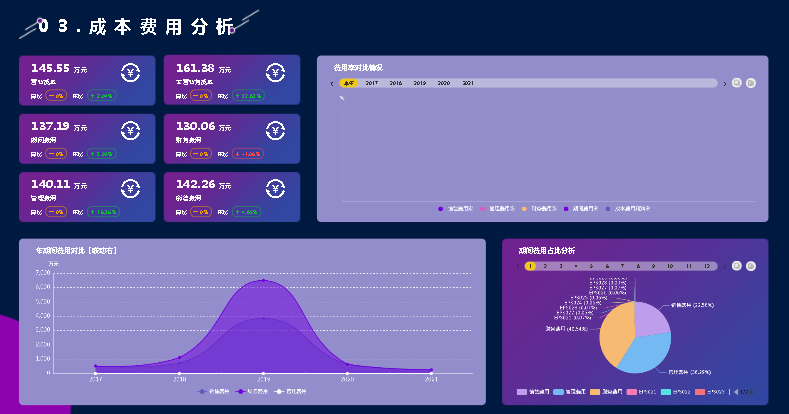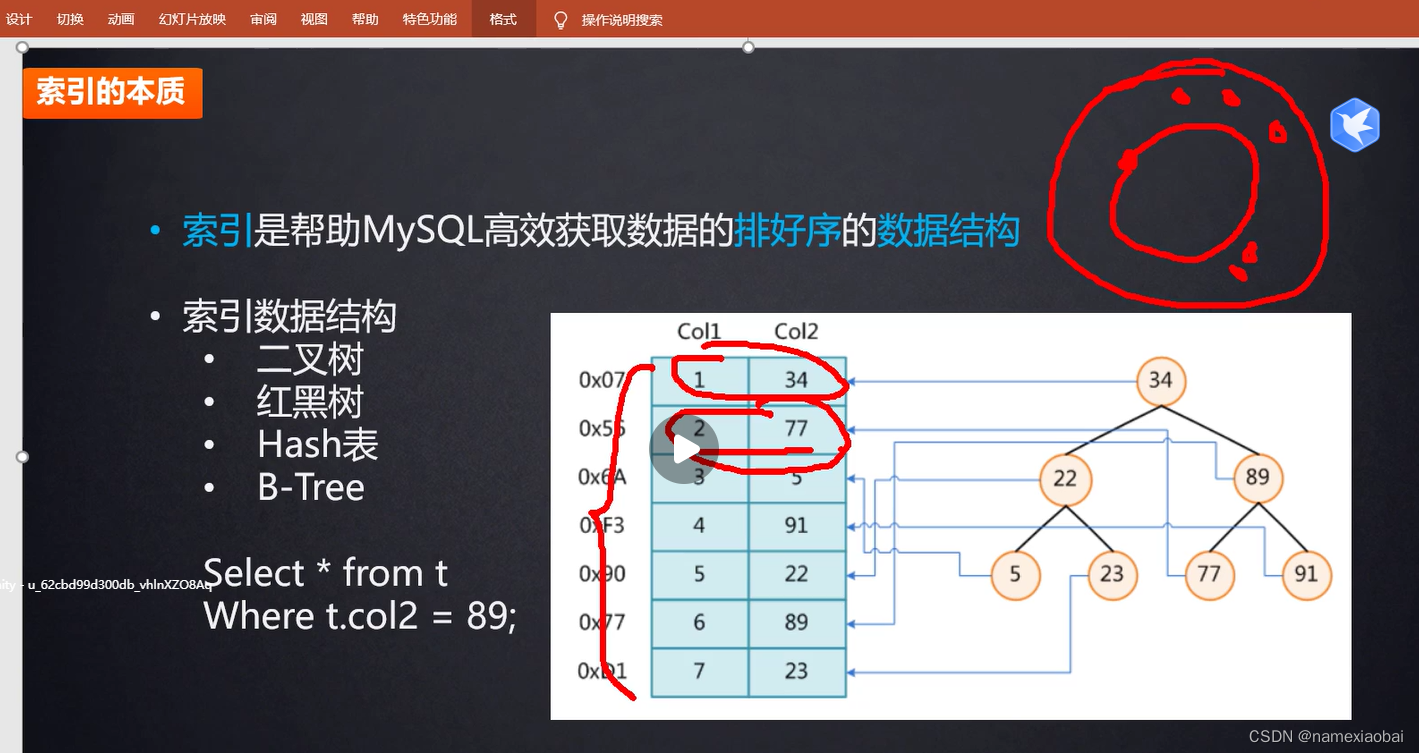
1.表中数据看似挨在一起,本质写在磁盘里,随着时间和其他程序占用可能分散分布
k为值 v为磁盘空间地址
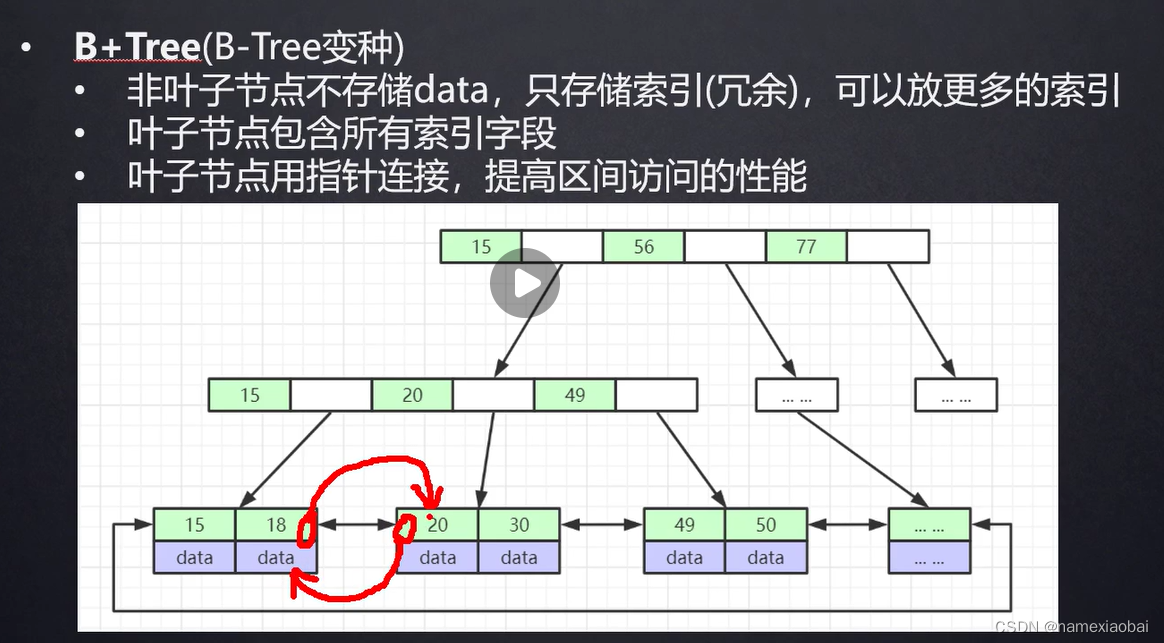

