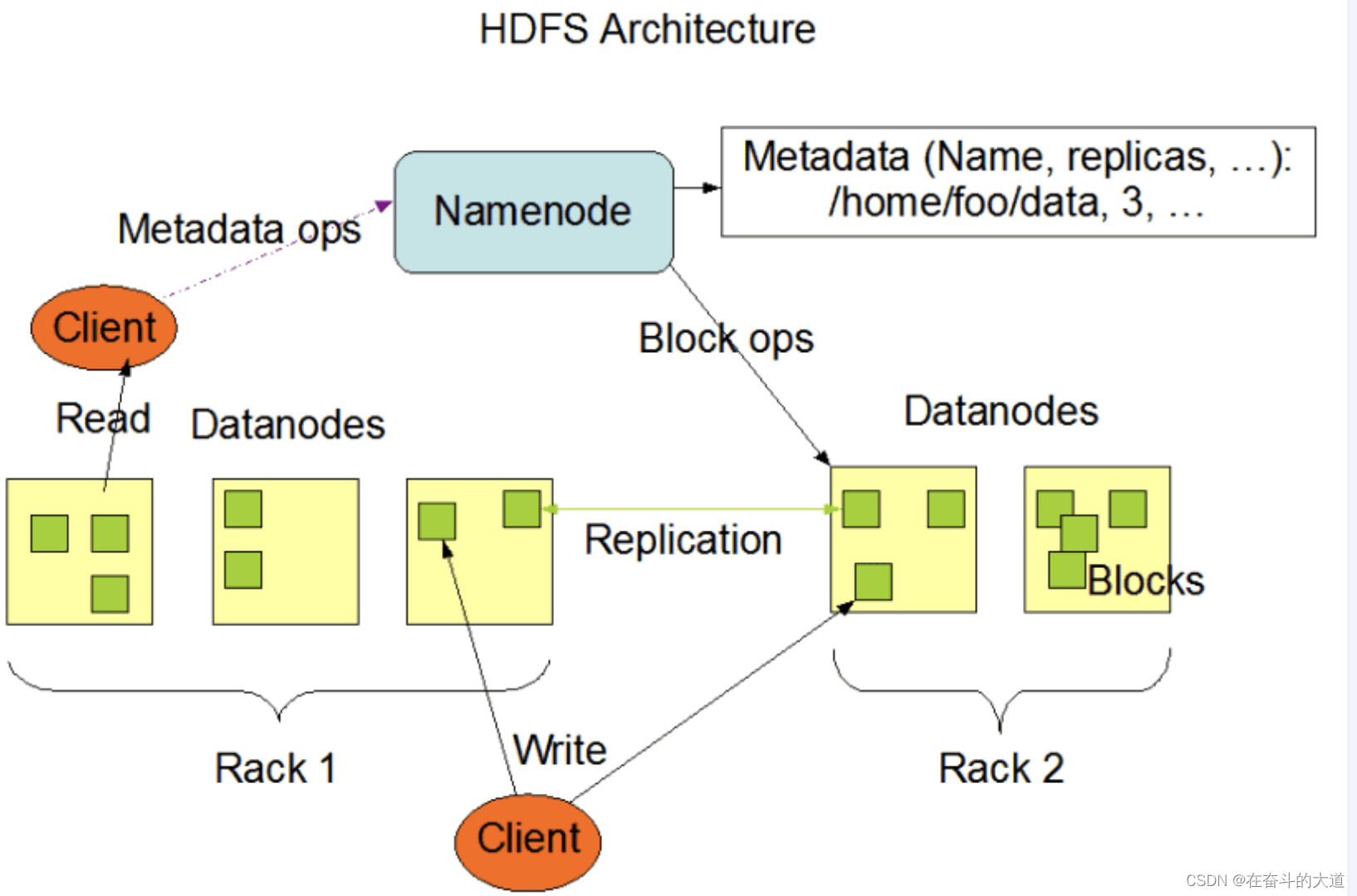
HDFS系统架构图,主要有三个角色,Client、NameNode、DataNode。
HDFS的一些关键元素
- Block:将文件分块,通常为64M。
- NameNode:是Master节点,是大领导。管理数据块映射;处理客户端的读写请求;配置副本策略;管理HDFS的名称空间。保存整个文件系统的目录信息、文件信息及分块信息,由唯一一台主机专门保存。
- SecondaryNameNode:是一个小弟,分担大哥NameNode的工作量;是NameNode的冷备份;合并fsimage和fsedits然后再发给NameNode。(热备份:b是a的热备份,如果a坏掉。那么b马上运行代替a的工作。冷备份:b是a的冷备份,如果a坏掉。那么b不能马上代替a工作。但是b上存储a的一些信息,减少a坏掉之后的损失。)
- DataNode:是Slave节点,奴隶,干活的。负责存储Client发来的数据块block;执行数据块的读写操作。
- fsimage:元数据镜像文件(文件系统的目录树)
- edits:元数据的操作日志(针对文件系统做的修改操作记录)
HDFS设计重点
- HDFS 数据备份HDFS被设计成一个可以在大集群中、跨机器、可靠的存储海量数据的框架。它将所有文件存储成block块组成的序列,除了最后一个block块,所有的block块大小都是一样的。
- HDFS中的文件默认规则是write one(一次写、多次读)的,并且严格要求在任何时候只有一个writer。
- NameNode全权管理数据块的复制,它周期性地从集群中的每个DataNode接受心跳信号和块状态报告(BlockReport)。接收到心跳信号以为该DataNode工作正常,块状态报告包含了一个该DataNode上所有数据块的列表。
- NameNode内存中存储的是=fsimage+edits。SecondaryNameNode负责定时(默认1小时)从NameNode上,获取fsimage和edits来进行合并,然后再发送给NameNode。减少NameNode的工作量。
HDFS 文件写入
Client向NameNode发起文件写入的请求。
- NameNode根据文件大小和文件块配置情况,返回给Client它所管理部分DataNode的信息。
- Client将文件划分为多个block块,并根据DataNode的地址信息,按顺序写入到每一个DataNode块中。
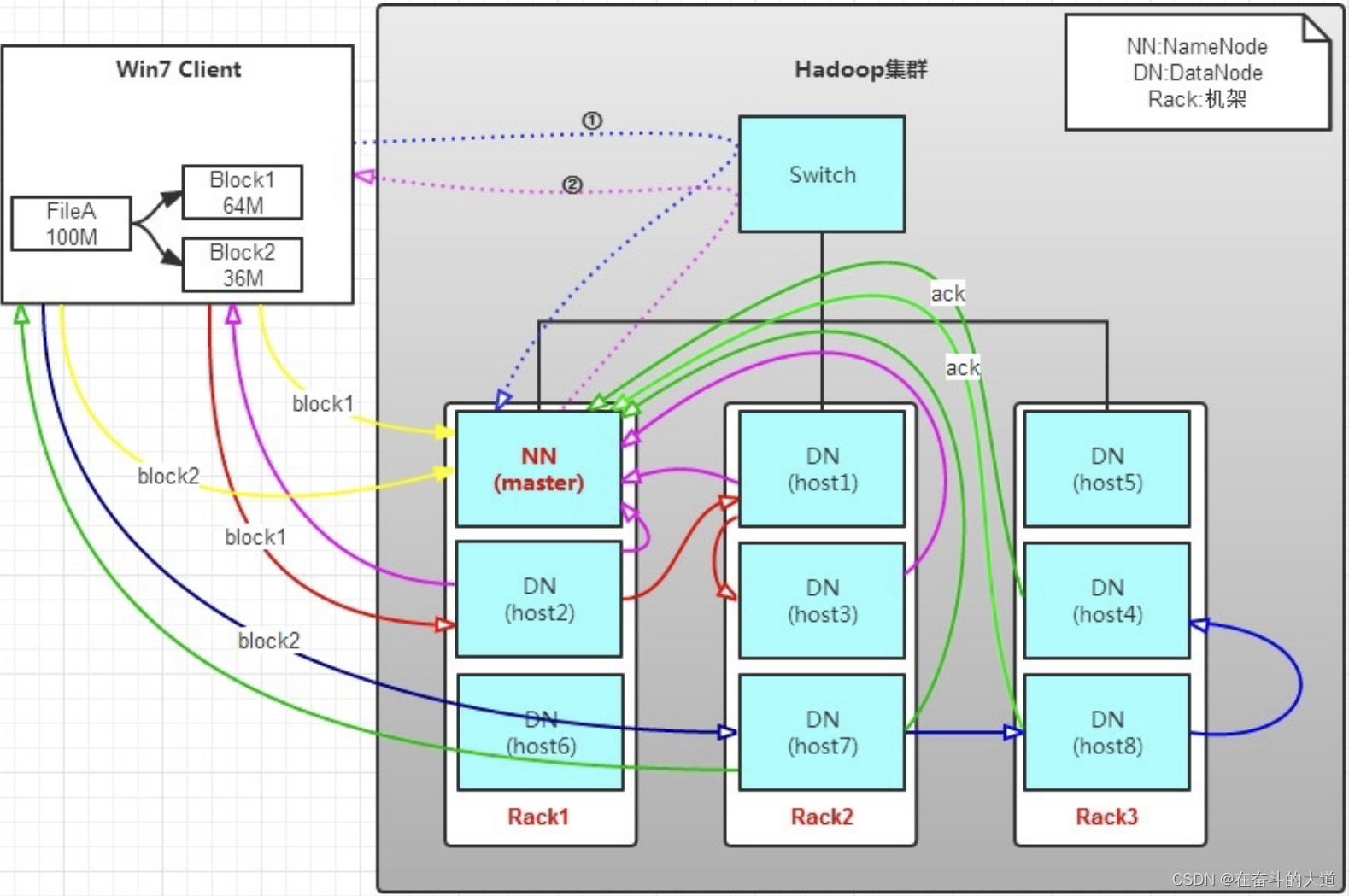
实例讲解:有一个文件FileA,100M大小。Client将FileA写入到HDFS上。
Hadoop 环境配置说明:
- HDFS分布在三个机架上Rack1,Rack2,Rack3。
文件写入过程如下:
- Client将FileA按64M分块。分成两块,block1和Block2;
- Client向NameNode发送写数据请求,如图蓝色虚线①------>。
- NameNode节点,记录block信息。并返回可用的DataNode,如粉色虚线②--------->。
- Block1: host2,host1,host3
- Block2: host7,host8,host4
- 原理:
- NameNode具有RackAware机架感知功能,这个可以配置。
- 若Client为DataNode节点,那存储block时,规则为:副本1,同Client的节点上;副本2,不同机架节点上;副本3,同第二个副本机架的另一个节点上;其他副本随机挑选。
