介绍两篇利用Transformer做图像分类的论文:CoAtNet(NeurIPS2021),ConvMixer(ICLR2022)。CoAtNet结合CNN和Transformer的优点进行改进,ConvMixer则patch的角度来说明划分patch有助于分类。
CoAtNet: Marrying Convolution and Attention for All Data Sizes, NeurIPS2021
论文:https://arxiv.org/abs/2106.04803
CoAtNet: Marrying Convolution and Attention for All Data Sizes
代码:https://github.com/xmu-xiaoma666/External-Attention-pytorch
解读:【图像分类】2021-CoAtNet NeurlPS_relative attention_說詤榢的博客-CSDN博客
CoAtNet论文详解附代码实现 - 知乎
论文导读:CoAtNet是如何完美结合 CNN 和 Transformer的 - 知乎 (zhihu.com)
简介
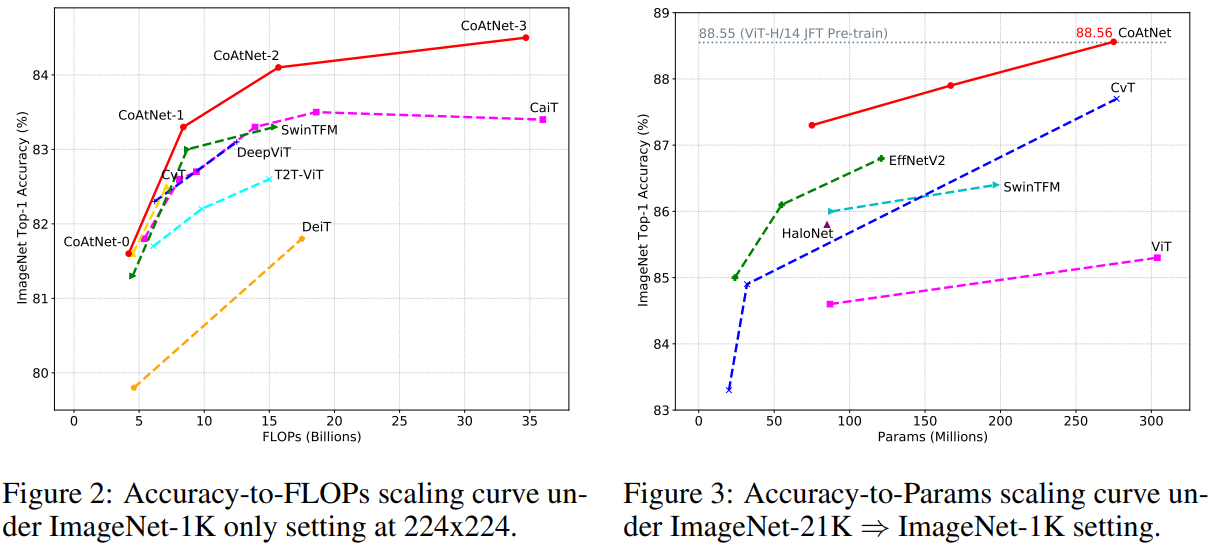
本文证明,尽管 Transformers 具有更强的model capacity(模型能力),但因为缺乏inductive bias(归纳偏置)特性,它的泛化性要落后于 CNN。为了有效地结合二者的长处,论文提出CoAtNets,它的构建主要基于两个关键想法:(1)可以通过简单的 relative attention(相对注意力)将 depthwise Convolution(深度卷积)和 self-Attention(自注意力)自然统一;(2)在提升泛化性、能力和效率方面,按照一定的原则,垂直摆放卷积层和注意力层会非常有效。实验证明,CoAtNets 在多个数据集上,根据不同的资源要求,可以取得 SOTA 的效果。例如,CoAtNet 在 ImageNet 上取得了 86.0 % top-1 准确率,无需额外的数据,如果使用了 JFT 数据,则可达到 89.77 % top-1准确率,超越目前所有的 CNN 和 Transformers。
动机