2.为什么mysql选择B+树
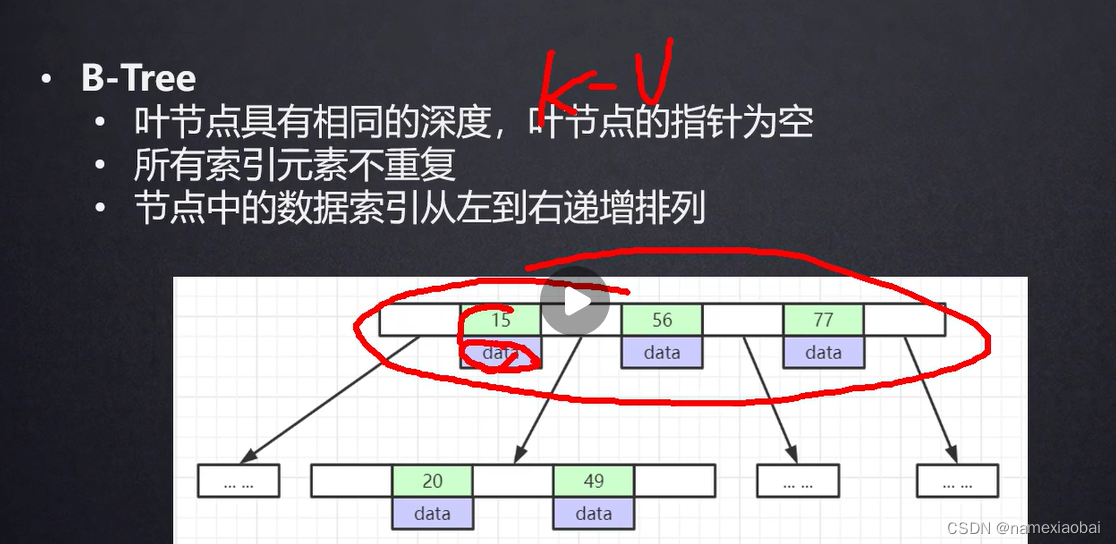
假如b树存放2k万数据 一个节点16KB,里面带有data的话存的太少,导致树的高度过高,所以让他放在叶子节点上去。
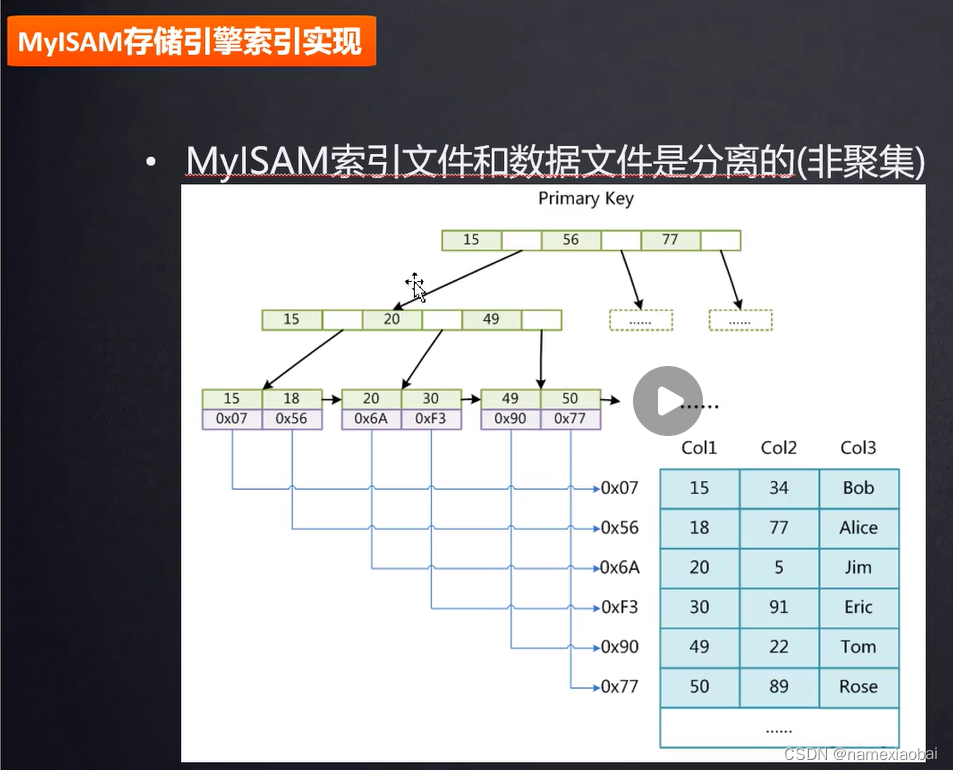
