目录
秃顶面试官:简单介绍下什么是Redis Cluster呢?
秃顶面试官:那集群的缺点有哪些呢?
秃顶面试官:说说如何搭建集群呢?
秃顶面试官:集群内部是如何通信的呢?
秃顶面试官:线上如何对集群进行扩容和缩容呢?
秃顶面试官:不错不错,再来说下集群的故障转移吧
秃顶面试官:说的非常详细,来集群的完整性如何保证呢?
秃顶面试官:那集群中的数据倾斜有了解吗?
面试官:说说Redis的持久化以及主从同步呗_cj_eryue的博客-CSDN博客
面试官:说说Redis的哨兵模式呗_cj_eryue的博客-CSDN博客
秃顶面试官:前面我们聊了主从和哨兵,那今天来聊一聊集群吧
花花:好的
秃顶面试官:简单介绍下什么是Redis Cluster呢?
花花:Redis Cluster是Redis的分布式解决方案,在3.0版本正式推出,有效地解决了Redis分布式方面的需求。当遇到单机内存、并发、流量等瓶颈时,可以采用Cluster架构方案达到负载均衡的目的。
分布式数据库首先要解决把整个数据集按照分区规则映射到多个节点的问题,即把数据集划分到多个节点上,每个节点负责整体数据的一个子集。
Redis Cluser采用虚拟槽分区,所有的键根据哈希函数映射到0~16383整数槽内,计算公式:slot=CRC16(key)&16383。每一个节点负责维护一部分槽以及槽所映射的键值数据,如图所示

Redis虚拟槽分区的特点:
- 解耦数据和节点之间的关系,简化了节点扩容和收缩难度。
- 节点自身维护槽的映射关系,不需要客户端或者代理服务维护槽分区元数据。
- 支持节点、槽、键之间的映射查询,用于数据路由、在线伸缩等场景。
秃顶面试官:那集群的缺点有哪些呢?
花花:
Redis集群相对单机在功能上存在一些限制,限制如下:
1)key批量操作支持有限。如mset、mget,目前只支持具有相同slot值的key执行批量操作。对于映射为不同slot值的key由于执行mget、mget等操作可能存在于多个节点上因此不被支持。
2)key事务操作支持有限。同理只支持多key在同一节点上的事务操作,当多个key分布在不同的节点上时无法使用事务功能。
3)key作为数据分区的最小粒度,因此不能将一个大的键值对象如hash、list等映射到不同的节点。
4)不支持多数据库空间。单机下的Redis可以支持16个数据库,集群模式下只能使用一个数据库空间,即db0。
5)复制结构只支持一层,从节点只能复制主节点,不支持嵌套树状复制结构。
秃顶面试官:说说如何搭建集群呢?
花花:搭建集群也是非常的简单,下面以搭建三主三从来说下步骤:
①拷贝一份redis.conf,重命名为redis-7001.conf,具体修改的配置如下:
bind 192.168.84.1
port 7005
dir /home/cluster/redis6/conf/data
logfile "log-7005.log"
pidfile redis_7005.pid
cluster-enabled yes
cluster-config-file nodes-7005.conf
dbfilename dump-7005.rdb复制五份,依次修改端口值和其他带有端口的值的属性为7002...7006
②依次执行 ./redis-cli redis-7001.conf启动6个实例
③连接任一实例,发现此时的集群状态为不可用状态:
[root@localhost bin]# ./redis-cli -h 192.168.84.1 -p 7001
192.168.84.1:7001> cluster info
cluster_state:fail
cluster_slots_assigned:0
cluster_slots_ok:0
cluster_slots_pfail:0
cluster_slots_fail:0
cluster_known_nodes:1
cluster_size:0
cluster_current_epoch:0
cluster_my_epoch:0
cluster_stats_messages_sent:0
cluster_stats_messages_received:0
从输出内容可以看到,被分配的槽(cluster_slots_assigned)是0,由于目前所有的槽没有分配到节点,因此集群无法完成槽到节点的映射。只有当16384个槽全部分配给节点后,集群才进入在线状态。
④通过执行如下命令来分配槽:
[root@localhost bin]# ./redis-cli --cluster create --cluster-replicas 1 192.168.84.1:7001 192.168.84.1:7002 192.168.84.1:7003 192.168.84.1:7004 192.168.84.1:7005 192.168.84.1:7006
>>> Performing hash slots allocation on 6 nodes...
