QIIME 2用户文档. 11元数据
Metadata in QIIME 2
https://docs.qiime2.org/2023.5/tutorials/metadata/
注:此实例需要一些基础知识,要求完成本系列文章前两篇内容:《1简介和安装Introduction&Install》和4《人体各部位微生物组分析MovingPicture》。
详者注:什么是元数据?是描述数据的数据,样本信息是样本元数据,物种注释是特征元数据。
元数据提供了从数据中获得生物学发现的关键。在QIIME 2中,样本元数据可以包括更多技术细节,例如在多次测序批次中用于每个样本的DNA条形码,或者样本的描述,例如每个样本来自人类微生物组对应时间序列研究中的分组、时间点和身体部位。特征元数据通常是特征注释,例如分配给序列变量或OTU的物种注释。QIIME 2中的许多插件都使用样本和特征元数据,本教程(以及其他QIIME 2教程)中提供了示例,说明如何在自己的微生物组分析中使用元数据。
元数据通常用于特定的微生物组研究而编写,收集样本元数据通常是在开始QIIME 2分析之前要进行的第一步。由研究人员决定哪些信息是作为元数据收集和跟踪的。QIIME 2不限制期望存在的元数据类型;没有强制执行的“元数据标准”。这是你跟踪任何你认为对你的分析很重要的信息的机会,不幸的是,QIIME 2不能为你收集这些信息。如果有疑问,尽可能多的收集元数据,因为您可能无法追溯收集某些类型的信息。
提示:虽然QIIME 2没有对要收集的元数据类型执行标准,但MIMARKS标准 (NBT:扩增子及其他测序的最小信息标准和测序规范(MIMARKS) )为微生物组研究提供了建议,并可能有助于确定研究中要收集的信息。如果计划将数据存储在数据存档(例如ENA或QIITA)中,那么确定存档所期望的元数据类型也很重要,因为每个存档可能都有其自己特定的要求。数据提交教程,详见:中国核酸数据库GSA数据提交指南,以及 扩增子16S实例 和 宏基因组实例。
元数据格式要求
Metadata Formatting Requirements
QIIME 2元数据通常存储在TSV(即制表符分隔,Tab-separated values)文件中。这些文件通常具有.tsv或.txt文件扩展名,但QIIME 2使用什么文件扩展名并不重要。TSV文件是用于存储表格数据的简单文本文件,其格式受多种软件支持,如从电子表格程序和数据库中编辑、导入和导出。因此,使用您选择的软件操作编辑QIIME 2元数据通常很简单。如果有疑问,我们建议使用电子表格程序(如Microsoft Excel或Google工作表)编辑和导出元数据文件。
注: 除了TSV文件之外,QIIME 2对象(即qza文件)也可以用作元数据。有关详细信息,请参阅下面使用QIIME 2对象作为元数据的部分。QIIME 2将来还可能支持其他文件格式。
QIIME 1用户: 在QIIME 1中,TSV元数据文件被称为映射文件(mapping files)。在QIIME 2中,我们将这些文件称为元数据文件,但它们在概念上是相同的。QIIME 2元数据文件与QIIME 1映射文件向后兼容,这意味着您可以在QIIME 2中使用现有的QIIME 1映射文件,而无需对该文件进行修改。
以下各节介绍了QIIME 2元数据文件的格式要求,以及如何验证元数据文件。由于TSV文件没有通用标准,因此必须遵守如下要求,并了解QIIME 2如何解释文件内容,以充分利用元数据!
