针对python使用过程中,经常使用的代码片段进行总结,梳理
python3学习–实用代码片段-1
文章目录
- @property 装饰器
- 查看参数类型
- 序列化
- 反转序列
- 列表全展开(生成器版)
- 在jupyter lab使用echarts画图
- 正则匹配
- 常用元字符
- 常用通用字符
- 使用示例
- 字符串 与 字节互转
- 探测字节的编码
@property 装饰器
既要保护类的封装特性,又要让开发者可以使用“对象.属性”的方式操作类属性,Python 提供了 @property 装饰器。
class Rect:
def __init__(self, area):
self.__area = area
@property
def area(self):
return self.__area
@area.setter
def area(self, value):
self.__area = value
@area.deleter
def area(self):
self.__area = 0
rect = Rect(80)
print("矩形的面积是:", rect.area)
rect.area = 30
print("修改后的面积:",rect.area)
del rect.area
print("删除后的area值为:",rect.area)
查看参数类型
python五类参数:位置参数,关键字参数,默认参数,可变位置或关键字参数的使用
def f(a,*b,c=10,**d):
print(f'a:{a},b:{b},c:{c},d:{d}')
from inspect import signature
for name,val in signature(f).parameters.items():
print(name,val.kind)
f(1, 2, 5, width=10, height=20)
f(1, c=12)
f(1, width=10, height=20, c=0)
f(1, width=10, height=20, c=0)
def f2(*, e, f=2, **g):
print(f'e:{e},f:{g},g:{g}')
参数类型:
- a POSITIONAL_OR_KEYWORD
- b VAR_POSITIONAL
- c KEYWORD_ONLY
- d VAR_KEYWORD
- e KEYWORD_ONLY
- f KEYWORD_ONLY
- g VAR_KEYWORD

注意:
f2(1) 报:f2() takes 0 positional arguments but 1 was given
只有使用f2(e=1)进行调用
序列化
class Student():
def __init__(self,**args):
self.ids = args['ids']
self.name = args['name']
