1. 写在前面
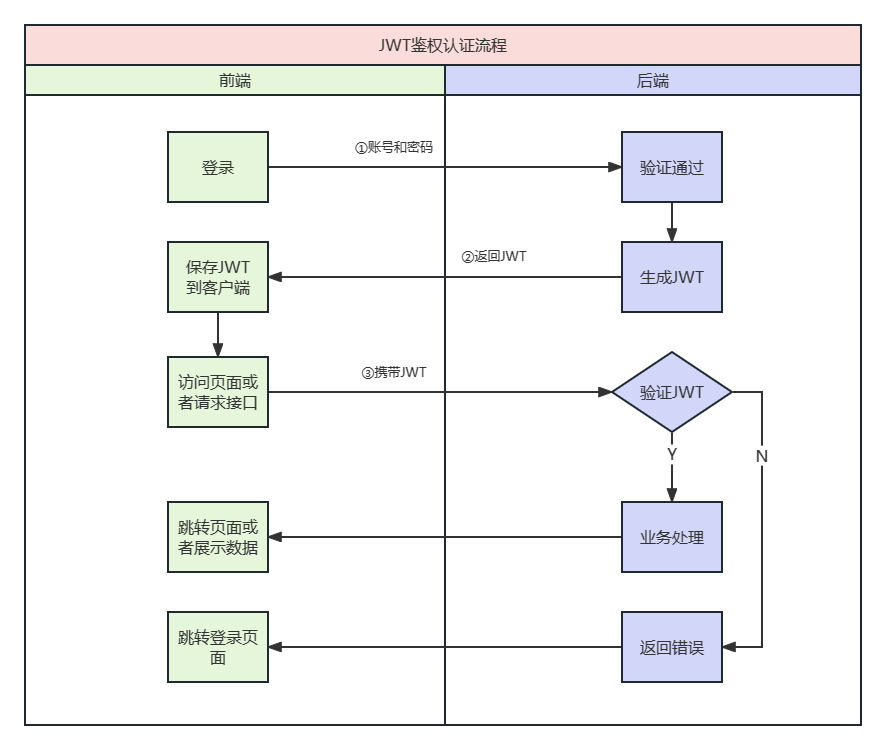
某查查网站反爬虫风控还是较强的,之后会分别介绍一下PC端协议、APP端自动化、APP端接口协议三种采集方案。这里主要介绍APP端的自动化方式,APP端自动化方式需要登陆账号,协议的话需要签名授权(自动化经测试没有太多限制、走协议接口的话账号与次数有捆绑)
接口出来结构化数据、自动化就得手搓解析
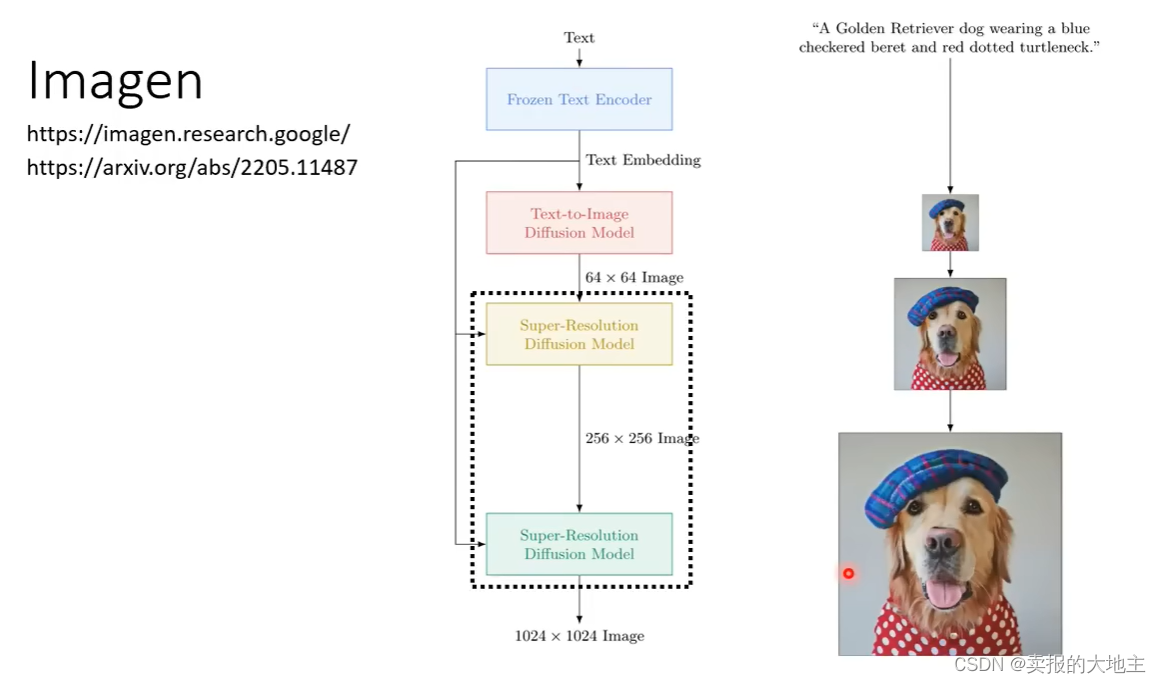
APP接口效果图
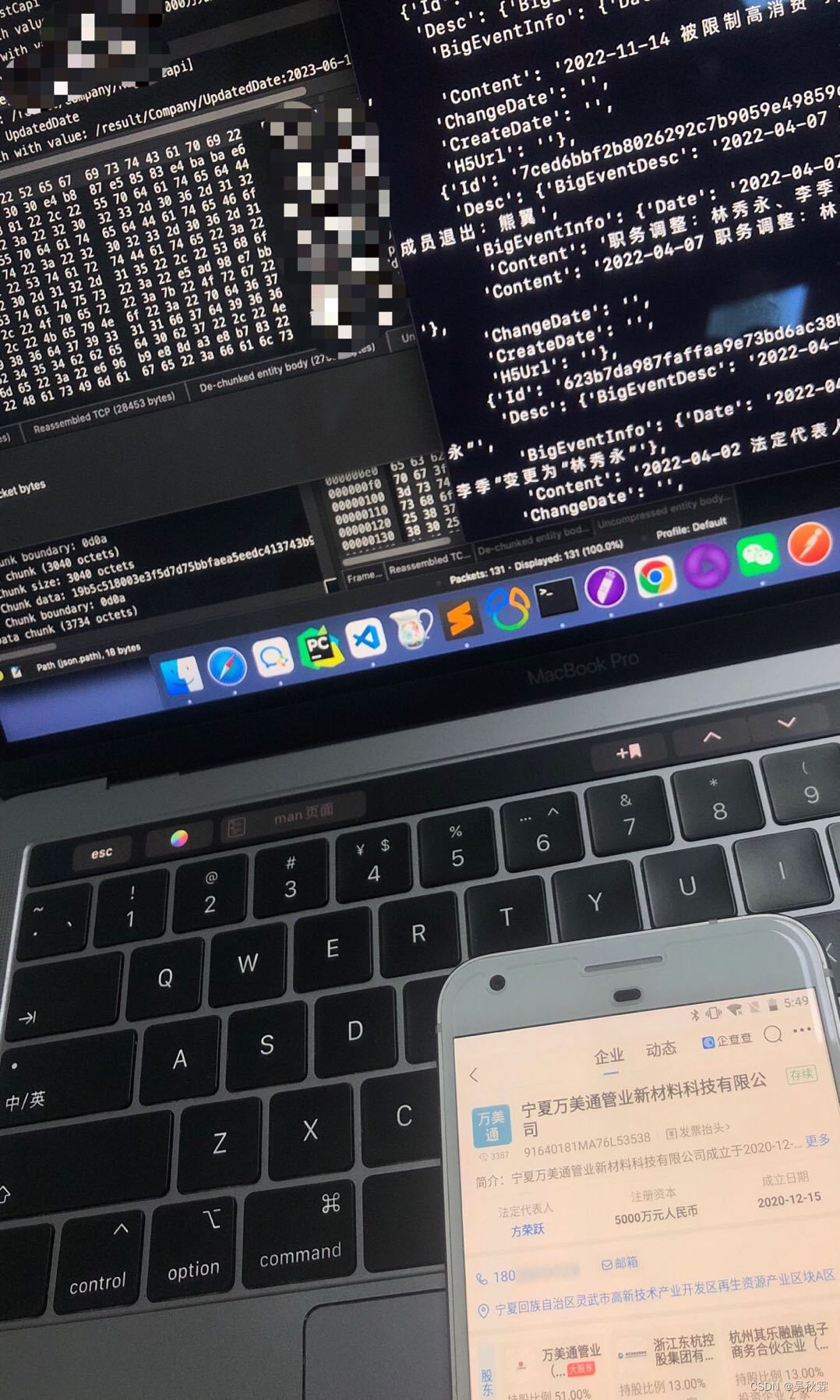
几种方式都测试过,自动化的方案优势就是比较稳定,对IP及账号的资源依赖相对不太高!缺点就是慢,懂得都懂!不过这个弊端是可以弥补的,做成自动化集群不管是模拟器还是真机均可拉升效率提高产能
APP自动化效果图
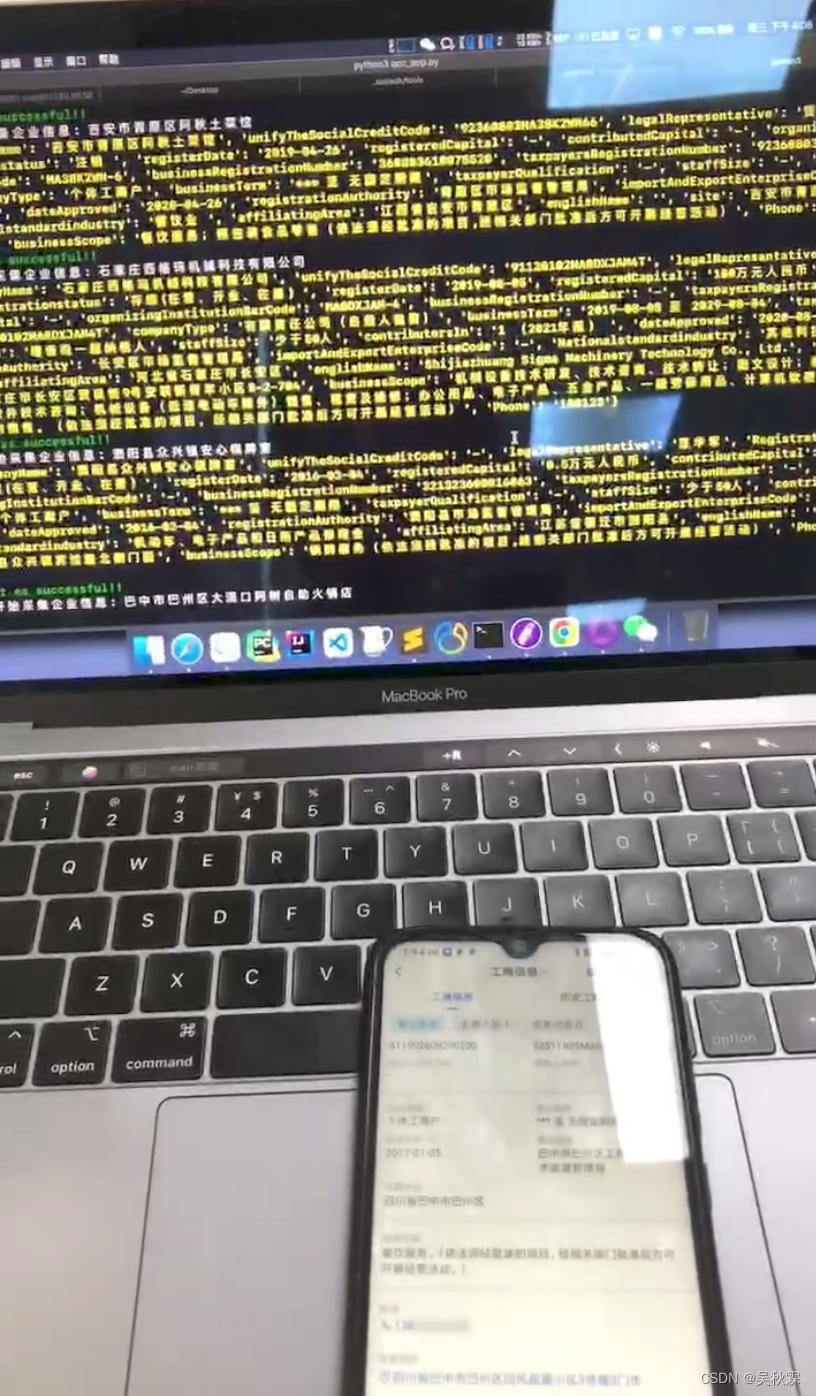
用自动化的话前期的琐事比较多,而且自动化要想完全稳定的投入长期持续的生产过程当中也是比较艰辛的,适配各种可能出现的状况
自动化分析页面元素是首要工作,可以在Appium中进行元素分析查看,但是并不支持,个人感觉体验感较差,呈现的信息不够完整

这里推荐大家使用Android SDK下面自带的tools工具:

看起来都比较丝滑一些

首先我们需要打开Appium的客户服务,以下URL是服务地址。通过它与移动设备进行通信和控制,另外需要进行自动化测试的Android设备的信息配置:
url = "http://127.0.0.1:4723/wd/hub"
deviceList = [
{
"platformName": "Android" #操作系统类型,
"platformVersion": "9" #Android版本号,
# "deviceName": "1304dccd",
"udid": "172.16.18.167:5555", #这里用IP的方式可以不接USB,直接通过网络连接设备进行测试
"appPackage": "com.android.icredit", #应用程序的包名
"appActivity": ".ui.SplashActivity", #应用程序的入口
"newCommandTimeout": "1800",
"noReset": True, #Appium不重置应用程序状态
'unicodeKeyboard': True,
'resetKeyboard': True
}
]
for device in self.deviceList:
driver = Remote(
command_executor=self.url,
desired_capabilities=device)
自动化的程序还是比较简单的,解析的话用id取值就可以
# 数据解析规则
def parameter(self, **kwargs):
return kwargs
def parse_rule(self):
rule = self.parameter(
companyName="com.android.icredit:id/ai8",
unifyTheSocialCreditCode="com.android.icredit:id/aid",
legalRepresentative="com.android.icredit:id/h6",
Registrationstatus="com.android.icredit:id/ajb",
registerDate="com.android.icredit:id/aje",
registeredCapital="com.android.icredit:id/ajh",
contributedCapital="com.android.icredit:id/ajk",
organizingInstitutionBarCode="com.android.icredit:id/aig",
businessRegistrationNumber="com.android.icredit:id/aij",
taxpayersRegistrationNumber="com.android.icredit:id/aim",
companyType="com.android.icredit:id/ait",
businessTerm="com.android.icredit:id/aiu",
taxpayerQualification="com.android.icredit:id/ais",
staffSize="com.android.icredit:id/ajo",
contributorsIn="com.android.icredit:id/ajn",
dateApproved="com.android.icredit:id/aix",
registrationAuthority="com.android.icredit:id/aiy",
importAndExportEnterpriseCode="com.android.icredit:id/aip",
Nationalstandardindustry="com.android.icredit:id/ajr"
)