3.存储引擎对表生效,每个表可以使用不同存储引擎
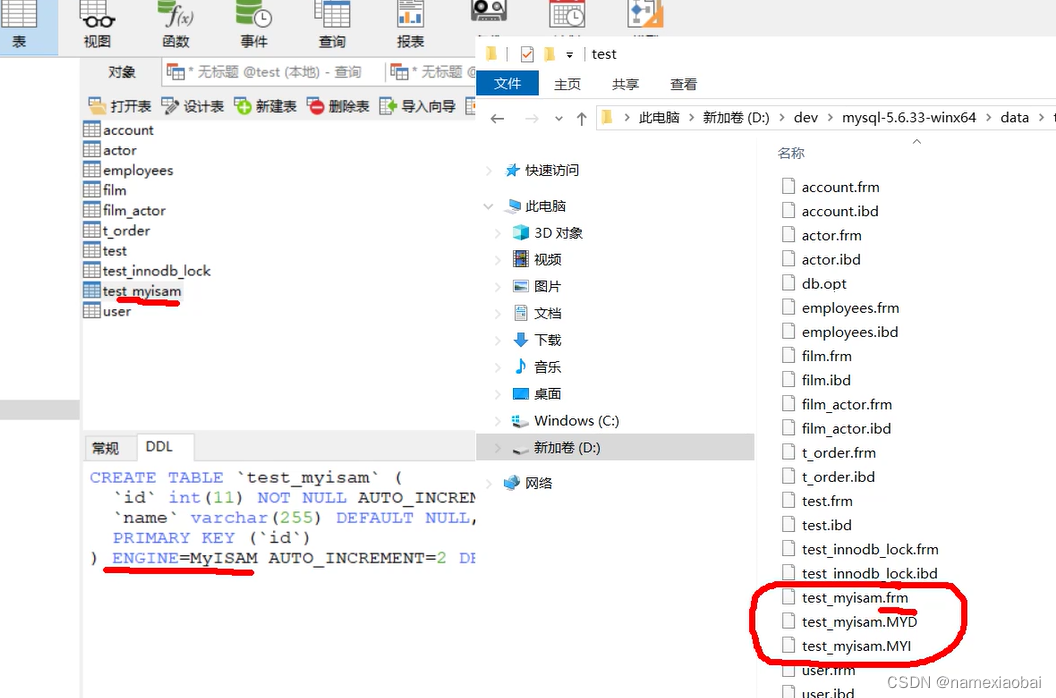
frm frame 数据表结构信息
myd MyISAM data
myi MyISAM index
4.对于myisam存储引擎建的表,查找办法通过索引地址myi文件 到 数据myd文件找数据
