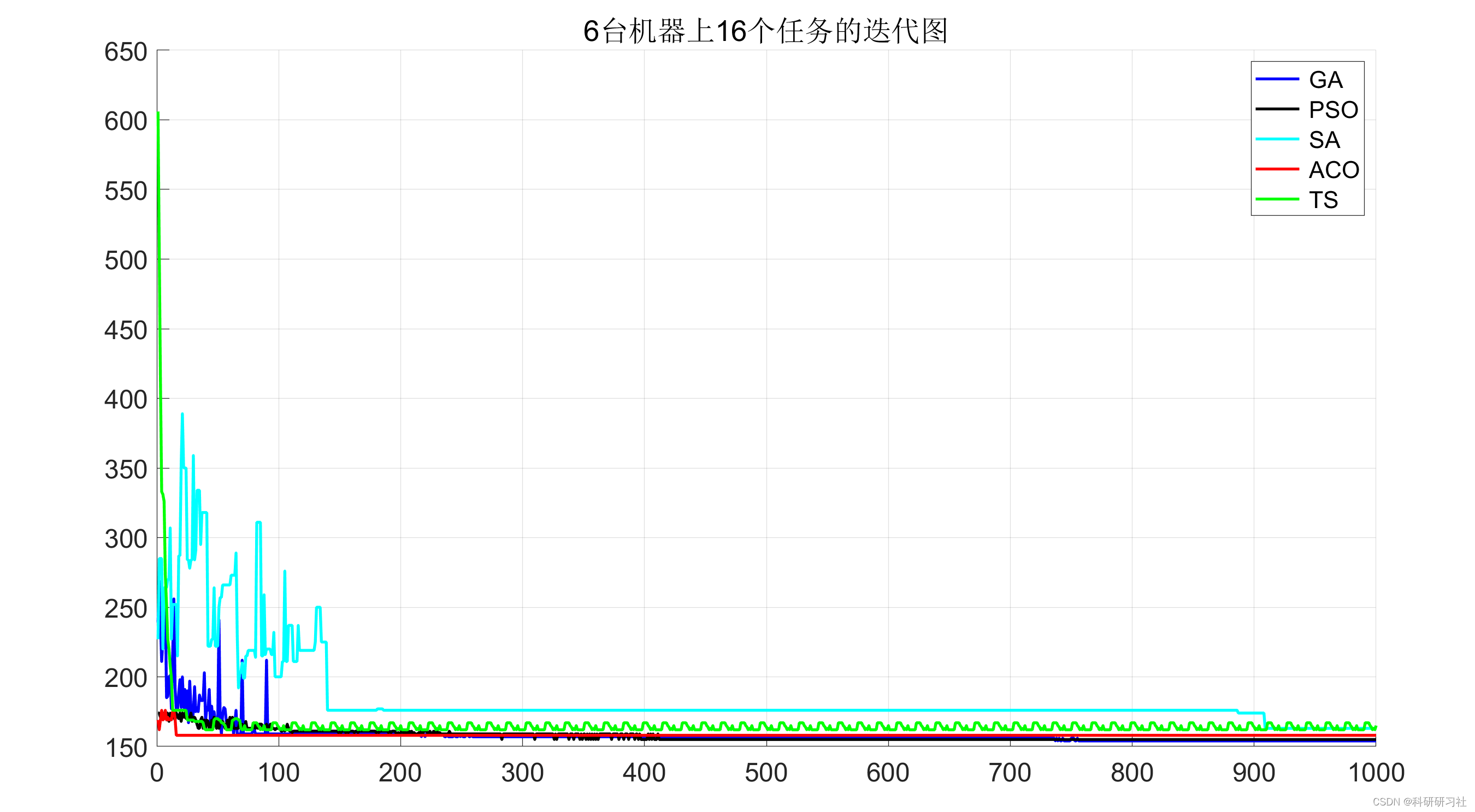
BufferManager类处理主机和设备buffer分配和释放。
这个RAII类处理主机和设备buffer的分配和释放、主机和设备buffers之间的memcpy以帮助inference,以及debugging dumps以验证inference。BufferManager类用于简化buffer管理以及buffer和 engine之间的交互。
代码位于:TensorRT\samples\common\buffers.h
协作图

Public Member
BufferManager
BufferManager构造函数作用分配主机和设备的buffer内存,创建一个BufferManager来处理和引擎的缓冲区交互。具体实现如下:
BufferManager(std::shared_ptr<nvinfer1::ICudaEngine> engine, const int batchSize = 0,
const nvinfer1::IExecutionContext* context = nullptr)
: mEngine(engine), mBatchSize(batchSize)
{
// 查询引擎是否使用implicit batch维度生成。 如果张量具有implicit batch维度,则返回True,否则返回false。engine中的所有张量要么都有implicit batch维度,要么都没有。
// 仅当生成此引擎的INetworkDefinition是使用createNetworkV2创建的,而没有NetworkDefinitionCreationFlag::kEXPLICIT_BATCH标志。hasImplicitBatchDimension返回为true
assert(engine->hasImplicitBatchDimension() || mBatchSize == 0);
// Create host and device buffers
for (int i = 0; i < mEngine->getNbBindings(); i++)
{
auto dims = context ? context->getBindingDimensions(i) : mEngine->getBindingDimensions(i);
// 1
size_t vol = context || !mBatchSize ? 1 : static_cast<size_t>(mBatchSize);
nvinfer1::DataType type = mEngine->getBindingDataType(i);
int vecDim = mEngine->getBindingVectorizedDim(i);
//
if (-1 != vecDim) // i.e., 0 != lgScalarsPerVector
{
