基于Yolov8与LabelImg训练自己数据的完整流程
- 1. 创建虚拟环境
- 2. 通过git 安装 ultralytics
- 3. 安装完成之后,通过以下代码测试下环境配置是否正确
- 4. 安装labelImg标注软件
- 5. 使用labelImg进行标注,图片使用上面的coco128
- 5.1 点击“打开目录”选择存储图像的文件夹进行标注,右下角会出现图像列表
- 5.2 选择“创建区块”,在图像上对目标进行标注,然后填入类别,每张图片皆可标记多个目标
- 5.3 每一张图片标注完后,软件会提示进行保存,点击Yes即可;
- 5.4 标记完后的文件如图所示;
- 5.5 将xml文件放入vocLabels文件夹中;
- 6. 将数据转换成yolo需要的格式
- 7. 对数据集进行划分
- 8.训练
- 8.1 如果运行的时候出现如下报错,进入虚拟环境中搜索libiomp5md.dll,删掉一个即可
- 8.2 训练时需要修改的文件如下,修改文件的路径如下:
- 8.3 训练
- 9. Predict 预测
- 10. ONNX
1. 创建虚拟环境
```python
conda create -n yolos python=3.11
# 激活yolos 环境,后续的安装都在里面进行
conda activate yolos
2. 通过git 安装 ultralytics
# 没有git的话要安装git
conda install git
# D: 进入D盘
D:
mkdir yolos
cd yolos
# Clone the ultralytics repository
git clone https://github.com/ultralytics/ultralytics
# Navigate to the cloned directory
cd ultralytics
# Install the package in editable mode for development
pip install -e . //最后的“.”不可省略
# 通过该命令安装的torch 是cpu版本,如果需要安装gpu,需要先卸载掉,然后安装
pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu117 //这一步骤比较慢
# torch 安装完成后,可以执行如下命令,进行快速安装
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple -r requirements.txt
# 后面有些代码需要pytest,也要安装一下
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple pytest
# 如果需要安装onnx,也可以安装一下
conda install onnx
3. 安装完成之后,通过以下代码测试下环境配置是否正确
# DemoTest.py
# yolo predict model=yolov8n-seg.pt source='https://youtu.be/Zgi9g1ksQHc' imgsz=320 通过该命令可自动下载不同模型
from multiprocessing import freeze_support