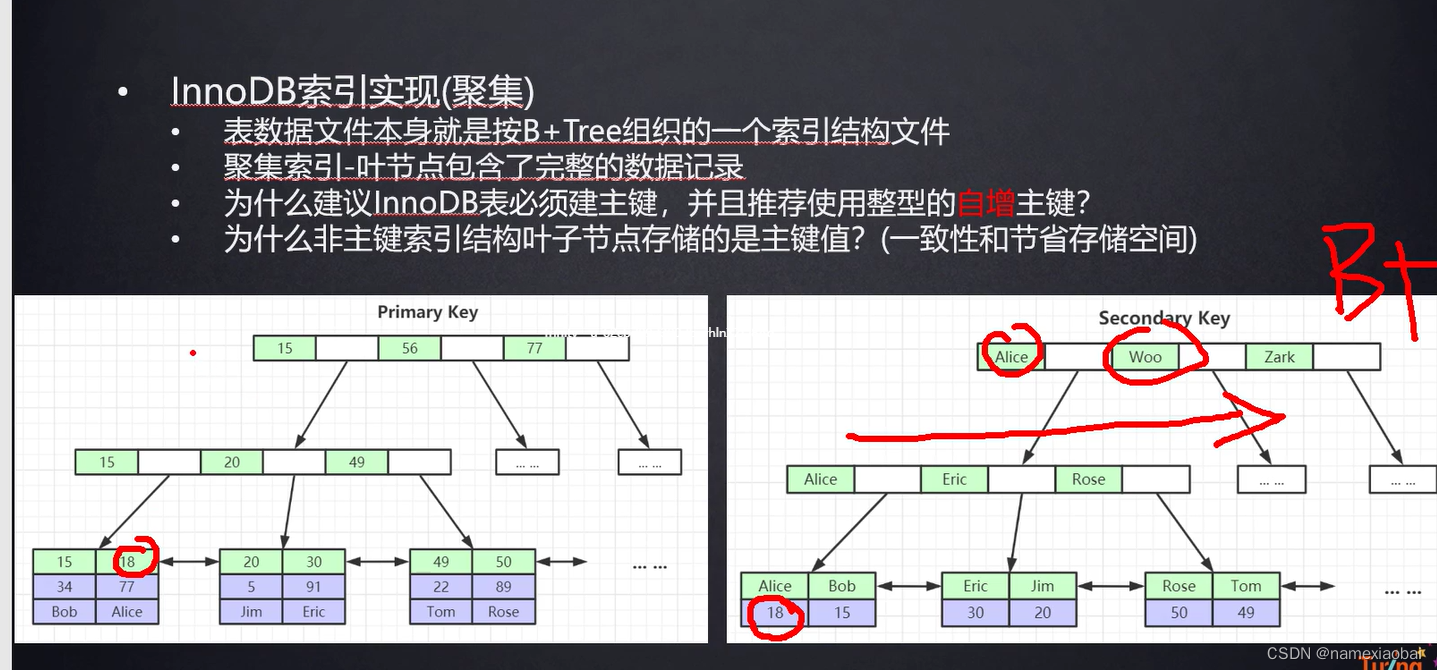
两个面试题
为什么建议InnoDB表必须建主键,并且推荐使用整型的自增主键?
如果不建主键mysql会选择一列作为隐藏列作为主键,为了不麻烦mysql还是自己建表时就指定好主键,自增主键在后面插入效率高,如果非自增导致前面还要平衡效率低下
uuid既不是整型还是自增,主要方便排序且减小空间