- 若Client不为DataNode节点,那存储block时,规则为:副本1,随机选择一个节点上;副本2,不同副本1,机架上;副本3,同副本2相同的另一个节点上;其他副本随机挑选。
- Client向DataNode发送block1;发送过程是以流式写入。流式写入过程如下:
- 将64M的block1按64k的package划分;
- 然后将第一个package发送给host2;
- host2接收完后,将第一个package发送给host1,同时Client想host2发送第二个package;
- host1接收完第一个package后,发送给host3,同时接收host2发来的第二个package。
- 以此类推,如图红线实线所示,直到将block1发送完毕。
- host2,host1,host3向NameNode,host2向Client发送通知,说“消息发送完了”。如图粉红颜色实线所示。
- Client收到host2发来的消息后,向NameNode发送消息,说我写完了。这样就真完成了。如图黄色粗实线
- 发送完block1后,再向host7、host8、host4发送block2,如图蓝色实线所示。
- 发送完block2后,host7、host8、host4向NameNode,host7向Client发送通知,如图浅绿色实线所示。
- Client向NameNode发送消息,说我写完了,如图黄色粗实线。。。这样就完毕了。
- 分析:通过写过程,我们可以了解到
- 写1T文件,我们需要3T的存储,3T的网络流量贷款。
- 在执行读或写的过程中,NameNode和DataNode通过HeartBeat进行保存通信,确定DataNode活着。如果发现DataNode死掉了,就将死掉的DataNode上的数据,放到其他节点去。读取时,要读其他节点去。
- 挂掉一个节点,没关系,还有其他节点可以备份;甚至,挂掉某一个机架,也没关系;其他机架上,也有备份。
HDFS 文件读取
Client向NameNode发起文件读取的请求。
- Client向NameNode发起文件读取的请求。
- NameNode返回文件存储的block块信息、及其block块所在DataNode的信息。
- Client读取文件信息。
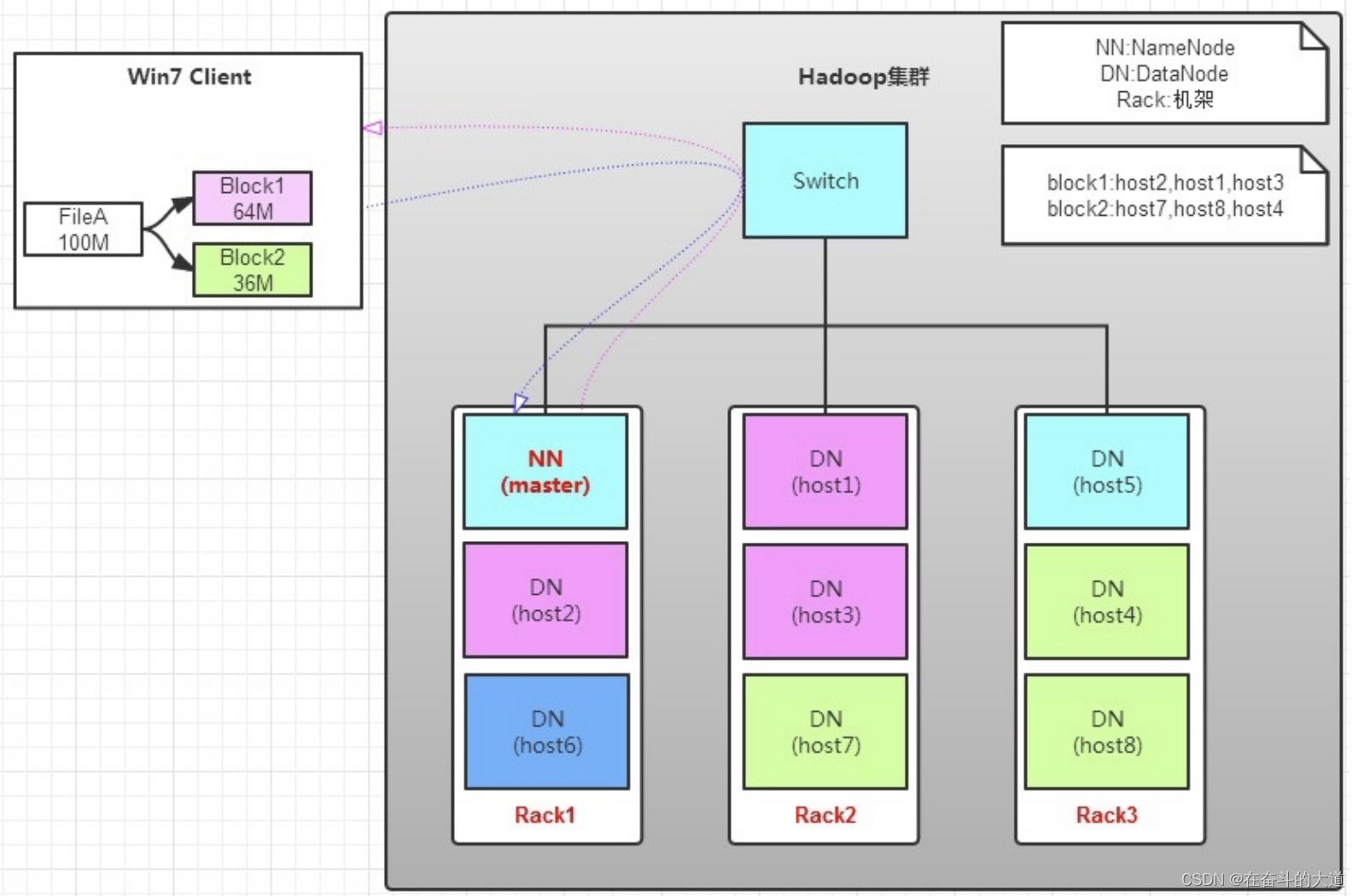
如图所示,Client要从DataNode上,读取FileA。而FileA由block1和block2组成。读操作流程如下:
- Client向NameNode发送读请求。
- NameNode查看Metadata信息,返回FileA的block的位置。
- block1:host2,host1,host3
- block2:host7,host8,host4
- block的位置是有先后顺序的,先读block1,再读block2。而且block1去host2上读取;然后block2,去host7上读取。
上面例子中,Client位于机架外,那么如果Client位于机架内某个DataNode上,例如,Client是host6。那么读取的时候,遵循的规律是:优选读取本机架上的数据。
HDFS 数据备份
备份数据的存放是HDFS可靠性和性能的关键。HDFS采用一种称为rack-aware的策略来决定备份数据的存放。
通过一个称为Rack Awareness的过程,NameNode决定每个DataNode所属rack id。
缺省情况下,一个block块会有三个备份:
- 一个在NameNode指定的DataNode上
- 一个在指定DataNode非同一rack的DataNode上
- 一个在指定DataNode同一rack的DataNode上。