自从AlexNet,CNN已经成为计算机视觉领域最主要的模型结构。同时,随着自注意力模型如 Transformers 在 NLP 领域取得成功,许多工作都尝试将注意力机制引入计算机视觉,并逐渐超越CNN。实验证明,在数据量充足的情况下,Transformer模型可以比CNN模型的能力更强。但是,在给定数据和计算量的前提下,transformer都没有超过SOTA卷积模型。例如在数据较少的数据集上,transformer表现差于CNN。这表明Transformer可能缺乏归纳偏置特性。而该特性存在于CNN结构中。所以一些工作尝试将卷积网络的归纳偏置融合到transformer模型中,在注意力层中强加上局部感受野,或通过隐式或显式的卷积操作来增强注意力和FFN层,但是,这些方法都关注在某个特性的注入上,缺乏对卷积和注意力结合时各自角色的理解。
本文作者从机器学习的两个基本面,系统地研究了卷积和注意力融合的问题:
- generalization(泛化性)
- model capacity(模型能力)
研究显示得益于归纳偏置先验,卷积网络的泛化性更强,收敛速度更快,而注意力层则拥有更强的模型能力,对大数据集更有益。将卷积和注意力层结合,可以取得更好的泛化性和模型能力;但是,问题是如何将二者有效结合,实现准确率和效率的平衡。
本文作者探讨了以下两点:
- 利用简单的相对注意力,深度卷积可以有效地融合入注意力层。
- 以适当的方式直接堆叠卷积层和注意力层,效果可能惊人地好,泛化性和能力都更高。
CoAtNet由此诞生,具备CNN和transformer的优势。
CoAtNet方法
网络模型
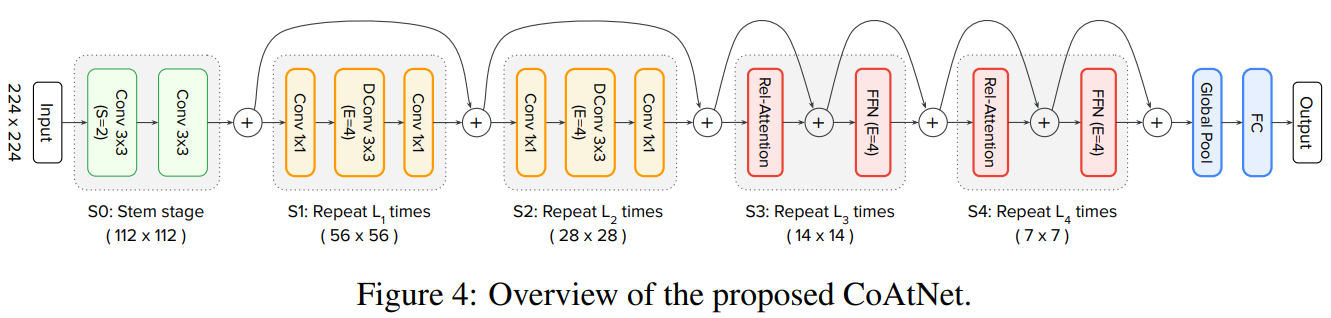
CoAtNet模型由C-C-T-T的形式构成。其中C表示Convolution,T表示Transformer。
其中,block数量以及隐藏层维度不同,CoAtNet有一系列不同容量大小的模型。如表所示
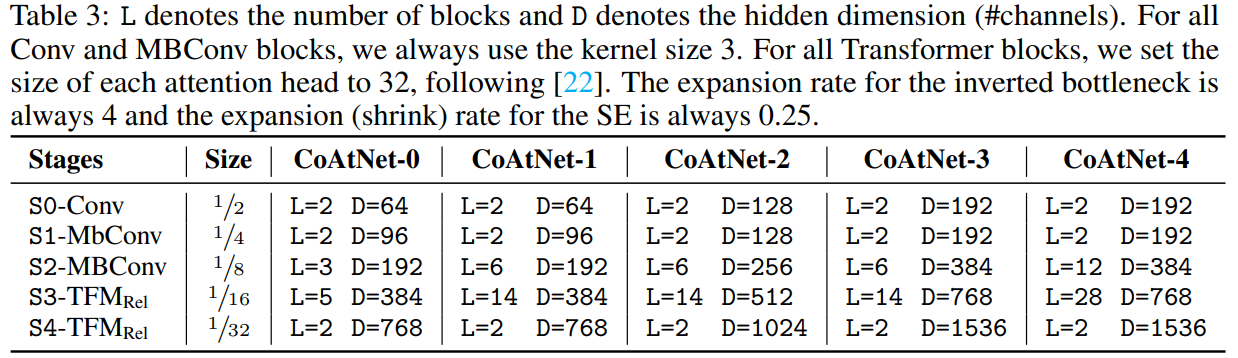
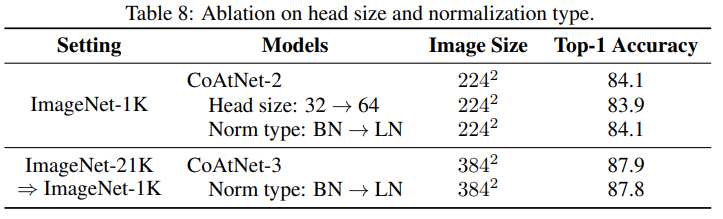
其中,Conv和MBConv模块的卷积核大小为3。Transformer注意力头的大小为32。inverted bottleneck的维度扩展比例为4。SE模块 shrink比例为0.25。
如何完美地将卷积和transformer结合呢?作者将该问题拆分为以下两部分:
- 如何将卷积和自注意力结合在一个计算模块内?