聚集索引高于非聚集索引,因为非聚集索引查找数据要跨文件,聚集索引数据直接就可以返回。
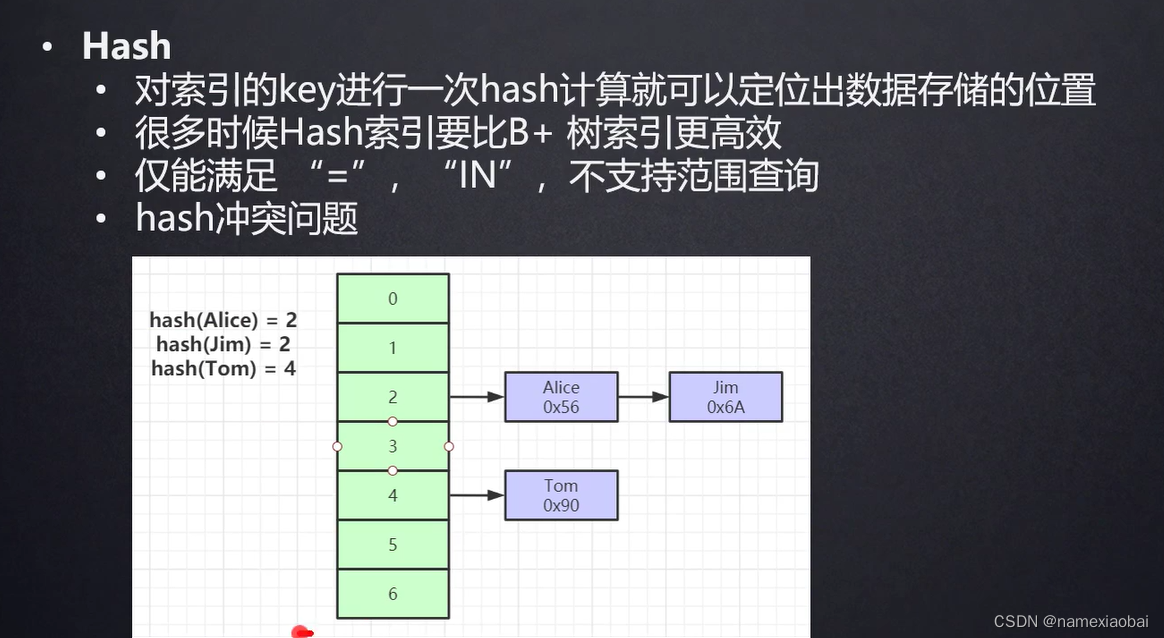
为什么大多情况下选择B+树不选择哈希,因为hash对等值查找高,但是范围查找效率低
B树和B+树最大区别,叶子节点相连,非叶子节点不存储数据,对范围查找支持较好和一个页存储的数据多
