文章作者邮箱:yugongshiye@sina.cn 地址:广东惠州
▲ 本章节目的
⚪ 掌握Kafka的架构;
⚪ 掌握Kafka的Topic与Partition;
一、Kafka核心概念及操作


1. producer生产者,可以是一个测试线程,也可以是某种技术框架(比如flume)。
2. producer向kafka生产数据,必须指定向哪个主题去生产数据。
3. 主题topic,主题是由用户(程序员)自己来创建的。
4. 创建主题的指令:
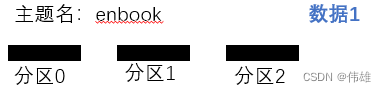
sh kafka-topics.sh --create ---zookeeper hadoop01:2181
--replication-factor 1 --partitions 1 --topic enbook
5. 查看kafka集群的所有主题:
sh kafka-topics.sh --list --zookeeper hadoop01:2181
6. 创建一个主题,需要指定:
①主题名
②主题的分区数量
③分区的副本数量
7. 主题的分区:本质上就是一个分区文件目录。
分区目录的命名规则:主题名 - 分区编号(分区编号从0开始)。
思考:kafka主题引入分区机制的作用?
回答:可以分布式的对一个主题的数据进行存储和管理。
补充:主题的分区数量可以远大于kafka broker 服务器数量。kafka底层尽可能确保分区目录的负载均衡。比如:一个主题有10个分区,有3个broker服务器,则分区目录的数量分配:3-3-4。
8. 启动一个生产者线程。
sh kafka-console-producer.sh --broker-list
hadoop01:9092, hadoop02:9092, hadoop03:9092 --topic enbook
9. producer向kafka指定的主题生产数据,数据最终是存到了分区目录下的log文件中。此外kafka底层会确保每个分区目录的数据达到负载均衡的效果(轮询发送给每个分区目录)。
10. Kafka支持数据的容错机制,即分区数据丢失后,可以恢复。通过副本冗余机制来实现的。即我们在创建主题时,可以指定每个分区有多个副本。

补充:如果出现kafka创建主题分区异常。主要检查zookeeper状态。
sh /home/software/zookeeper-3.4.8/bin/zkServer.sh status
如果报错:Error Start,查看zookeeper.out文件。