- 如何将不同类别的计算模型垂直的堆叠在一起,形成一个完整的网络。
融合卷积和自注意力
对于卷积,作者主要关注在 MBConv 模块,它利用深度卷积来获取空间联系。因为 Transformers 的 FFN 模块和 MBConv 都使用 “inverted bottleneck” 设计,首先将输入的通道大小扩展4倍,然后将它映射回原来的通道大小,这样可以使用残差连接。
除了都使用inverted bottleneck,作者也注意到,深度卷积和自注意力都可以表示为一个预先定义好的感受野内的数值加权和。卷积需要一个固定的卷积核,从局部感受野中获取信息:

其中,分别是i位置的输入和输出。L(i)表示i位置的相邻区域,即中心点为i的3X3网络。
为了比较,自注意力的感受野涵盖所有的空间位置,根据一对点的归一化后的相似度来计算权值:
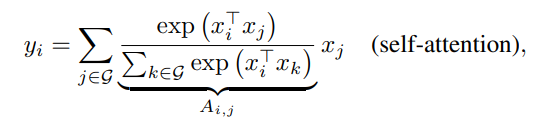
其中G表示全局位置空间。
在研究如何将他们最优地结合之前,先分析一下它们各自的优劣:
- 首先,深度卷积核
是一个与输入无关的静态参数,而注意力
动态的依赖输入的表征。因此,自注意力可以很容易地获取不同空间位置的相互关系,当处理高级别任务时这是非常必须的性质。但是,这种灵活性也带来了容易过拟合的风险,尤其是当数据有限时。
- 其次,给定一对空间点( i , j ) ,相应的卷积权重
只关心二者的相对偏移,即i − j,而不是 i 或 j 的具体数值。通常是指平移不变性,可以在有限的数据集上提升泛化性。因为使用了绝对位置 embedding,标准 ViT 缺少该特性。这就部分解释了为何当数据集有限时,卷积网络通常要比 Transformer 的表现好。
- 最后,感受野大小也是自注意力和卷积的最根本区别。一般而言,较大的感受野能提供更多的语义信息,模型能力就更强。因此,人们将自注意力应用在视觉领域的关键原因就是,它能提供全局感受野。但是,较大的感受野需要非常多的计算量。以全局感受野为例,复杂度相对于空间大小是指数的,这就限制了它的应用范围。

最理想的模型应该具备表1的三点特性。根据等式1和等式2的相似性,最直接的想法就是将在Softmax归一化之前或之后全局静态卷积核和自适应的注意力矩阵相加。如下所示:
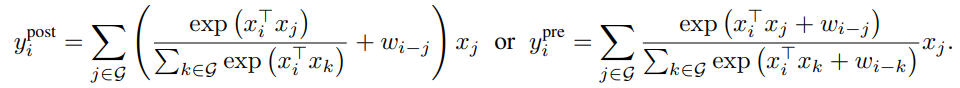
注意,为了确保全局卷积核不会造成参数量爆炸,作者将表示为一个标量,而非等式1中的向量。好处是,通过计算pairwise点积注意力,这样计算开支是最低的。
垂直堆叠网络层
得到一个简洁地将卷积和注意力结合的方式后,下一步就该思考如何利用它们。
如上所述,全局关系相对于空间大小呈指数复杂度。因此,如果直接在原始输入图像上使用等式3的相对注意力,计算会非常慢。要想构建出一个可行的网络,主要有三个选项:
- A:先进行下采样降低空间大小,然后当特征图达到可控的范围后,再使用全局相对注意力。
- B:强行加上局部注意力,将注意力中的全局感受野G约束在一个局部范围L内,就像卷积一样。
- C:将指数增长的 Softmax 注意力替换为线性注意力变体,它对于空间大小只有线性复杂度。
作者实验发现,B和C没有得到合理的效果。对于B,实现局部注意力会带来很多严重的形状变换操作,造成大量的内存读取。在 TPU 加速器上,该操作会非常慢,不仅无法实现全局注意力的加速,也会伤害模型的能力。对于C,实验发现没有取得合理效果。
因此,作者主要针对A选项进行优化。下采样操作可以是一个步长很大的卷积操作(如VIT,步长=16)或者是一个使用逐步池化的多阶段网络。
基于这些选项,作者设计了5个变体的网络结构,并做了实验比较。
- 当用 ViT 时,利用相对注意力直接堆叠 L个 Transformer 模块,记做VIT_REL 。
- 当使用多阶段池化时,我们模拟ConvNets,构建一个有5个阶段的网络(S0,S1,S2,S3 & S4),从S0 到S4 其空间分辨率是逐渐下降的。在每个阶段开始位置,空间大小缩小2倍,增加通道数。第一个阶段S0是一个简单的2层CNN,S1使用 MBConv 模块和 squeeze-excitation 操作,其空间大小对于全局注意力来说太大了。从S2 到S4,可以用 MBConv 或者 Transformer 模块,要求是卷积阶段必须在 Transformer 阶段之前。这个要求是基于一个先验得到的,卷积更擅长处理早期阶段中很常见的局部模式。这样随着 Transformer 阶段的增加,我们就有4种变体,C-C-C-C, C-C-C-T, C-C-T-T 和 C-T-T-T,其中C和T分别表示卷积和Transformer。
作者主要从泛化能力和模型能力对5个变体进行实验。
针对泛化性,本文研究了训练损失和测试精度之间的误差。如果两个模型有着相同的训练损失,那么测试精度更高的模型就应该有着更强的泛化性,因为它对没见过的数据泛化更好。当数据有限时,泛化能力就非常重要。
针对模型能力,作者评估了模型拟合大型数据集上的能力。当训练数据充足时,过拟合就不再是个问题,能力强的模型越有可能取得更好的效果。一般而言,模型越大,能力就越强,所以为了比较公平些,本文保证5个变体模型的大小是差不多的。
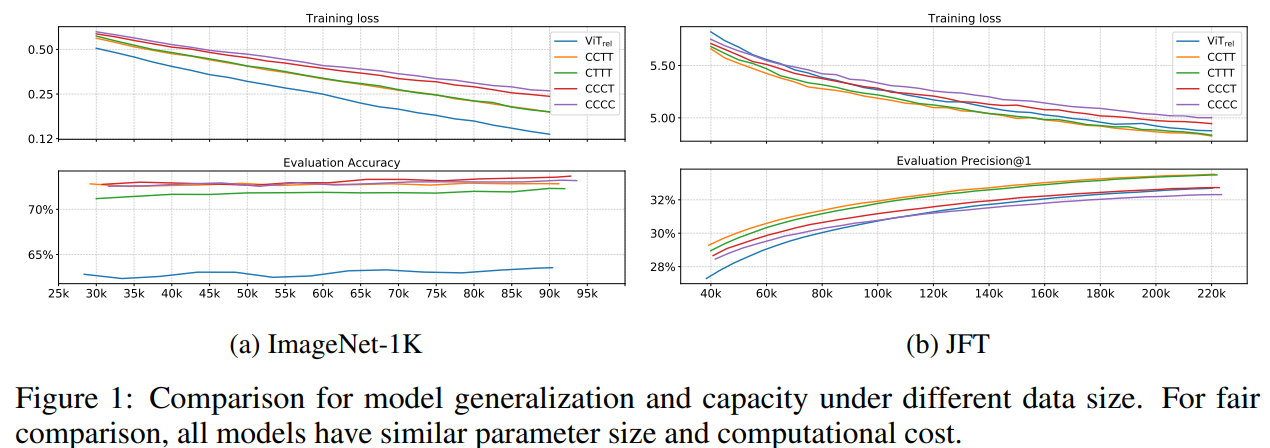
图1展示了模型在不同数据集规模下的泛化能力和模型能力。
