CMU 15-445 -- Distributed OLAP Databases -21
- 引言
- OLTP and OLAP
- Star Schema vs. Snowflake Schema
- Problem Setup
- 本节大纲
- Execution Models:Push vs. Pull
- Example #1: Push Query to Data in Shared-Nothing Architecture
- Example #2: Pull Data to Query in Shared-Disk Architecture
- Query Fault Tolerance
- Query Planning
- Approach #1: Physical Operators
- Approach #2: SQL
- Distributed Join Algorithms
- Scenario #1
- Scenario #2
- Scenario #3
- Scenario #4
- Semi-Join
- Cloud Systems
- Serverless Databases
- Disaggregated Components
- Universal Formats
- 小结
引言
本系列为 CMU 15-445 Fall 2022 Database Systems 数据库系统 [卡内基梅隆] 课程重点知识点摘录。
OLTP and OLAP
众所周知,数据库有两种典型使用场景,OLTP 和 OLAP。线上服务与 OLTP 数据库交互,OLTP 数据库再被异步地导出到 OLAP 数据库中作离线分析,如下图所示:
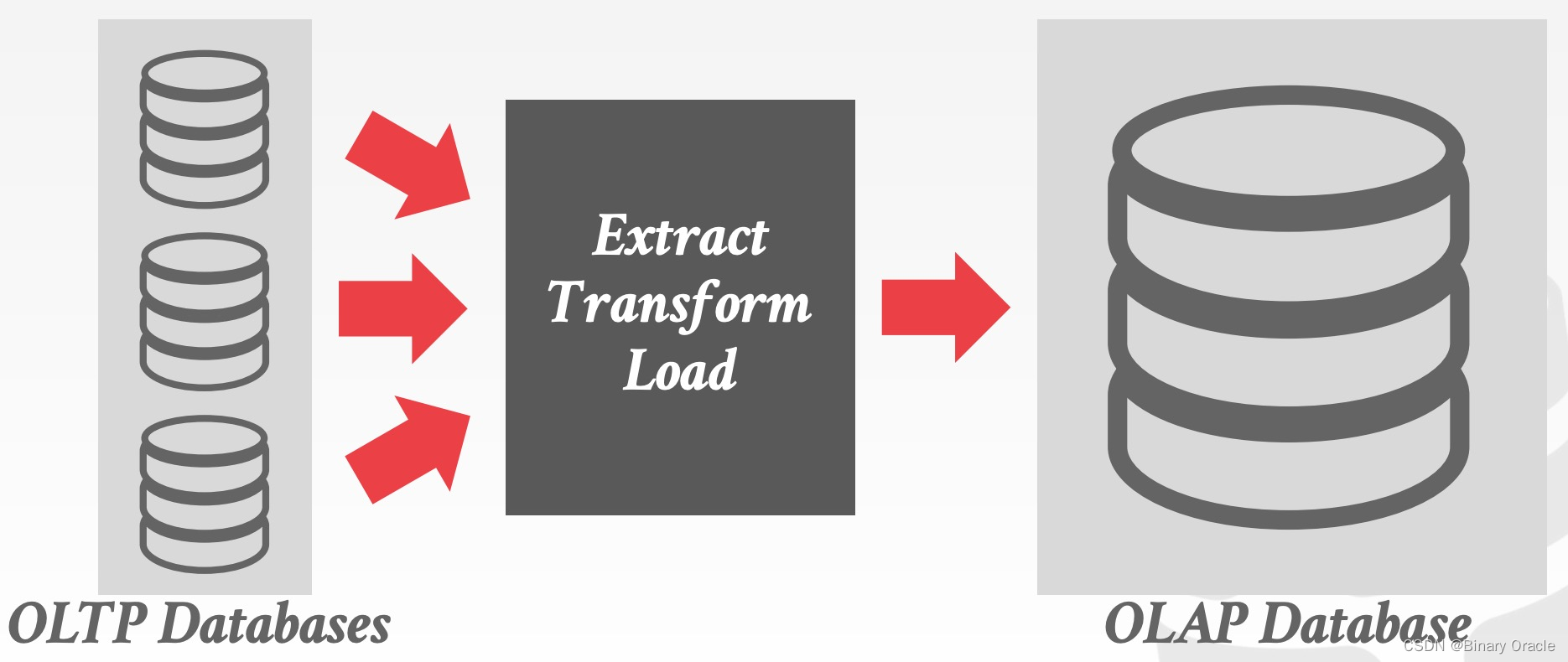
OLTP 数据库就是 OLAP 数据库的前端,通过 ETL 的过程,OLTP 数据库中的数据将被清理、重新整理到 OLAP 数据库上。OLAP 数据库为用户提供复杂的数据查询、分析能力,帮助公司:分析过去和预测未来。