return rule
def parse_rule_slither(self):
rule = self.parameter(
affiliatingArea="com.android.icredit:id/aiz",
englishName="com.android.icredit:id/aj3",
site="com.android.icredit:id/ya",
businessScope="com.android.icredit:id/ajv",
Phone="com.android.icredit:id/ajz"
)
return rule
然后就是搜索的部分,这里涉及点击下拉的一些操作。有更多提升优化的操作空间
search_element = 'com.android.icredit:id/azd'
self._random_sleep(driver, search_element)
driver.find_element(By.ID, search_element).click()
# 清理搜索记录跟历史浏览记录
if self.search_count >= 15:
for element_id in [
"com.android.icredit:id/at8",
"com.android.icredit:id/awm",
"com.android.icredit:id/a7c",
"com.android.icredit:id/awf",
"com.android.icredit:id/awj",
"com.android.icredit:id/a7c",
]:
driver.find_element(By.ID, element_id).click()
time.sleep(1)
self.search_count = 0
search_box = driver.find_element(By.XPATH, '//*[@resource-id="com.android.icredit:id/lt"]')
search_box.send_keys(keyword)
self.search_count += 1
driver.press_keycode(66)
index = 1
while True:
if index >= 3:
driver.back()
return
click_company = driver.find_element(By.XPATH, f'//*[@resource-id="com.android.icredit:id/vs"][{index}]')