from ultralytics import YOLO
def main():
# Load a model
model = YOLO("yolov8n.yaml") # build a new model from scratch
model = YOLO("yolov8n.pt") # load a pretrained model (recommended for training)
# Use the model
model.train(data="coco128.yaml", epochs=3) # train the model
metrics = model.val() # evaluate model performance on the validation set
results = model("https://ultralytics.com/images/bus.jpg") # predict on an image
# path = model.export(format="onnx") # export the model to ONNX format
if __name__ == '__main__':
freeze_support()
main()
运行过程中,会提示下载coco128.zip,和yolov8n.pt,模型与py文件放在同一目录下,如果网速快的话,自己下载就好,下载慢的话,下面是网盘地址:
yolov8 检测预训练模型百度网盘:链接:https://pan.baidu.com/s/1L5q1sdtBmq0FcuX6t1SvIg 提取码:ix9e
coco128.zip 百度网盘: 链接:https://pan.baidu.com/s/1UMdrWcY49jfCVvGvTMm8xg 提取码:rqd0
测试结果路径:ultralytics\runs\detect\val,里面存储了运行的结果,这样环境就算是配置好了。
结果如下:

4. 安装labelImg标注软件
# 下载源代码
git clone https://github.com/HumanSignal/labelImg.git
# 创建labelImg虚拟环境,lebelImg 需要低版本的python,我这里安装3.7
conda create -n labelImg37 python=3.7
# 激活环境
conda activate labelImg37
# 安装依赖库
conda install pyqt=5
conda install -c anaconda lxml
# 将qrc转换成可调用的py
pyrcc5 -o libs/resources.py resources.qrc
# 直接运行会报错 'pyrcc5' 不是内部或外部命令,也不是可运行的程序;因为从anaconda 中安装的pyqt不包含pyrcc5
# 需要从cmd直接安装
pip install pyqt5_tools -i https://pypi.tuna.tsinghua.edu.cn/simple
# 然后再执行下一句
pyrcc5 -o libs/resources.py resources.qrc
#然后执行下一句弹出窗口
python labelImg.py