从ImageNet上的结果可以看出,对于泛化能力,结论有:
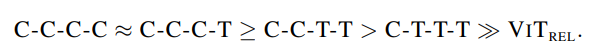
VIT_REL要比其它变体差好多,作者猜测这可能是因为在它激进的下采样过程中,缺失了低层级的信息。在多阶段变体中,整体趋势是,模型中卷积越多,泛化性越好。
针对模型能力,结论有:
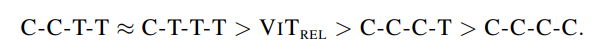
这说明,简单地增加 Transformer 模块并不一定会带来更强的模型能力。一方面,尽管初始化的很糟糕,VIT_REL最终追赶上了另两个带有 MBConv 的变体,表明 Transformer 模块的能力很强。另一方面,C-C-T-T 和C-T-T-T明显优于VIT_REL,表明 ViT 如果步长过大,会丢失很多信息,不利于模型的能力。C-C-T-T ≈C-T-T-T表明,对于低层级信息而言,静态局部操作如卷积的能力可与自适应全局注意力机制相当,但能大幅度降低计算量和内存占用。
最后,为了在C-C-T-T和C-T-T-T之间做决定,作者进行了可迁移性测试,作者在 ImageNet-1K 上对两个在 JFT 数据集上预训练的模型进行微调,训练了30个epochs,比较它们的迁移效果。从表2可以看到,C-C-T-T的效果要好于C-T-T-T,尽管它们的预训练表现差不多。

根据泛化性,模型能力,可迁移性和效率,作者在CoAtNet中采用了C-C-T-T多阶段方案。
关键代码
import torch
import torch.nn as nn
from einops import rearrange
from einops.layers.torch import Rearrange
from collections import OrderedDict
"""
代码来源 https://github.com/KKKSQJ/DeepLearning
"""
__all__ = ["coatnet_0", "coatnet_1", "coatnet_2", "coatnet_3", "coatnet_4"]
def conv_3x3_bn(in_c, out_c, image_size, downsample=False):
stride = 2 if downsample else 1
layer = nn.Sequential(
nn.Conv2d(in_c, out_c, 3, stride, 1, bias=False),
nn.BatchNorm2d(out_c),
nn.GELU()
)
return layer
class SE(nn.Module):
def __init__(self, in_c, out_c, expansion=0.25):
super(SE, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.fc = nn.Sequential(
nn.Linear(out_c, int(in_c * expansion), bias=False),
nn.GELU(),
nn.Linear(int(in_c * expansion), out_c, bias=False),
nn.Sigmoid()
)
def forward(self, x):
b, c, _, _ = x.size()
y = self.avg_pool(x).view(b, c)
y = self.fc(y).view(b, c, 1, 1)
return x * y
class MBConv(nn.Module):
def __init__(self,
in_c,
out_c,
image_size,
downsample=False,
expansion=4):
super(MBConv, self).__init__()
self.downsample = downsample
stride = 2 if downsample else 1
hidden_dim = int(in_c * expansion)
if self.downsample:
# 只有第一层的时候,进行下采样
# self.pool = nn.MaxPool2d(kernel_size=2,stride=2)
self.pool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
self.proj = nn.Conv2d(in_c, out_c, 1, 1, 0, bias=False)
layers = OrderedDict()
# expand
expand_conv = nn.Sequential(
nn.Conv2d(in_c, hidden_dim, 1, stride, 0, bias=False),
nn.BatchNorm2d(hidden_dim),
nn.GELU(),
)
layers.update({"expand_conv": expand_conv})
# Depwise Conv
dw_conv = nn.Sequential(
nn.Conv2d(hidden_dim, hidden_dim, 3, 1, 1, groups=hidden_dim, bias=False),