元数据验证
Metadata Validation
详者注:国内使用Google不方便,一般在Excel表中统计和整理元数据即可。
存储在谷歌工作表中的样品和功能元数据文件可以使用keemi插件进行验证。选择加载项>Keemi>验证QIIME 2元数据文件以验证存储在谷歌工作表中的元数据。
QIIME 2还将在软件使用元数据文件时自动验证该文件。但是,建议使用keemi验证元数据,因为每次运行keemi时都会显示所有验证错误和警告信息的报告。在QIIME 2中加载元数据通常一次只会出现一个错误,特别是在元数据有很多问题的情况下,这会使识别和解决验证问题变得很麻烦。
注:将来,将有一个QIIME元数据验证命令来在QIIME 2中执行
keemi类似的验证(例如,如果使用Google工作表对您来说不是一个可选项,中国大陆很多用户使用Google工作表存在一定困难)。
前导和尾随空格字符
Leading and trailing whitespace characters
如果元数据中的任何单元格包含前导或尾随空格字符(例如空格、制表符),则加载文件时将忽略这些字符。因此,前导和尾随空格字符不重要,因此包含值“gut”和“ gut ”的单元格是等效的。此规则在下面描述的任何其他规则之前应用。
注释和空行
Comments and Empty Rows
第一个单元格以井号(#)开头的行被解释为注释,并可能出现在文件中的任何位置。注释行被QIIME 2忽略,仅供参考。不支持行内注释(类似代码中使用的行末注释)。
空行(例如空行或仅由空单元格组成的行)可能出现在文件中的任何位置,并被忽略。
标识符列
Identifier Column
元数据文件中的第一列是标识符(ID)列。此列定义与您的研究关联的样本或功能ID。不建议在单个元数据文件中混合样本和功能ID;将样本和功能元数据存储在单独的文件中。
ID列名(即ID行开头)必须是以下值之一。下面列出的值不能用于命名文件中的其他ID或列。
不区分大小写:
id
sampleid
sample id
sample-id
featureid
feature id
feature-id
大小写敏感的以下样品列名,兼容QIIME 1、Biom格式和QITTA
- #SampleID
- #Sample ID
- #OTUID
- #OTU ID
- sample_nameID(样品名)命名的规则:
ID可以由任何Unicode字符组成,但不能以井号(#)开头,因为这些行将被解释为注释并被忽略。
有关在研究中选择标识符的建议,请参阅下方标识符建议一节。
ID不能为空(即,它们必须至少包含一个字符)。
ID必须唯一(执行精确的字符串匹配以检测重复项)。
文件中必须至少存在一个ID。
ID不能使用上面列出现过的任何保留ID列名称。
标识符的建议
Recommendations for Identifiers
QIIME 2的目标是在元数据文件的所有单元格中支持任意Unicode字符。但是,考虑到任何人都可以开发QIIME 2插件和接口,我们不能保证任意Unicode字符可以与所有插件和接口一起使用。因此,我们可以向用户推荐在标识符中应该安全使用的字符,并且我们正在为插件和接口开发人员准备资源,以帮助他们的软件尽可能兼容性更好(robust, 稳定)。当开发人员资源可用时,我们将在QIIME 2论坛的开发人员讨论栏目中宣布。
带有问题字符的样本和功能标识符往往会给我们的用户带来最常碰到的问题。根据我们对QIIME 1、QIIME 2以及其他生物信息学和命令行工具的经验,我们可以为标识符推荐以下属性:
标识符的长度应不超过36个字符;
标识符只能包含ASCII字母数字字符(即[A-Z]、[A-Z]或[0-9]范围内)、句点(.)字符或短划线(-)字符;
(尽可能仅使用字母数字组合,且仅以字母开头,可兼容更多分析工具)
要记住的一个重要点是,有时示例元数据中的值可以成为标识符。
例如,分类法注释可以在
qiime taxa collapse后成为特征标识符,而示例或特征元数据值可以在应用qiime feature-table group后成为标识符。如果您计划在元数据值可以成为标识符的地方应用这些或类似的方法,那么如果这些值也符合这些标识符建议,您将不太可能遇到问题。
为了帮助用户了解这些建议,Keemi元数据验证器将警告用户不符合上述建议的标识符。
用户可能对
cual-id(https://msystems.asm.org/content/1/1/e00010-15 原作者开发的一款样本命名软件)软件感兴趣,以帮助创建样本标识符cual-id文件还提供了一些关于如何设计标识符的讨论。
注: 一些生物信息学工具对标识符的要求可能比这里概述的建议更严格。例如,Illumina示例表标识符不能具有点
.字符,而我们在推荐的字符集中包含这些字符,尤其是使用USEARCH软件时样本名不能有点,因为点是样本名与序列ID的分割符。同样,phylip要求标识符最多为10个字符,而我们建议长度不超过36个字符。如果计划导出数据,在对标识符有更严格要求的其他工具在分析,我们建议您在QIIME 2分析中也遵循这些要求,以简化后续处理步骤。注: 这里建议的长度(36个字符或更少)设计为尽可能短,同时仍然支持用破折号格式化的UUID版本4。
元数据列
Metadata Columns