# python labelImg.py [IMAGE_PATH] [PRE-DEFINED CLASS FILE]
# 也可以直接通过pip安装
pip3 install labelImg
# 启动
labelImg
5. 使用labelImg进行标注,图片使用上面的coco128
首先创建一个文件夹:cocoImages, 里面分别创建2个文件夹,images用来放置标注图片, vocLabels 用来放置标注文件
5.1 点击“打开目录”选择存储图像的文件夹进行标注,右下角会出现图像列表

5.2 选择“创建区块”,在图像上对目标进行标注,然后填入类别,每张图片皆可标记多个目标
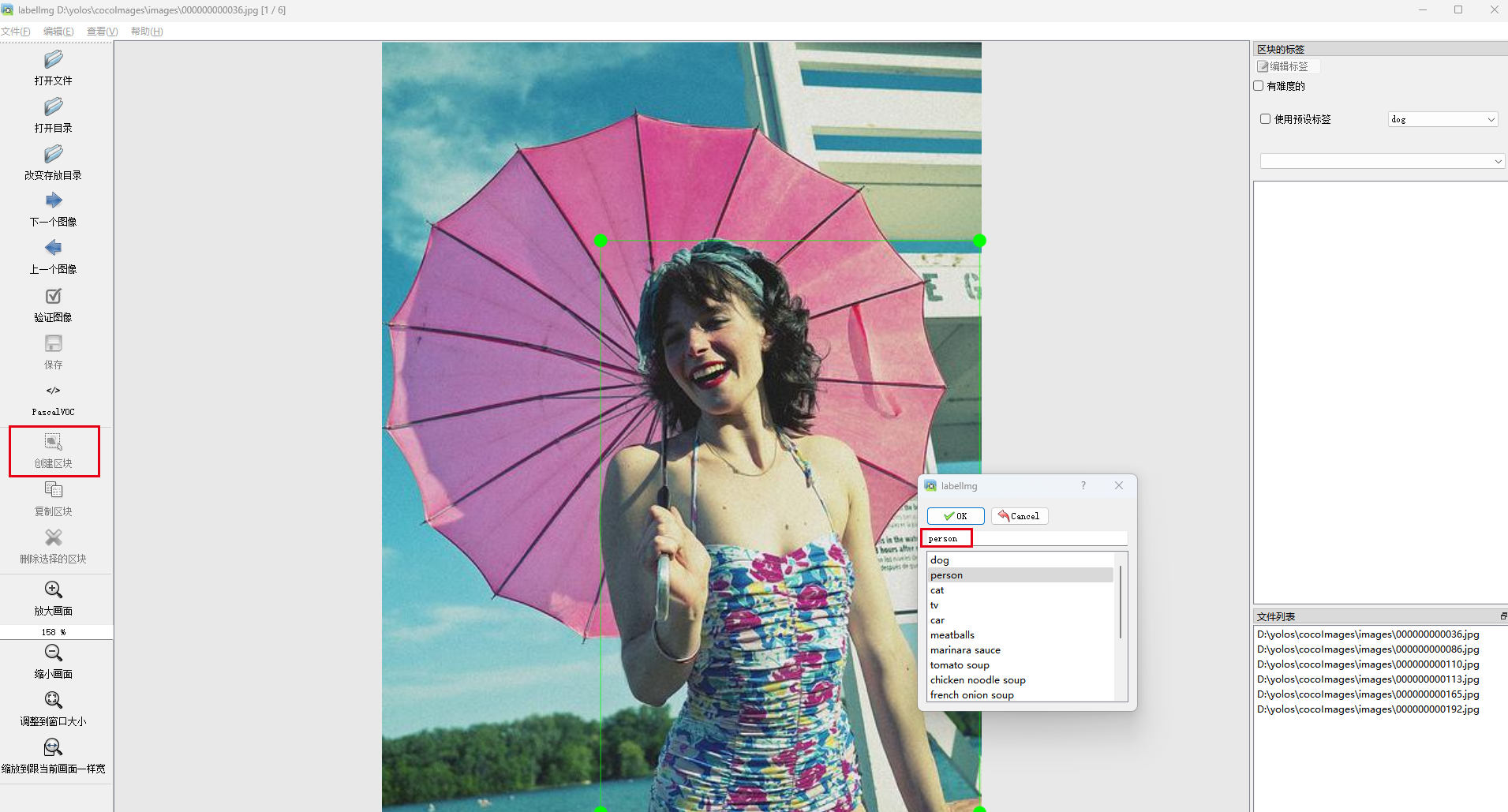
5.3 每一张图片标注完后,软件会提示进行保存,点击Yes即可;
5.4 标记完后的文件如图所示;
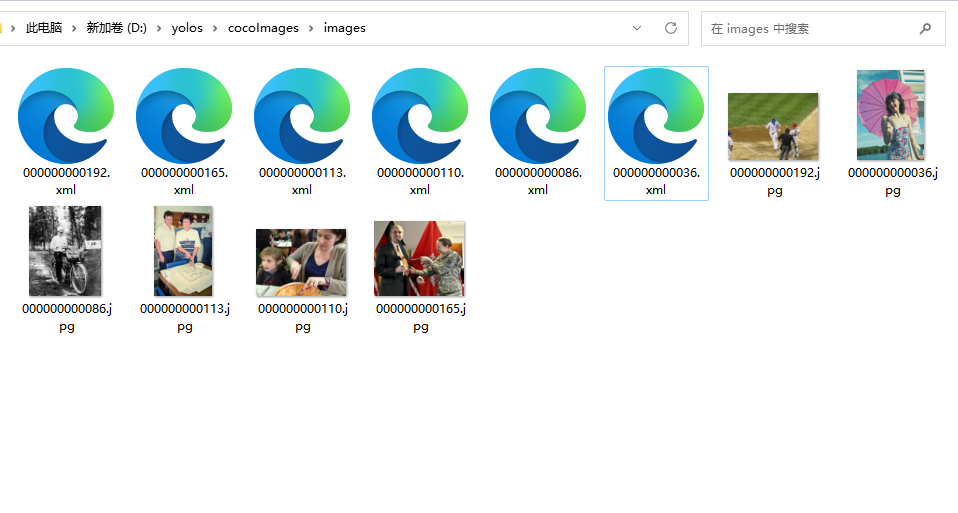
5.5 将xml文件放入vocLabels文件夹中;
6. 将数据转换成yolo需要的格式
首先将11行中的classes改为自己标注的类别,然后执行下代码生成相应的文件夹,接着将图像copy到JPEGImages下,labels copy到Annotations下面,再次执行一次该代码即可。
import xml.etree.ElementTree as ET
import pickle
import os
from os import listdir, getcwd
from os.path import join
import random
# classes=["aeroplane", 'bicycle', 'bird', 'boat', 'bottle', 'bus', 'car', 'cat', 'chair', 'cow', 'diningtable', 'dog',
# 'horse', 'motorbike', 'person', 'pottedplant', 'sheep', 'sofa', 'train', 'tvmonitor'] # class names
classes = ["person", 'cup', 'umbrella']
def clear_hidden_files(path):
dir_list = os.listdir(path)
for i in dir_list:
abspath = os.path.join(os.path.abspath(path), i)
if os.path.isfile(abspath):
if i.startswith("._"):
os.remove(abspath)
else:
clear_hidden_files(abspath)
def convert(size, box):
dw = 1. / size[0]
dh = 1. / size[1]
x = (box[0] + box[1]) / 2.0
y = (box[2] + box[3]) / 2.0
w = box[1] - box[0]
h = box[3] - box[2]
x = x * dw
w = w * dw
y = y * dh
h = h * dh
return x, y, w, h
def convert_annotation(image_id, voc_labels, yolo_labels):