Star Schema vs. Snowflake Schema
ETL 的过程并不只是简单地移动,通常还会涉及表结构的重新整理,以提高后续查询分析的效率。最常见的两种 schema 就是 Star Schema 和 Snowflak Schema:
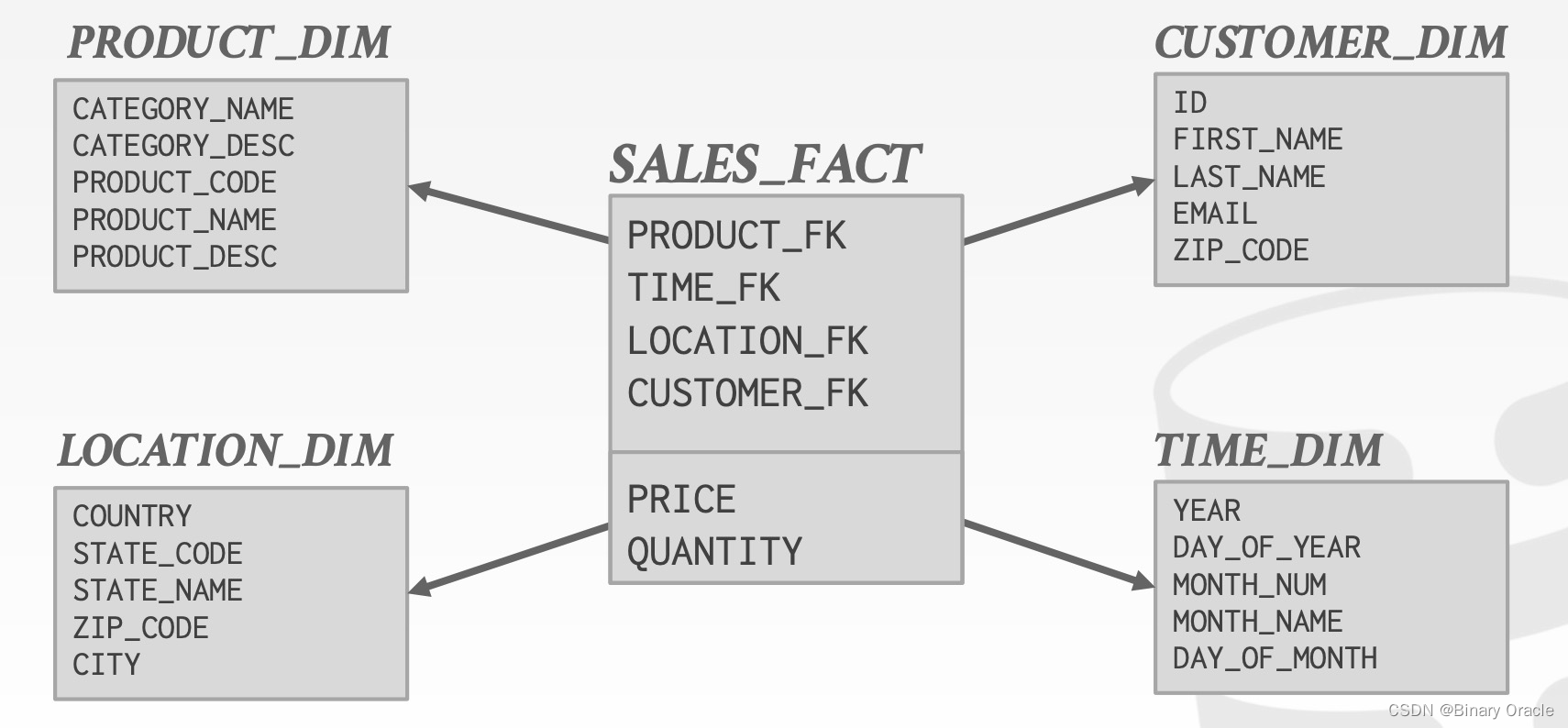
Star Schema 就是一个星形拓扑结构,处在最中间的是 Fact Table,通常记录着业务流程中的核心事件、指标,如成单记录;处在四周的是 Dimension Tables,记录一些补充信息。Fact Table 通过外键与 Dimension Tables 关联,用户可以通过简单的 Join 来分析数据。在 Star Schema 中,只能允许有一层的引用关系,在 Snowflake Schema 中,则允许有两层关系,如:
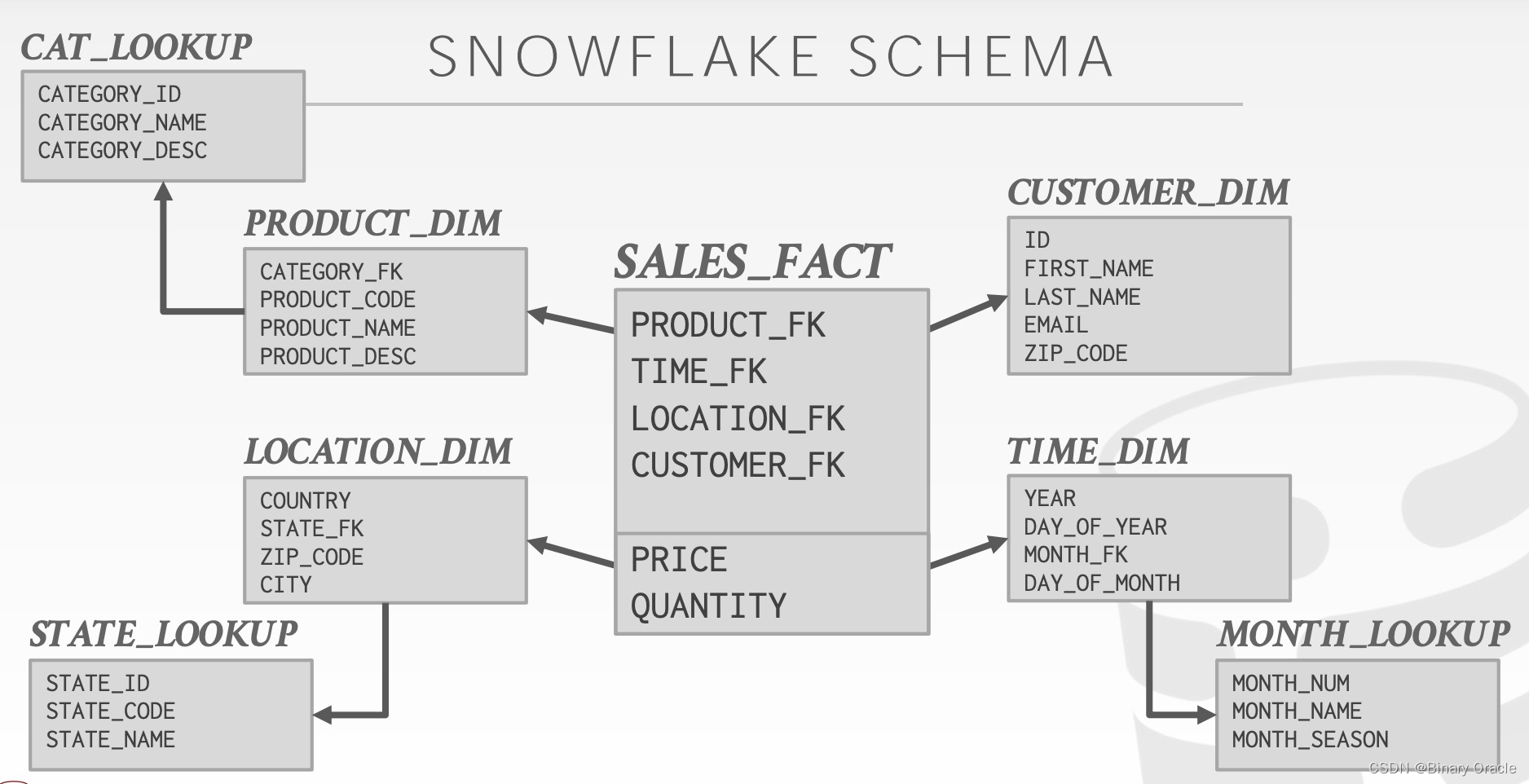
二者的区别、权衡主要在于以下两个方面:
- Normalization:Snowflake Schema 的规范化 (Normalization) 级别更高,冗余信息更少,占用空间更少,但会遇到数据完整性和一致性问题。
- Query Complexity:Snowflake Schema 在查询时需要更多的 join 操作才能获取到查询所需的所有数据,速度更慢。
Problem Setup
想象下面这个最简单的分析场景:
- 一个 join 语句需要访问所有数据库分片
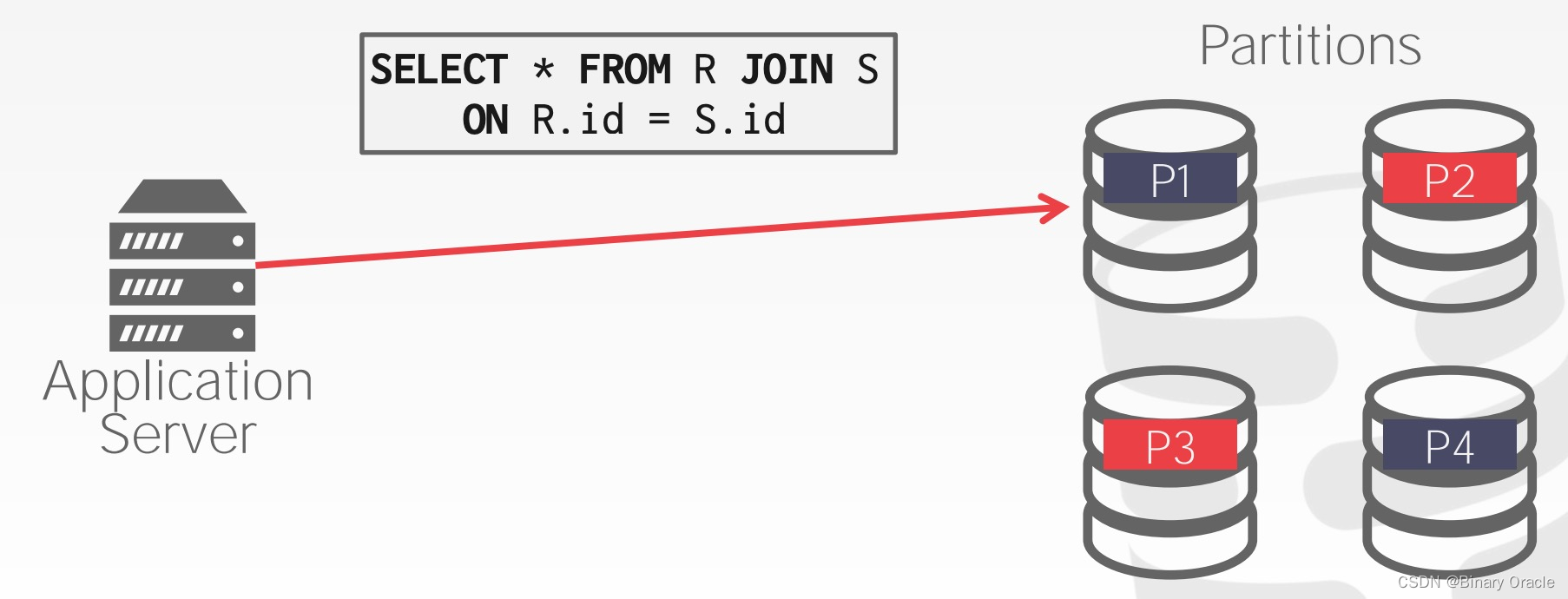
- 要满足这样的需求,最简单的做法就是,将所有相关的数据读取到某一个分片上,然后统一计算
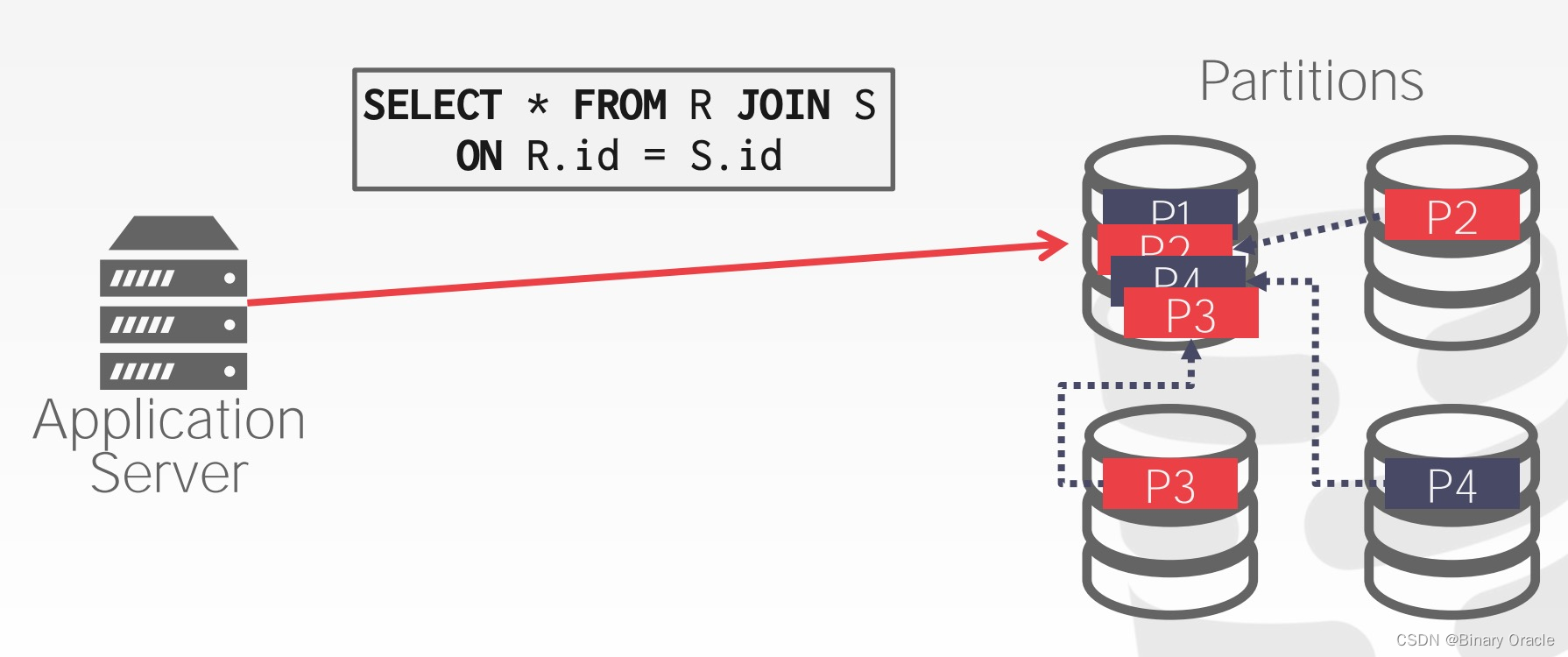