Master[0] -> Slots 0 - 5460
Master[1] -> Slots 5461 - 10922
Master[2] -> Slots 10923 - 16383
Adding replica 192.168.84.1:7005 to 192.168.84.1:7001
Adding replica 192.168.84.1:7006 to 192.168.84.1:7002
Adding replica 192.168.84.1:7004 to 192.168.84.1:7003
>>> Trying to optimize slaves allocation for anti-affinity
[WARNING] Some slaves are in the same host as their master
M: 30c69d9e408015082c1a2145875cd1ec0c7a41ea 192.168.84.1:7001
slots:[0-5460] (5461 slots) master
M: 10a4381d9869e293cad95bf75482f506de9f43fe 192.168.84.1:7002
slots:[5461-10922] (5462 slots) master
M: 222df2165b7b9dba291cfa572d472ad292637873 192.168.84.1:7003
slots:[10923-16383] (5461 slots) master
S: f6df82f6c67fbe83049d6f95a8473221afee2ee6 192.168.84.1:7004
replicates 30c69d9e408015082c1a2145875cd1ec0c7a41ea
S: 4cdc4c8127dc5ea8d15a239fa6c2f3c09b0d5f3a 192.168.84.1:7005
replicates 10a4381d9869e293cad95bf75482f506de9f43fe
S: 8ae862c1815ff89e49d6c8801ea0cb074e82855c 192.168.84.1:7006
replicates 222df2165b7b9dba291cfa572d472ad292637873
# 这里询问是否接受上述配置,输入yes后回车即可
Can I set the above configuration? (type 'yes' to accept): yes
>>> Nodes configuration updated
>>> Assign a different config epoch to each node
>>> Sending CLUSTER MEET messages to join the cluster
Waiting for the cluster to join
.
>>> Performing Cluster Check (using node 192.168.84.1:7001)
M: 30c69d9e408015082c1a2145875cd1ec0c7a41ea 192.168.84.1:7001
slots:[0-5460] (5461 slots) master
1 additional replica(s)
M: 10a4381d9869e293cad95bf75482f506de9f43fe 192.168.84.1:7002
slots:[5461-10922] (5462 slots) master
1 additional replica(s)
S: 4cdc4c8127dc5ea8d15a239fa6c2f3c09b0d5f3a 192.168.84.1:7005
slots: (0 slots) slave
replicates 10a4381d9869e293cad95bf75482f506de9f43fe
S: f6df82f6c67fbe83049d6f95a8473221afee2ee6 192.168.84.1:7004
slots: (0 slots) slave
replicates 30c69d9e408015082c1a2145875cd1ec0c7a41ea
S: 8ae862c1815ff89e49d6c8801ea0cb074e82855c 192.168.84.1:7006
slots: (0 slots) slave
replicates 222df2165b7b9dba291cfa572d472ad292637873
M: 222df2165b7b9dba291cfa572d472ad292637873 192.168.84.1:7003
slots:[10923-16383] (5461 slots) master
1 additional replica(s)
[OK] All nodes agree about slots configuration.
>>> Check for open slots...
>>> Check slots coverage...
[OK] All 16384 slots covered.
执行结束后,再次查看集群状态:
[root@localhost bin]# ./redis-cli -h 192.168.84.1 -p 7001
192.168.84.1:7001> cluster info
cluster_state:ok
cluster_slots_assigned:16384
cluster_slots_ok:16384
cluster_slots_pfail:0
cluster_slots_fail:0
cluster_known_nodes:6
cluster_size:3
cluster_current_epoch:6
cluster_my_epoch:1
cluster_stats_messages_ping_sent:15
cluster_stats_messages_pong_sent:24
cluster_stats_messages_sent:39
cluster_stats_messages_ping_received:19
cluster_stats_messages_pong_received:15
cluster_stats_messages_meet_received:5
cluster_stats_messages_received:39
192.168.84.1:7001> cluster nodes
10a4381d9869e293cad95bf75482f506de9f43fe 192.168.84.1:7002@17002 master - 0 1689577175000 2 connected 5461-10922
4cdc4c8127dc5ea8d15a239fa6c2f3c09b0d5f3a 192.168.84.1:7005@17005 slave 10a4381d9869e293cad95bf75482f506de9f43fe 0 1689577176128 2 connected
f6df82f6c67fbe83049d6f95a8473221afee2ee6 192.168.84.1:7004@17004 slave 30c69d9e408015082c1a2145875cd1ec0c7a41ea 0 1689577175118 1 connected
8ae862c1815ff89e49d6c8801ea0cb074e82855c 192.168.84.1:7006@17006 slave 222df2165b7b9dba291cfa572d472ad292637873 0 1689577174064 3 connected
222df2165b7b9dba291cfa572d472ad292637873 192.168.84.1:7003@17003 master - 0 1689577173054 3 connected 10923-16383
30c69d9e408015082c1a2145875cd1ec0c7a41ea 192.168.84.1:7001@17001 myself,master - 0 1689577174000 1 connected 0-5460
表示集群已经搭建完毕
秃顶面试官:集群内部是如何通信的呢?