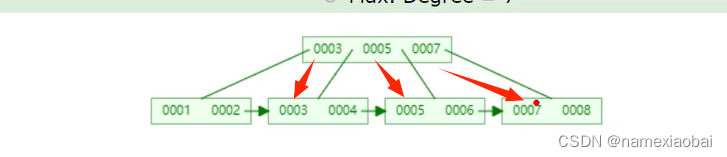
联合索引数据结构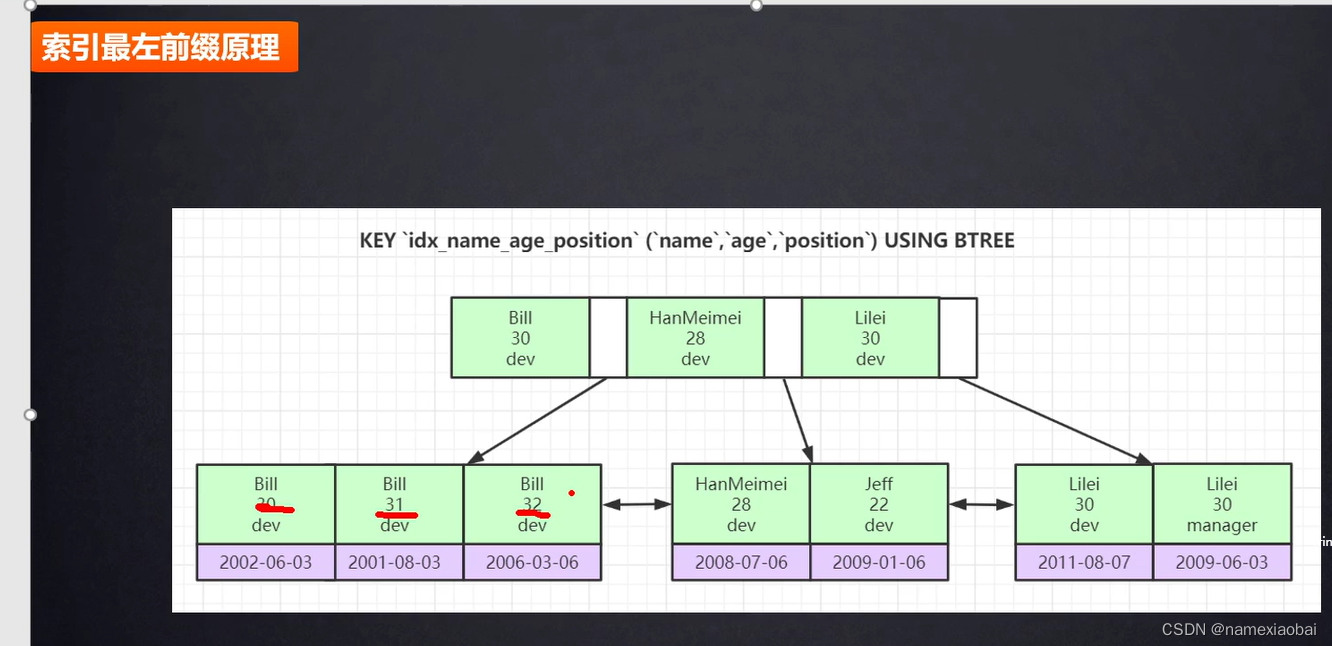
先排第一个 第一个如果能排序排第一个如果不能再排序第二个

第一个sql语句会使用索引,第二三个sql语句不会使用索引