观看当今毁灭人类的智能代理玩复杂的视频游戏可能很有趣 - 但创建一个是另一回事。构建有效的智能代理需要设置大量超参数来塑造环境、建立奖励等。来自马萨诸塞大学阿默斯特分校的一组研究人员试图通过他们新的自主学习图书馆项目来简化这一过程。
自治学习库是 PyTorch 的深度强化学习 (DRL) 库,可简化新型强化学习代理的构建和评估。该计划的核心理念之一是强化学习(RL)应该是基于代理的,这意味着模型只是接受状态和奖励,然后返回一个动作。
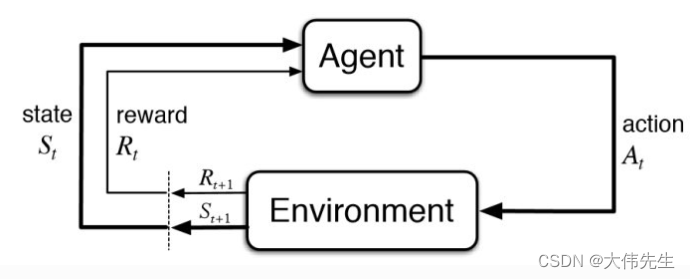
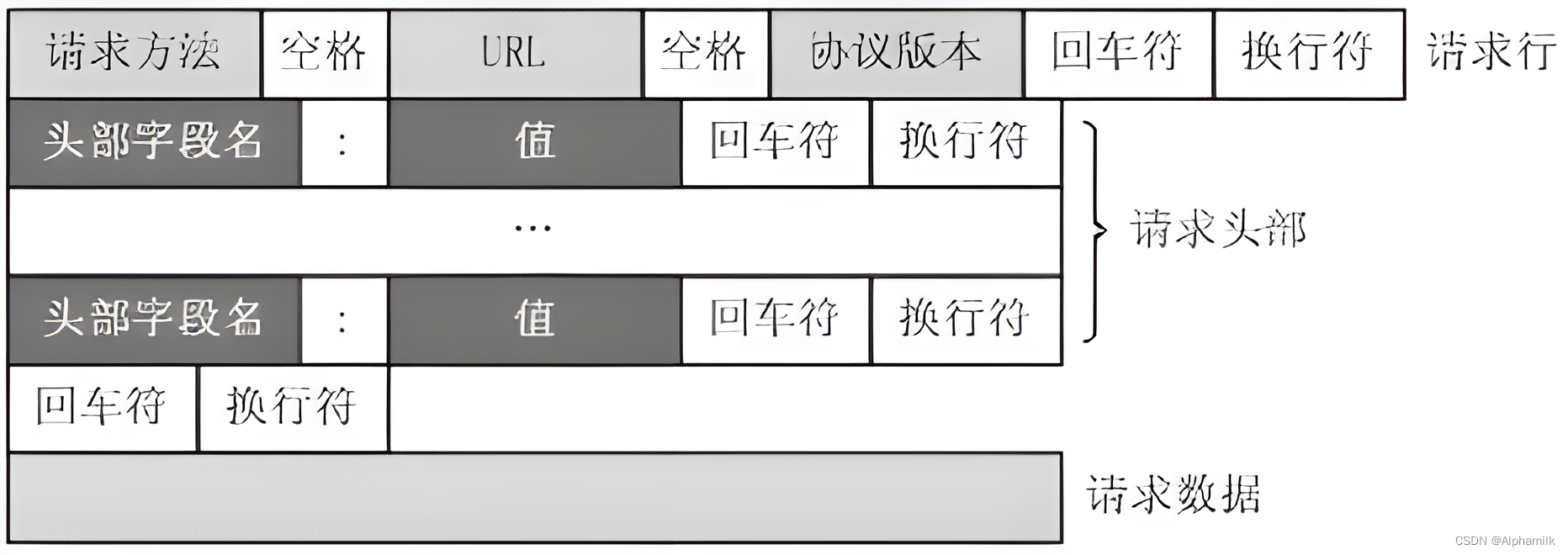
规范代理-环境反馈循环
自治学习库将控制环路与代理逻辑分离,以简化代理实现和控制回路本身,从而提高代理使用方式的灵活性。在这种情况下,该项目允许代理的操作由控制循环确定,从而使代理接口和实现非常简洁。
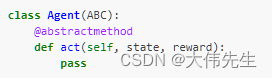
class Agent(ABC):
@abstractmethod
del act(self,state,reward):
pass
自主学习库代理界面

def act(self,state,reword):
self._store_transition(self._state,self._action,reward,state)
self._train()