但这在 OLAP 场景下是不可行的。通常 OLAP 就需要访问全量数据,遇到全量数据无法装进一个分片中的情况,就无计可施了。
本节大纲
- Execution Models
- Query Planning
- Distributed Join Algorithms
- Cloud Systems
Execution Models:Push vs. Pull
大体上,查询的执行模式分为两种:
- Approach #1: Push Query to Data
- 将查询、或查询的一部分发送到拥有该数据的节点上
- 在相应的节点上执行尽可能多的过滤、预处理操作,将尽量少的数据通过网络传输返回
- Approach #2: Pull Data to Query
- 将数据移动到执行查询的节点上,然后再执行查询获取结果
对于数据库来说,Push Query to Data 和 Pull Data to Query 并不是非此即彼的选择,在不同类型的分布式数据库、不同的查询执行阶段上,也有可能使用不同的执行模式。
Example #1: Push Query to Data in Shared-Nothing Architecture
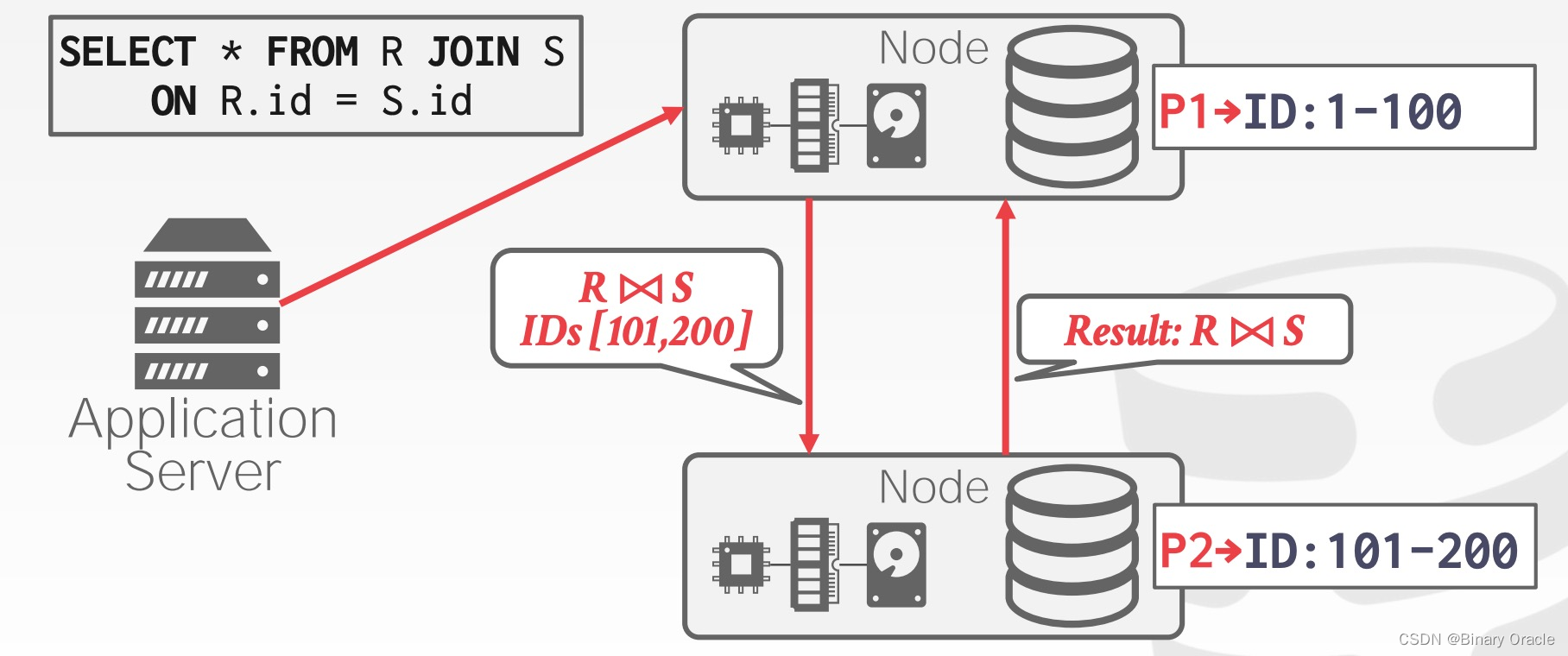
如上图所示:应用程序将查询请求发到上方的节点,称为节点 A。节点 A 发现 ID 在 1-100 之间的数据就在本地存储;而 ID 在 101-200 之间的数据位于下方的节点,称为节点 B。因此节点 A 将查询发给节点 B,由节点 B 负责将 101-200 之间的数据 join,然后将 join 的结果返回给节点 A,而节点 A 则自行将 1-100 之间的数据 join,最终节点 A 将所有数据整理好返回给应用程序。整个过程对应用程序透明。
Example #2: Pull Data to Query in Shared-Disk Architecture