花花:简单的来说下
Redis集群采用Gossip(流言)协议,Gossip协议工作原理就是节点彼此不断通信交换信息,一段时间后所有的节点都会知道集群完整的信息,这种方式类似流言传播:
1)集群中的每个节点都会单独开辟一个TCP通道,用于节点之间彼此通信,通信端口号在基础端口上加10000。
2)每个节点在固定周期内通过特定规则选择几个节点发送ping消息。
3)接收到ping消息的节点用pong消息作为响应。集群中每个节点通过一定规则挑选要通信的节点,每个节点可能知道全部节点,也可能仅知道部分节点,只要这些节点彼此可以正常通信,最终它们会达到一致的状态。当节点出故障、新节点加入、主从角色变化、槽信息变更等事件发生时,通过不断的ping/pong消息通信,经过一段时间后所有的节点都会知道整个集群全部节点的最新状态,从而达到集群状态同步的目的。
秃顶面试官:线上如何对集群进行扩容和缩容呢?
花花:这个其实很简单,先来说下扩容:
redis-cli脚本给我们提供了扩容的命令

扩容即对现有的集群新加入一个节点,我们记为newIns(192.168.84.1:7007),首先启动newIns,通过redis-cli -h -p 连接上现有集群任意节点,执行 cluster meet 192.168.84.1:7007命令,让newIns加入集群,此时,newIns没有分配任何槽位,我们可通过 redis-cli --cluster reshard 或者rebalance命令来给newIns迁移槽即可。
从节点的添加也有类似的命令:cluster replicate {masterNodeId}命令为主节点添加对应从节点

再来说下缩容:
流程说明:
1)首先需要确定下线节点是否有负责的槽,如果是,需要把槽迁移到其他节点,保证节点下线后整个集群槽节点映射的完整性。可使用reshard将该节点拥有的槽位迁移到其他节点上
2)当下线节点不再负责槽或者本身是从节点时,就可以通知集群内其他节点忘记下线节点,当所有的节点忘记该节点后可以正常关闭。可使用cluster forget {downNodeId},但是线上不建议这么用,建议使用 redis-cli --cluster del-node {host:port} {downNodeId}命令
秃顶面试官:不错不错,再来说下集群的故障转移吧
花花:可以可以,这个及有点复杂了,容我慢慢道来
①发现故障:
Redis集群内节点通过ping/pong消息实现节点通信,消息不但可以传播节点槽信息,还可以传播其他状态如:主从状态、节点故障等。因此故障发现也是通过消息传播机制实现的,主要环节包括:主观下线(pfail)和客观下线(fail)。
·主观下线:指某个节点认为另一个节点不可用,即下线状态,这个状态并不是最终的故障判定,只能代表一个节点的意见,可能存在误判情况。
·客观下线:指标记一个节点真正的下线,集群内多个节点都认为该节点不可用,从而达成共识的结果。如果是持有槽的主节点故障,需要为该节点进行故障转移。
②故障恢复
故障节点变为客观下线后,如果下线节点是持有槽的主节点则需要在它的从节点中选出一个替换它,从而保证集群的高可用。下线主节点的所有从节点承担故障恢复的义务,当从节点通过内部定时任务发现自身复制的主节点进入客观下线时,将会触发故障恢复流程
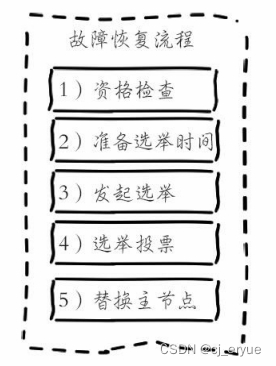
1)资格检查
每个从节点都要检查最后与主节点断线时间,判断是否有资格替换故障的主节点。如果从节点与主节点断线时间超过cluster-node-timeout*cluster-replica-validity-factor,则当前从节点不具备故障转移资格。参数cluster-replica-validity-factor用于从节点的有效因子,默认为10。
2)准备选举时间
当从节点符合故障转移资格后,更新触发故障选举的时间,只有到达该时间后才能执行后续流程。这里之所以采用延迟触发机制,主要是通过对多个从节点使用不同的延迟选举时间来支持优先级问题。复制偏移量越大说明从节点延迟越低,那么它应该具有更高的优先级来替换故障主节点。
3)发起选举
当从节点定时任务检测到达故障选举时间后,发起选举流程如下:
-》更新配置纪元
配置纪元是一个只增不减的整数,每个主节点自身维护一个配置纪元标示当前主节点的版本,所有主节点的配置纪元都不相等,从节点会复制主节点的配置纪元。整个集群又维护一个全局的配
置纪元,用于记录集群内所有主节点配置纪元的最大版本。执行cluster info命令可以查看配置纪元信息:
192.168.84.1:7001> cluster info
...