obj = click_company.get_attribute('text')
if obj == keyword:
break
index += 1
click_company.click()
while True:
driver.swipe(423, 600, 446, 200, 200)
checker_ele = driver.find_elements(By.XPATH, '//*[@content-desc="工商信息" or @content-desc="登记信息" or @content-desc="基本信息"]')
if checker_ele:
break
time.sleep(1)
if checker_ele[0].get_attribute('text') == '登记信息':
print(self.RED % '当前企业无符合数据, 跳过!')
driver.find_element(By.ID, 'com.android.icredit:id/j3').click()
return
checker_ele[0].click()
time.sleep(1)
data = {}
for key, rule in self.parse_rule().items():
checker = driver.find_elements(By.ID, rule)
data[key] = checker[0].get_attribute('text') if checker else ''
for _ in range(2):
driver.swipe(423, 820, 446, 245, 200)
for k, v in self.parse_rule_slither().items():
if not data.get(k):
checker = driver.find_elements(By.ID, v)
data[k] = checker[0].get_attribute('text') if checker else ''
for k in self.parse_rule_slither().keys():
data.setdefault(k, '')
phone = data.get('Phone', '')
if phone and phone.startswith('1') and len(phone) != 11:
data['Phone'] = phone + '*' * (11 - len(phone))
好了,到这里又到了跟大家说再见的时候了。创作不易,帮忙点个赞再走吧。你的支持是我创作的动力,希望能带给大家更多优质的文章