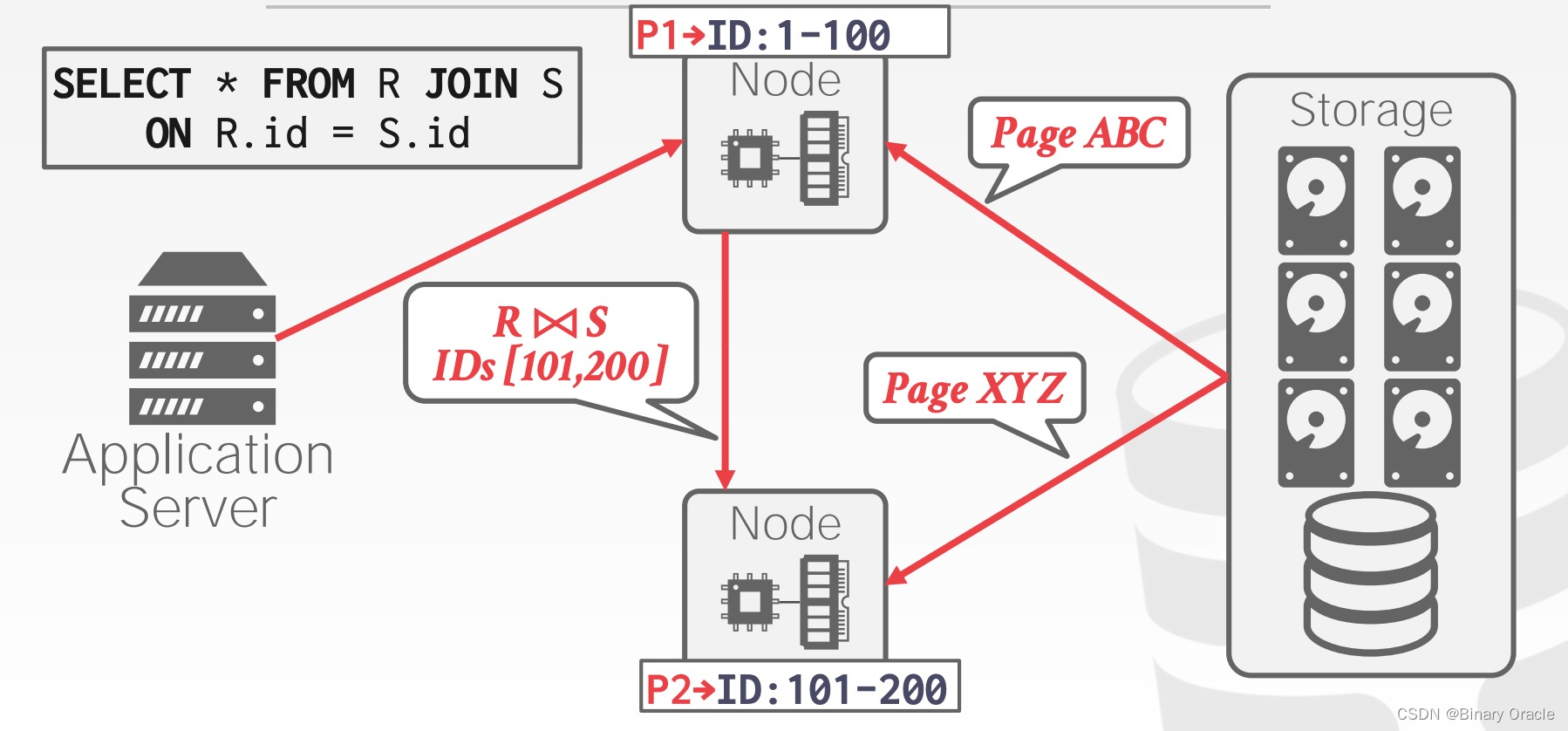
如上图所示:在 shared-disk 架构下,节点 A 可以将计算分散到不同的节点上,如 1-100 的在 A 节点上计算;101-200 的在 B 节点上计算。A,B 拿到计算任务后,就将各自所需的数据 (page ABC、XYZ) 从共享的存储服务中取出放到本地。这个取数据的过程就是 Pull Data to Query。当 B 节点中的计算任务执行完后,B 节点将结果返回给 A 节点,A 节点再将自己的结果与 B 节点的结果结合,得到最终的结果返回给应用程序:
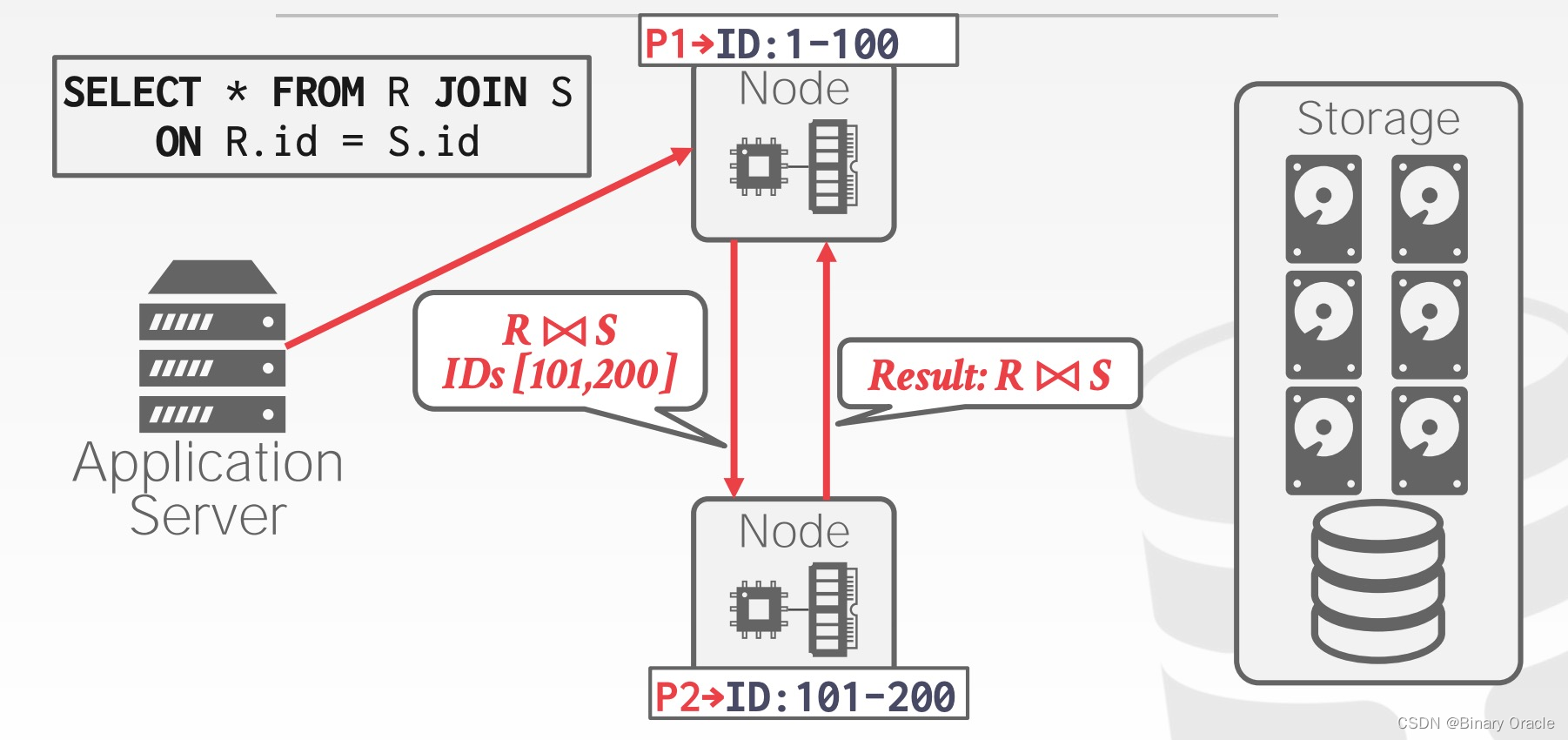
后面这步又有点类似 Push Query to Data,因此我们需要注意 Push 和 Pull 并不是在一次查询执行过程中只能取其一,也可能是一种混合过程。
Query Fault Tolerance
每个节点都会有自己的缓存管理器,从其它计算节点获取的数据可能会被缓存在本地的缓存池中,方便缓存中间结果,我们甚至可以将这些中间结果持久化的本地磁盘中的临时文件,这允许我们缓存比内存更大的数据,但这些数据在重启之后都会消失,那么对一个需要运行很长时间的 OLAP 查询来说,如果一个节点挂了怎么办?
对于 OLTP 数据库,有大量的写事务,一旦告诉客户端事务提交成功,那么它必须保证规定范围内的故障不会导致数据丢失;对于 OLAP 数据库,只有读请求,几乎没有数据库选择向用户提供类似的容错机制,一个查询在执行过程中如果遇到节点故障,就直接返回错误,让用户重试。当然,如果真的面对常常会遇到故障的场景,一些 OLAP DBMS 可以选择存储中间结果的快照数据,在节点故障后能恢复当时的部分执行结果,避免重复计算。
Query Planning
我们在单机数据库上讨论过的所有优化,在分布式场景下同样适用,如:
- Predicate Pushdown
- Early Projections
- Optimal Join Orderings
当然,分布式查询优化还需要考虑数据的位置信息、数据移动的成本,因此分布式查询肯定需要将查询的过程分解成多个部分 (Query Plan Fragments),可以并行执行,从而最大程度地利用分布式系统的扩展性。分布式数据库的查询优化主要有两种粒度:Physical Operators、SQL。
Approach #1: Physical Operators
先生成一个查询计划,再将它按数据分片信息 (partition-specific) 分解成多个部分,分发给不同的节点。大部分数据库采用的就是这种做法。
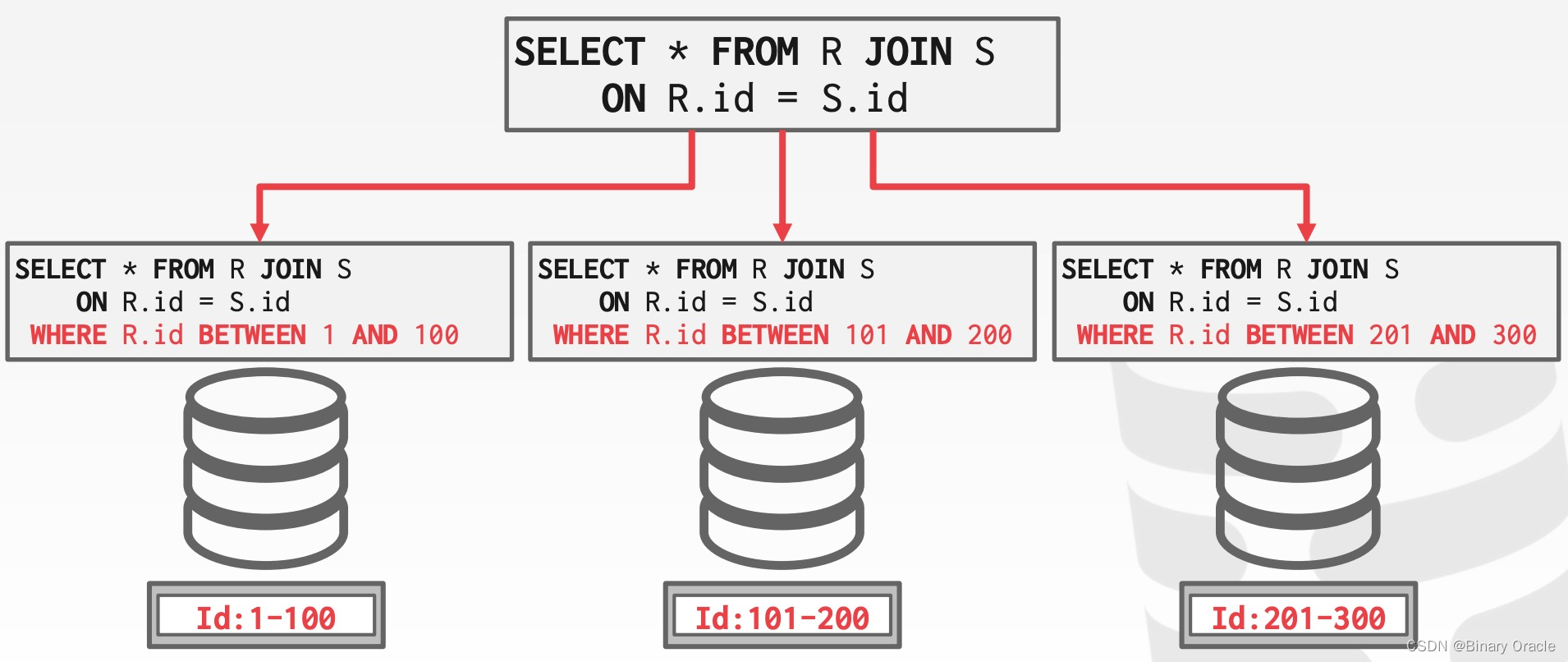
Approach #2: SQL
将原始的 SQL 语句按分片信息重写成多条 SQL 语句,每个节点自己在本地作查询优化。AP 说他只见过 MemSQL 采用了这种方案,举例如下:
Distributed Join Algorithms
在刚才的讨论中,我们利用了这样一句 SQL 语句:
SELECT * FROM R JOIN S ON R.id = S.id
但我们忽略了一个细节,即我们假设 R 和 S 表中 id 在相同范围内的数据位于同一个节点上。这样的假设并不现实。实际上,要获得 R 和 S join 的结果,我们还需要先将 join 所需的数据移动到同一个节点上。一旦移动完毕,我们就可以使用之前学习的单机 join 算法完成余下的计算。
下面讨论这条 SQL 在不同场景下的 join 执行过程:
Scenario #1
参与 Join 的两张表中,其中一张表 (假设为 S 表) 复制到了所有节点上,那么每个节点按 R 表的分片信息执行 join,最后聚合到 coordinating node 上即可:
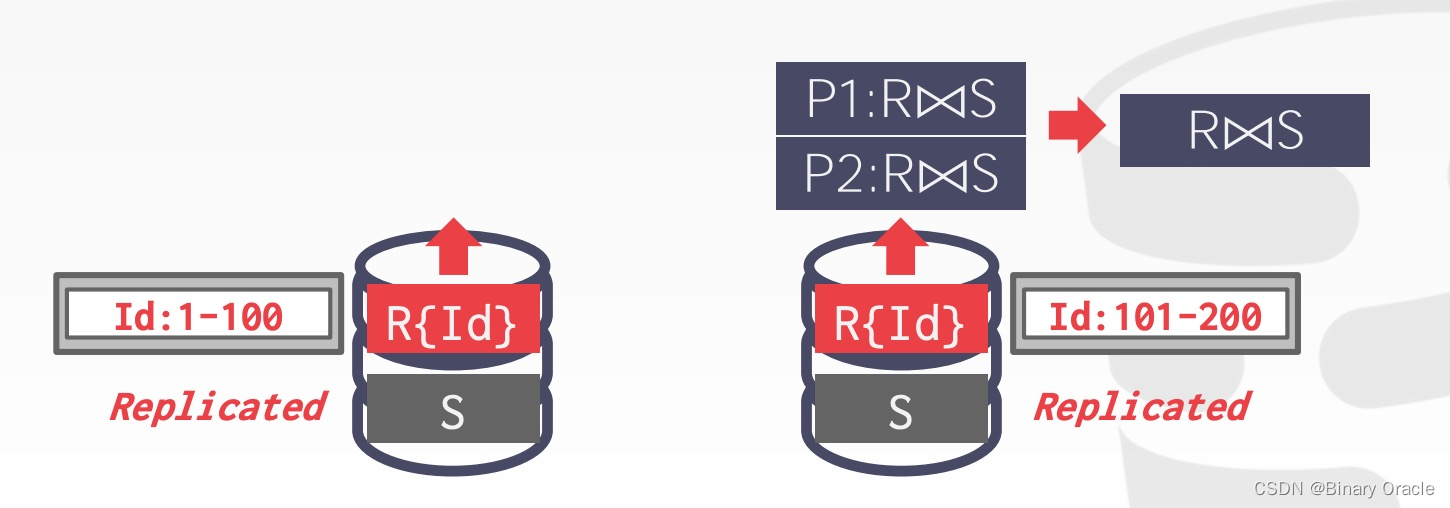
Scenario #2
恰好 R 和 S join 的字段就是 partition 的字段,那么每个节点本地 join,最后聚合到 coordinating node 上即可,与我们之前的假设一致:
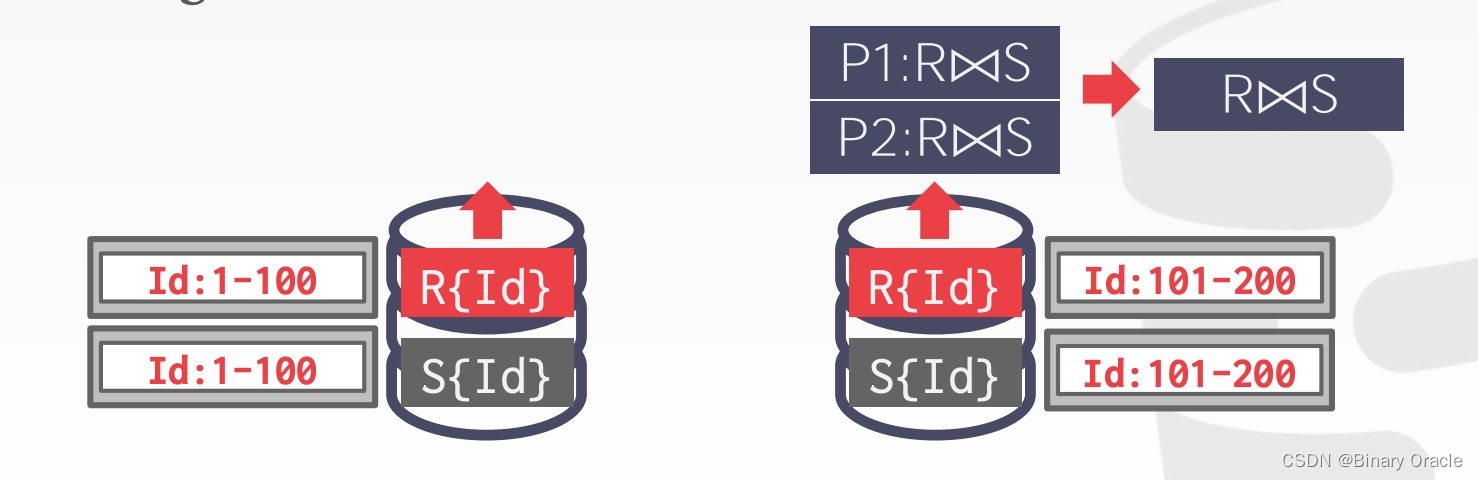
Scenario #3
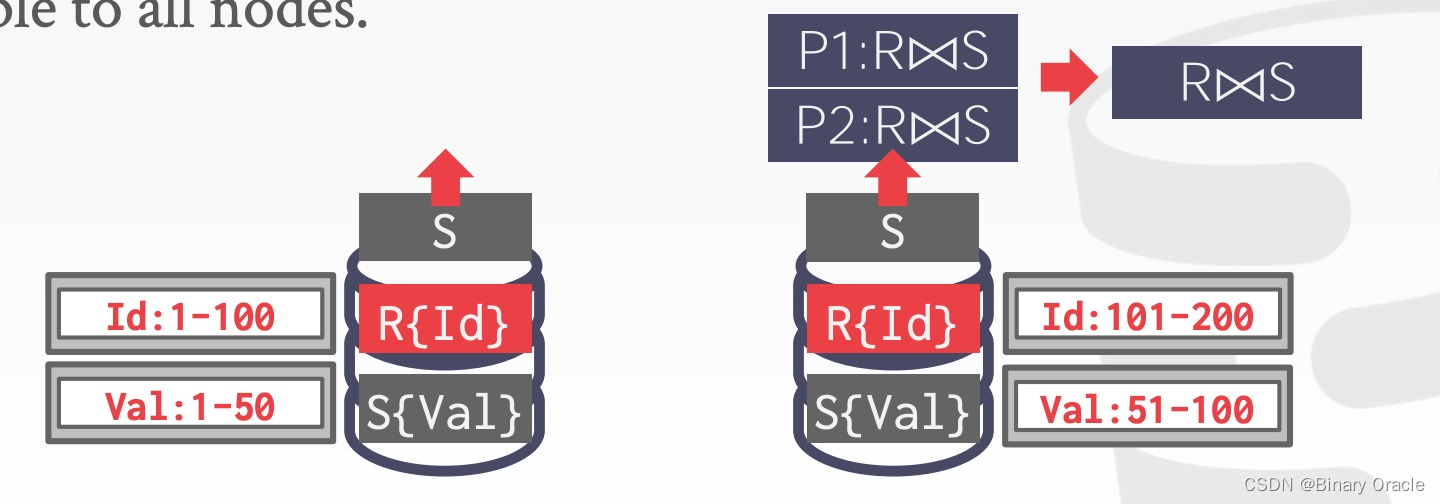
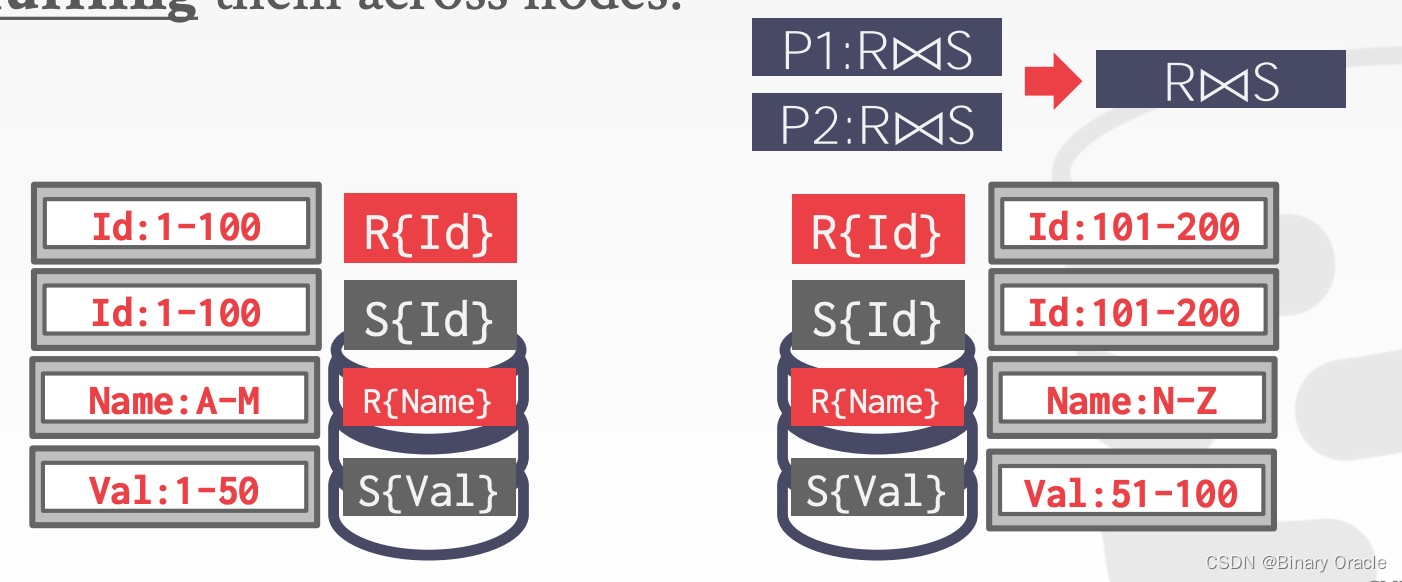
如果 R 和 S 是根据不同 key 来分片,其中一张表 (S) 的 key 不是 join key 且数据量很小,那么 DBMS 可以将这张小表广播到所有需要执行计算的节点上,这样执行时就可以按 R 的分片信息来执行,最后汇总结果:
- R按照ID分片,S按照Val分片
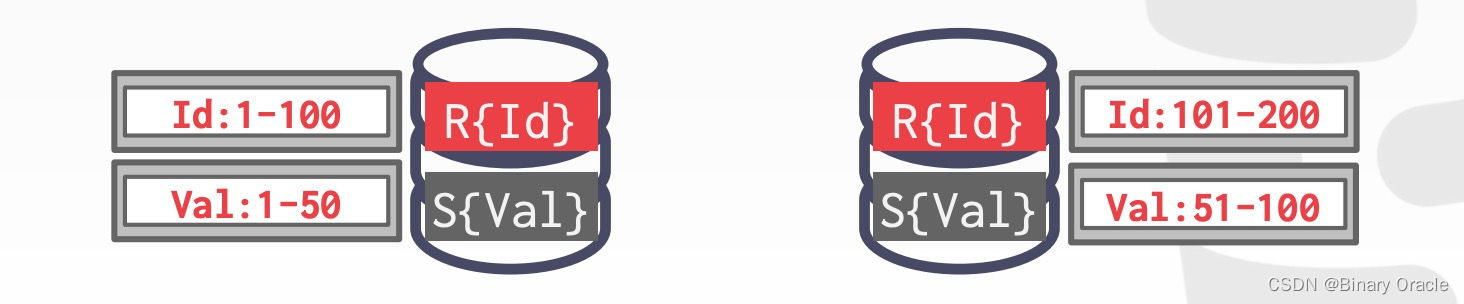
- 左边分片将 S 表的部分数据同步到右边分片
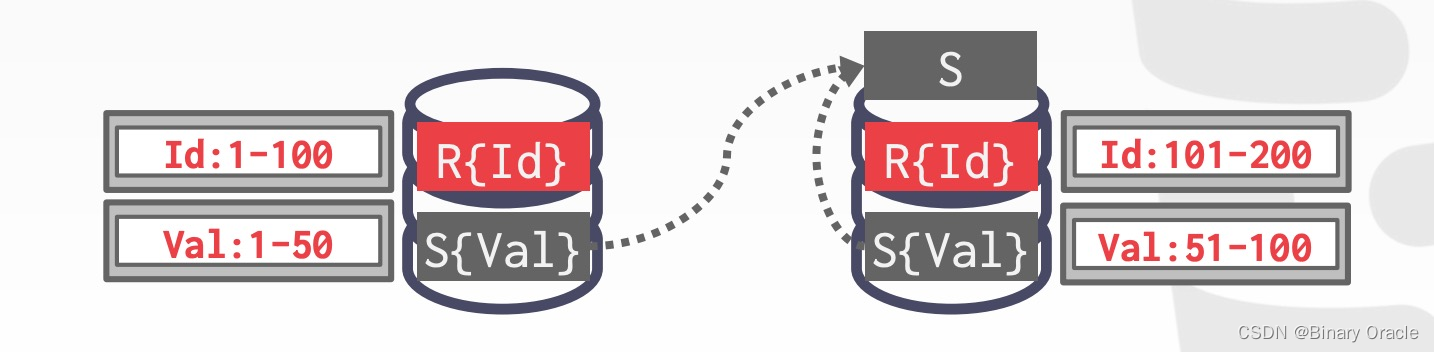
- 右边分片将 S 表的部分数据同步到左边分片
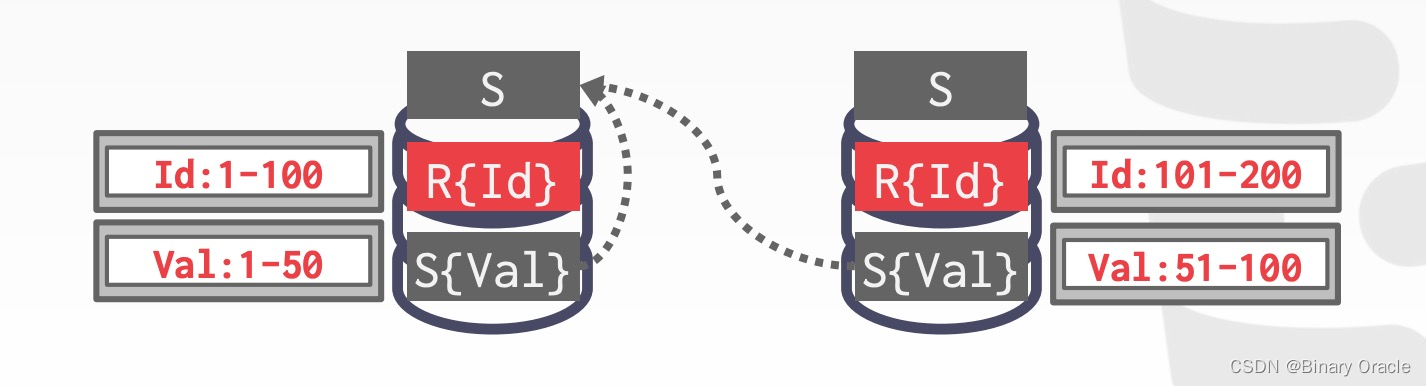
- 分别在两个节点上执行 Join 操作,然后汇总结果并返回
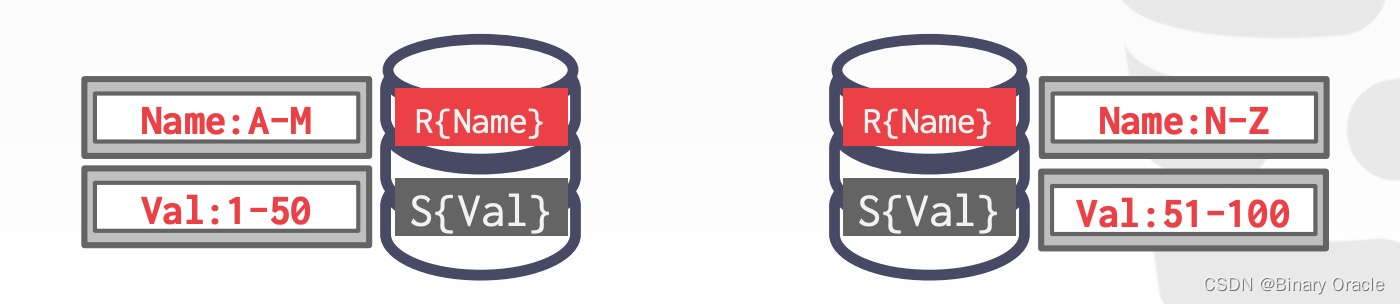
Scenario #4
两张表都不是按照 join key 来分片。DBMS 需要将数据表按照 join key 重新洗牌,挪动到对应的位置,再执行 join 操作:
- R 和 S 都不是按照 join key 分片
- 将 R 表中 id 为 101-200 的数据移动到右边节点
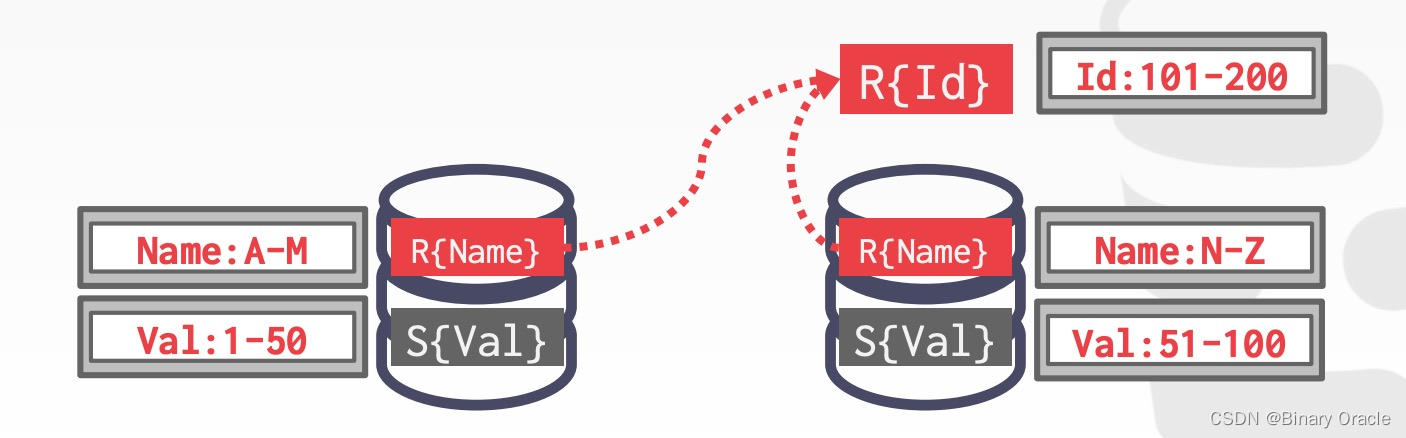