ID列是元数据文件中的第一列,可以选择后面跟随定义与每个样本或功能ID关联元数据的附加列。元数据文件不需要具有附加的元数据列,因此仅包含ID列的文件是有效的QIIME 2元数据文件。
以下规则适用于列名:
可以由任何Unicode字符组成。
不能为空(即列名必须至少包含一个字符)。
必须唯一(执行精确的字符串匹配以检测重复项)。
列名不能使用上面列标识符列中描述的任何保留ID列名。
以下规则适用于列值:
可以由任何Unicode字符组成。
空单元格表示缺失数据。其它值(如NA)不会被解释为缺失数据;
只有空单元格才被识别为“缺失missing”。
请注意,仅由空白字符组成的单元格也被解释为缺失数据,因为前导和尾随的空白字符总是被忽略,从而有效地使单元格为空。
注意: 空单元格只表示缺失数据,但不表示可能缺失哪种类型的数据。您可以使用您选择的其他值来表示不同类型的缺失数据(例如,“不适用not applicable”与“未收集not collected”)。这些自定义值不会被解释为QIIME 2中的缺失数据,但在进一步分析之前,您仍然可以记录并使用这些“缺失”的元数据值对数据执行筛选(例如,使用QIIME功能表筛选样本可根据自定义“缺失”值筛选样本)。
列类型
Column Types
QIIME 2目前支持分类和数字元数据列。默认情况下,QIIME 2将尝试推断每个元数据列的类型:如果该列仅包含数字或缺少的数据,则该列将被推断为数字。否则,如果列包含任何非数字值,则该列将被推断为分类列。分类列和数字列都支持缺失数据(即空单元格)。
QIIME 2支持可选的comment指令,允许用户显式地声明列的类型,避免了上面描述的列类型推断。如果有一列看起来是数字的,但实际上应被视为分类元数据(例如样品分组列,其中分组类型被标记为1、2、3会被当时数值列),则这一点很有用。显式声明列的类型也会使元数据文件更具描述性,因为预期的列类型包含在元数据中,而不是依赖软件来推断类型(这并不总是透明的)。
注意:包含非数字元数据(例如分类数据)的列不能设置为列类型。
numeric
您可以使用可选的注释指令手动或通过 q2cli 开发人员工具在元数据文件中声明列类型。
可以使用可选的comment指令在元数据文件中声明列类型。comment指令必须出现在表头的正下方。该行的第一个单元格必须是#q2:types,以指示该行是注释指令。后续单元格可以包含类别值categorical或数字值numeric(大小写均可)。如果不希望将类型赋给列(在这种情况下将推断该类型),也支持空单元格。因此,在不必为元数据中的每一列声明类型的情况下,很容易包含此comment指令。
此功能现在也可以通过QIIME 2的命令行界面直接通过该工具支持。此工具允许对元数据文件列类型进行批量规范,设置为分类或数字。此工具使用上述注释指令,但允许内联数据操作(或通过自定义脚本自动执行列类型分配的能力),这可能是比手动文件操作更可靠的方法。此工具的详细教程和示例用法可以在 QIIME 2实用程序教程页面上找到。。qiime tools cast-metadata
小提示:使用QIIME元数据表查看QIIME 2元数据的列类型。无论您使用的是comment指令、类型推断还是这两种方法的组合,这都是有效的。
注意: 在QIIME 2和QIIME 1的早期版本中,元数据列通常被称为元数据类别。既然我们支持元数据列类型化,这允许您判断一个列是否包含数字或分类数据,那么我们最终将使用诸如分类元数据类别或数字元数据类别之类的术语,这可能会令人困惑。我们现在避免使用术语
category,除非它在分类元数据的上下文中使用。我们已经尽了最大努力更新了我们的软件和文档,以使用元数据列(metadata column)的叫法而不是元数据类别(metadata category),但是仍然可能会有以前的研究中使用此类名称。注意
#q2:typescomment指令是唯一支持的comment指令;其他指令可能会在将来添加(例如q2:units)。因此,不允许以#q2:开头的行,因为我们将保留该命名空间以供将来的注释指令使用。
数字格式化
Number Formatting
如果要将列解释为数字元数据列(通过列类型推理或使用#q2:types 注释指令指定),则必须按照以下规则格式化列中的数字:
使用十进制数字系统:
ASCII字符[0-9],
.对于可选的小数点,和+和-分别表示正负号。示例:
123、123.45、0123.40、-0.000123、+1.23
科学记数法可与数字记数法一起使用;
支持e和E
示例:
1E9,1.23E-4,-1.2E-08,+4.5E+6
总共只支持15位数字(包括小数点前后),以保持在64位浮点规范内。
总数超过15位的数字不受支持,将导致未定义的行为;
不支持非数字(例如 NaN、nan)或无穷大(例如 Inf、-Infinity)的常用表示。
对丢失的数据使用空单元格(而不是NaN)。
此时在QIIME 2元数据文件中不支持无穷大。
高级文件格式详细信息
Advanced File Format Details
注:如果使用电子表格程序(如Microsoft Excel、Google Sheets)创建和导出QIIME 2元数据文件,则通常不需要本节中的详细信息。如果您手工创建TSV文件(例如在文本编辑器中),或者编写自己的软件来使用或生成QIIME 2元数据文件,那么本节中的详细信息可能很重要,请继续阅读!