这种策略综合考虑了同一rack失效、以及不同rack之间数据复制性能问题。
副本的选择:为了降低整体的带宽消耗和读取延时,HDFS会尽量读取最近的副本。如果在同一个rack上有一个副本,那么就读该副本。如果一个HDFS集群跨越多个数据中心,那么将首先尝试读本地数据中心的副本。
HDFS Shell 命令
HDFS Shell 简介
调用文件系统(HDFS)Shell命令应使用 bin/hadoop fs <args>的形式。 所有的的FS shell命令使用URI路径作为参数。URI格式是scheme://authority/path。对HDFS文件系统,scheme是hdfs,对本地文件系统,scheme是file。其中scheme和authority参数都是可选的,如果未加指定,就会使用配置中指定的默认scheme。
HDFS Shell 命令详解
cat
使用方法:hadoop fs -cat URI [URI …]
将路径指定文件的内容输出到stdout。
示例:
- hadoop fs -cat hdfs://host1:port1/file1 hdfs://host2:port2/file2
- hadoop fs -cat file:///file3 /user/hadoop/file4
返回值:
成功返回0,失败返回-1。
chgrp
使用方法:hadoop fs -chgrp [-R] GROUP URI [URI …] Change group association of files. With -R, make the change recursively through the directory structure. The user must be the owner of files, or else a super-user. Additional information is in the Permissions User Guide. -->
改变文件所属的组。使用-R将使改变在目录结构下递归进行。命令的使用者必须是文件的所有者或者超级用户。更多的信息请参见HDFS权限用户指南。
chmod
使用方法:hadoop fs -chmod [-R] <MODE[,MODE]... | OCTALMODE> URI [URI …]
改变文件的权限。使用-R将使改变在目录结构下递归进行。命令的使用者必须是文件的所有者或者超级用户。更多的信息请参见HDFS权限用户指南。
chown
使用方法:hadoop fs -chown [-R] [OWNER][:[GROUP]] URI [URI ]
改变文件的拥有者。使用-R将使改变在目录结构下递归进行。命令的使用者必须是超级用户。更多的信息请参见HDFS权限用户指南。
copyFromLocal
使用方法:hadoop fs -copyFromLocal <localsrc> URI
除了限定源路径是一个本地文件外,和put命令相似。
copyToLocal
使用方法:hadoop fs -copyToLocal [-ignorecrc] [-crc] URI <localdst>
除了限定目标路径是一个本地文件外,和get命令类似。
cp
使用方法:hadoop fs -cp URI [URI …] <dest>
将文件从源路径复制到目标路径。这个命令允许有多个源路径,此时目标路径必须是一个目录。
示例:
- hadoop fs -cp /user/hadoop/file1 /user/hadoop/file2
- hadoop fs -cp /user/hadoop/file1 /user/hadoop/file2 /user/hadoop/dir
返回值:
成功返回0,失败返回-1。
du
使用方法:hadoop fs -du URI [URI …]
显示目录中所有文件的大小,或者当只指定一个文件时,显示此文件的大小。
示例:
hadoop fs -du /user/hadoop/dir1 /user/hadoop/file1 hdfs://host:port/user/hadoop/dir1
返回值:
成功返回0,失败返回-1。
dus
使用方法:hadoop fs -dus <args>
显示文件的大小。
expunge
使用方法:hadoop fs -expunge
清空回收站。请参考HDFS设计文档以获取更多关于回收站特性的信息。
get
使用方法:hadoop fs -get [-ignorecrc] [-crc] <src> <localdst>
复制文件到本地文件系统。可用-ignorecrc选项复制CRC校验失败的文件。使用-crc选项复制文件以及CRC信息。
示例:
- hadoop fs -get /user/hadoop/file localfile
- hadoop fs -get hdfs://host:port/user/hadoop/file localfile
返回值:
成功返回0,失败返回-1。
getmerge
使用方法:hadoop fs -getmerge <src> <localdst> [addnl]
接受一个源目录和一个目标文件作为输入,并且将源目录中所有的文件连接成本地目标文件。addnl是可选的,用于指定在每个文件结尾添加一个换行符。
ls
使用方法:hadoop fs -ls <args>
如果是文件,则按照如下格式返回文件信息:
文件名 <副本数> 文件大小 修改日期 修改时间 权限 用户ID 组ID
如果是目录,则返回它直接子文件的一个列表,就像在Unix中一样。目录返回列表的信息如下:
目录名 <dir> 修改日期 修改时间 权限 用户ID 组ID
示例:
hadoop fs -ls /user/hadoop/file1 /user/hadoop/file2 hdfs://host:port/user/hadoop/dir1 /nonexistentfile
返回值:
成功返回0,失败返回-1。
lsr
使用方法:hadoop fs -lsr <args>
ls命令的递归版本。类似于Unix中的ls -R。
mkdir
使用方法:hadoop fs -mkdir <paths>
接受路径指定的uri作为参数,创建这些目录。其行为类似于Unix的mkdir -p,它会创建路径中的各级父目录。
示例:
- hadoop fs -mkdir /user/hadoop/dir1 /user/hadoop/dir2
- hadoop fs -mkdir hdfs://host1:port1/user/hadoop/dir hdfs://host2:port2/user/hadoop/dir
返回值:
成功返回0,失败返回-1。
movefromLocal
使用方法:dfs -moveFromLocal <src> <dst>
输出一个”not implemented“信息。
mv
使用方法:hadoop fs -mv URI [URI …] <dest>
将文件从源路径移动到目标路径。这个命令允许有多个源路径,此时目标路径必须是一个目录。不允许在不同的文件系统间移动文件。
示例:
- hadoop fs -mv /user/hadoop/file1 /user/hadoop/file2
- hadoop fs -mv hdfs://host:port/file1 hdfs://host:port/file2 hdfs://host:port/file3 hdfs://host:port/dir1
