CMU 15-445 -- Introduction to Distributed Databases - 19
- 引言
- System Architecture
- Shared Memory
- Shared Disk
- Shared Nothing
- Early Distributed Database Systems
- Design Issues
- Homogeneous VS. Heterogeneous
- Database Partitioning
- Naive Table Partitioning
- Horizontal Partitioning
- Transaction Coordination
- Centralized Coordinator
- TP Monitor
- Middleware
- Decentralized Coordinator
- Distributed Concurrency Control
- Conclusion
引言
本系列为 CMU 15-445 Fall 2022 Database Systems 数据库系统 [卡内基梅隆] 课程重点知识点摘录。
当我们在谈论分布式数据库时,首先要明确什么是分布式系统:如果通信成本和通信的可靠性问题不可忽略,就是分布式系统。这也是区分 Parallel DBMS 和 Distributed DBMS 的依据所在
| Parallel DBMSs | Distributed DBMSs |
|---|---|
| 不同节点在物理上隔得很近 | 不同节点在物理上可能隔得很远 |
| 不同节点通过高速局域网连接 | 不同节点通过普通公共网络相连接 |
| 通信成本很小,基本不会产生问题 | 通信成本和通信问题不可忽略 |
那么如何利用我们在这节课中介绍的单节点 DBMS 的知识,构建支持事务的 Distributed DBMS 呢?之前讨论过的很多话题:
- Optimization & Planning
- Concurrency Control
- Logging & Recovery
在分布式环境下都可能遇到新的挑战。
System Architecture
Distributed DBMS 的系统架构主要指的是在哪一层上共享资源,主要分为以下 4 种:
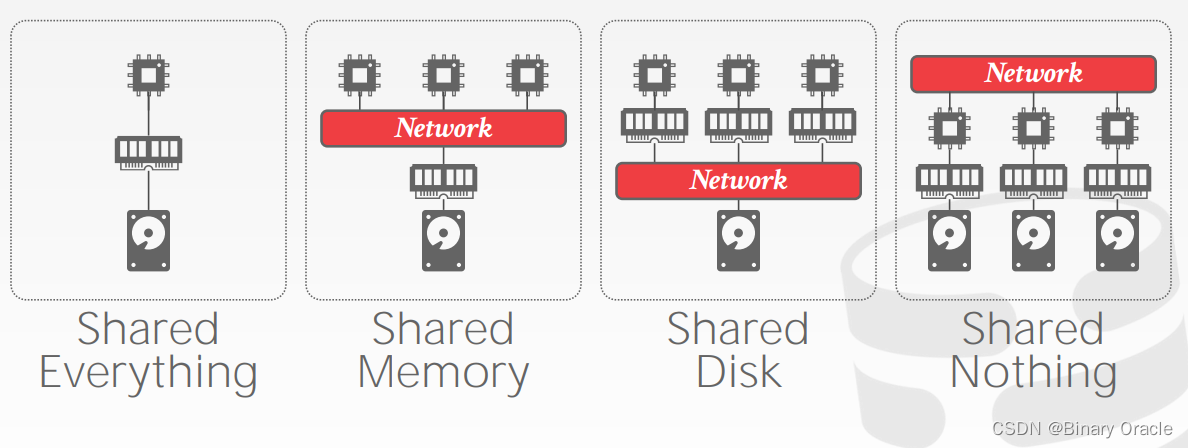
实际上 Shared Everything 就没有分布式可言了,因此严格来说,只有 Shared Memory、Shared Disk 和 Shared Nothing 三种。
Shared Memory
在 Shared Memory 架构下,不同的 CPU 通过网络访问同一块内存空间,每个 CPU 中都能看到所有内存数据结构,每个 DBMS 实例都知道其它实例的所有情况。这种架构实际上只出现在一些大型机上,在云原生环境下几乎见不到。
Shared Disk
在 Shared Disk 架构下,不同的 CPU 通过网络访问同一块逻辑磁盘,但各自都有自己的内存空间。这种架构的好处就是计算和存储可以独立扩容,坏处就是 CPU 之间需要通过更多的通信来传递数据和元信息。采用这种架构的数据库有很多,罗列如下图所示:

主要以云厂商为主,因为它们已经搭建好了稳定、成熟、可伸缩的存储服务,基于此构建 Shared Disk 架构的 Distributed DBMS 符合整体生态和分层设计理念。但 Shared Disk 的坏处在于 DBMS 对存储层没有控制权,无法决定数据的分布,因此在查询数据时无法达到最优的性能。