11. 分区的副本机制,是为了数据容错。
sh kafka-topics.sh --create --zookeeper hadoop01:2181
--replication-factor 2 --partitions 1 --topic frbook
补充:
①分区副本的数量不能broker服务器数量。
②分区的副本数不宜过多。副本数量越多,集群磁盘的利用率越低。比如3副本,集群利用率就只有33%。
在实际生产环境下,一般3个副本足够了,2个副本也可以。如果是1个副本则没有容错机制,所有一般需要2个或3个副本即可。
综上,Kafka最基础和核心的概念就是topic主题。因为无论是向kafka生产数据,还是从kafka消费数据,都需要指定主题。
主题topic的属性:
①主题名 topic name
②分区数量 partition
③分区的副本数量 replication
12. 从kafka消费数据,消费者可以是一个测试线程,也可以是某种技术框架(Spark,Flink)。
sh kafka-console-consumer.sh --zookeeper hadoop01:2181
--topic enbook --from-beginning
13. kafka的特点:kafka的数据无论消费与否,会一直存在,不会删除。
14. 在调用kafka相关指令时,如果涉及到zookeeper的,写一台即可。如果涉及kafka的,有几个写几个。
二、Kafka主题分区的副本相关补充
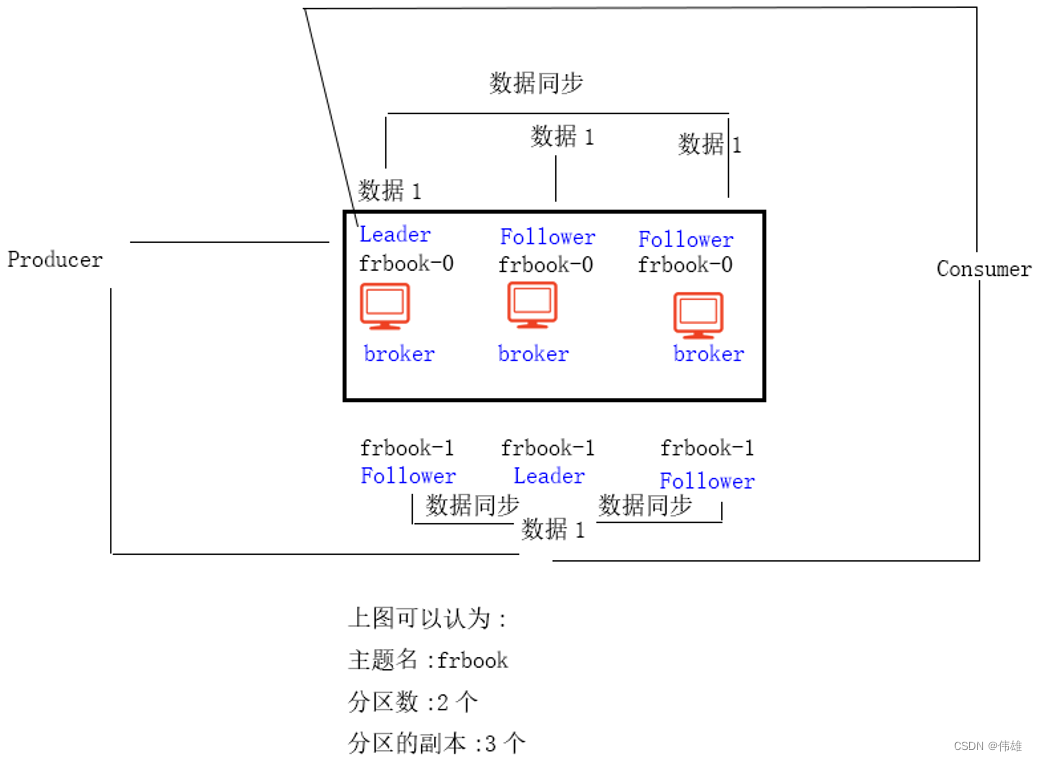
1. kafka是有Leader和Follower概念的,注意:是针对分区的副本而言的,不是针对broker来说的。kafka集群,broker没有主从之分。
2. 分区的副本Leader的作用:无论是生产数据还是消费数据,都是和分区副本的Leader交互的。
3. 如果分区副本的Leader挂掉了,Kafka会从剩余的Follower中选出新Leader。
三、Kafka架构
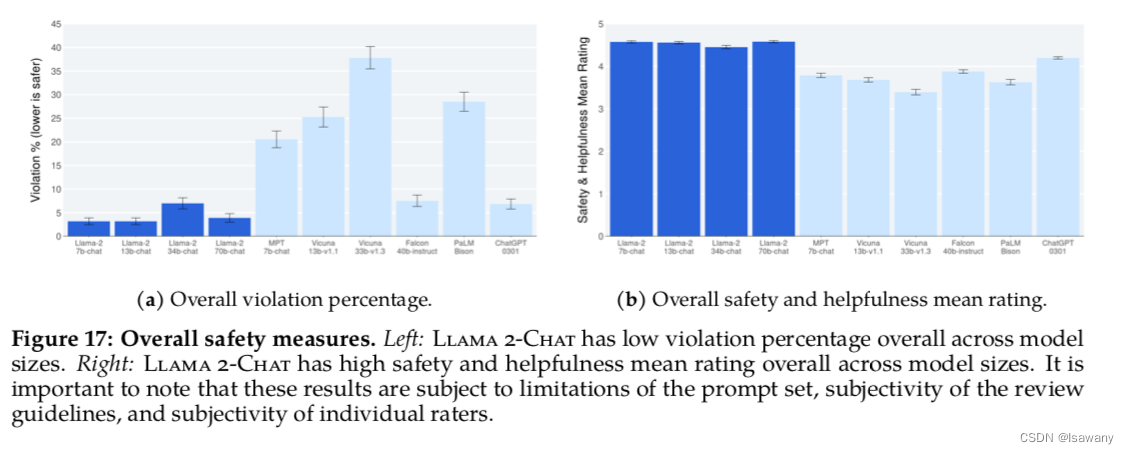
1. Kafka拓扑结构

1.producer:
消息生产者,发布消息到 kafka 集群的终端或服务。
2.broker:
kafka 集群中包含的服务器。broker (经纪人,消费转发服务)
3.topic:
每条发布到 kafka 集群的消息属于的类别,即 kafka 是面向 topic 的。