返回值:
成功返回0,失败返回-1。
put
使用方法:hadoop fs -put <localsrc> ... <dst>
从本地文件系统中复制单个或多个源路径到目标文件系统。也支持从标准输入中读取输入写入目标文件系统。
- hadoop fs -put localfile /user/hadoop/hadoopfile
- hadoop fs -put localfile1 localfile2 /user/hadoop/hadoopdir
- hadoop fs -put localfile hdfs://host:port/hadoop/hadoopfile
- hadoop fs -put - hdfs://host:port/hadoop/hadoopfile
从标准输入中读取输入。
返回值:
成功返回0,失败返回-1。
rm
使用方法:hadoop fs -rm URI [URI …]
删除指定的文件。只删除非空目录和文件。请参考rmr命令了解递归删除。
示例:
- hadoop fs -rm hdfs://host:port/file /user/hadoop/emptydir
返回值:
成功返回0,失败返回-1。
rmr
使用方法:hadoop fs -rmr URI [URI …]
delete的递归版本。
示例:
- hadoop fs -rmr /user/hadoop/dir
- hadoop fs -rmr hdfs://host:port/user/hadoop/dir
返回值:
成功返回0,失败返回-1。
setrep
使用方法:hadoop fs -setrep [-R] <path>
改变一个文件的副本系数。-R选项用于递归改变目录下所有文件的副本系数。
示例:
- hadoop fs -setrep -w 3 -R /user/hadoop/dir1
返回值:
成功返回0,失败返回-1。
stat
使用方法:hadoop fs -stat URI [URI …]
返回指定路径的统计信息。
示例:
- hadoop fs -stat path
返回值:
成功返回0,失败返回-1。
tail
使用方法:hadoop fs -tail [-f] URI
将文件尾部1K字节的内容输出到stdout。支持-f选项,行为和Unix中一致。
示例:
- hadoop fs -tail pathname
返回值:
成功返回0,失败返回-1。
test
使用方法:hadoop fs -test -[ezd] URI
选项:
-e 检查文件是否存在。如果存在则返回0。
-z 检查文件是否是0字节。如果是则返回0。
-d 如果路径是个目录,则返回1,否则返回0。
示例:
- hadoop fs -test -e filename
text
使用方法:hadoop fs -text <src>
将源文件输出为文本格式。允许的格式是zip和TextRecordInputStream。
touchz
使用方法:hadoop fs -touchz URI [URI …]
创建一个0字节的空文件。
示例:
- hadoop -touchz pathname
返回值:
成功返回0,失败返回-1。
HDFS Python API
HDFS 除了通过HDFS Shell 命令的方式进行操作,还可以通过Java API、Python API、C++ API等方式进行编程操作。在使用Python API 编程前,需要安装HDFS 依赖的第三方库:PyHDFS
pyhdfs