- 将 R 表中 id 为 1-100 的数据移动到左边节点
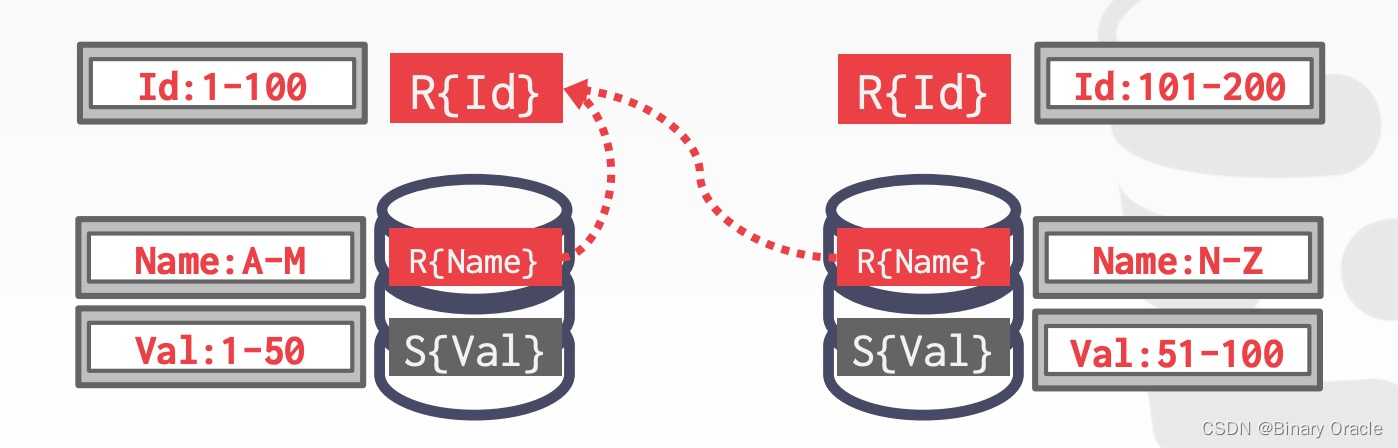
- 将 S 表中 id 为 101-200 的数据移动到右边节点
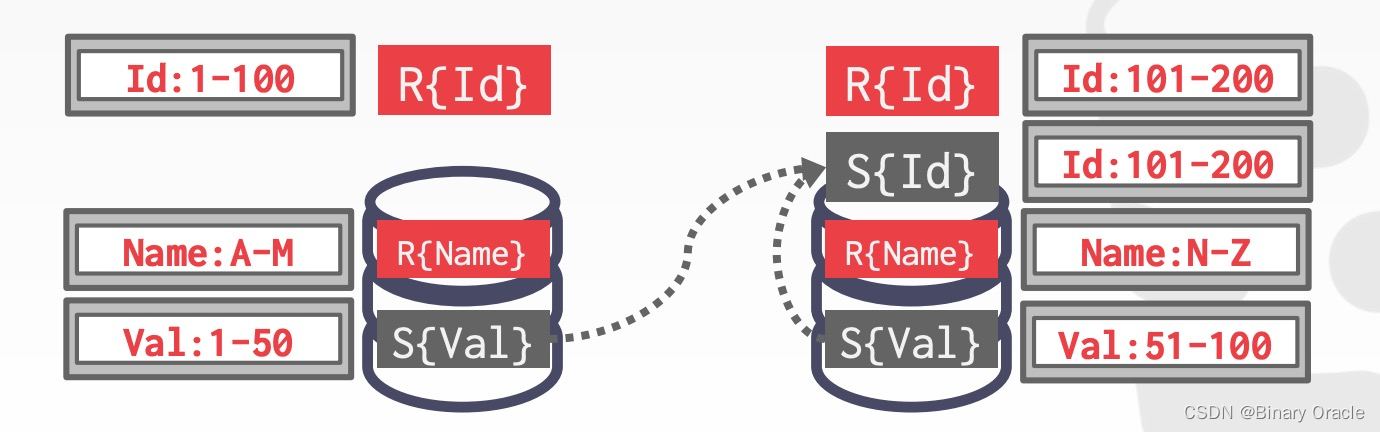
- 将 S 表中 id 为 1-100 的数据移动到左边节点
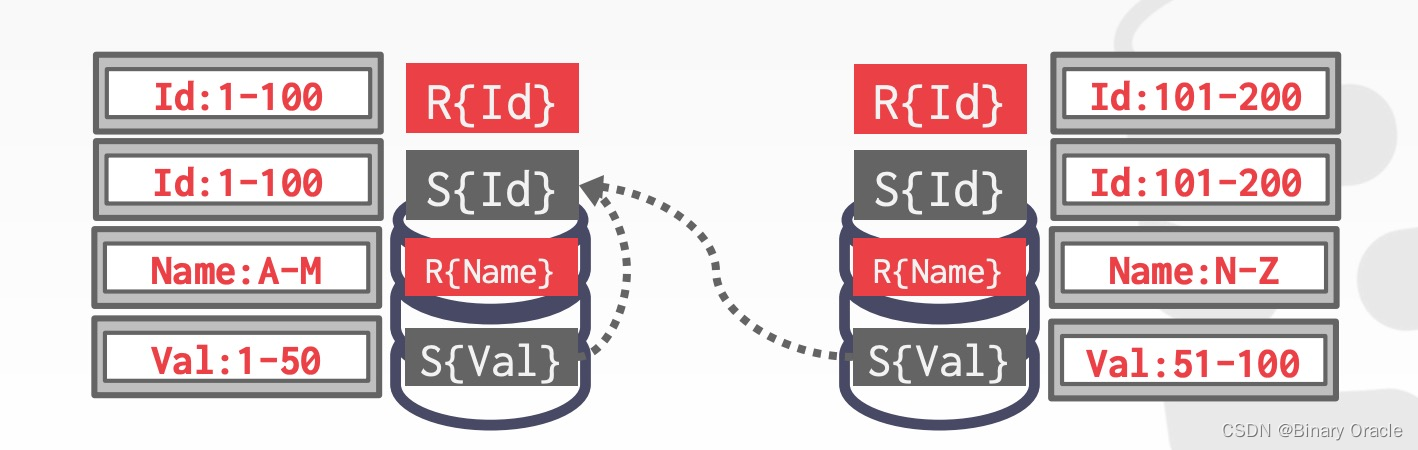
- 在两个节点上执行 Join
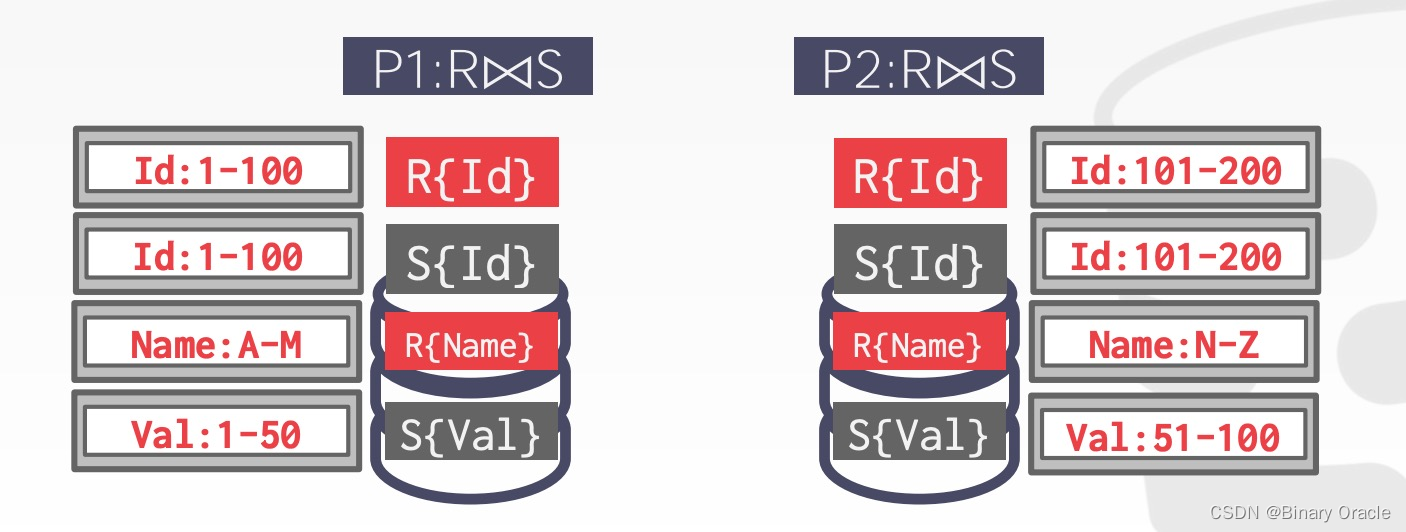
- 合并结果并返回
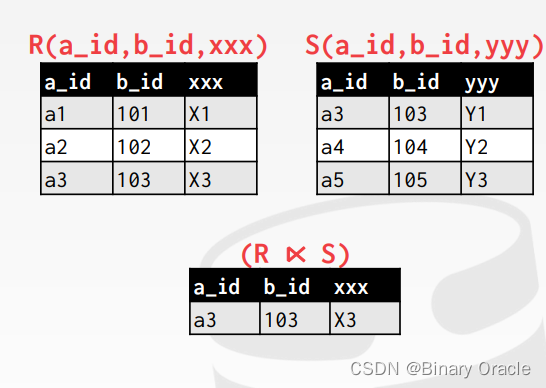
Semi-Join
semi-join 指的是当 join 的结果只需要左边数据表的字段,右边数据表的字段仅仅是用来做筛选的情况。在分布式数据库中,可以对这种特殊情况优化数据移动量,从而减少 join 成本。一些数据库支持 semi-join 的 SQL 语法,如果不支持则可以使用 EXISTS 语法来模拟:
SELECT R.id FROM R
WHERE EXISTS (
SELECT 1 FROM S
WHERE R.id = S.id);
这一点很像之前说的 projection pushdown 。
semi-join很像普通的join查询,不过semi-join针对的是不需要右表字段参与计算的场景:
Cloud Systems
OLAP 数据库的云服务也分为两类:
- Approach #1: Managed DBMS
- 将开源单机数据库挪到云上,增加一些小的修改,大多数供应商采用这种做法
- Approach #2: Cloud-Native DBMS
- 为云原生环境而设计
- 通常基于 shared-disk 架构
- 一些例子包括:Snowflake,Google BigQuery,Amazon Redshift 以及 Microsoft SQL Azure