TSV行话和语法分析器
TSV Dialect and Parser
QIIME 2尝试与从Microsoft Excel导出的TSV文件进行互操作,因为这是我们在使用中看到的最常见的TSV“行话”。QIIME 2元数据解析器(即读取器)使用python csv模块excel tab方言来解析TSV元数据文件。此方言支持双引号字符(“)包装字段,以允许字段中包含制表符、换行符和回车符。要在字段中包含文本双引号字符,双引号字符必须紧跟在另一个双引号字符之前。有关Excel选项卡方言的完整文档,请参阅python csv模块。
编码和行尾
Encoding and Line Endings
元数据文件必须编码为UTF-8,这与ASCII编码向后兼容。
为了实现互操作性,元数据分析器都支持Unix行尾(\n)、Windows/DOS行尾(\r\n)和“经典Mac OS”行尾(\r)。在QIIME 2中将元数据文件写入磁盘时,行尾将始终为\r\n(Windows/DOS行尾)。
尾随的空单元格和交错数据
Trailing Empty Cells and Jagged Data
元数据分析器忽略出现在由头声明的字段之后的任何尾随的空单元格。这主要是为了与从一些电子表格程序导出的文件进行互操作。这些尾随的单元格/列可能参差不齐(或整齐);在读取文件时,它们将被忽略。
如果一行不包含标题声明的字段,则将填充空单元格以匹配标题长度(同样,这主要是为了与导出的电子表格进行互操作)。
译者注:元数据编写注意事项
为了方便分析,对样品的描述必须包括一些基本信息和格式规范,QIIME2中实验设计/元数据mapping file/metadata基本要求如下:
文件必须是制表符分隔的纯文本文件,建议使用Excel编辑并复制到纯文本编辑器(如editplus, ultraedit等)中保存为UTF-8编码的txt格式;
注释行以#开头,可以出现在文中任意位置,程序会自己忽略;
空行也会被忽略;
第一行为表头,与QIIME1相比不再以#开头,更合理;
表头每列名称必须唯一,不能包括标点符号; 建议实验设计只使用字母和数字,任何符号在后续分析都可能会有问题
文件至少包括除表头外的一行数据;
第一列为样品名,用于标识每个样品,名字必须唯一。
具体实例,可参考:
样品命名注意事项
样品命名编写实例——从简单到复杂
使用元数据
Using Metadata Files
mkdir -p metadata
cd metadata
# 下载示例样本信息
http://www.imeta.science/github/QIIME2ChineseManual/2023.5/moving-pictures/sample-metadata.tsv由于这是一个TSV文件,它可以在各种应用程序中打开和编辑,包括文本编辑器、Microsoft Excel和Google工作表(如果您计划使用Keemi验证元数据)。
