写在前面
在刚刚结束的 ACCV 2022 国际细粒度图像分析挑战赛中,我们团队在 133 支参赛队伍中脱颖而出,在 Leadboard-B 上以 2.5 的绝对优势取得冠军。

比赛成绩截图
在比赛过程中,我们使用了一些对细粒度分类十分有效的解决方案。
- 例如,在数据清洗方面我们去掉二义性的图片;
- 模型选择和方法方面我们使用了 ViT-L和 Swin-v2;
- 为了提高实验效率,方便整个实验过程的管理,我们基于 MMSelfSup 和 MMClassification 两个开源算法框架开展比赛。
所有的模型权重和全部代码都已经开源,欢迎大家使用。
本次赛事相关的所有预训练,微调以及推理的代码和配置文件分别放在 MMSelfSup 以及 MMClassification 的 projects 中, 欢迎大家 star 和使用。
自监督预训练部分:
https://github.com/open-mmlab/mmselfsup/tree/dev-1.x/projects/fgia_accv2022_1st
微调与模型推理:
https://github.com/open-mmlab/mmclassification/tree/dev-1.x/projects/fgia_accv2022_1st
今天这篇文章我们将整体介绍此次夺冠的方案,希望为大家提供一些经验以供参考。
本周四晚,受 OpenMMLab 社区开放麦栏目的邀请,我们也将会针对本次的冠军方案开展直播,介绍更多的比赛细节,分享比赛期间的经验教训,欢迎大家预约观看!
(插入预约链接)
比赛介绍
ACCV 2022 细粒度图像分析挑战赛是由南京理工大学和澳大利亚 University of Wollongong 主办、极市平台提供技术支持的国际性赛事。
本赛事涉及的细粒度图像分析是计算机视觉和模式识别中的热门研究课题,其目标是对细粒度级别图像中的物体子类(如不同种类的“狗”:“哈士奇”、“阿拉斯加”、“萨摩耶”)进行定位、识别及检索等视觉分析任务的研究,具有真实场景下广泛的应用价值。然而因细粒度级别子类别间较小的类间差异和较大的类内差异,使其区别于传统图像分析问题成为更具挑战的任务。
此次我们参加的赛题是:网络监督的细粒度识别,接下来我们将从数据清洗、模型选择、训练技巧(Bag-of-tricks)、模型集成和后处理等角度介绍我们的方案。
数据清洗
官方提供的数据包含: Train, Test-A, Test-B。Train 是用于训练的数据,这部分数据官方提供了 label。同时因为这项比赛分为 A/B 榜,所以 Test A 和 Test B 分别是用于评测的数据,这两部分数据是可以获得的,但是他们的 label 是不提供的。 这几部分的数据的详细信息如下:
Train: 835K
Test-A: 60K
Test-B: 90K
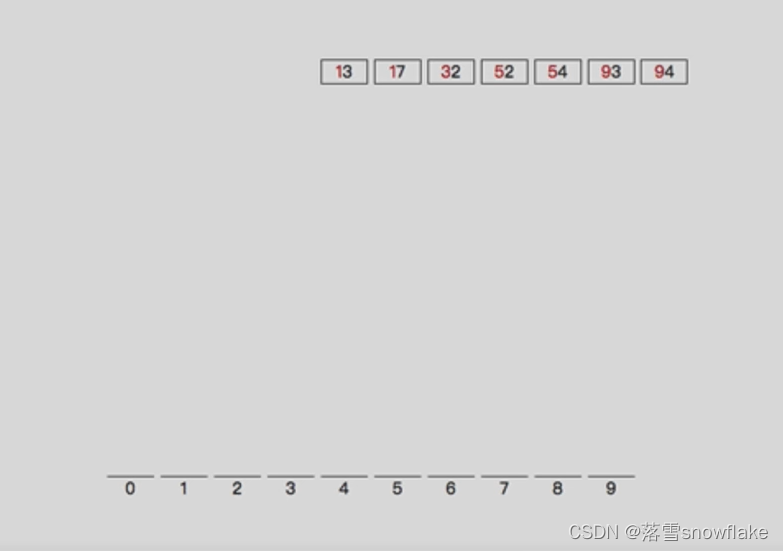
对于用于训练的数据 Train, 其分布如下:
可以发现该数据为长尾分布,其中最多类的数据有 422 张图,最少类数据却只有 3 张图, 均值为 166 张。 除了以上的分布问题,训练数据还存在以下几个问题:
- 有噪声的图片,数据集中存在大量的图表图片(如下面这些图片所示)
- 有些图片的分辨率非常小
- 有一部分图片有多个 label
- 有些数据不可读取
针对以上问题,我们尝试了以下几种方案:
成功的方案:
- 我们过滤掉这些不可读取的图片,一共 4687 张
- 根据哈希文件名,过滤掉这些具有多个 label 的图片
- 我们不创建额外的 validation set,所有数据用于训练
无明显效果的方案:
- 由于数据集是一个长尾分布,我们尝试了 class-balanced sampler
- 采用聚类方法,将这些离群的异常值除去掉
模型选择和方法
考虑到模型性能和速度,我们所有实验均采用 ViT-L 和 Swin-V2。方法总览如下图所示:

总结起来就以下几步:
- 对 ViT-L[1] 和 Swin-V2[2] 进行自监督预训练
- 使用预训练的权重进行微调(fine-tunine)
- 然后对各个模型进行集成
- 推理时候进行数据的后处理
其中第 2 步和第 3 步通过自蒸馏的形式进行迭代,自蒸馏是指本次训练得到的集成模型充当 teacher 对下一轮模型的训练进行指导。
调试技巧
在分类微调(fine-tuning)的过程中我们使用了以下几种策略:

模型集成
我们最终使用了 17 个模型进行集成,其中包含 10 个 ViT-L 模型和 7 个 Swin-v2 模型,集成的权重通过其分别在 Test A 上的精度,按比例得到。总体来说就是,高精度模型权重更大,低精度模型权重更小。
后处理
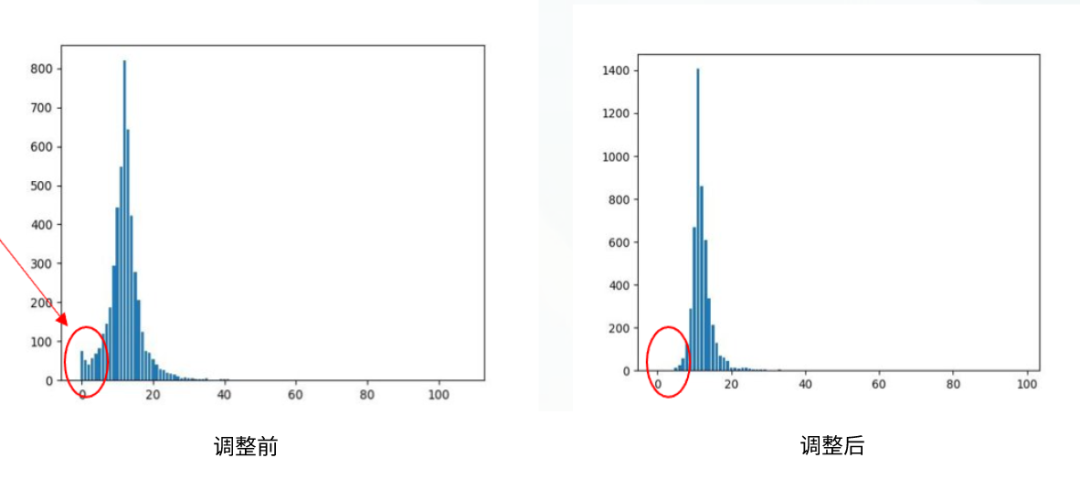
因为比赛中有说明,Train 集中的类别不平衡,但 Test 集中类别是按均匀分布的,所有对最后的预测结果,我们微调了标签的分布,调整前后的标签分布如下图所示:
总结
最终,我们模型的消融效果如下图所示:

图十一 性能消融实验分析
代码仓库
考虑到效率和实验管理,我们选择了 MMSelfSup 和 MMClassification,这两个库均来自于 OpenMMLab 开源框架。
此次赛事相关的所有预训练,微调以及推理的代码和配置文件分别放在 MMSelfSup 和 MMClassification 的 projects 中, 欢迎大家 star 和使用。
自监督预训练部分:
https://github.com/open-mmlab/mmselfsup/tree/dev-1.x/projects/fgia_accv2022_1st
微调与模型推理:
https://github.com/open-mmlab/mmclassification/tree/dev-1.x/projects/fgia_accv2022_1st
相较于市面上的其他库,这两个库具有以下优点:
- 丰富的模型库,便捷的跨库调用。例如 MMSelfSup 自带 MAE,其预训练无需改变任何代码就可以在 MMClassification 中使用。
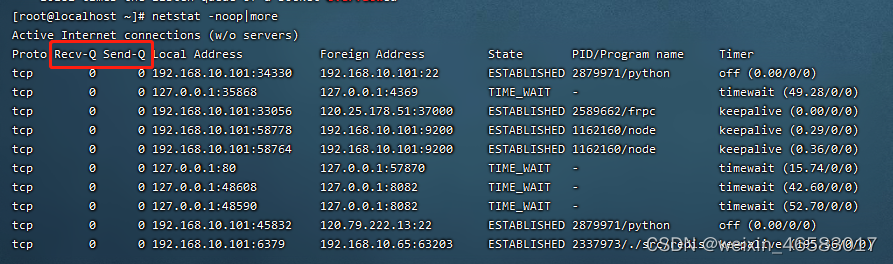
- 方便的实验管理。下图展示了本次比赛的实验记录,每次实验都会保存在对应的文件夹下,包括详细的训练日志、可复现的 config、相关 checkpoint 等等,可便捷地进行配置对比。
- 丰富多元的各种数据增强策略,包括 RandomAug,RandomErase,MixUP,CutMiX,TTA 等等。

实验日志信息截图
我们也将于本周四晚在 OpenMMLab 社区开放麦开展直播,介绍冠军方案更多的比赛细节,分享比赛经验,欢迎预约观看!
引用
[1] An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
[2] Swin Transformer V2: Scaling Up Capacity and Resolution
[3] ArcFace: Additive Angular Margin Loss for Deep Face Recognition
[4] Masked Autoencoders Are Scalable Vision Learners
[5] SimMIM: A Simple Framework for Masked Image Modeling
[6] Sub-center ArcFace: Boosting Face Recognition by Large-scale Noisy Web Faces
[7] AdaptiveMarginArcFace: Google Landmark Recognition 2020 Competition Third Place Solution
[8] The Equalization Losses: Gradient-Driven Training for Long-tailed Object Recognition
[9] Learning with not Enough Data Part 1: Semi-Supervised Learning
[10] Model soups: averaging weights of multiple fine-tuned models improves accuracy without increasing inference time