nn.BatchNorm2d(hidden_dim),
nn.GELU(),
)
layers.update({"dw_conv": dw_conv})
# se
layers.update({"se": SE(in_c, hidden_dim)})
# project
pro_conv = nn.Sequential(
nn.Conv2d(hidden_dim, out_c, 1, 1, 0, bias=False),
nn.BatchNorm2d(out_c)
)
layers.update({"pro_conv": pro_conv})
self.block = nn.Sequential(layers)
def forward(self, x):
if self.downsample:
return self.proj(self.pool(x)) + self.block(x)
else:
return x + self.block(x)
class Attention(nn.Module):
def __init__(self,
in_c,
out_c,
image_size,
heads=8,
dim_head=32,
dropout=0.):
super(Attention, self).__init__()
inner_dim = dim_head * heads
project_out = not (heads == 1 and dim_head == in_c)
self.ih, self.iw = image_size if len(image_size) == 2 else (image_size, image_size)
self.heads = heads
self.scale = dim_head ** -0.5
# parameter table of relative position bias
self.relative_bias_table = nn.Parameter(
torch.zeros((2 * self.ih - 1) * (2 * self.iw - 1), heads)
)
coords = torch.meshgrid((torch.arange(self.ih), torch.arange(self.iw)))
coords = torch.flatten(torch.stack(coords), 1)
relative_coords = coords[:, :, None] - coords[:, None, :]
relative_coords[0] += self.ih - 1
relative_coords[1] += self.iw - 1
relative_coords[0] *= 2 * self.iw - 1
relative_coords = rearrange(relative_coords, 'c h w -> h w c')
relative_index = relative_coords.sum(-1).flatten().unsqueeze(1)
"""
PyTorch中定义模型时,self.register_buffer('name', Tensor),
该方法的作用是定义一组参数,该组参数的特别之处在于:
模型训练时不会更新(即调用 optimizer.step() 后该组参数不会变化,只可人为地改变它们的值),
但是保存模型时,该组参数又作为模型参数不可或缺的一部分被保存。
"""
self.register_buffer("relative_index", relative_index)
self.attend = nn.Softmax(dim=-1)
self.qkv = nn.Linear(in_c, inner_dim * 3, bias=False)
self.proj = nn.Sequential(
nn.Linear(inner_dim, out_c),
nn.Dropout(dropout)
) if project_out else nn.Identity()
def forward(self, x):
# [q,k,v]
qkv = self.qkv(x).chunk(3, dim=-1)
# q,k,v:[batch_size, num_heads, num_patches, head_dim]
q, k, v = map(lambda t: rearrange(
t, 'b n (h d) -> b h n d', h=self.heads), qkv)
# [batch_size, num_heads, ih*iw, ih*iw]
# 时间复杂度:O(图片边长的平方)
dots = torch.matmul(q, k.transpose(-1, -2)) * self.scale
# Use "gather" for more efficiency on GPUs
relative_bias = self.relative_bias_table.gather(
0, self.relative_index.repeat(1, self.heads)
)
relative_bias = rearrange(