cluster_current_epoch:6 // 整个集群最大配置纪元
cluster_my_epoch:1 // 当前主节点配置纪元
配置纪元会跟随ping/pong消息在集群内传播,当发送方与接收方都是主节点且配置纪元相等时代表出现了冲突,nodeId更大的一方会递增全局配置纪元并赋值给当前节点来区分冲突.
配置纪元的主要作用:
- 标示集群内每个主节点的不同版本和当前集群最大的版本。
- 每次集群发生重要事件时,这里的重要事件指出现新的主节点(新加入的或者由从节点转换而来),从节点竞争选举。都会递增集群全局的配置纪元并赋值给相关主节点,用于记录这一关键事件。
- 主节点具有更大的配置纪元代表了更新的集群状态,因此当节点间进行ping/pong消息交换时,如出现slots等关键信息不一致时,以配置纪元更大的一方为准,防止过时的消息状态污染集群。
配置纪元的应用场景有:
- 新节点加入。
- 槽节点映射冲突检测。
- 从节点投票选举冲突检测。
4)选举投票
只有持有槽的主节点才会处理故障选举消息(FAILOVER_AUTH_REQUEST),因为每个持有槽的节点在一个配置纪元内都有唯一的一张选票,当接到第一个请求投票的从节点消息时回复
FAILOVER_AUTH_ACK消息作为投票,之后相同配置纪元内其他从节点的选举消息将忽略。
投票过程其实是一个领导者选举的过程,如集群内有N个持有槽的主节点代表有N张选票。由于在每个配置纪元内持有槽的主节点只能投票给一个从节点,因此只能有一个从节点获得N/2+1的选票,保证能够找出唯一的从节点。
Redis集群没有直接使用从节点进行领导者选举,主要因为从节点数必须大于等于3个才能保证凑够N/2+1个节点,将导致从节点资源浪费。使用集群内所有持有槽的主节点进行领导者选举,即使只有一个从节点也可以完成选举过程。
当从节点收集到N/2+1个持有槽的主节点投票时,从节点可以执行替换主节点操作,例如集群内有5个持有槽的主节点,主节点b故障后还有4个,
当其中一个从节点收集到3张投票时代表获得了足够的选票可以进行替换主节点操作。
PS:故障主节点也算在投票数内,假设集群内节点规模是3主3从,其中有2个主节点部署在一台机器上,当这台机器宕机时,由于从节点无法收集到3/2+1个主节点选票将导致故障转移失败。这个问题也适用于故障发现环节。因此部署集群时所有主节点最少需要部署在3台物理机上才能避免单点问题。
投票作废:每个配置纪元代表了一次选举周期,如果在开始投票之后的cluster-node-timeout*2时间内从节点没有获取足够数量的投票,则本次选举作废。从节点对配置纪元自增并发起下一轮投票,直到选举成功为止。
5)替换主节点
当从节点收集到足够的选票之后,触发替换主节点操作:
5.1)当前从节点取消复制变为主节点。
5.2)执行cluster delSlot操作撤销故障主节点负责的槽,并执行cluster addSlot把这些槽委派给自己。
5.3)向集群广播自己的pong消息,通知集群内所有的节点当前从节点变为主节点并接管了故障主节点的槽信息。
秃顶面试官:说的非常详细,来集群的完整性如何保证呢?
