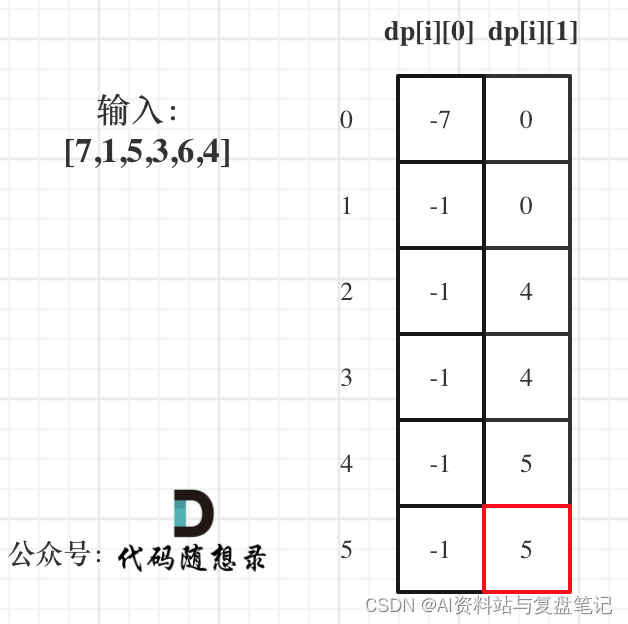
目录
前言
原始数据集
爬虫部分
爬取每个队员在buct做题数量
爬取每个队员codeforces的最高分,注册时间,解题数量
爬取每个队员有效做题时间
数据处理部分
模型部分
Linear Regression
XGBregression+gridsearchCV调参
Random Forset
前言
刚开课时
我:老师我们能不能写深度学习呀
某老师:当然可以呀
本来我们组都弄好了大作业给他写个CNN分类植物种类
数据都跑出来了
某老师给来一句:你这个分类花花草草阿太简单了,不符合大作业的代码量(火速入典)
当天晚上:诶你做我们ACM队员的获奖预测吧!
我:(......wsnd)
于是就有了接下来的故事
原始数据集
从某老师那里得到的学生,学号,班级(没啥用),codeforces的id,atcoder的id(很多没有)
我合并了一下大概500条数据左右
清洗了一波,把信息缺失太严重的删掉,去个重,剩400左右
后面各种删最后有效的只有不到400条
然后我拟了一些class
从某老师那得到的历届ACM获奖名单,填写下
具体是这样的
class1: 没得过奖+蓝桥杯省三+一些水奖
class2: 蓝桥省二+天梯国三
class3: icpc/ccpc铜奖+蓝桥国二/三/优+天梯国二
class4: icpc/ccpc银奖+蓝桥国一+天梯国一
class5: icpc/ccpc金奖
于是这个荒唐的项目就轰轰烈烈展开了
爬虫部分
爬取每个队员在buct做题数量
xpath+F12抓包,找标签
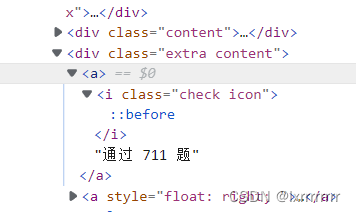
xpath解析拿到数据
代码如下 (cookie已打码,
这个真不能给别人)
#//div[@class="extra content"]
import lxml
import numpy as np
import requests
from lxml import etree
import pandas as pd
def create_request(name):
print(name)
url = 'https://buctcoder.com/userinfo.php?user='+str(name)
headers = {
'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.4951.64 Safari/537.36 Edg/101.0.1210.53',
'Cookie':'XSYWSND'
}
request = requests.get(url=url,headers=headers)
return request
def get_content_html(request):
request.encoding='utf-8'
content = request.text
content = etree.HTML(content)
return content
def get_solve_number(content):
solve_result = content.xpath('//div[@class="extra content"]/a/text()')
try:
solve_result = solve_result[0].split(" ")[1]
return solve_result
except:
return 0
if __name__ == '__main__':
df = pd.DataFrame(pd.read_csv('work.csv'))
totleset = df.values
id=[]
solve_set=[]
for node in totleset:
id.append(node[3])