relative_bias, '(h w) c -> 1 c h w', h=self.ih * self.iw, w=self.ih * self.iw
)
dots = dots + relative_bias
attn = self.attend(dots)
out = torch.matmul(attn, v)
out = rearrange(out, 'b h n d -> b n (h d)')
out = self.proj(out)
return out
class FFN(nn.Module):
def __init__(self, dim, hidden_dim, dropout=0.):
super(FFN, self).__init__()
self.ffn = nn.Sequential(
nn.Linear(dim, hidden_dim),
nn.GELU(),
nn.Dropout(dropout),
nn.Linear(hidden_dim, dim),
nn.Dropout(dropout)
)
def forward(self, x):
return self.ffn(x)
class Transformer(nn.Module):
def __init__(self,
in_c,
out_c,
image_size,
heads=8,
dim_head=32,
downsample=False,
dropout=0.,
expansion=4,
norm_layer=nn.LayerNorm):
super(Transformer, self).__init__()
self.downsample = downsample
hidden_dim = int(in_c * expansion)
self.ih, self.iw = image_size
if self.downsample:
# 第一层进行下采样
self.pool1 = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
self.pool2 = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
self.proj = nn.Conv2d(in_c, out_c, 1, 1, 0, bias=False)
self.attn = Attention(in_c, out_c, image_size, heads, dim_head, dropout)
self.ffn = FFN(out_c, hidden_dim)
self.norm1 = norm_layer(in_c)
self.norm2 = norm_layer(out_c)
def forward(self, x):
x1 = self.pool1(x) if self.downsample else x
x1 = rearrange(x1, 'b c h w -> b (h w) c')
x1 = self.attn(self.norm1(x1))
x1 = rearrange(x1, 'b (h w) c -> b c h w', h=self.ih, w=self.iw)
x2 = self.proj((self.pool2(x))) if self.downsample else x
x3 = x1 + x2
x4 = rearrange(x3, 'b c h w -> b (h w) c')
x4 = self.ffn(self.norm2(x4))
x4 = rearrange(x4, 'b (h w) c -> b c h w', h=self.ih, w=self.iw)
out = x3 + x4
return out
class CoAtNet(nn.Module):
def __init__(self,
image_size=(224, 224),
in_channels: int = 3,
num_blocks: list = [2, 2, 3, 5, 2], # L
channels: list = [64, 96, 192, 384, 768], # D
num_classes: int = 1000,
block_types=['C', 'C', 'T', 'T']):
super(CoAtNet, self).__init__()
assert len(image_size) == 2, "image size must be: {H,W}"
assert len(channels) == 5
assert len(block_types) == 4
ih, iw = image_size
block = {'C': MBConv, 'T': Transformer}
self.s0 = self._make_layer(
conv_3x3_bn, in_channels, channels[0], num_blocks[0], (ih // 2, iw // 2)
)
self.s1 = self._make_layer(
block[block_types[0]], channels[0], channels[1], num_blocks[1], (ih // 4, iw // 4)
)