官方文档地址:https://pyhdfs.readthedocs.io/en/latest/pyhdfs.html
原文简介:
WebHDFS client with support for NN HA and automatic error checking
For details on the WebHDFS endpoints, see the Hadoop documentation:
https://hadoop.apache.org/docs/current/hadoop-project-dist/hadoop-hdfs/WebHDFS.html
https://hadoop.apache.org/docs/current/api/org/apache/hadoop/fs/FileSystem.html
https://hadoop.apache.org/docs/current/hadoop-project-dist/hadoop-common/filesystem/filesystem.html大致意思是:pyhdfs 模块/库使用WebHDFS 客户端连接HDFS,支持NN HA 和自动错误检测,详细使用参考官方文档地址。
pyhdfs 核心类

Python 3 使用 pyhdfs(重点是HdfsClient 类)
安装pyhdfs 模块/库
pip install pyhdfspyhdfs 使用实例
# _*_ coding : UTF-8_*_
# 开发者 : zhuozhiwengang
# 开发时间 : 2023/8/11 22:35
# 文件名称 : pythonHdfs_1
# 开发工具 : PyCharm
import pyhdfs
# 基于pyHDFS 模块, 连接Hadoop 主机:9870 端口
fs = pyhdfs.HdfsClient(hosts="192.168.43.11:9870", user_name="root")
# 返回用户根目录
print(fs.get_home_directory())
# 返回可用namenode节点
print(fs.get_active_namenode())
# 返回指定目录下所有文件
print(fs.listdir("/"))
# hadoop 创建指定目录
fs.mkdirs('/uploads')
# 再次执行返货指定目录下所有文件
print(fs.listdir("/"))
# 执行本地文件上传Hadoop 指定目录
# fs.copy_from_local("D:\one.txt", '/uploads/one.txt')
# 执行Hadoop 文件下载
# fs.copy_to_local("/uploads/one.txt", r'D:\two.txt')
# 判断目录是否存在
print(fs.exists("/uploads"))
# 返回目录下的所有目录,路径,文件名
print(list(fs.walk('/uploads')))
# 删除目录/文件
fs.delete("/uploads", recursive=True) # 删除目录 recursive=True
fs.delete("/uploads/one.txt") # 删除文件
Python 3 通用封装 pyhdfs
# _*_ coding : UTF-8_*_
# 开发者 : zhuozhiwengang
# 开发时间 : 2023/8/11 22:35
# 文件名称 : pythonHdfs
# 开发工具 : PyCharm
import sys
import pyhdfs
class HDFS:
def __init__(self, host='192.168.43.11',user_name='root'):