int scalarsPerVec = mEngine->getBindingComponentsPerElement(i);
// divUp:(a + b - 1) / b;
dims.d[vecDim] = divUp(dims.d[vecDim], scalarsPerVec);
vol *= scalarsPerVec;
}
vol *= samplesCommon::volume(dims);
std::unique_ptr<ManagedBuffer> manBuf{new ManagedBuffer()};
// 分配buffer设备内存和主机内存
manBuf->deviceBuffer = DeviceBuffer(vol, type);
manBuf->hostBuffer = HostBuffer(vol, type);
mDeviceBindings.emplace_back(manBuf->deviceBuffer.data());
// std::move避免不必要的拷贝操作,将对象的状态或者所有权从一个对象转移到另一个对象,只是转移,没有内存的搬迁
mManagedBuffers.emplace_back(std::move(manBuf));
}
}
getDeviceBindings
返回设备缓冲区的向量,可以直接将其用作IExecutionContext的execute和enqueue方法的绑定。
//!
//! \brief Returns a vector of device buffers.
//!
const std::vector<void*>& getDeviceBindings() const
{
return mDeviceBindings;
}
//!
//! \brief Returns the device buffer corresponding to tensorName.
//! Returns nullptr if no such tensor can be found.
//!
void* getDeviceBuffer(const std::string& tensorName) const
{
return getBuffer(false, tensorName);
}
getDeviceBuffer
返回与tensorName对应的设备缓冲区。如果找不到此类张量,则返回nullptr。
void* getDeviceBuffer(const std::string& tensorName) const
{
return getBuffer(false, tensorName);
}
getHostBuffer
返回与tensorName对应的主机缓冲区。如果找不到此类张量,则返回nullptr。
//!
//! \brief Returns the host buffer corresponding to tensorName.
//! Returns nullptr if no such tensor can be found.
//!