in_file = open(os.path.join(voc_labels + '%s.xml') % image_id)
out_file = open(os.path.join(yolo_labels + '%s.txt') % image_id, 'w')
tree = ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
difficult = obj.find('difficult').text
cls = obj.find('name').text
if cls not in classes or int(difficult) == 1:
continue
cls_id = classes.index(cls)
xml_box = obj.find('bndbox')
b = (float(xml_box.find('xmin').text), float(xml_box.find('xmax').text), float(xml_box.find('ymin').text),
float(xml_box.find('ymax').text))
bb = convert((w, h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
in_file.close()
out_file.close()
if __name__ == '__main__':
# 获取当前路径
wd = os.getcwd()
# 创建相应VOC模式文件夹
voc_path = os.path.join(wd, "voc_dataset")
if not os.path.isdir(voc_path):
os.mkdir(voc_path)
annotation_dir = os.path.join(voc_path, "Annotations/")
if not os.path.isdir(annotation_dir):
os.mkdir(annotation_dir)
clear_hidden_files(annotation_dir)
image_dir = os.path.join(voc_path, "JPEGImages/")
if not os.path.isdir(image_dir):
os.mkdir(image_dir)
clear_hidden_files(image_dir)
voc_file_dir = os.path.join(voc_path, "ImageSets/")
if not os.path.isdir(voc_file_dir):
os.mkdir(voc_file_dir)
voc_file_dir = os.path.join(voc_file_dir, "Main/")
if not os.path.isdir(voc_file_dir):
os.mkdir(voc_file_dir)
VOC_train_file = open(os.path.join(voc_path, "ImageSets/Main/train.txt"), 'w')
