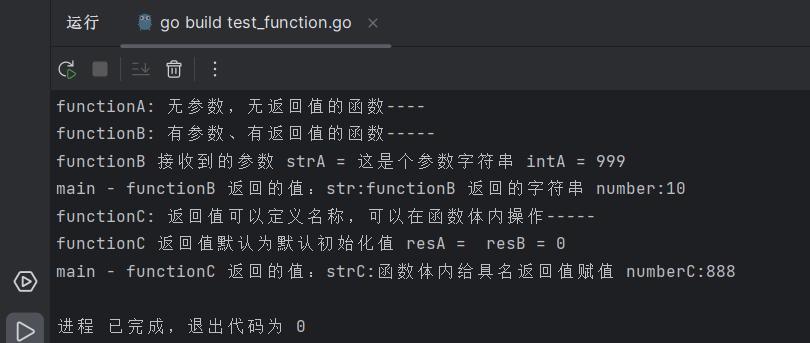
梭子蟹终于上市了,早早起来准备去买来尝鲜,出发之前想起大概 2016,2017 年左右温州老板推荐给我的一篇好论文:The Linux Scheduler: a Decade of Wasted Cores,但有点长,就读个梗概:a Decade of Wasted Cores。
大意是,现有的观测工具无法观测到 Linux 调度器在一定精度以下的细节行为,于是这帮人开发了一个精度更高的可观测工具,观测到了 Linux 调度器隐藏了非常久的一些不合理行为并进行了修正。
拥塞控制本质上也是一种资源调度行为,肯定同样存在粒度问题,问题是能识别的精度上限在哪。
RTT 测量不准和抖动是造成算法带宽分配不合理的首要因素,从而引发效率和公平性问题,高估会导致丢包重传,低估影响利用率和公平性,受 a Decade of Wasted Cores 启发,对 RTT 的测量可等同而视之。
看一组 RTT 采样:9,10,11,9,28,12,9,3,10,11,… 这组样本对目前TCP RTT 采集会有什么影响?
- 样本 28 会拉高 srtt,虽然移动指数平均会平滑些许,但还是会拉高。
- 样本 3 会被 minrtt 记录,造成类 BBR,Vegas 算法对带宽的高估。
肉眼看一眼就能排除 28 和 3,但在算法离散采样过程中如何识别?势必要进行更精细粒度的观测。
真实的排队是什么样?如果一个连接发送足够平滑,报文应该足够均匀分布在每一个 buffer,以 3 个报文为例,通过这 3 个报文采集的 RTT 应该均匀梯度:
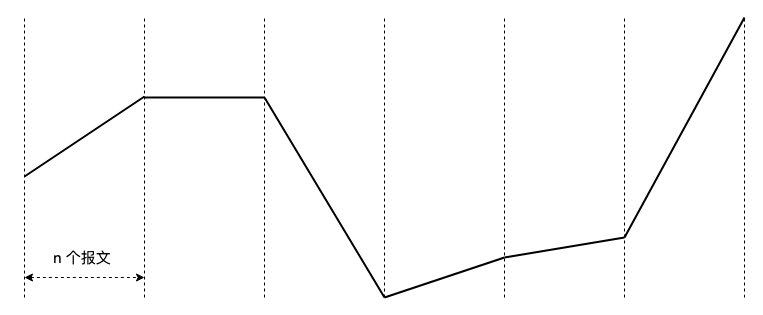
这样才是合理的采集 RTT 的方式,但凡在 n 以内的变化,均属于抖动,不予理睬。在这里,n 是一个参数,预估为一个连接在 buffer 里所能被容纳的报文数量,这是个前提,意味着通过 n 个连续报文采集的 RTT 波动是噪声,因为同时排在同一 buffer 里的报文应该具有相同排队时延。
n 个间隔为 1 个报文的轮次一起向前推,就能大致勾勒出 RTT 的变化,从而探测出精确的拥塞变化并排除任何潜在的噪声:
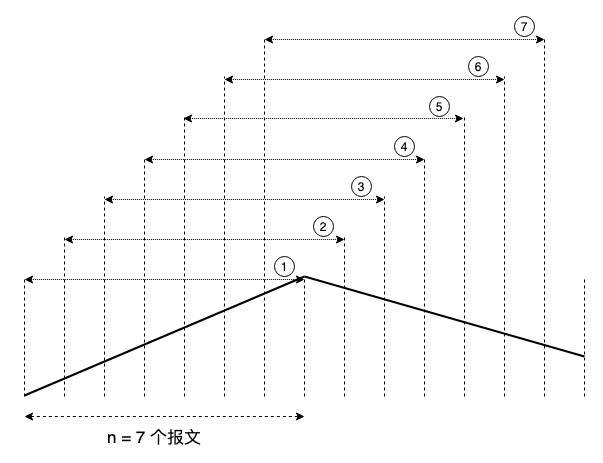
以 7 个报文为例,一共 7 个计算序列(小圆圈表示)作为一个周期,任何一个序列里的梯度波动被主动忽略,梯度变化可通过相邻序列校准,即差一个固定相位差。
如此,增加一个 buffer 容纳报文数量 n,细节便能被捕捉。
以一组 RTT 样本作为考察样本而不是一个,以另一种维度的组样本做校准。和试图用算法平滑掉噪声不同,恰恰需要放大噪声才能识别到它真的是噪声,不然就是掩耳盗铃。IBM Aspera 与此类似。
浙江温州皮鞋湿,下雨进水不会胖。