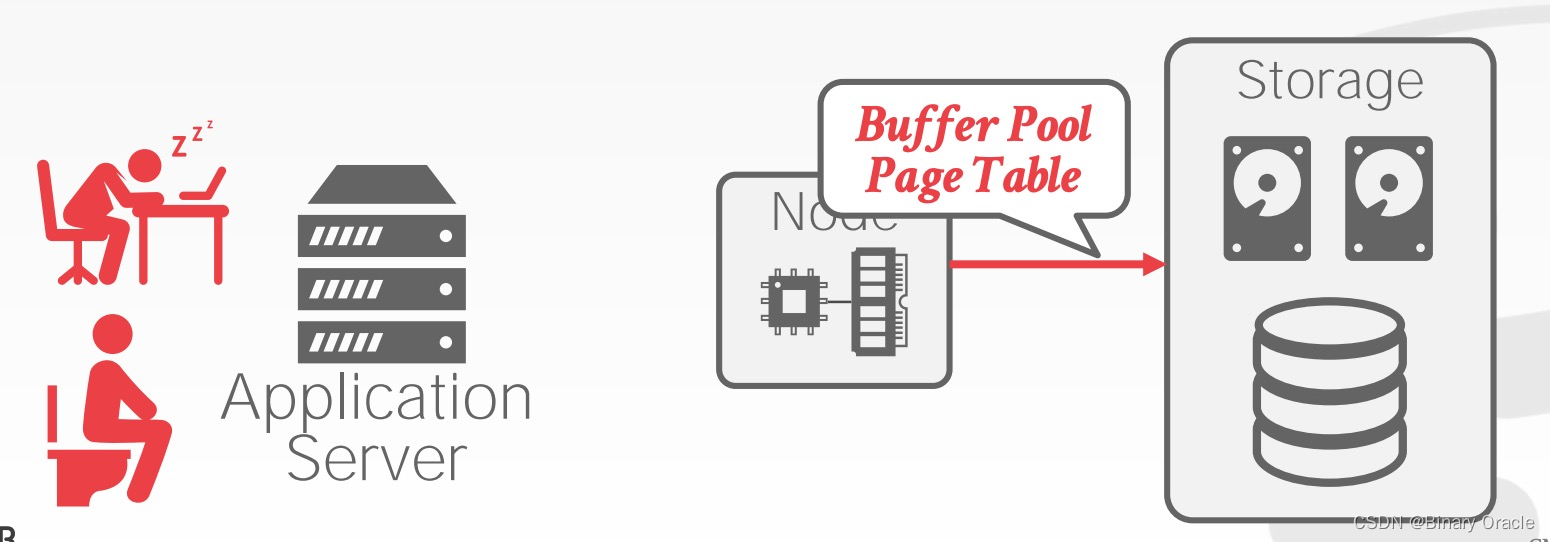
Serverless Databases
基本思想就是,在空闲期间回收计算资源,租户只需要为存储资源买单,节省租户成本。实现的基本思路就是空闲指标达到一定阈值时,将 Buffer Pool Page Table 持久化:
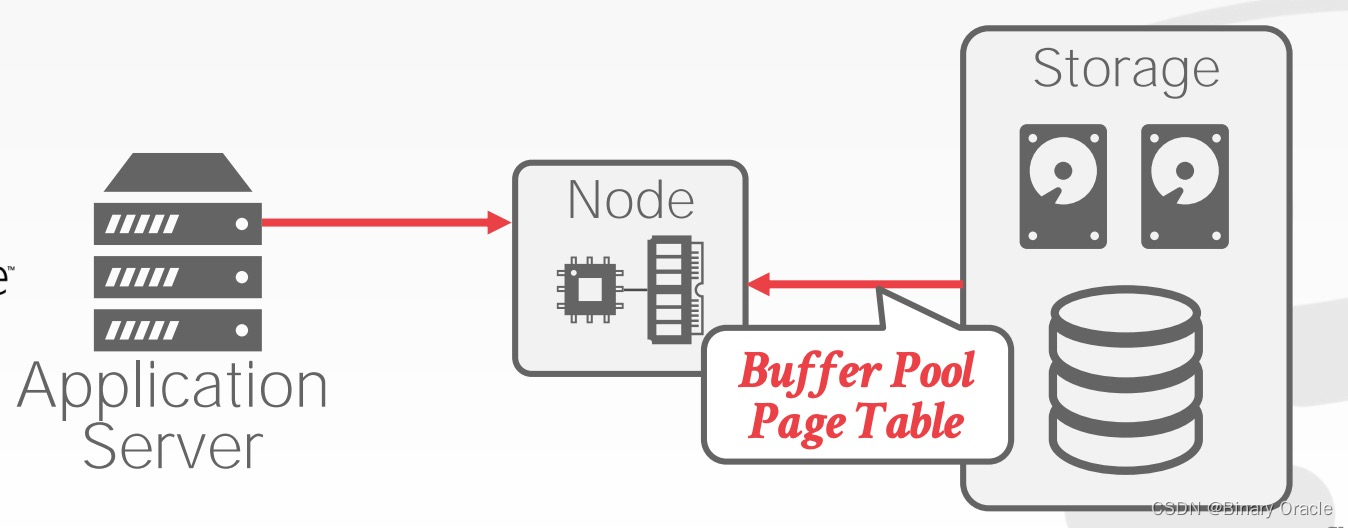
当活跃请求到来时,再将其载入到内存中:
Disaggregated Components
一些云服务商也提供 OLAP 数据库所需的模块服务,如:
- System Catalogs
- HCatalog
- Google Data Catalog
- Amazon Glue Data Catalog
- Node Management
- Kubernetes
- Apache YARN
- Cloud Vendor Tools
- Query Optimizers
- Greenplum Orca
- Apache Calcite
Universal Formats
大多数 DBMS 都使用自主设计研发的二进制文件格式存储数据,因此在异构 DBMS 之间共享数据的唯一方法就是将这些数据转化成一些常见的文本格式,如 csv,json,xml 等。为了解决这个问题,也有一些开源的二进制文件格式出现:

小结
More money, more data, more problems… 这句话是CMU 15-445这门课程的结束语,下一步大家可以进入数据库高级课程学习:
- cmu15-721 – 高级数据库系统
同时作为cmu 15-445配套教材的帆船书也非常值得一看:
还有就是cmu 15-445 对应课程lab, 相比MIT 6.830的实现来说更有挑战性。
最后就是阅读相关开源数据库的源码。
本节对应教材PDF