self.host = host
self.user_name=user_name
def get_con(self):
try:
hdfs = pyhdfs.HdfsClient(hosts = self.host,user_name = self.user_name)
return hdfs
except pyhdfs.HdfsException,e:
print "Error:%s" % e
# 返回指定目录下的所有文件
def listdir(self,oper):
try:
client = self.get_con()
dirs = client.listdir(oper)
for row in dirs:
print row
except pyhdfs.HdfsException, e:
print "Error:%s" % e
# 返回用户的根目录
def get_home_directory(self):
try:
client = self.get_con()
print client.get_home_directory()
except pyhdfs.HdfsException, e:
print "Error:%s" % e
# 返回可用的namenode节点
def get_active_namenode(self):
try:
client = self.get_con()
print client.get_active_namenode()
except pyhdfs.HdfsException, e:
print "Error:%s" % e
# 创建新目录
def mkdirs(self,oper):
try:
client = self.get_con()
print client.mkdirs(oper)
except pyhdfs.HdfsException, e:
print "Error:%s" % e
# 从集群上copy到本地
def copy_to_local(self, dest,localsrc):
try:
client = self.get_con()
print client.copy_to_local(dest,localsrc)
except pyhdfs.HdfsException, e:
print "Error:%s" % e
# 从本地上传文件至集群
def copy_from_local(self, localsrc, dest):
try:
client = self.get_con()
print client.copy_from_local(localsrc, dest)
except pyhdfs.HdfsException, e:
print "Error:%s" % e
# 查看文件内容
def read_files(self,oper):
try:
client = self.get_con()
response = client.open(oper)
print response.read()
except pyhdfs.HdfsException, e:
print "Error:%s" % e
# 向一个已经存在的文件追加内容
def append_files(self, file,content):
try:
client = self.get_con()
print client.append(file,content)
except pyhdfs.HdfsException, e:
print "Error:%s" % e