schoolnumber=int(node[1])
request=create_request(schoolnumber)
content=get_content_html(request)
result=get_solve_number(content)
solve_set.append(result)
df = pd.DataFrame(pd.read_csv('oldwork.csv'))
totleset = df.values
for node in totleset:
id.append(node[3])
schoolnumber=int(node[2])
request = create_request(schoolnumber)
content = get_content_html(request)
result = get_solve_number(content)
solve_set.append(result)
result=[]
for i in range(0,len(id)):
tmp=[]
tmp.append(id[i])
tmp.append(solve_set[i])
result.append(tmp)
data = pd.DataFrame(result, columns=['name', 'buct_solve'])
data.to_csv('data_buct_solve.csv', index=False)
爬取每个队员codeforces的最高分,注册时间,解题数量
maxrating抓包

codeforces这个网站他很鸡贼
蓝名用户的class名字是user-blue
绿名用户class名字就变成user-green
所以写了个颜色列表依次遍历过去
解题数抓包

注册时间抓包

这个注册时间要根据单位换算成天,不然会混乱
代码如下
import lxml
import numpy as np
import requests
from lxml import etree
import pandas as pd
def create_request(name):
url = 'https://codeforces.com/profile/'+str(name)
headers = {
'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.4951.64 Safari/537.36 Edg/101.0.1210.53'
}
request = requests.get(url=url,headers=headers)
return request
def get_content_html(request):
request.encoding='utf-8'
content = request.text
content = etree.HTML(content)
return content
def get_max_score(content):
color_set = ['gray', 'green', 'cyan', 'blue', 'violet', 'orange', 'red', 'legendary']
for color in color_set[::-1]:
targetstr = "//span[@class=\"user-" + str(color) + "\"]/text()"
maxscore_result = content.xpath(targetstr)
if len(maxscore_result) == 4:
maxscore_result = maxscore_result[3]
return int(maxscore_result)
elif len(maxscore_result) == 2:
maxscore_result = maxscore_result[1]
return int(maxscore_result)
return 0
def get_solve_problem(content):
solve_result = content.xpath('//div[@class="_UserActivityFrame_counterValue"]/text()')
solve_result = solve_result[0]
solve_result = solve_result.split(' ')[0]
return int(solve_result)
def get_age_time(content):
time_result = content.xpath('//span[@class="format-humantime"]/text()')
time_result = time_result[-1].split(' ')
if time_result[1] == 'months':
time_result = int(time_result[0]) * 4 * 7
elif time_result[1] == 'years':
time_result = int(time_result[0]) * 12 * 4 * 7
elif time_result[1] == 'week':
time_result = int(time_result[0]) * 7
else:
time_result = int(time_result[0])
return time_result
if __name__ == '__main__':
df = pd.DataFrame(pd.read_csv('work.csv'))
totleset = df.values
maxscore_set = []
solveproblem_set = []
time_age_set = []
id=[]
for node in totleset:
id.append(node[3])
codeforcesid_set=node[4:7]
maxscore=-1
timeage=0
solvepro=0
for name in codeforcesid_set:
if name is not np.nan:
print(name)
request = create_request(name)
content = get_content_html(request)
maxscore = max(maxscore,get_max_score(content))
solvepro=solvepro+get_solve_problem(content)
timeage=timeage+get_age_time(content)
maxscore_set.append(maxscore)
solveproblem_set.append(solvepro)
time_age_set.append(timeage)
df = pd.DataFrame(pd.read_csv('oldwork.csv'))
totleset = df.values
for node in totleset:
id.append(node[3])
name=node[6]
maxscore=0
timeage=0
solvepro=0
if name is not np.nan:
print(name)
request = create_request(name)
content = get_content_html(request)
maxscore = max(maxscore,get_max_score(content))
solvepro=solvepro+get_solve_problem(content)