VOC_test_file = open(os.path.join(voc_path, "ImageSets/Main/test.txt"), 'w')
VOC_train_file.close()
VOC_test_file.close()
if not os.path.exists(os.path.join(voc_path, 'Labels/')):
os.makedirs(os.path.join(voc_path, 'Labels'))
train_file = open(os.path.join(voc_path, "2007_train.txt"), 'a')
test_file = open(os.path.join(voc_path, "2007_test.txt"), 'a')
VOC_train_file = open(os.path.join(voc_path, "ImageSets/Main/train.txt"), 'a')
VOC_test_file = open(os.path.join(voc_path, "ImageSets/Main/test.txt"), 'a')
image_list = os.listdir(image_dir) # list image files
probo = random.randint(1, 100)
print("Probobility: %d" % probo)
for i in range(0, len(image_list)):
path = os.path.join(image_dir, image_list[i])
if os.path.isfile(path):
image_path = image_dir + image_list[i]
image_name = image_list[i]
(name_without_extent, extent) = os.path.splitext(os.path.basename(image_path))
voc_name_without_extent, voc_extent = os.path.splitext(os.path.basename(image_name))
annotation_name = name_without_extent + '.xml'
annotation_path = os.path.join(annotation_dir, annotation_name)
probo = random.randint(1, 100)
print("Probobility: %d" % probo)
if (probo < 75):
if os.path.exists(annotation_path):
train_file.write(image_path + '\n')
VOC_train_file.write(voc_name_without_extent + '\n')
yolo_labels_dir = os.path.join(voc_path, 'Labels/')
convert_annotation(name_without_extent, annotation_dir, yolo_labels_dir)
else:
if os.path.exists(annotation_path):