void* getHostBuffer(const std::string& tensorName) const
{
return getBuffer(true, tensorName);
}
size
返回与tensorName对应的主机和设备缓冲区的大小。如果找不到此类张量,则返回kINVALID_SIZE_VALUE。
size_t size(const std::string& tensorName) const
{
int index = mEngine->getBindingIndex(tensorName.c_str());
if (index == -1)
return kINVALID_SIZE_VALUE;
return mManagedBuffers[index]->hostBuffer.nbBytes();
}
将任意类型的缓冲区转储到std::ostream的模板化打印函数。rowCount参数控制每行上的元素数。rowCount为1表示每行上只有1个元素。
template <typename T>
void print(std::ostream& os, void* buf, size_t bufSize, size_t rowCount)
{
assert(rowCount != 0);
assert(bufSize % sizeof(T) == 0);
T* typedBuf = static_cast<T*>(buf);
size_t numItems = bufSize / sizeof(T);
for (int i = 0; i < static_cast<int>(numItems); i++)
{
// Handle rowCount == 1 case
if (rowCount == 1 && i != static_cast<int>(numItems) - 1)
os << typedBuf[i] << std::endl;
else if (rowCount == 1)
os << typedBuf[i];
// Handle rowCount > 1 case
else if (i % rowCount == 0)
os << typedBuf[i];
else if (i % rowCount == rowCount - 1)
os << " " << typedBuf[i] << std::endl;
else
os << " " << typedBuf[i];
}
}
copyInputToDevice
将输入主机缓冲区的内容同步复制到输入设备缓冲区。
void copyInputToDevice()
{
memcpyBuffers(true, false, false);
}
copyOutputToHost
将输出设备缓冲区的内容同步复制到输出主机缓冲区。
void copyOutputToHost()
{
memcpyBuffers(false, true, false);
}
将输出设备缓冲区的内容同步复制到输出主机缓冲区。
copyInputToDeviceAsync
将输入主机缓冲区的内容异步复制到输入设备缓冲区。
void copyInputToDeviceAsync(const cudaStream_t& stream = 0)
{
memcpyBuffers(true, false, true, stream);
}
copyOutputToHostAsync
将输出设备缓冲区的内容异步复制到输出主机缓冲区。
void copyOutputToHostAsync(const cudaStream_t& stream = 0)
{
memcpyBuffers(false, true, true, stream);
}
~BufferManager
~BufferManager() = default;
Private Member
getBuffer
void* getBuffer(const bool isHost, const std::string& tensorName) const
{
int index = mEngine->getBindingIndex(tensorName.c_str());
if (index == -1)
return nullptr;
return (isHost ? mManagedBuffers[index]->hostBuffer.data() : mManagedBuffers[index]->deviceBuffer.data());
}
memcpyBuffers
void memcpyBuffers(const bool copyInput, const bool deviceToHost, const bool async, const cudaStream_t& stream = 0)
{
for (int i = 0; i < mEngine->getNbBindings(); i++)
{
void* dstPtr
= deviceToHost ? mManagedBuffers[i]->hostBuffer.data() : mManagedBuffers[i]->deviceBuffer.data();
const void* srcPtr
= deviceToHost ? mManagedBuffers[i]->deviceBuffer.data() : mManagedBuffers[i]->hostBuffer.data();
const size_t byteSize = mManagedBuffers[i]->hostBuffer.nbBytes();
const cudaMemcpyKind memcpyType = deviceToHost ? cudaMemcpyDeviceToHost : cudaMemcpyHostToDevice;
if ((copyInput && mEngine->bindingIsInput(i)) || (!copyInput && !mEngine->bindingIsInput(i)))
{
if (async)
CHECK(cudaMemcpyAsync(dstPtr, srcPtr, byteSize, memcpyType, stream));
else
CHECK(cudaMemcpy(dstPtr, srcPtr, byteSize, memcpyType));
}
}
}
Member Data
Static Public Attributes
static const size_t kINVALID_SIZE_VALUE = ~size_t(0)
Private Attributes
// The pointer to the engine.
std::shared_ptr<nvinfer1::ICudaEngine> samplesCommon::BufferManager::mEngine
// The batch size for legacy networks, 0 otherwise.
int samplesCommon::BufferManager::mBatchSize
// The vector of pointers to managed buffers.
std::vector<std::unique_ptr<ManagedBuffer>> samplesCommon::BufferManager::mManagedBuffers
// The vector of device buffers needed for engine execution.
std::vector<void*> samplesCommon::BufferManager::mDeviceBindings
代码
/*
* SPDX-FileCopyrightText: Copyright (c) 1993-2022 NVIDIA CORPORATION & AFFILIATES. All rights reserved.
* SPDX-License-Identifier: Apache-2.0
*
* Licensed under the Apache License, Version 2.0 (the "License");
* you may not use this file except in compliance with the License.