# 查看是否存在文件
def check_files(self,oper):
try:
client = self.get_con()
print client.exists(oper)
except pyhdfs.HdfsException, e:
print "Error:%s" % e
# 查看文件的校验和
def get_file_checksum(self,oper):
try:
client = self.get_con()
print client.get_file_checksum(oper)
except pyhdfs.HdfsException, e:
print "Error:%s" % e
# 查看路径总览信息
def get_content_summary(self,oper):
try:
client = self.get_con()
print client.get_content_summary(oper)
except pyhdfs.HdfsException, e:
print "Error:%s" % e
# 查看当前路径的状态
def list_status(self,oper):
try:
client = self.get_con()
print client.list_status(oper)
except pyhdfs.HdfsException, e:
print "Error:%s" % e
# 删除文件
def delete_files(self,path):
try:
client = self.get_con()
print client.delete(path)
except pyhdfs.HdfsException, e:
print "Error:%s" % e
if __name__ == '__main__':
db = HDFS('Hadoop3-master','root')
# db.listdir('/user')
# db.get_home_directory()
# db.get_active_namenode()
# db.mkdirs('/dave')
# db.copy_from_local("D:/one.txt","/uploads/two.txt")
# db.listdir('/uploads')
# db.read_files('/uploads/two.txt')
# db.check_files('/uploads/two.txt')
# db.get_file_checksum('/uploads/two.txt')
# db.get_content_summary('/')
# db.list_status('/')
# db.list_status('/uploads/two.txt')
# db.copy_to_local("/uploads/two.txt","D:/one.txt")
# db.append_files('/uploads/two.txt',"88, CSDN 博客")
# db.read_files('/uploads/two.txt')
# db.copy_from_local("D:/three.txt", "/uploads/two.txt")
db.listdir('/uploads')
# db.delete_files('/uploads/two.txt')


![【深度学习】遗传算法[选择、交叉、变异、初始化种群、迭代优化、几何规划排序选择、线性交叉、非均匀变异]](https://img-blog.csdnimg.cn/9b328783005d4848ab6b2df48e8d03bd.png)