QIIME 2还提供了一个可视化工具,用于查看交互表中的元数据:
qiime metadata tabulate \
--m-input-file sample-metadata.tsv \
--o-visualization tabulated-sample-metadata.qzvtabulated-sample-metadata.qzv:元数据可视化文件。
查看 | 下载
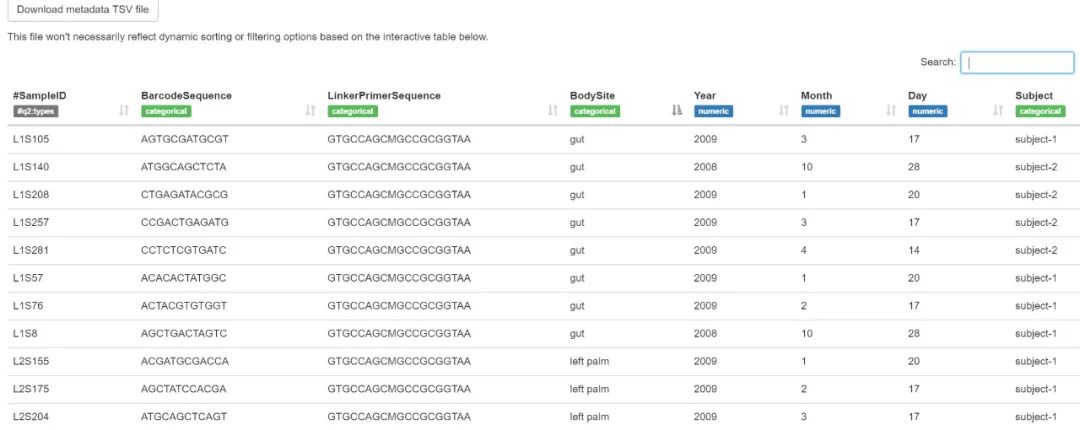
此文件网页中支持排序,筛选。
问题
根据表tabulated-sample-metadata.qzv中的表格,有多少样本与subject-1相关?有多少样本与gut肠道部位有关?提示:使用搜索框和/或列排序选项来帮助执行此查询。
使用QIIME2对象作为元数据
Using QIIME 2 Artifacts as Metadata
除了TSV元数据文件之外,QIIME 2还支持将某些类型的对象作为元数据。这方面的一个例子是SampleData[AlphaDiversity]类型的对象。
要开始将对象理解为元数据,首先下载一个示例对象:
详者注:微生物组分析的Alpha、Beta多样性值,在本质上,也是样本的一种属性,可加入元数据表中,方便后续分析。
# 下载Alpha多样性PD算法的结果
wget -c https://data.qiime2.org/2023.5/tutorials/metadata/faith_pd_vector.qza要将此对象视为元数据,只需将其传递给希望看到元数据的任何方法或可视化工具(例如,metadata tabulate或emperor plot):
qiime metadata tabulate \
--m-input-file faith_pd_vector.qza \
--o-visualization tabulated-faith-pd-metadata.qzv输出对象
faith_pd_vector.qza:多样性元数据可视化。
查看 | 下载
可视化对象
tabulated-faith-pd-metadata.qzv:多样性元数据可视化。
查看 | 下载
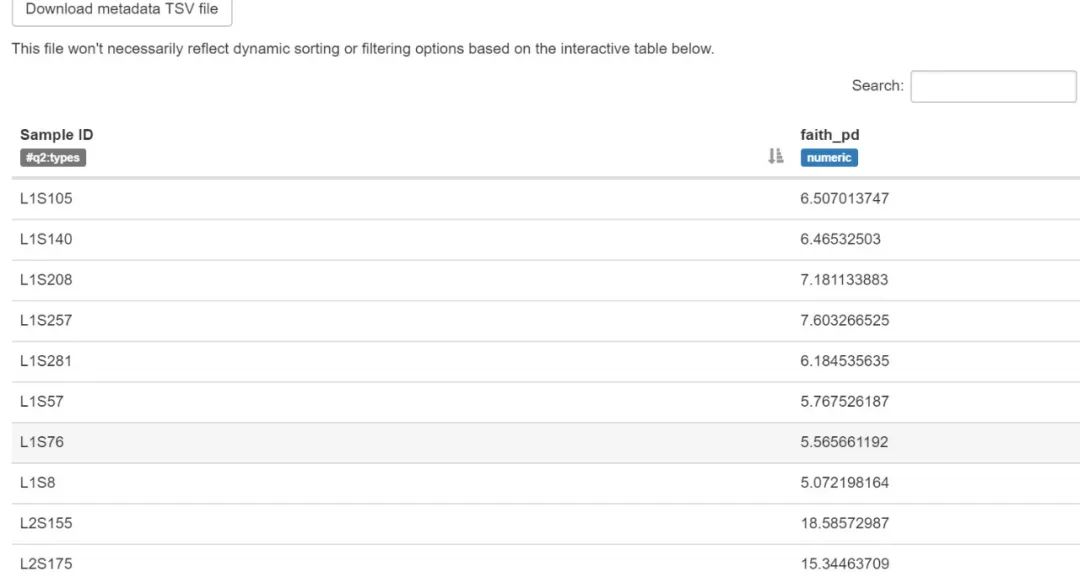
图中的样本新增了对应pd多样性值
问题:Faith’s PD的最大值是多少?最小值是多少?提示:使用列排序功能。
问题:qzv文件包括结果生成的过程,请查看该结果的追溯图,研究分析过程。
合并元数据
Merging metadata
由于元数据可以来自许多不同的源,因此在运行命令时,QIIME 2支持元数据合并。基于上面的示例,只需多次传递--m-input-file就可以将元数据列组合到指定的文件中:
qiime metadata tabulate \
--m-input-file sample-metadata.tsv \
--m-input-file faith_pd_vector.qza \
--o-visualization tabulated-combined-metadata.qzvtabulated-combined-metadata.qzv:多样性元数据可视化。
查看 | 下载
合并后生成的元数据将包含所有指定文件中标识符的交集。换句话说,合并的元数据将只包含在所有提供的元数据文件中共享的标识符。这是一个使用数据库术语的内部联接。
问题: 修改上面的命令,将
SampleData[AlphaDiversity]的均匀度向量(evenness vector)合并到Faith’s PD向量之后。合并三个对象时会发生什么?结果元数据可视化中有多少列?这些列中有多少列表示样本ID?这些列中有多少列表示SampleData[AlphaDiversity]度量?如果元数据文件的顺序颠倒了,可视化会发生什么?提示,仔细查看列顺序。
在QIIME 2中接受元数据的任何地方都支持元数据合并。例如,根据研究元数据或样本alpha多样性为Emperor plot着色可能很有意思。这可以通过提供样本元数据文件和SampleData[AlphaDiversity]对象来实现:
# 组合Alpha和Beta多样性
wget https://data.qiime2.org/2023.5/tutorials/metadata/unweighted_unifrac_pcoa_results.qza
qiime emperor plot \
--i-pcoa unweighted_unifrac_pcoa_results.qza \
--m-metadata-file sample-metadata.tsv \
--m-metadata-file faith_pd_vector.qza \
--o-visualization unweighted-unifrac-emperor-with-alpha.qzv输出对象
unweighted_unifrac_pcoa_results.qza:无权重unifrac PCoA结果。
查看 | 下载
可视化对象
unweighted-unifrac-emperor-with-alpha.qzv:Beta多样性可视化添加Alpha多样性。
查看 | 下载
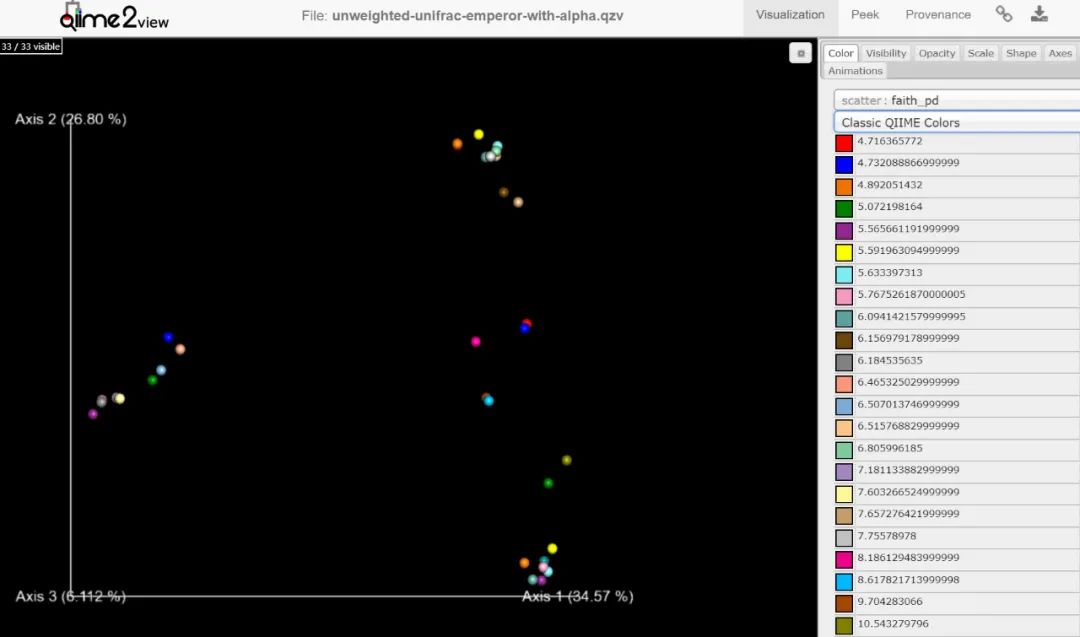
可以按Alpha多样性进行PCoA的着色了,这样探索更有意思
问题:哪一类取样位置有最高的Faith’s进化多样性值?