* You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
#ifndef TENSORRT_BUFFERS_H
#define TENSORRT_BUFFERS_H
#include "NvInfer.h"
#include "common.h"
#include "half.h"
#include <cassert>
#include <cuda_runtime_api.h>
#include <iostream>
#include <iterator>
#include <memory>
#include <new>
#include <numeric>
#include <string>
#include <vector>
namespace samplesCommon
{
//!
//! \brief The GenericBuffer class is a templated class for buffers.
//!
//! \details This templated RAII (Resource Acquisition Is Initialization) class handles the allocation,
//! deallocation, querying of buffers on both the device and the host.
//! It can handle data of arbitrary types because it stores byte buffers.
//! The template parameters AllocFunc and FreeFunc are used for the
//! allocation and deallocation of the buffer.
//! AllocFunc must be a functor that takes in (void** ptr, size_t size)
//! and returns bool. ptr is a pointer to where the allocated buffer address should be stored.
//! size is the amount of memory in bytes to allocate.
//! The boolean indicates whether or not the memory allocation was successful.
//! FreeFunc must be a functor that takes in (void* ptr) and returns void.
//! ptr is the allocated buffer address. It must work with nullptr input.
//!
template <typename AllocFunc, typename FreeFunc>
class GenericBuffer
{
public:
//!
//! \brief Construct an empty buffer.
//!
GenericBuffer(nvinfer1::DataType type = nvinfer1::DataType::kFLOAT)
: mSize(0)
, mCapacity(0)
, mType(type)
, mBuffer(nullptr)
{
}
//!
//! \brief Construct a buffer with the specified allocation size in bytes.
//!
GenericBuffer(size_t size, nvinfer1::DataType type)
: mSize(size)
, mCapacity(size)
, mType(type)
{
if (!allocFn(&mBuffer, this->nbBytes()))
{
throw std::bad_alloc();
}
}
GenericBuffer(GenericBuffer&& buf)
: mSize(buf.mSize)
, mCapacity(buf.mCapacity)
, mType(buf.mType)
, mBuffer(buf.mBuffer)
{
buf.mSize = 0;
buf.mCapacity = 0;
buf.mType = nvinfer1::DataType::kFLOAT;
buf.mBuffer = nullptr;
}
GenericBuffer& operator=(GenericBuffer&& buf)
{
if (this != &buf)
{
freeFn(mBuffer);
mSize = buf.mSize;
mCapacity = buf.mCapacity;
mType = buf.mType;
mBuffer = buf.mBuffer;
// Reset buf.
buf.mSize = 0;
buf.mCapacity = 0;
buf.mBuffer = nullptr;
}
return *this;
}
//!
//! \brief Returns pointer to underlying array.
//!
void* data()
{
return mBuffer;
}
//!
//! \brief Returns pointer to underlying array.
//!
const void* data() const
{
return mBuffer;
}
//!
//! \brief Returns the size (in number of elements) of the buffer.
//!
size_t size() const
{
return mSize;
}
//!
//! \brief Returns the size (in bytes) of the buffer.
//!
size_t nbBytes() const
{
return this->size() * samplesCommon::getElementSize(mType);
}
//!
//! \brief Resizes the buffer. This is a no-op if the new size is smaller than or equal to the current capacity.
//!
void resize(size_t newSize)
{
mSize = newSize;
if (mCapacity < newSize)
{
freeFn(mBuffer);
if (!allocFn(&mBuffer, this->nbBytes()))
{
throw std::bad_alloc{};
}
mCapacity = newSize;
}
}
//!
//! \brief Overload of resize that accepts Dims
//!
void resize(const nvinfer1::Dims& dims)
{
return this->resize(samplesCommon::volume(dims));
}
~GenericBuffer()
{
freeFn(mBuffer);
}
private:
size_t mSize{0}, mCapacity{0};
nvinfer1::DataType mType;
void* mBuffer;
AllocFunc allocFn;
FreeFunc freeFn;
};
class DeviceAllocator
{
public:
bool operator()(void** ptr, size_t size) const
{
return cudaMalloc(ptr, size) == cudaSuccess;
}
};
class DeviceFree
{
public:
void operator()(void* ptr) const
{
cudaFree(ptr);
}
};
class HostAllocator
{
public:
bool operator()(void** ptr, size_t size) const
{
*ptr = malloc(size);
return *ptr != nullptr;
}
};
class HostFree
{
public:
void operator()(void* ptr) const
{
free(ptr);
}
};
using DeviceBuffer = GenericBuffer<DeviceAllocator, DeviceFree>;
using HostBuffer = GenericBuffer<HostAllocator, HostFree>;
//!