4.partition:
partition 是物理上的概念,每个 topic 包含一个或多个 partition。kafka 分配的单位是 partition。
5.consumer:
从 kafka 集群中消费消息的终端或服务。以一个测试线程也可以是某种技术框架(Spark和Flink)。
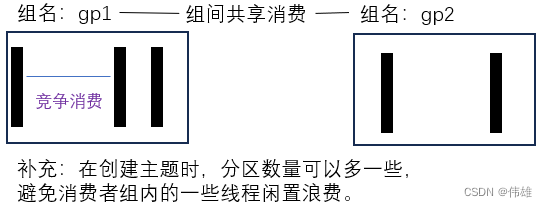
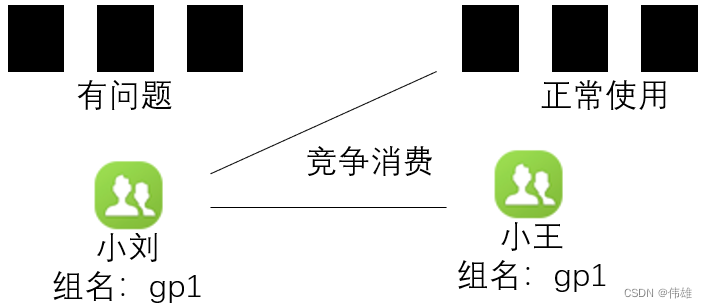
6.Consumer group:
high-level consumer API 中,每个 consumer 都属于一个 consumer group,每条消息只能被 consumer group 中的一个 Consumer 消费,但可以被多个 consumer group 消费。
即组间数据是共享的,组内数据是竞争的。
7.replica:
partition 的副本,保障 partition 的高可用。
副本数量不宜过多,因为降低进群磁盘的利用率。
比如3副本,磁盘利用率1/3.
8.leader:
replica 中的一个角色, producer 和 consumer 只跟 leader 交互。
9.follower:
replica 中的一个角色,从 leader 中复制数据。
10.controller:
kafka 集群中的其中一个服务器,用来进行 leader election 以及 各种 failover。
11.zookeeper:
kafka 通过 zookeeper 来存储集群的 meta 信息。负责管理和监控Kafka集群运行(临时节点+监听机制),包括存储一些元数据信息(比如主题名,主题的分区数,分区的副本数,副本Leader的位置信息,Controller位置等)。
2. 核心APIs
Producer API:也叫做生产者API,应用程序通过这些API可以发布记录的数据流到一个或多个topic上。
Consumer API:消费者API,应用程序可以通过消费者API订阅一个或多个topic上的记录,并对这些记录进行处理。
Streams API:通过调用Streams API,应用程序可以对一个或多个Topic上的记录进行转换处理,同时将处理后的记录发布到一个或多个Topic上。
Connector API:通过Connector API可以构建和运行可重用的生产者和消费者,能够把topic连接到现有的应用程序或数据库。比如,一个数据库连接器可以捕获每个表的变化。