timeage=timeage+get_age_time(content)
maxscore_set.append(maxscore)
solveproblem_set.append(solvepro)
time_age_set.append(timeage)
# print(id)
# print(maxscore_set)
# print(solveproblem_set)
# print(time_age_set)
result = []
for i in range(0,len(id)):
tmp=[]
tmp.append(id[i])
tmp.append(maxscore_set[i])
tmp.append(solveproblem_set[i])
tmp.append(time_age_set[i])
result.append(tmp)
data=pd.DataFrame(result,columns=['name','cf_max_rating','cf_solve','cf_time'])
data.to_csv('data.csv',index=False)
爬取每个队员有效做题时间
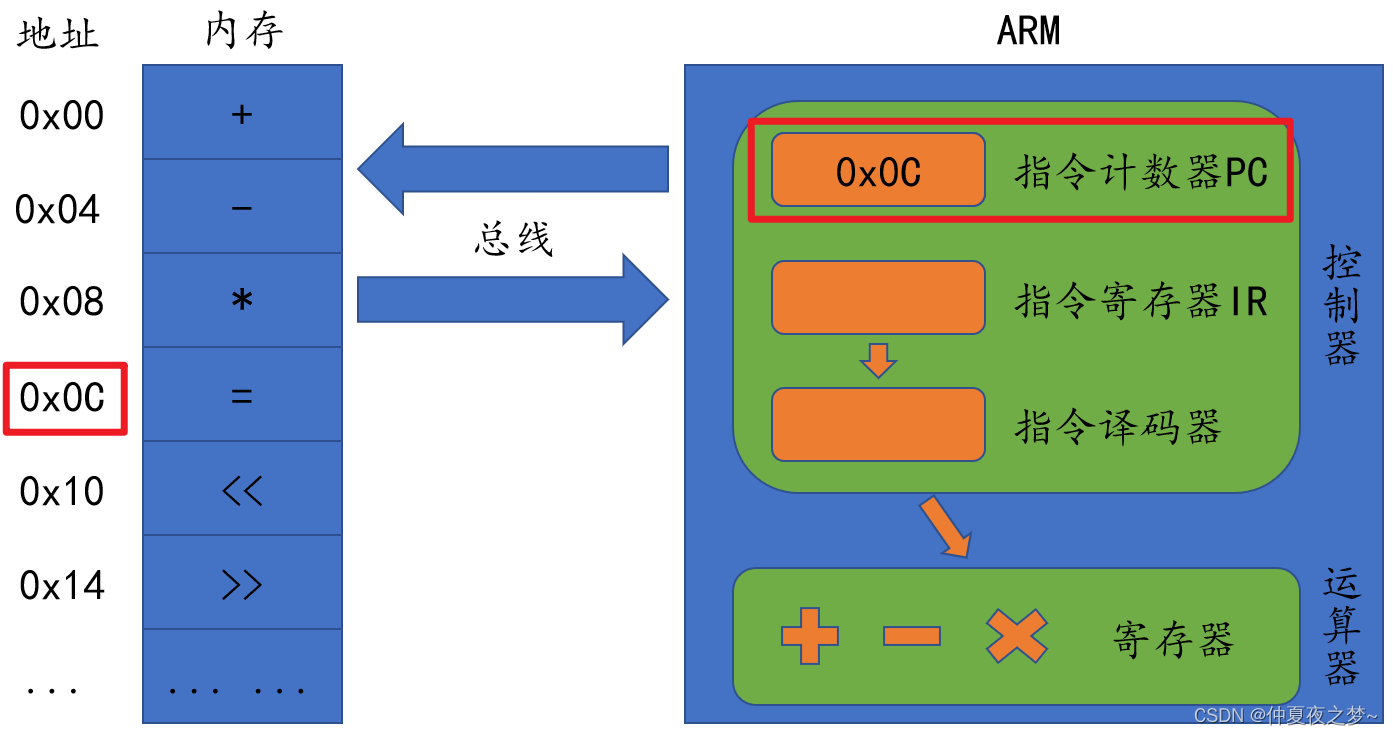
在https://codeforces.com/api/user.rating?handle=用户id'

这个地址里,有json格式的每个账号打比赛的所有记录
其中时间戳只差是以秒为单位的
也就是说,我们用用户打过的最后一场比赛和第一场比赛时间戳相减,在单位换算,就可以得到用户有效做题时间
代码如下:
import lxml
import numpy as np
import requests
from lxml import etree
import pandas as pd
import json
import jsonpath
import requests
from lxml import etree
def create_request(name):
url = 'https://codeforces.com/api/user.rating?handle='+str(name)
headers = {
'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.4951.64 Safari/537.36 Edg/101.0.1210.53'
}
request = requests.get(url=url,headers=headers)
return request
def get_content(request):
try:
request.encoding = 'utf-8'
content = request.text
content = json.loads(content)
return content
except:
return False
def get_time(content):
if(content==False):
return 0
contest_list = jsonpath.jsonpath(content, '$..result..ratingUpdateTimeSeconds')
if(not contest_list):
return 0
return (contest_list[-1]-contest_list[0])//3600//24
if __name__ == '__main__':
df = pd.DataFrame(pd.read_csv('work.csv'))
totleset=df.values
id=[]
time_set=[]
for node in totleset:
id.append(node[3])