//! \brief The ManagedBuffer class groups together a pair of corresponding device and host buffers.
//!
class ManagedBuffer
{
public:
DeviceBuffer deviceBuffer;
HostBuffer hostBuffer;
};
//!
//! \brief The BufferManager class handles host and device buffer allocation and deallocation.
//!
//! \details This RAII class handles host and device buffer allocation and deallocation,
//! memcpy between host and device buffers to aid with inference,
//! and debugging dumps to validate inference. The BufferManager class is meant to be
//! used to simplify buffer management and any interactions between buffers and the engine.
//!
class BufferManager
{
public:
static const size_t kINVALID_SIZE_VALUE = ~size_t(0);
//!
//! \brief Create a BufferManager for handling buffer interactions with engine.
//!
BufferManager(std::shared_ptr<nvinfer1::ICudaEngine> engine, const int batchSize = 0,
const nvinfer1::IExecutionContext* context = nullptr)
: mEngine(engine)
, mBatchSize(batchSize)
{
// Full Dims implies no batch size.
assert(engine->hasImplicitBatchDimension() || mBatchSize == 0);
// Create host and device buffers
for (int i = 0; i < mEngine->getNbBindings(); i++)
{
auto dims = context ? context->getBindingDimensions(i) : mEngine->getBindingDimensions(i);
size_t vol = context || !mBatchSize ? 1 : static_cast<size_t>(mBatchSize);
nvinfer1::DataType type = mEngine->getBindingDataType(i);
int vecDim = mEngine->getBindingVectorizedDim(i);
if (-1 != vecDim) // i.e., 0 != lgScalarsPerVector
{
int scalarsPerVec = mEngine->getBindingComponentsPerElement(i);
dims.d[vecDim] = divUp(dims.d[vecDim], scalarsPerVec);
vol *= scalarsPerVec;
}
vol *= samplesCommon::volume(dims);
std::unique_ptr<ManagedBuffer> manBuf{new ManagedBuffer()};
manBuf->deviceBuffer = DeviceBuffer(vol, type);
manBuf->hostBuffer = HostBuffer(vol, type);
mDeviceBindings.emplace_back(manBuf->deviceBuffer.data());
mManagedBuffers.emplace_back(std::move(manBuf));
}
}
//!
//! \brief Returns a vector of device buffers that you can use directly as
//! bindings for the execute and enqueue methods of IExecutionContext.
//!
std::vector<void*>& getDeviceBindings()
{
return mDeviceBindings;
}
//!
//! \brief Returns a vector of device buffers.
//!
const std::vector<void*>& getDeviceBindings() const
{
return mDeviceBindings;
}
//!
//! \brief Returns the device buffer corresponding to tensorName.
//! Returns nullptr if no such tensor can be found.
//!
void* getDeviceBuffer(const std::string& tensorName) const
{
return getBuffer(false, tensorName);
}
//!
//! \brief Returns the host buffer corresponding to tensorName.
//! Returns nullptr if no such tensor can be found.
//!
void* getHostBuffer(const std::string& tensorName) const
{
return getBuffer(true, tensorName);
}
//!
//! \brief Returns the size of the host and device buffers that correspond to tensorName.
//! Returns kINVALID_SIZE_VALUE if no such tensor can be found.
//!
size_t size(const std::string& tensorName) const
{
int index = mEngine->getBindingIndex(tensorName.c_str());
if (index == -1)
return kINVALID_SIZE_VALUE;
return mManagedBuffers[index]->hostBuffer.nbBytes();
}
//!
//! \brief Templated print function that dumps buffers of arbitrary type to std::ostream.