提示:查看中使用按
body site上色,再按Faith's PD连续着色,两图并列比较试试;
探索特征元数据
Exploring feature metadata
wget https://data.qiime2.org/2023.5/tutorials/metadata/rep-seqs.qza
wget https://data.qiime2.org/2023.5/tutorials/metadata/taxonomy.qza
qiime metadata tabulate \
--m-input-file rep-seqs.qza \
--m-input-file taxonomy.qza \
--o-visualization tabulated-feature-metadata.qzv输出对象
taxonomy.qza:物种注释结果文件。
查看 | 下载
rep-seqs.qza:代表序列。
查看 | 下载
可视化对象
tabulated-feature-metadata.qzv:特征元数据,包括序列、物种注释和置信度。
查看 | 下载

现在已经将序列ID、序列物种注释和置信度合并一起展示了。
问题:所有
.qza都是可查看的元数据吗?使用qiime metadata tabulate自己试试吧。
最后,在元数据表生成的可视化中有可用的导出选项。使用tabulated-feature-metadata.qzv的结果,将数据导出为新的tsv。在TSV查看器或文本编辑器中打开该文件,并注意内容与可视化中的交互式元数据表相同。
问题:是否可以将上述步骤中导出的TSV用作元数据?能够导出元数据有哪些好处(提示:请参阅上面关于元数据合并的讨论)?关于一些潜在的缺点(提示:当数据从QIIME 2导出时,数据来源会发生什么情况)?
译者注:网页中查看可以导出任意格式的结果、并可追溯实验的分析过程、支持筛选、查找和排序。导出后分析过程将不可追溯。
译者简介
刘永鑫,研究员,博士生导师。2014年博士毕业于中国科学院大学生物信息学专业,之后在中国科学院遗传与发育生物学研究所工作历任博士后、工程师、高级工程师,2022年10月加入中国农业科学院深圳农业基因组研究所担任课题组长。研究方向为宏基因组方法开发、功能挖掘和科学传播。参与QIIME 2项目,主导开发了易扩增子(EasyAmplicon)、易宏基因组(EasyMetagenome)、培养组(Culturome)分析流程、数据分析网站(EVenn、ImageGP) 和R包(amplicon、ggClusterNet)等,目标是全面打造宏基因组领域方法学基础设施,推动微生物组学发展。以(共同)第一或通讯作者在Nature Biotechnology、Nature Microbiology、iMeta等期刊发表论文20余篇。合作在Science、Cell Host & Microbe、Microbiome等期刊发表论文20余篇,累计发表论文50余篇,被引用13000+次。主编《微生物组实验手册》专著,由300多位同行参与,共同打造本领域长期更新的中文百科全书。创办宏基因组公众号,15万+同行关注,分享原创文章3千余篇,累计阅读量超4千万,打造本领域最具影响力的科学传播平台。发起《iMeta》期刊,联合全球千位专家共同打造宏基因组学、微生物组和生物信息学顶刊,解决我国本领域期刊出版卡脖子问题。课题组长期招聘博士后、客座研究生,有兴趣可加微信yongxinliu详谈。
王惠铃,湖南农业大学,生物信息学本科在读,在刘永鑫组毕业实习。负责本次版本的更新和测试。
Reference
https://docs.qiime2.org/2023.5/
Evan Bolyen, Jai Ram Rideout, Matthew R. Dillon, Nicholas A. Bokulich, Christian C. Abnet, Gabriel A. Al-Ghalith, Harriet Alexander, Eric J. Alm, Manimozhiyan Arumugam, Francesco Asnicar, Yang Bai, Jordan E. Bisanz, Kyle Bittinger, Asker Brejnrod, Colin J. Brislawn, C. Titus Brown, Benjamin J. Callahan, Andrés Mauricio Caraballo-Rodríguez, John Chase, Emily K. Cope, Ricardo Da Silva, Christian Diener, Pieter C. Dorrestein, Gavin M. Douglas, Daniel M. Durall, Claire Duvallet, Christian F. Edwardson, Madeleine Ernst, Mehrbod Estaki, Jennifer