一、Map的遍历
- 创建Map集合
Map<String, Integer> map = new HashMap<>(); - 添加元素
map.put("java", 99);map.put("c", 88);map.put("c++", 93);map.put("python", 96);map.put("Go", 88);
- 遍历方法:
map.keySet();map.entrySet();
遍历方式1
//获取所有的key
Set<String> keys = map.keySet();
for (String key : keys){
//根据key获取对应的value
Integer value = map.get(key);
System.out.println(value);
}
遍历方式2
//获取所有的键值对
Set<Map.Entry<String, Integer>> entries = map.entrySet();
for (Map.Entry<String, Integer> entry : entries) {
String key = entry.getKey();
Integer value = entry.getValue();
}
二、实现类

1 HashMap实现类
特点:元素唯一(key唯一),无序,key和value都可以为null
底层结构:哈希表
效率:综合效率较高
添加元素时如果和原先的key值相等,会覆盖原有的value值。判断key值唯一的依据和hashSet一致,也是先比较hashCode, 然后再比较eqauls。
2 Hashtable实现类
Hashtable是线程安全的,相对来说,效率更低。key和value不能为null。HashMap是线程不安全的,效率相对较高,key和value可以为null。
3 LinkedHashMap实现类
特点:key唯一, 有序
底层结构:哈希表 + 链表(用于记录元素迭代顺序)
效率:略低于HashMap
4 TreeMap实现类
特点:key唯一,无序,但实现了排序比大小
底层结构:红黑树
效率:查询效率接近二分查找
5 Properties实现类
Properties是Hashtable的子类,key和value都是String字符串。
特有方法:
- getProperty(String key)
- setPropertiy(String key, String value)
6 Set和Map的关系
HashSet底层是HashMap
LinkedHashMap底层是LinkedHashMap
TreeSet底层是TreeMap
三、底层结构和源码分析
哈希表 = 数组 + 链表 + 红黑树,将数组、链表和二叉搜索数的优点结合在一起,在增删查改时效率均高于单独的数组、链表和二叉树结构。
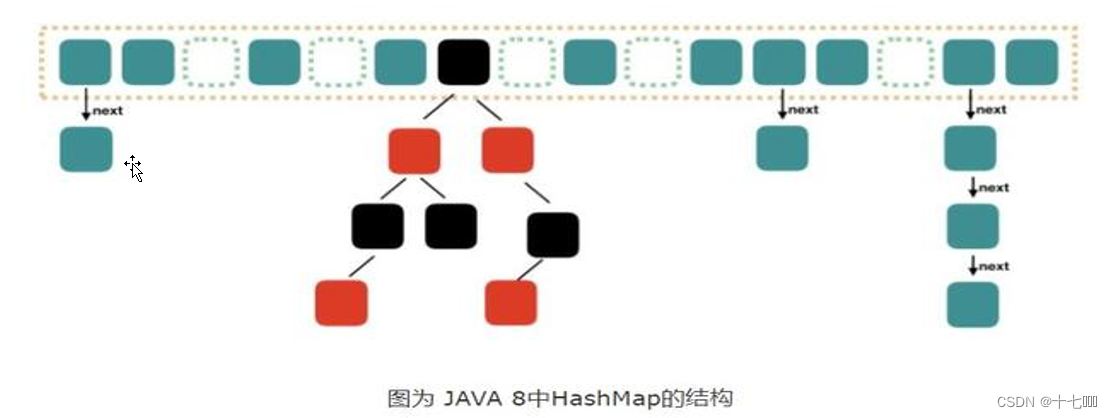
数据插入时会哈希分布到数组的各个位置,只有当某个位置的链表元素个数大于某个值时才会转换成红黑树。当红黑树的深度到达一定数量时,底层数组的大小也会进行扩容。
1 存储元素时的位置的计算过程
- 先计算key的hashCode值
- 让不同的可以对应的value尽量均匀分布,
- 但不同的哈希值进行取模运算时,高位没有参与到运算
- 二次哈希:hash值的高低16位进行异或运算
- 进行异或运算可以将高位的值 参与到后面的取模运算
- hash容量取模运算:获取到元素的在数组中的索引位置
2 临界值
红黑树:当链表长度达到8时,并且容量达到64,转换为红黑树。当红黑树节点数量小于6时,退化为链表。
数组:当元素个数达到扩容阈值(= 容量*加载因子)时,进行扩容。默认初始容量为DEFAULT_INITIAL_CAPACITY = 16。
加载因子默认为0.75,当到达阈值时,需要将所有元素复制到新数组中,并重新计算哈希值。因此初始容量的大小的要最好大于元素个数和负载因子的乘积。