test_file.write(image_path + '\n')
VOC_test_file.write(voc_name_without_extent + '\n')
yolo_labels_dir =os.path.join(voc_path, 'Labels/')
convert_annotation(name_without_extent, annotation_dir, yolo_labels_dir)
train_file.close()
test_file.close()
VOC_train_file.close()
VOC_test_file.close()
7. 对数据集进行划分
import os
import shutil
import random
ratio=0.1
img_dir='./voc_dataset/JPEGImages' #图片路径
label_dir='./voc_dataset/Labels'#生成的yolo格式的数据存放路径
train_img_dir='./voc_dataset/images/train2017'#训练集图片的存放路径
val_img_dir='./voc_dataset/images/val2017'
train_label_dir='./voc_dataset/labels/train2017'#训练集yolo格式数据的存放路径
val_label_dir='./voc_dataset/labels/val2017'
if not os.path.exists(train_img_dir):
os.makedirs(train_img_dir)
if not os.path.exists(val_img_dir):
os.makedirs(val_img_dir)
if not os.path.exists(train_label_dir):
os.makedirs(train_label_dir)
if not os.path.exists(val_label_dir):
os.makedirs(val_label_dir)
names=os.listdir(img_dir)
val_names=random.sample(names,int(len(names)*ratio))
cnt_1=0
cnt_2=0
for name in names:
if name in val_names:
#cnt_1+=1
#if cnt_1>100:
#break
shutil.copy(os.path.join(img_dir,name),os.path.join(val_img_dir,name))
shutil.copy(os.path.join(label_dir, name[:-4]+'.txt'), os.path.join(val_label_dir, name[:-4]+'.txt'))
else:
#cnt_2+=1
#if cnt_2>1000:
#break
shutil.copy(os.path.join(img_dir, name), os.path.join(train_img_dir, name))
shutil.copy(os.path.join(label_dir, name[:-4] + '.txt'), os.path.join(train_label_dir, name[:-4] + '.txt'))