Fouquier, Julia M. Gauglitz, Sean M. Gibbons, Deanna L. Gibson, Antonio Gonzalez, Kestrel Gorlick, Jiarong Guo, Benjamin Hillmann, Susan Holmes, Hannes Holste, Curtis Huttenhower, Gavin A. Huttley, Stefan Janssen, Alan K. Jarmusch, Lingjing Jiang, Benjamin D. Kaehler, Kyo Bin Kang, Christopher R. Keefe, Paul Keim, Scott T. Kelley, Dan Knights, Irina Koester, Tomasz Kosciolek, Jorden Kreps, Morgan G. I. Langille, Joslynn Lee, Ruth Ley, Yong-Xin Liu, Erikka Loftfield, Catherine Lozupone, Massoud Maher, Clarisse Marotz, Bryan D. Martin, Daniel McDonald, Lauren J. McIver, Alexey V. Melnik, Jessica L. Metcalf, Sydney C. Morgan, Jamie T. Morton, Ahmad Turan Naimey, Jose A. Navas-Molina, Louis Felix Nothias, Stephanie B. Orchanian, Talima Pearson, Samuel L. Peoples, Daniel Petras, Mary Lai Preuss, Elmar Pruesse, Lasse Buur Rasmussen, Adam Rivers, Michael S. Robeson, Patrick Rosenthal, Nicola Segata, Michael Shaffer, Arron Shiffer, Rashmi Sinha, Se Jin Song, John R. Spear, Austin D. Swafford, Luke R. Thompson, Pedro J. Torres, Pauline Trinh, Anupriya Tripathi, Peter J. Turnbaugh, Sabah Ul-Hasan, Justin J. J. van der Hooft, Fernando Vargas, Yoshiki Vázquez-Baeza, Emily Vogtmann, Max von Hippel, William Walters, Yunhu Wan, Mingxun Wang, Jonathan Warren, Kyle C. Weber, Charles H. D. Williamson, Amy D. Willis, Zhenjiang Zech Xu, Jesse R. Zaneveld, Yilong Zhang, Qiyun Zhu, Rob Knight & J. Gregory Caporaso#. Reproducible, interactive, scalable and extensible microbiome data science using QIIME 2. Nature Biotechnology. 2019, 37: 852-857. https://doi.org/10.1038/s41587-019-0209-9
猜你喜欢
iMeta简介 高引文章 高颜值绘图imageGP 网络分析iNAP
iMeta网页工具 代谢组MetOrigin 美吉云乳酸化预测DeepKla
iMeta综述 肠菌菌群 植物菌群 口腔菌群 蛋白质结构预测
10000+:菌群分析 宝宝与猫狗 梅毒狂想曲 提DNA发Nature
系列教程:微生物组入门 Biostar 微生物组 宏基因组
专业技能:学术图表 高分文章 生信宝典 不可或缺的人
一文读懂:宏基因组 寄生虫益处 进化树 必备技能:提问 搜索 Endnote
扩增子分析:图表解读 分析流程 统计绘图
16S功能预测 PICRUSt FAPROTAX Bugbase Tax4Fun
生物科普: 肠道细菌 人体上的生命 生命大跃进 细胞暗战 人体奥秘
写在后面
为鼓励读者交流快速解决科研困难,我们建立了“宏基因组”讨论群,己有国内外6000+ 科研人员加入。请添加主编微信meta-genomics带你入群,务必备注“姓名-单位-研究方向-职称/年级”。高级职称请注明身份,另有海内外微生物PI群供大佬合作交流。技术问题寻求帮助,首先阅读《如何优雅的提问》学习解决问题思路,仍未解决群内讨论,问题不私聊,帮助同行。
点击阅读原文,跳转最新文章目录阅读