self.address = args['address']
xiaoming = Student(ids = 1,name = 'xiaoming',address = '北京')
xiaohong = Student(ids = 2,name = 'xiaohong',address = '南京')
import json
json.dump([xiaoming, xiaohong], default=lambda obj: obj.__dict__,
ensure_ascii=False, indent=0, sort_keys=True)
展示结果
[
{
"address": "北京",
"ids": 1,
"name": "xiaoming"
},
{
"address": "南京",
"ids": 2,
"name": "xiaohong"
}
]
反转序列
[1,2,3][::-1] # [3,2,1]
'abcde'[::-1] #edcba
列表全展开(生成器版)
#多层列表展开成单层列表
a=[1,2,[3,4,[5,6],7],8,["python",6],9]
def function(lst):
for i in lst:
if type(i)==list:
yield from function(i)
else:
yield i
print(list(function(a))) # [1, 2, 3, 4, 5, 6, 7, 8, 'python', 6, 9]
在jupyter lab使用echarts画图
from pyecharts.globals import CurrentConfig,NotebookType
CurrentConfig.NOTEBOOK_TYPE = NotebookType.JUPYTER_LAB
from pyecharts.charts import Bar
import pyecharts.options as opts
import numpy as np
def bar_chart() -> Bar:
c = (
Bar()
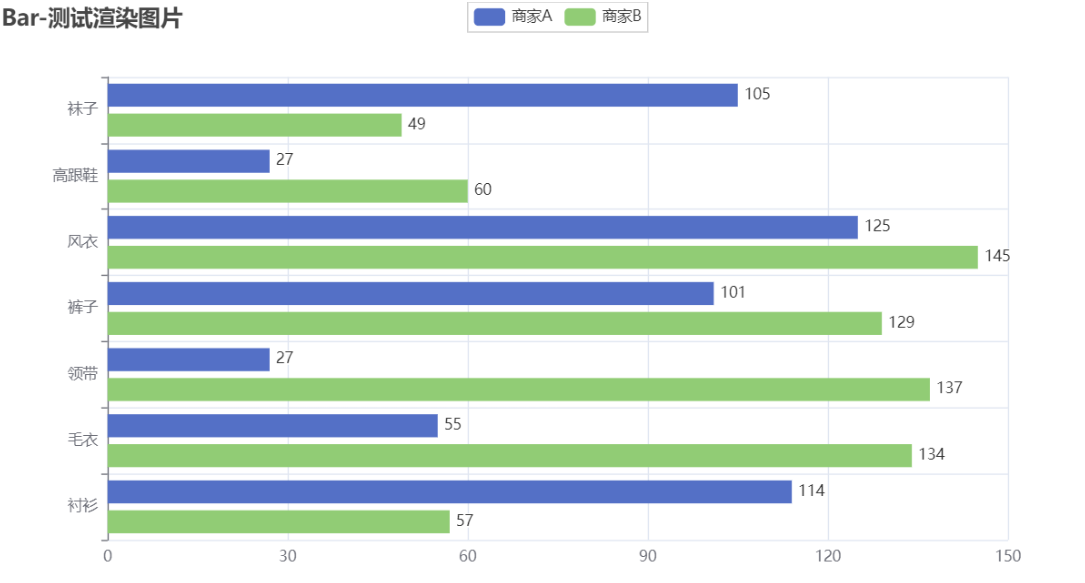
.add_xaxis(["衬衫", "毛衣", "领带", "裤子", "风衣", "高跟鞋", "袜子"])
.add_yaxis("商家A", [114, 55, 27, 101, 125, 27, 105])
.add_yaxis("商家B", [57, 134, 137, 129, 145, 60, 49])
.reversal_axis()
.set_series_opts(label_opts=opts.LabelOpts(position="right"))
.set_global_opts(title_opts=opts.TitleOpts(title="Bar-测试渲染图片"))
)
return c
bar = bar_chart()