codeforcesid_set = node[4:7]
time_tmp=0
for name in codeforcesid_set:
if name is not np.nan:
print(name)
request = create_request(name)
content = get_content(request)
time_tmp=max(time_tmp,get_time(content))
time_set.append(time_tmp)
df = pd.DataFrame(pd.read_csv('oldwork.csv'))
totleset = df.values
for node in totleset:
id.append(node[3])
name = node[6]
time_tmp=0
if name is not np.nan:
print(name)
request = create_request(name)
content = get_content(request)
time_tmp = max(time_tmp, get_time(content))
time_set.append(time_tmp)
print(id)
print(time_set)
result=[]
for i in range(0,len(id)):
tmp=[]
tmp.append(id[i])
tmp.append(time_set[i])
result.append(tmp)
data = pd.DataFrame(result, columns=['name', 'real_time'])
data.to_csv('data_time.csv', index=False)数据处理部分
得到爬取的数据后,我们得到了一张并不干净的数据
其中有因为网络问题爬出来挂0的,有一场比赛没打过的等等
这部分我们可以按自己的意愿酌情删除或修改数据
(tmd数据本来就少)
由于我们之后模型训练要用分类模型,所以对连续数据进行分箱使其离散化
依据事实我们选择等距分箱
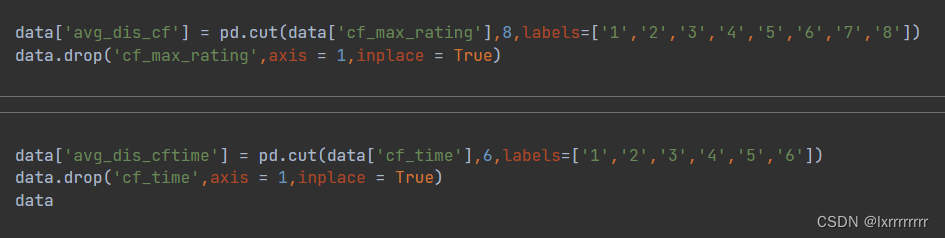

最终用于回归模型的data如下
用于分类模型的data如下
模型部分
回归模型,先归一化

得到如下数据

Linear Regression
来一发Linear Regression试试水
from sklearn.linear_model import LinearRegression
lin = LinearRegression()
lin.fit(x_train,y_train)
prediction = lin.predict(x_train)
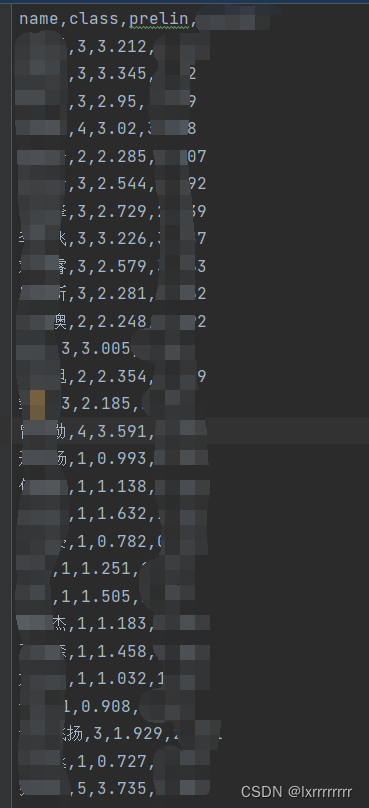
得分确实假了才60多好像
ZZX那么强才给铜牌水平是吧(模型背大锅)
XGBregression+gridsearchCV调参
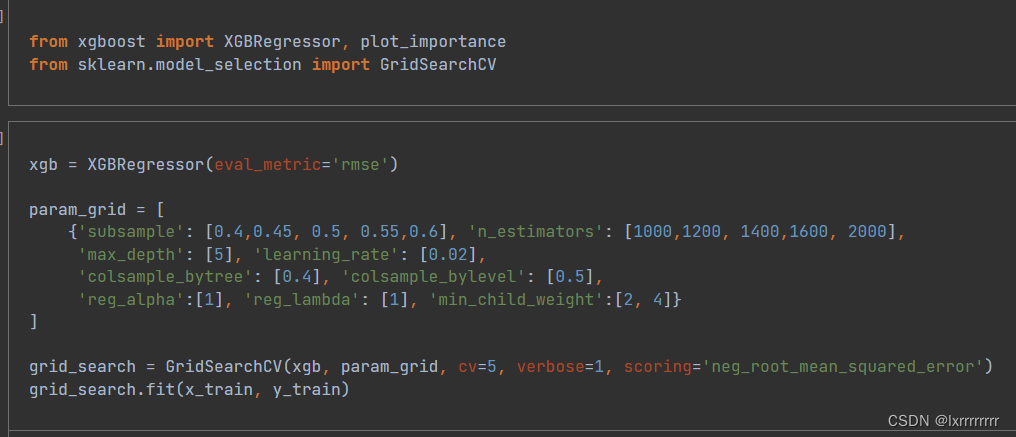
当时忘记看得分了,反正高了巨多
ZZX给了3.8,小低一点可以接受
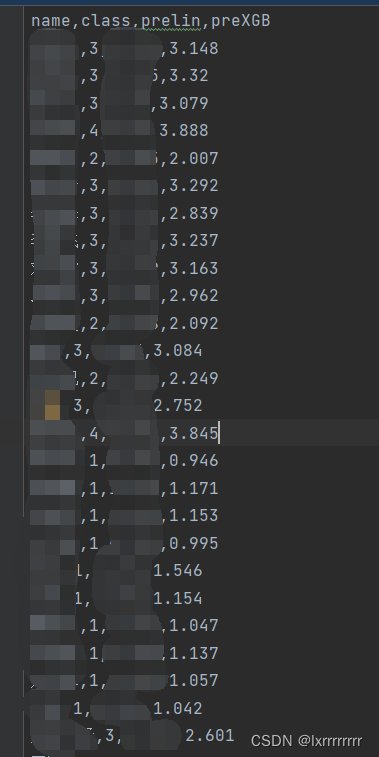
之后是分类模型
Random Forset
随机森林
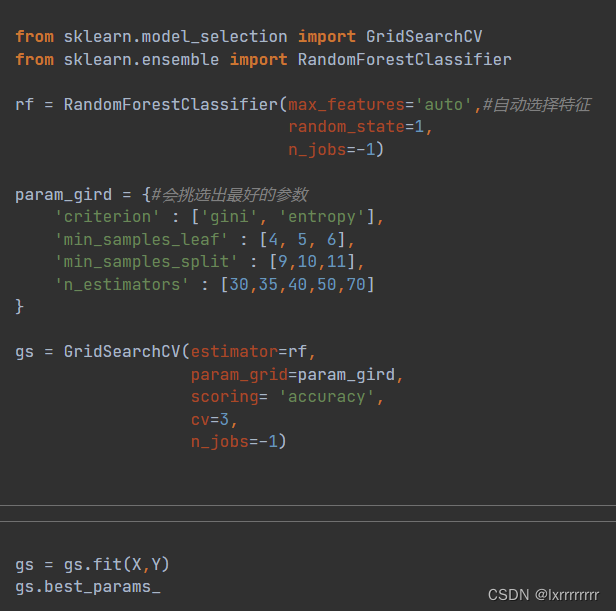
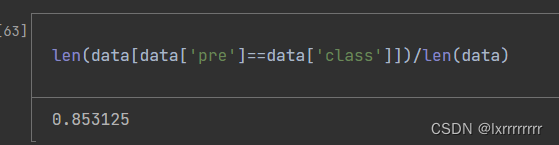
起码在训练集上有百分之85的准确率,也算挺好了
没有测试集给咱试呀
结语
没想到阴差阳错之后最后答辩的外教就是我三天之前机器学习课答辩时的外教(希望我的异乡人英语别给他留太深印象)
还好没有认出我,最后他还小夸了我们组一下,可能写的专业对他口了
老师给分别太离谱/doge