self.s2 = self._make_layer(
block[block_types[1]], channels[1], channels[2], num_blocks[2], (ih // 8, iw // 8)
)
self.s3 = self._make_layer(
block[block_types[2]], channels[2], channels[3], num_blocks[3], (ih // 16, iw // 16)
)
self.s4 = self._make_layer(
block[block_types[3]], channels[3], channels[4], num_blocks[4], (ih // 32, iw // 32)
)
# 总共下采样32倍 2^5=32
self.pool = nn.AvgPool2d(ih // 32, 1)
self.fc = nn.Linear(channels[-1], num_classes, bias=False)
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
elif isinstance(m, (nn.BatchNorm2d, nn.GroupNorm, nn.LayerNorm)):
nn.init.constant_(m.weight, 1)
nn.init.constant_(m.bias, 0)
def forward(self, x):
x = self.s0(x)
x = self.s1(x)
x = self.s2(x)
x = self.s3(x)
x = self.s4(x)
x = self.pool(x)
x = torch.flatten(x, 1)
x = self.fc(x)
return x
def _make_layer(self, block, in_c, out_c, depth, image_size):
layers = nn.ModuleList([])
for i in range(depth):
if i == 0:
layers.append(block(in_c, out_c, image_size, downsample=True))
else:
layers.append(block(out_c, out_c, image_size, downsample=False))
return nn.Sequential(*layers)
def coatnet_0(num_classes=1000):
num_blocks = [2, 2, 3, 5, 2] # L
channels = [64, 96, 192, 384, 768] # D
return CoAtNet((224, 224), 3, num_blocks, channels, num_classes=num_classes)
def coatnet_1(num_classes=1000):
num_blocks = [2, 2, 6, 14, 2] # L
channels = [64, 96, 192, 384, 768] # D
return CoAtNet((224, 224), 3, num_blocks, channels, num_classes=num_classes)
def coatnet_2(num_classes=1000):
num_blocks = [2, 2, 6, 14, 2] # L
channels = [128, 128, 256, 512, 1026] # D
return CoAtNet((224, 224), 3, num_blocks, channels, num_classes=num_classes)
def coatnet_3(num_classes=1000):
num_blocks = [2, 2, 6, 14, 2] # L
channels = [192, 192, 384, 768, 1536] # D
return CoAtNet((224, 224), 3, num_blocks, channels, num_classes=num_classes)
def coatnet_4(num_classes=1000):
num_blocks = [2, 2, 12, 28, 2] # L
channels = [192, 192, 384, 768, 1536] # D
return CoAtNet((224, 224), 3, num_blocks, channels, num_classes=num_classes)
def count_parameters(model):
return sum(p.numel() for p in model.parameters() if p.requires_grad)
if __name__ == '__main__':
from torchsummary import summary
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
img = torch.randn(1, 3, 224, 224).to(device)
model = coatnet_0().to(device)