//! rowCount parameter controls how many elements are on each line.
//! A rowCount of 1 means that there is only 1 element on each line.
//!
template <typename T>
void print(std::ostream& os, void* buf, size_t bufSize, size_t rowCount)
{
assert(rowCount != 0);
assert(bufSize % sizeof(T) == 0);
T* typedBuf = static_cast<T*>(buf);
size_t numItems = bufSize / sizeof(T);
for (int i = 0; i < static_cast<int>(numItems); i++)
{
// Handle rowCount == 1 case
if (rowCount == 1 && i != static_cast<int>(numItems) - 1)
os << typedBuf[i] << std::endl;
else if (rowCount == 1)
os << typedBuf[i];
// Handle rowCount > 1 case
else if (i % rowCount == 0)
os << typedBuf[i];
else if (i % rowCount == rowCount - 1)
os << " " << typedBuf[i] << std::endl;
else
os << " " << typedBuf[i];
}
}
//!
//! \brief Copy the contents of input host buffers to input device buffers synchronously.
//!
void copyInputToDevice()
{
memcpyBuffers(true, false, false);
}
//!
//! \brief Copy the contents of output device buffers to output host buffers synchronously.
//!
void copyOutputToHost()
{
memcpyBuffers(false, true, false);
}
//!
//! \brief Copy the contents of input host buffers to input device buffers asynchronously.
//!
void copyInputToDeviceAsync(const cudaStream_t& stream = 0)
{
memcpyBuffers(true, false, true, stream);
}
//!
//! \brief Copy the contents of output device buffers to output host buffers asynchronously.
//!
void copyOutputToHostAsync(const cudaStream_t& stream = 0)
{
memcpyBuffers(false, true, true, stream);
}
~BufferManager() = default;
private:
void* getBuffer(const bool isHost, const std::string& tensorName) const
{
int index = mEngine->getBindingIndex(tensorName.c_str());
if (index == -1)
return nullptr;
return (isHost ? mManagedBuffers[index]->hostBuffer.data() : mManagedBuffers[index]->deviceBuffer.data());
}
void memcpyBuffers(const bool copyInput, const bool deviceToHost, const bool async, const cudaStream_t& stream = 0)
{
for (int i = 0; i < mEngine->getNbBindings(); i++)
{
void* dstPtr
= deviceToHost ? mManagedBuffers[i]->hostBuffer.data() : mManagedBuffers[i]->deviceBuffer.data();
const void* srcPtr
= deviceToHost ? mManagedBuffers[i]->deviceBuffer.data() : mManagedBuffers[i]->hostBuffer.data();
const size_t byteSize = mManagedBuffers[i]->hostBuffer.nbBytes();
const cudaMemcpyKind memcpyType = deviceToHost ? cudaMemcpyDeviceToHost : cudaMemcpyHostToDevice;
if ((copyInput && mEngine->bindingIsInput(i)) || (!copyInput && !mEngine->bindingIsInput(i)))
{
if (async)
CHECK(cudaMemcpyAsync(dstPtr, srcPtr, byteSize, memcpyType, stream));
else
CHECK(cudaMemcpy(dstPtr, srcPtr, byteSize, memcpyType));
}
}
}
std::shared_ptr<nvinfer1::ICudaEngine> mEngine; //!< The pointer to the engine
int mBatchSize; //!< The batch size for legacy networks, 0 otherwise.
std::vector<std::unique_ptr<ManagedBuffer>> mManagedBuffers; //!< The vector of pointers to managed buffers
std::vector<void*> mDeviceBindings; //!< The vector of device buffers needed for engine execution
};
} // namespace samplesCommon
#endif // TENSORRT_BUFFERS_H
参考:
- https://www.ccoderun.ca/programming/doxygen/tensorrt/classsamplesCommon_1_1BufferManager.html#aa64f0092469babe813db491696098eb0
- https://github.com/NVIDIA/TensorRT








![[附源码]Node.js计算机毕业设计电影网上购票系统Express](https://img-blog.csdnimg.cn/a5b1f59565f34ce98b0c956a674bba0a.png)