执行完第七个步骤后,数据集的文件分布如下所示,其中,images,Labels中的文件即yolov8训练时所需要的:
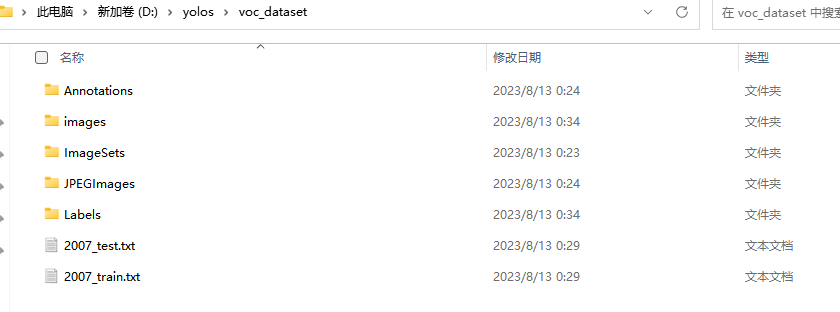
8.训练
8.1 如果运行的时候出现如下报错,进入虚拟环境中搜索libiomp5md.dll,删掉一个即可
OMP: Error #15: Initializing libiomp5md.dll, but found libiomp5md.dll already initialized
8.2 训练时需要修改的文件如下,修改文件的路径如下:
D:\yolos\ultralytics\ultralytics\cfg\datasets\myVOC.yaml
# Ultralytics YOLO 🚀, AGPL-3.0 license# PASCAL VOC dataset http://host.robots.ox.ac.uk/pascal/VOC by University of Oxford# Example usage: yolo train data=VOC.yaml# parent# ├── ultralytics# └── datasets# └── VOC ← downloads here (2.8 GB)# Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]path: ../voc_dataset/
train: # train images (relative to 'path') 16551 images - images/train2017
val: # val images (relative to 'path') 4952 images - images/train2017
test: # test images (optional) - images/train2017
# Classesnames:
0: person
1: cup
2: umbrella
网络配置参数:
D:\yolos\ultralytics\ultralytics\cfg\models\v8\yolov8.yaml
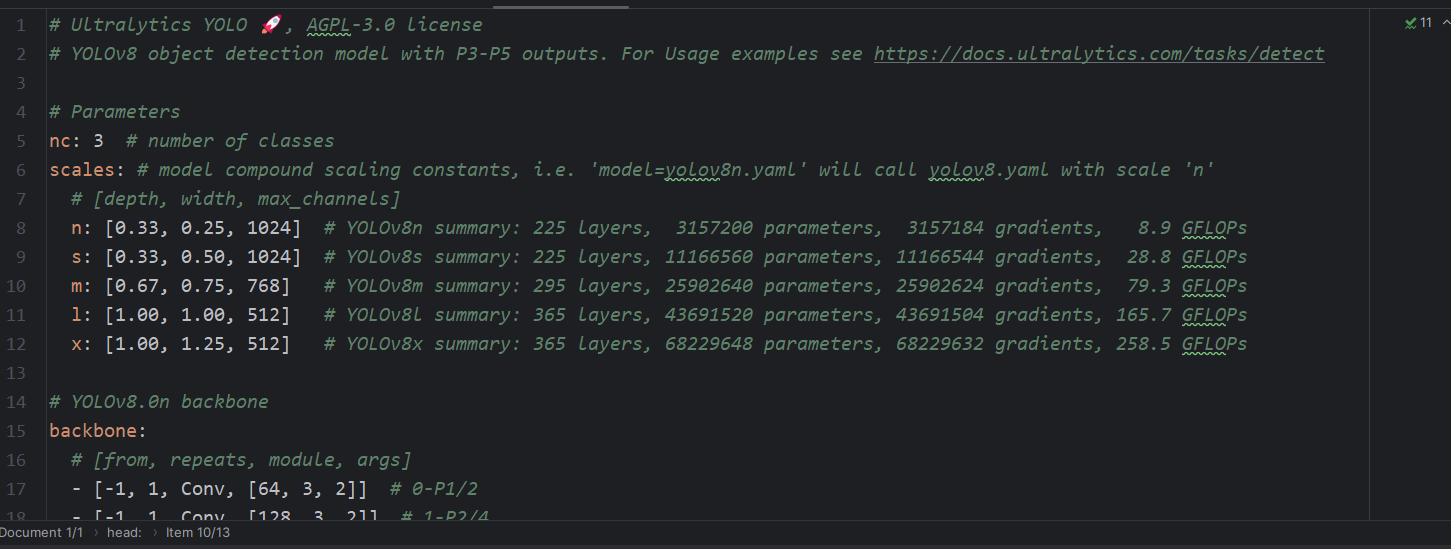
下面的文件是网络训练时的参数,可以进行修改,如果训练的次数少,没有结果,可以修改该配置里面的conf
D:\yolos\ultralytics\ultralytics\cfg\default.yaml
8.3 训练
修改完成后,训练完整代码如下:
from multiprocessing import freeze_support
import cv2
from ultralytics import YOLO
def main():
# Load a model
model = YOLO("yolov8n.yaml") # build a new model from scratch
model = YOLO("yolov8n.pt") # load a pretrained model (recommended for training)