bar.render_notebook()
正则匹配
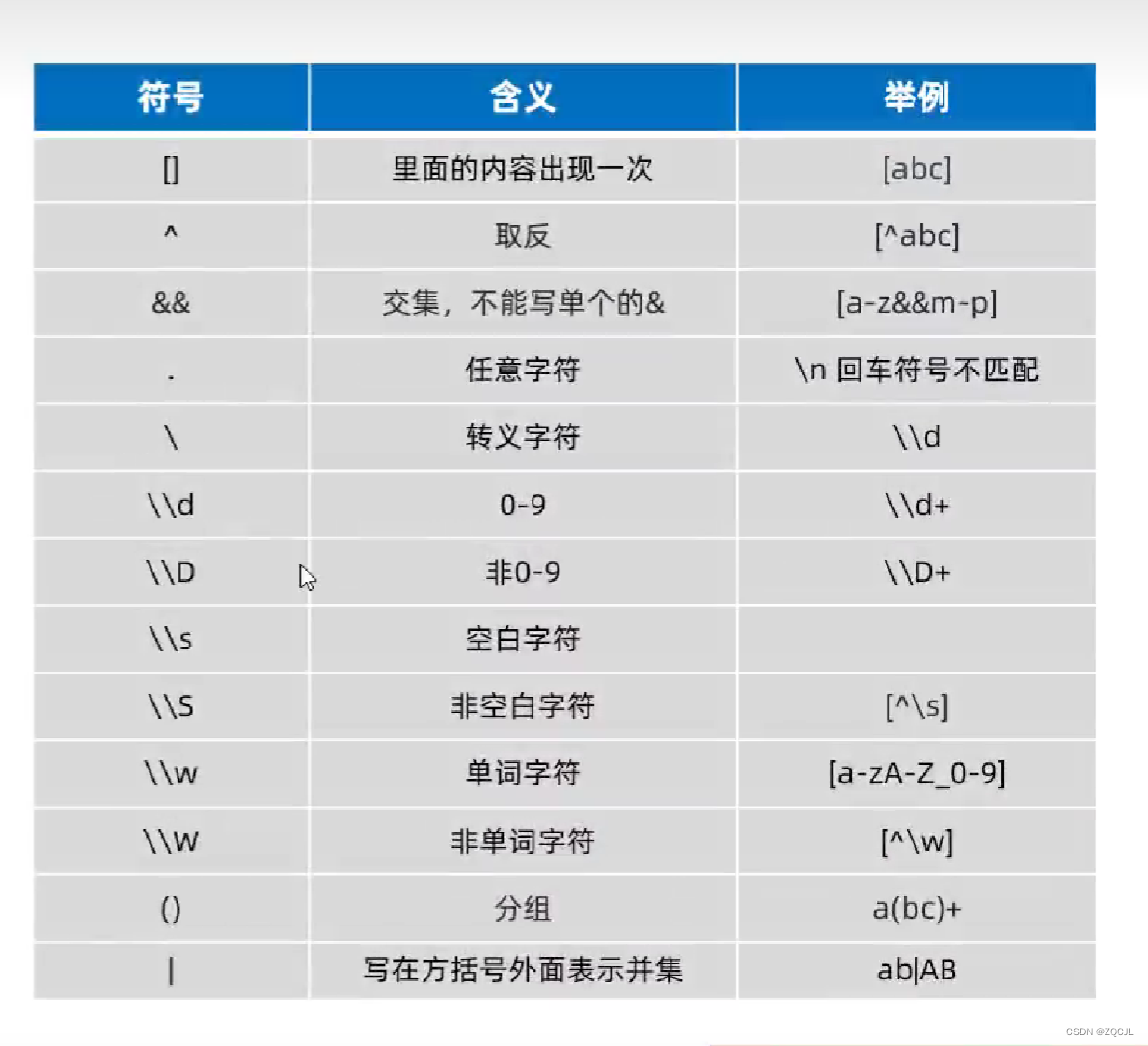
常用元字符
. 匹配任意字符
^ 匹配字符串开始位置
$ 匹配字符串中结束的位置
* 前面的原子重复0次、1次、多次
? 前面的原子重复0次或者1次
+ 前面的原子重复1次或多次
{n} 前面的原子出现了 n 次
{n,} 前面的原子至少出现 n 次
{n,m} 前面的原子出现次数介于 n-m 之间
( ) 分组,需要输出的部分
常用通用字符
\s 匹配空白字符
\w 匹配任意字母/数字/下划线
\W 和小写 w 相反,匹配任意字母/数字/下划线以外的字符
\d 匹配十进制数字
\D 匹配除了十进制数以外的值
[0-9] 匹配一个0-9之间的数字
[a-z] 匹配小写英文字母
[A-Z] 匹配大写英文字母
使用示例
s = 'This,,, module ; \t provides|| regular ; '
words = re.split('[,\s;|]+',s) #这样分隔出来,最后会有一个空字符串
words = [i for i in words if len(i)>0]
# re.I 忽略大小写
s = 'That'
pat = r't'
r = re.findall(pat,s,re.I)
# 查找第一个匹配串
s = 'i love python very much'
pat = 'python'
r = re.search(pat,s)
print(r.span()) #(7,13)
# 查看所有匹配
s = '山东省潍坊市青州第1中学高三1班'
pat = '1'
r = re.finditer(pat,s)
for i in r:
print(i)
# 替换匹配的子串
content="hello 12345, hello 456321"
pat=re.compile(r'\d+') #要替换的部分
m=pat.sub("666",content)
字符串 与 字节互转
>>> bytes('人生苦短,我用Python',encoding='gb2312')
b'\xc8\xcb\xc9\xfa\xbf\xe0\xb6\xcc\xa3\xac\xce\xd2\xd3\xc3Python'
>>>
>>> b'\xc8\xcb\xc9\xfa\xbf\xe0\xb6\xcc\xa3\xac\xce\xd2\xd3\xc3Python'.decode('gb2312')
'人生苦短,我用Python'
探测字节的编码
>>> import chardet
>>> chardet.detect(b'\xc8\xcb\xc9\xfa\xbf\xe0\xb6\xcc\xa3\xac\xce\xd2\xd3\xc3Python')
{'encoding': 'GB2312', 'confidence': 0.99, 'language': 'Chinese'}