out = model(img)
summary(model, input_size=(3, 224, 224))
print(out.shape, count_parameters(model))
# net = coatnet_1()
# out = net(img)
# print(out.shape, count_parameters(net))
#
# net = coatnet_2()
# out = net(img)
# print(out.shape, count_parameters(net))
#
# net = coatnet_3()
# out = net(img)
# print(out.shape, count_parameters(net))
#
# net = coatnet_4()
# out = net(img)
# print(out.shape, count_parameters(net))
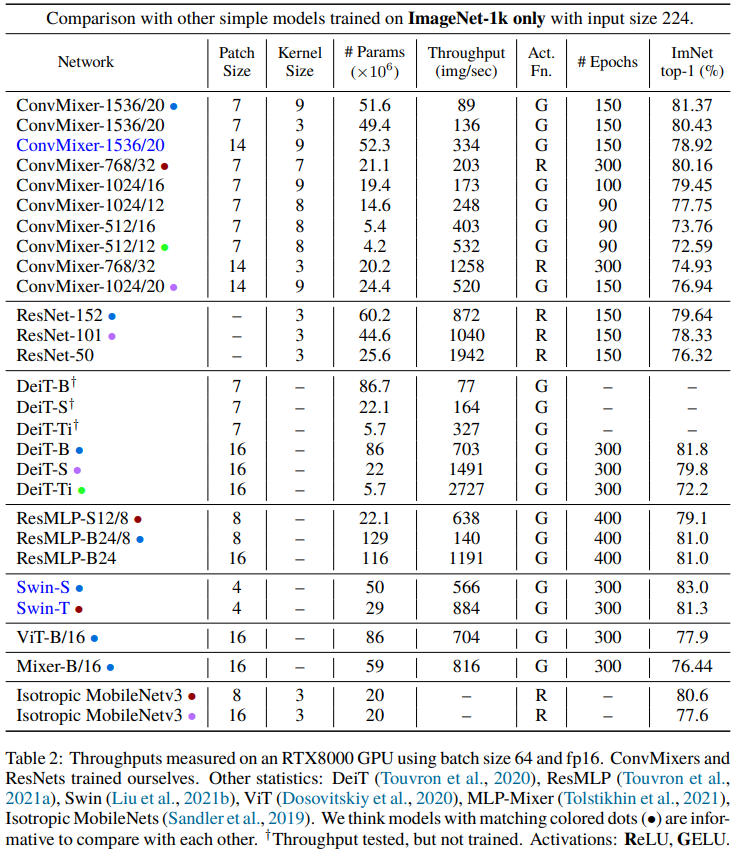
实验



Patches Are All You Need? ICLR 2022
论文:https://arxiv.org/abs/2201.09792
代码:https://github.com/locuslab/convmixer
解读:【图像分类】2022-ConvMixer ICLR_說詤榢的博客-CSDN博客
Patches are all you need? - 知乎 (zhihu.com)
简介
ViT和MLP-Mixer都表现出强大的性能,它们的一个共同点就是都将图像划分为Patches输入。论文提出一个问题: 模型的性能是否与使用补丁作为输入表示有关
本文提出ConvMixer,一个极其简单的模型,类似于ViT和更基本的MLP-Mixer,它直接操作补丁作为输入,分离空间和通道维度的混合,并在整个网络中保持相同的大小和分辨率。ConvMixer只使用标准的卷积来实现混合步骤。ConvMixer在类似的参数计数和数据集大小方面优于ViT、MLP-Mixer和它们的一些变体,此外还优于ResNet等经典视觉模型。

ConvMixer方法
ConvMixer 由一个 patch 嵌入层和一个简单的全卷积块的重复应用组成。

ConvMixer包括一个patch embedding层,然后重复应用一个简单的卷积块。
![]()
ConvMixer 采用深度可分离卷积的思想,主要由depthwise convolution和pointwise convolution组成,此外也使用了Batch Normalization和 Residual connection等技术,激活函数采用GELU,其中最值得注意的是 ConvMixer采用7×7或9×9 等比较大的卷积核。

代码表示

参数设计
ConvMixer的实例化依赖于四个参数:
- Patch Embedding的通道维度h hh
- ConvMixer层的重复次数d dd
- 控制模型中特征分辨率的patch大小p pp
- depthwise卷积的卷积核大小k。

关键代码
import torch.nn as nn
class Residual(nn.Module):
def __init__(self, fn):
super().__init__()
self.fn = fn
def forward(self, x):
return self.fn(x) + x
def ConvMixer(dim, depth, kernel_size=9, patch_size=7, n_classes=1000):
return nn.Sequential(
nn.Conv2d(3, dim, kernel_size=patch_size, stride=patch_size),
nn.GELU(),
nn.BatchNorm2d(dim),
*[nn.Sequential(
Residual(nn.Sequential(
nn.Conv2d(dim, dim, kernel_size, groups=dim, padding="same"),
nn.GELU(),
nn.BatchNorm2d(dim)
)),
nn.Conv2d(dim, dim, kernel_size=1),
nn.GELU(),
nn.BatchNorm2d(dim)
) for i in range(depth)],
nn.AdaptiveAvgPool2d((1,1)),
nn.Flatten(),
nn.Linear(dim, n_classes)
)
def ConvMixer(h,d,k,p,n):
S,C,A=Sequential,Conv2d,lambda x:S(x,GELU(),BatchNorm2d(h))
R=type('',(S,),{'forward':lambda s,x:s[0](x)+x})
return S(A(C(3,h,p,p)),*[S(R(A(C(h,h,k,groups=h,padding=k//2))),A(C(h,h,1))) for i
in range(d)],AdaptiveAvgPool2d(1),Flatten(),Linear(h,n))
实验