花花:为了保证集群完整性,默认情况下当集群16384个槽任何一个没有指派到节点时整个集群不可用。执行任何键命令返回(error)CLUSTERDOWN Hash slot not served错误。这是对集群完整性的一种保护措施,保证所有的槽都指派给在线的节点。但是当持有槽的主节点下线时,从故障发现到自动完成转移期间整个集群是不可用状态,对于大多数业务无法容忍这种情况,因此建议将参数cluster-require-full-coverage配置为no,当主节点故障时只影响它负责槽的相关命令执行,不会影响其他主节点的可用性。
秃顶面试官:那集群中的数据倾斜有了解吗?
花花:必须的啊
集群倾斜指不同节点之间数据量和请求量出现明显差异,这种情况将加大负载均衡和开发运维的难度。因此需要理解哪些原因会造成集群倾斜,从而避免这一问题。
1.数据倾斜
数据倾斜主要分为以下几种:
- 节点和槽分配严重不均。
- 不同槽对应键数量差异过大。
- 集合对象包含大量元素。
- 内存相关配置不一致。
1)节点和槽分配严重不均。针对每个节点分配的槽不均的情况,可以使用redis-cli --cluster info {hos:ip}进行定位,命令如下:
[root@localhost bin]# ./redis-cli --cluster info 192.168.84.1:7001
192.168.84.1:7001 (30c69d9e...) -> 2 keys | 5461 slots | 1 slaves.
192.168.84.1:7002 (10a4381d...) -> 0 keys | 5462 slots | 1 slaves.
192.168.84.1:7003 (222df216...) -> 0 keys | 5461 slots | 1 slaves.
[OK] 2 keys in 3 masters.
0.00 keys per slot on average.以上信息列举出每个节点负责的槽和键总量以及每个槽平均键数量。当节点对应槽数量不均匀时,可以使用redis-cli --cluster rebalance {hos:ip}命令进行平衡.
2)不同槽对应键数量差异过大。
键通过CRC16哈希函数映射到槽上,正常情况下槽内键数量会相对均匀。但当大量使用hash_tag时,会产生不同的键映射到同一个槽的情况。特别是选择作为hash_tag的数据离散度较差时,将加速槽内键数量倾斜情况。通过命令:cluster countkeysinslot {slot}可以获取槽对应的键数量,识别出哪些槽映射了过多的键。再通过命令cluster getkeysinslot {slot} {count}循环迭代出槽下所有的键。从而发现过度使用hash_tag的键。
3)集合对象包含大量元素。
对于大集合对象的识别可以使用redis-cli --bigkeys命令识别。找出大集合之后可以根据业务场景进
行拆分。同时集群槽数据迁移是对键执行migrate操作完成,过大的键集合如几百兆,容易造成migrate命令超时导致数据迁移失败。
root@localhost bin]# ./redis-cli -h 192.168.84.1 -p 7001 --bigkeys
# Scanning the entire keyspace to find biggest keys as well as
# average sizes per key type. You can use -i 0.1 to sleep 0.1 sec
# per 100 SCAN commands (not usually needed).
[00.00%] Biggest string found so far '"{age}:test2"' with 2 bytes
-------- summary -------
Sampled 2 keys in the keyspace!
Total key length in bytes is 22 (avg len 11.00)
Biggest string found '"{age}:test2"' has 2 bytes
0 lists with 0 items (00.00% of keys, avg size 0.00)
0 hashs with 0 fields (00.00% of keys, avg size 0.00)
2 strings with 4 bytes (100.00% of keys, avg size 2.00)
0 streams with 0 entries (00.00% of keys, avg size 0.00)
0 sets with 0 members (00.00% of keys, avg size 0.00)
0 zsets with 0 members (00.00% of keys, avg size 0.00)
4)内存相关配置不一致。
内存相关配置指hash-max-ziplist-value、set-max-intset-entries等压缩数据结构配置。当集群大量使用hash、set等数据结构时,如果内存压缩数据结构配置不一致,极端情况下会相差数倍的内存,从而造成节点内存量倾斜。
秃顶面试官:小伙子真不错,那今天就到这里,下次我们再聊
花花:好的面试官~