self._state = state
self._action = self.policy(state)
return self.action
自治学习库中的 DQN 实现
自治学习库将RL代理分为两个不同的模块:“all.agents”和“all.presets”。“all.agents”模块包含常见算法的实现,如Rainbow,A2C,Vanilla等;而“all.presets”提供了这些代理在特定环境下调整的具体示例,例如雅达利游戏、经典控制任务等。
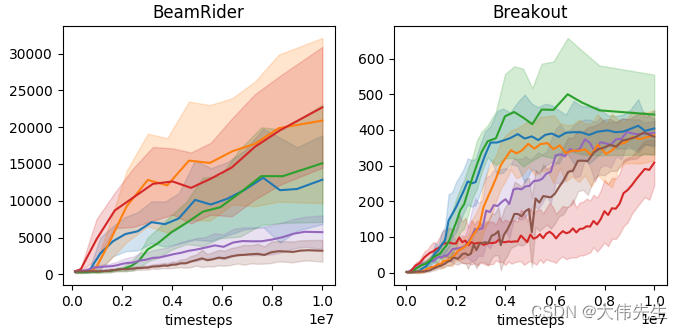
雅达利游戏环境中 RL 代理的基准测试结果
该项目还强调函数逼近模块是其中心抽象之一。通过构建依赖于近似抽象而不是直接与 PyTorch 模块和优化器对象接口的代理,用户可以在不更改其源代码的情况下添加或修改代理的功能(称为“开闭原则”)。这使代理实现能够专注于自行定义 RL 算法。

研究人员还制作了一个示例实现,以演示自主学习库在开发原始库中未包含的新代理方面的效用。虽然结果并没有使代理看起来特别聪明,但它们确实证明了库的实用性。
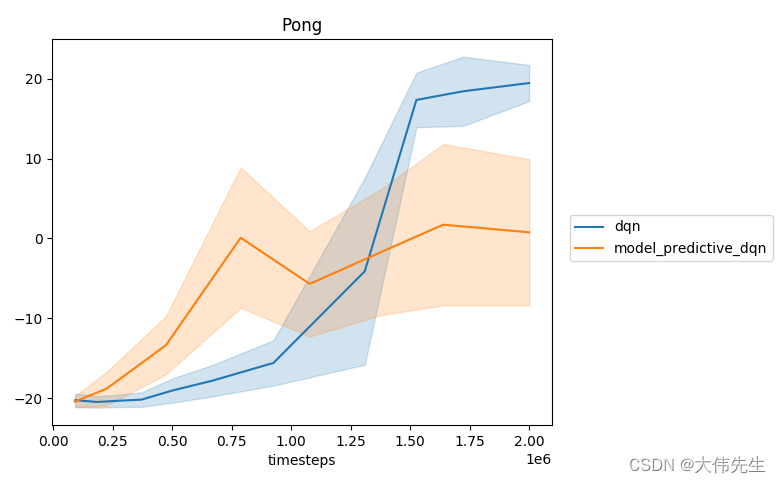
使用自治学习库构建新的 RL 代理的示例演示的结果。
自主学习图书馆项目由马萨诸塞大学阿默斯特分校强化学习博士生克里斯托弗·诺塔(Christopher Nota)分享。其他信息可在项目Github上找到。