kafka客户端与服务端的通信是基于一个简单的、高性能的、语言无关的TCP协议。这个协议是向下兼容的。我们提供了一个java语言的客户端,并且还有很多语言版本的客户端。
3. Kafka集群结构
分布式(distribution)
Partition分布在kafka集群的服务器上,每个分区配置一定数量的副本在集群服务器上提供容错能力,每个服务器会共享分区进行数据请求的处理。
每个分区都有一个对应的“leader”服务器,同时具有0个或多个“followers”服务器。leader服务器处理分区上的所有读写请求,follower服务器被动的复制leader服务器上的数据。如贵leader失败了,其中一个follower将自动变成leader。每个服务器都会从当分布在其上的分区的某些分区的领导则,而其他分区会在follower服务器上均匀分布。
生产者(producers)
生产者将数据发布到他选择的topic中,生产者负责指定将数据发送到topic中的那个partition上。可以通过简单的循环方式来实现负载均衡,也可以通过一些复杂的语义算法来实现(例如:根据记录中的一些Key)。
消费者(consumers)
每个消费者都隶属于某个消费群,每个发布到topic的记录都会被发送给一个订阅消费者组中的一个消费者实例上。消费则实例可以是一个单独的进程也可以是单独的一台机器。
如果所有的消费者实例都属于同一个消费者组,那么记录将被均匀的发送给消费者实例。
如果消费者实例在不同的消费群中,那么记录将被广播给所有的消费者进程。

如上图,两台服务器的kafka集群上分布四个partition(P0-P3),两个消费群,消费群A有两个消费者实例,消费群B有四个
四、Topic与Partition
1. 基础概念:

如上图所示,像一个主题生产数据。数据最终是存储到哥哥分区中。
分区从逻辑上来看,实际上是一个队列。
分区从物理上来看,实际上是一个分区目录。
向分区中存储数据,最终是存到的分区目录下的log文件中。

底层实际上是数据磁盘的顺序写操作(往文件末尾追加),所以Kafka的写入性能较高。
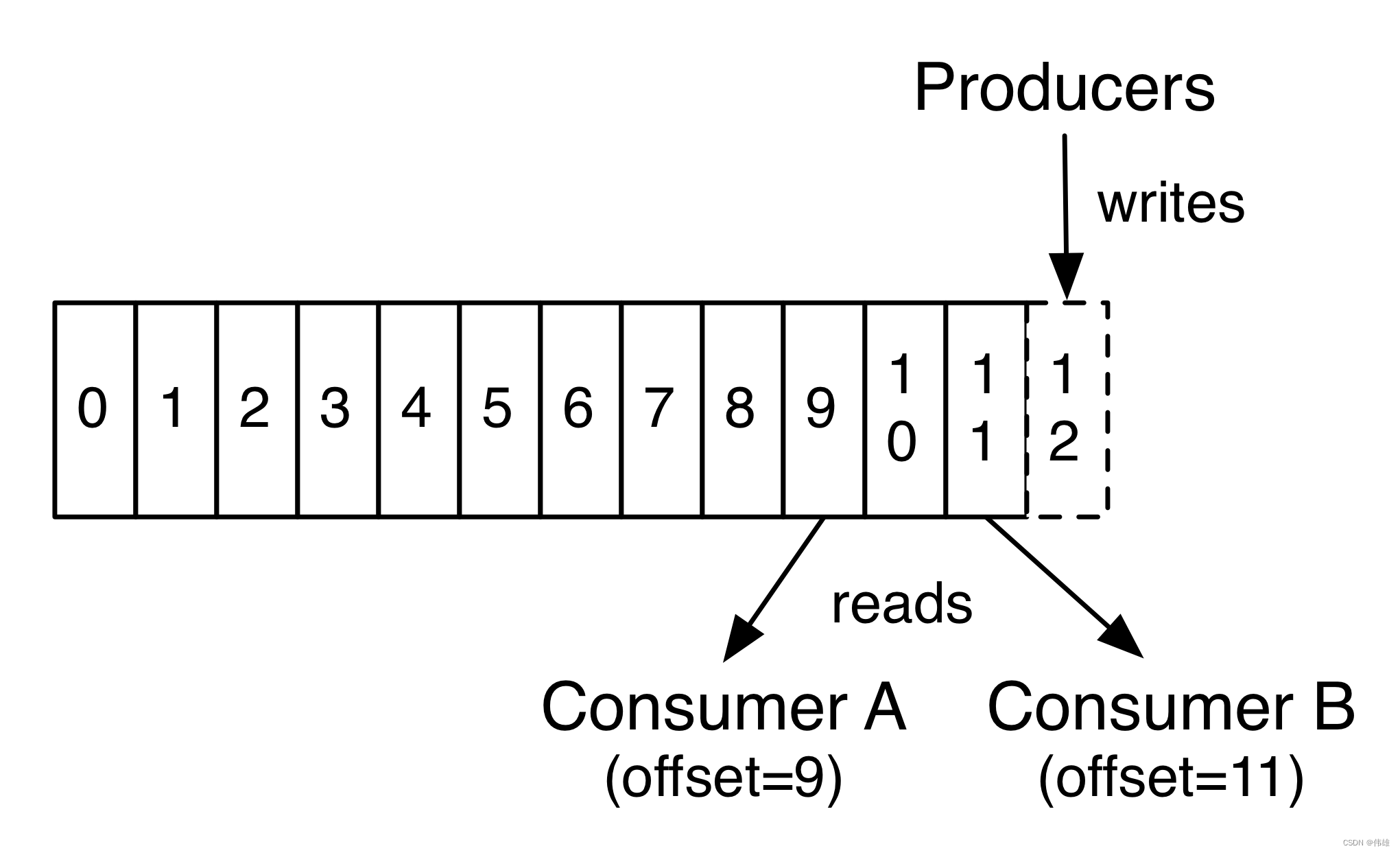
如上图所示,从分区中消费数据。Kafka底层有一个offset机制。
Kafka会记录消费者的offset(消费的位置偏移量),便于下一次从正确的位置进行消费。
Kafka记录offset分为两个版本:
旧版本:Kafka是将offset存到zookeeper上的。存在的问题是:会频繁的和zookeeper进行通信交互,即可能会为Zookeeper带来较高的访问负载。
新版本:Kafka自己来管理offset,以消费者组为单位进行管理。
2. 验证思路:
1. 启动一个消费者线程(需要带有消费者属性)
sh kafka-console-consumer.sh --bootstrap-server
hadoop01:9092,hadoop02:9092,hadoop03:9092 --topic enbook
--from-beginning --new-consumer
2. 会发现多出一些目录
__consumer_offsets-11
__consumer_offsets-14
__consumer_offsets-17
3. 即Kafka底层是通过一个主题来进行管理的。
主题名是__consumer_offsets,分区是50个。
__consumer_offsets-0
__consumer_offsets-49
4. 某个消费者组的offset就存在这个50个分区目录中的其中一个中。
存储位置规则:groupId.hashcode%50= 取余结果就是对应的分区目录。
sh kafka-consumer-groups.sh --bootstrap-server
hadoop01:9092,hadoop02:9092,hadoop03:9092 --list --new-consumer
3. Topic和Partition的关系
Topic
每条发布到Kafka集群的消息都有一个类别,这个类别被称为Topic(主题)。
Partition
Parition是物理上的概念,每个Topic包含一个或多个Partition.。
Topic在逻辑上可以被认为是一个queue,每条消息都必须指定它的Topic,可以简单理解为必须指明把这条消息放进哪个queue里。
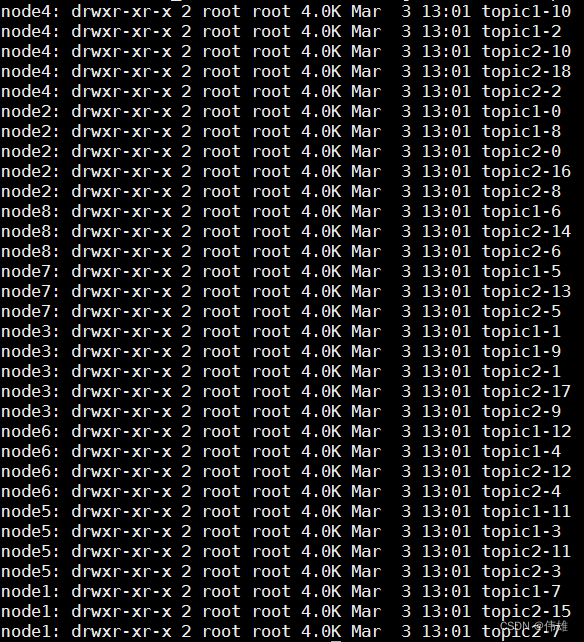
为了使得Kafka的吞吐率可以线性提高,物理上把Topic分成一个或多个Partition,每个Partition在物理上对应一个文件夹,该文件夹下存储这个Partition的所有消息和索引文件。若创建topic1和topic2两个topic,且分别有13个和19个分区,如下图所示。
因为每条消息都被append到该Partition中,属于顺序写磁盘,因此效率非常高(经验证,顺序写磁盘效率比随机写内存还要高,这是Kafka高吞吐率的一个很重要的保证)。