# Use the model
model.train(data="myVOC.yaml", epochs=100) # train the model
metrics = model.val() # evaluate model performance on the validation set
if __name__ == '__main__':
freeze_support()
main()
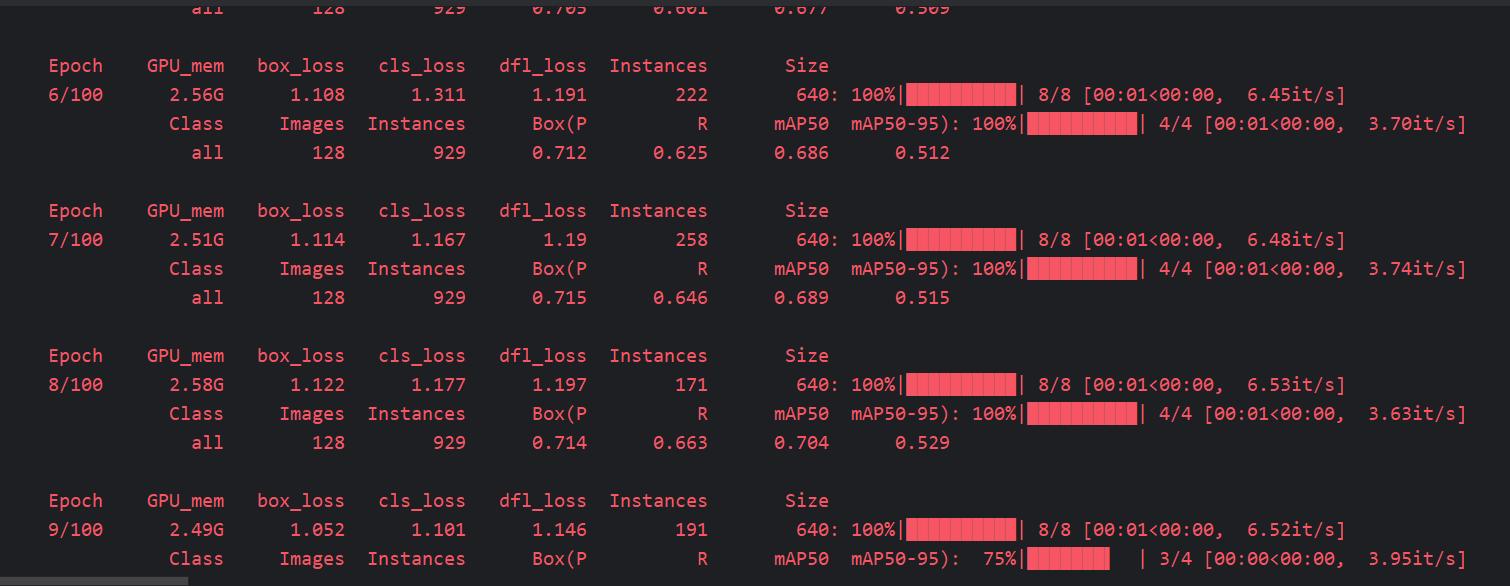
训练结果,
训练的结果和模型,在文件夹runs中:
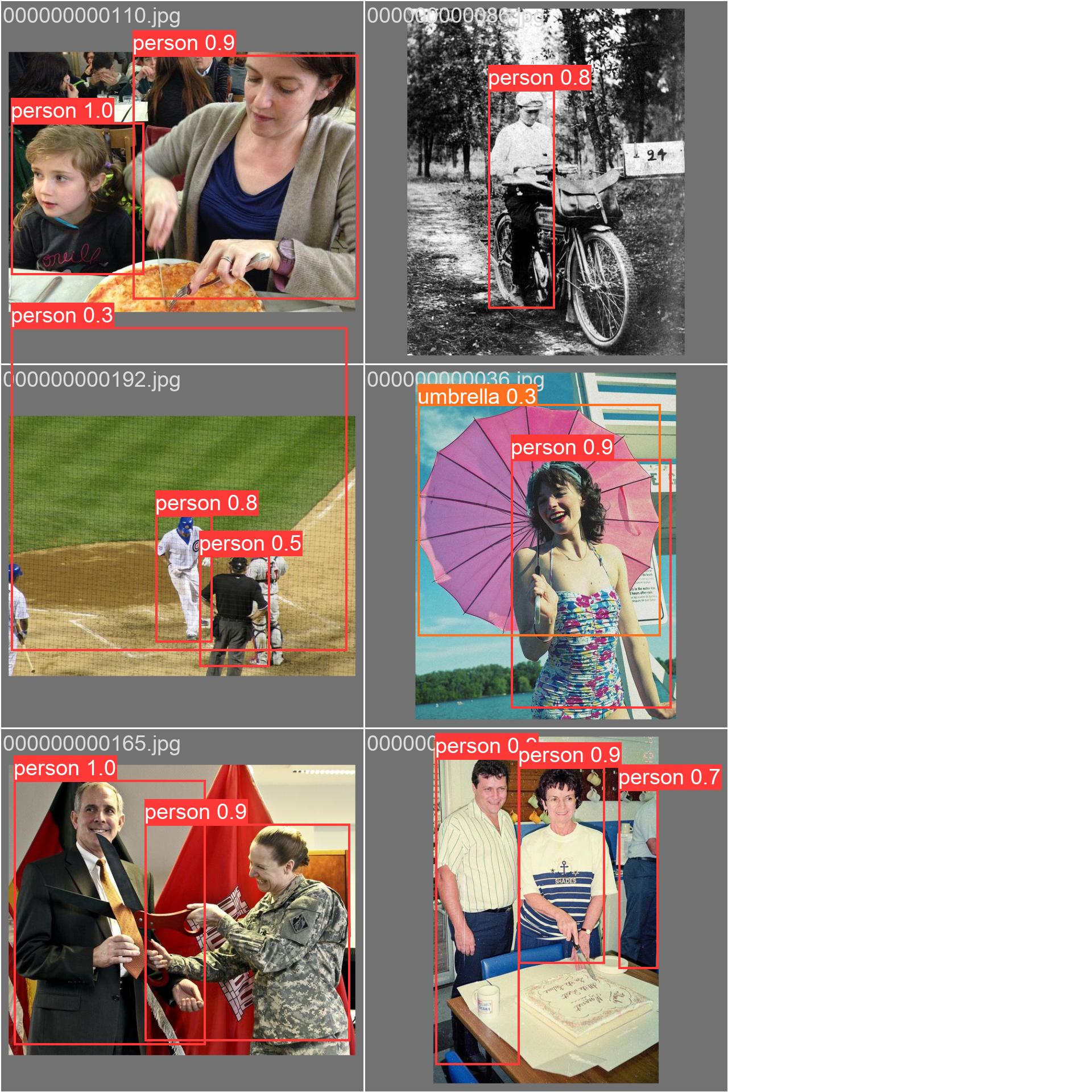
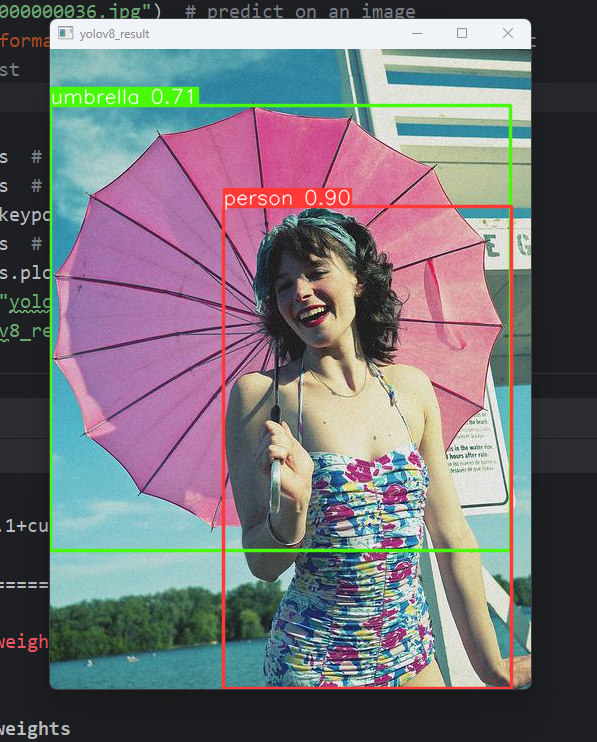
9. Predict 预测
预测完整代码如下:
代码如下,运行的时候需要注意修改模型的路径
from multiprocessing import freeze_support
import cv2
from ultralytics import YOLO
def main():
# Load a model
model = YOLO("yolov8n.yaml") # build a new model from scratch
model = YOLO("runs/detect/train18/weights/best.pt") # load a pretrained model (recommended for training)
results = model("000000000036.jpg") # predict on an image
path = model.export(format="onnx") # export the model to ONNX format
# Process results list
for res in results:
boxes = res.boxes # Boxes object for bbox outputs
masks = res.masks # Masks object for segmentation masks outputs
keypoints = res.keypoints # Keypoints object for pose outputs
probs = res.probs # Probs object for classification outputs
res_plotted = res.plot()
cv2.namedWindow("yolov8_result", cv2.WINDOW_NORMAL)
cv2.imshow("yolov8_result", res_plotted)
cv2.waitKey(0)
if __name__ == '__main__':
freeze_support()
main()
最终输出结果如下:
10. ONNX
path = model.export(format="onnx") # export the model to ONNX format
这句代码输出onnx格式的模型,可以通过提示查看网络结果:
运行完成后,terminal中会出现以下提示,可以点击网址,然后从网址中打开路径中的best.onnx,即可查看网络模型。