一个 Shared Disk 的 Distributed DBMS 举例如下:
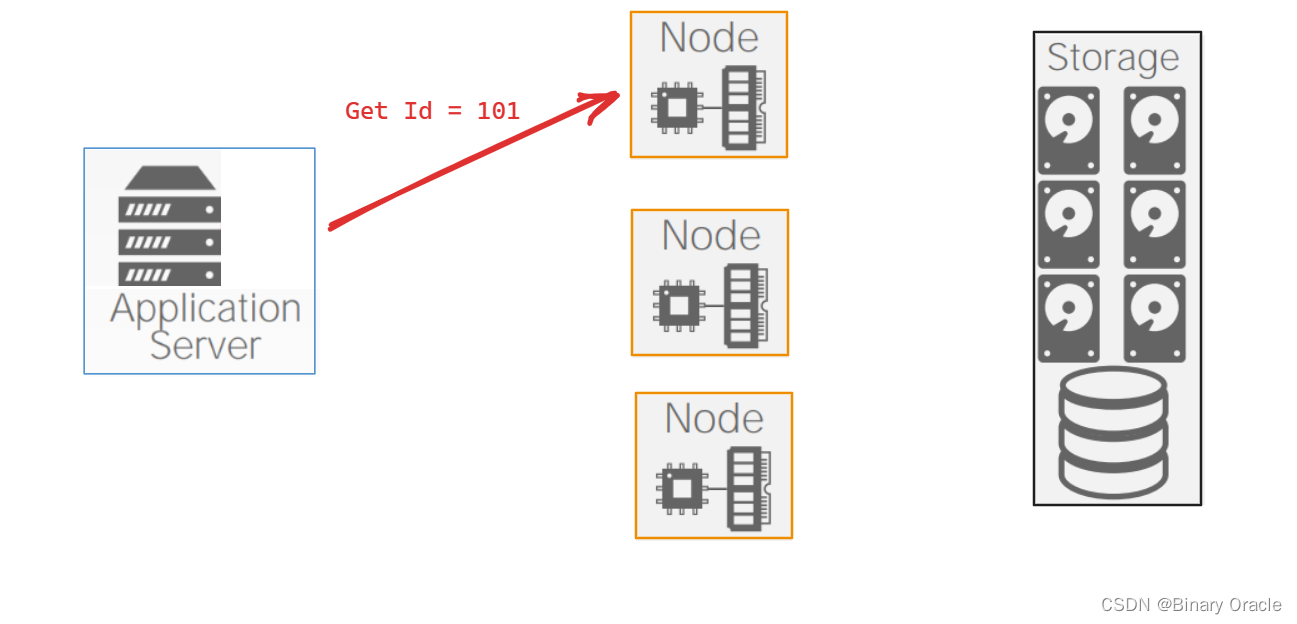
假设有两个计算节点,客户端想要获取 Id 为 101 的数据,它可以从任意计算节点访问。如果计算节点不足时,可以按需扩容:
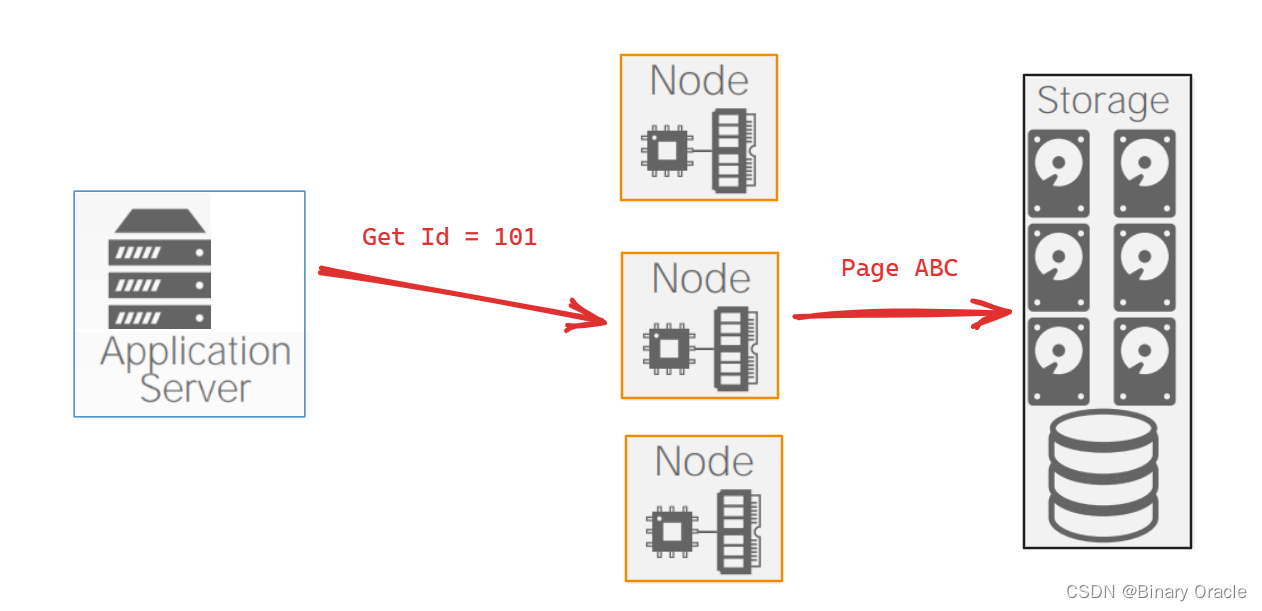
但如果客户端想要修改某条数据:
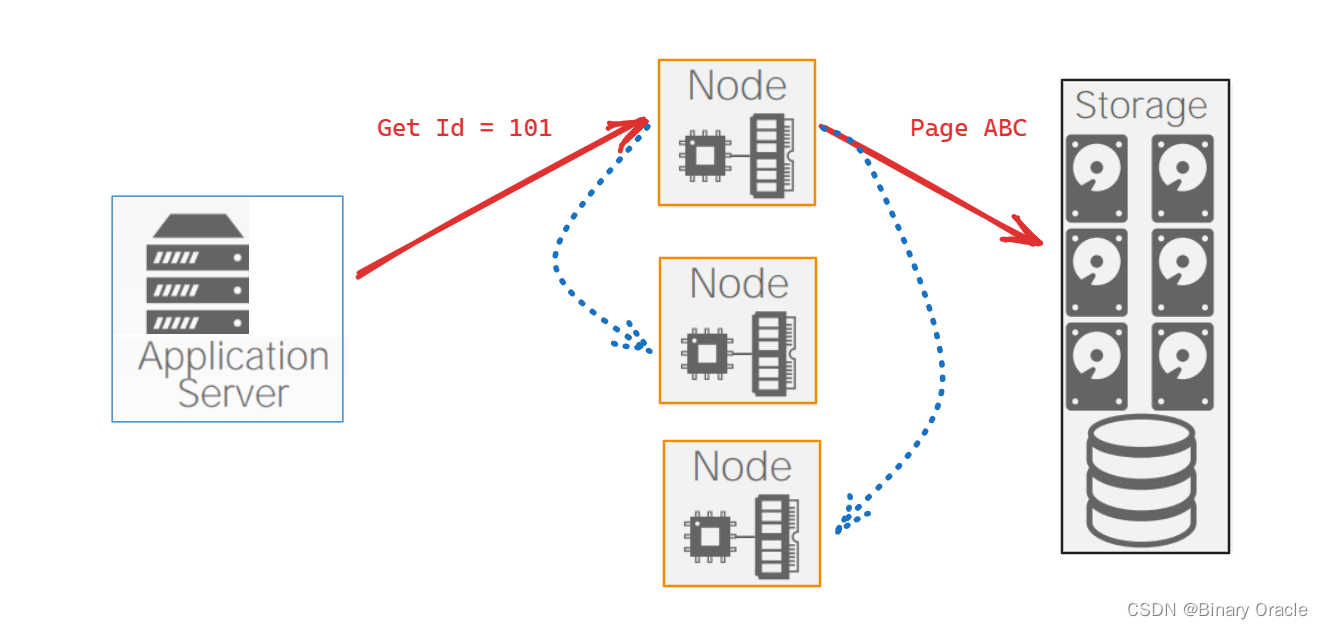
由于其它节点可能正缓存着 Page ABC,更新节点需要通过某种方式通知其它节点 Page ABC 已经被修改。由于既有的统一存储层不会再增加这样一层 Pub/Sub 逻辑,那么这种更新传播的逻辑就必须在计算层实现,且我们无法假设节点间的网络通信是可靠的,这也是 Shared-Disk 架构需要考虑的重要问题。
Shared Nothing
Shared Nothing,顾名思义,每个 CPU 都拥有独立的内存、磁盘,节点之间仅通过网络通信共享消息。这种架构下,扩容和保证一致性的难度将变得很大。扩容时,DBMS 需要在不同节点间迁移、均衡数据,同时要保证服务在线,且数据一致,可以想象其复杂性。但解决这个难题带来的好处也很可观,整个 DBMS 的性能将得到提升,因为数据库可以控制存储层本身,就能够独立根据数据的局部性原理排列数据,从而最大程度上减少每次查询所消耗的通信成本。
使用 Shared Nothing 架构的数据库有很多,罗列如下:

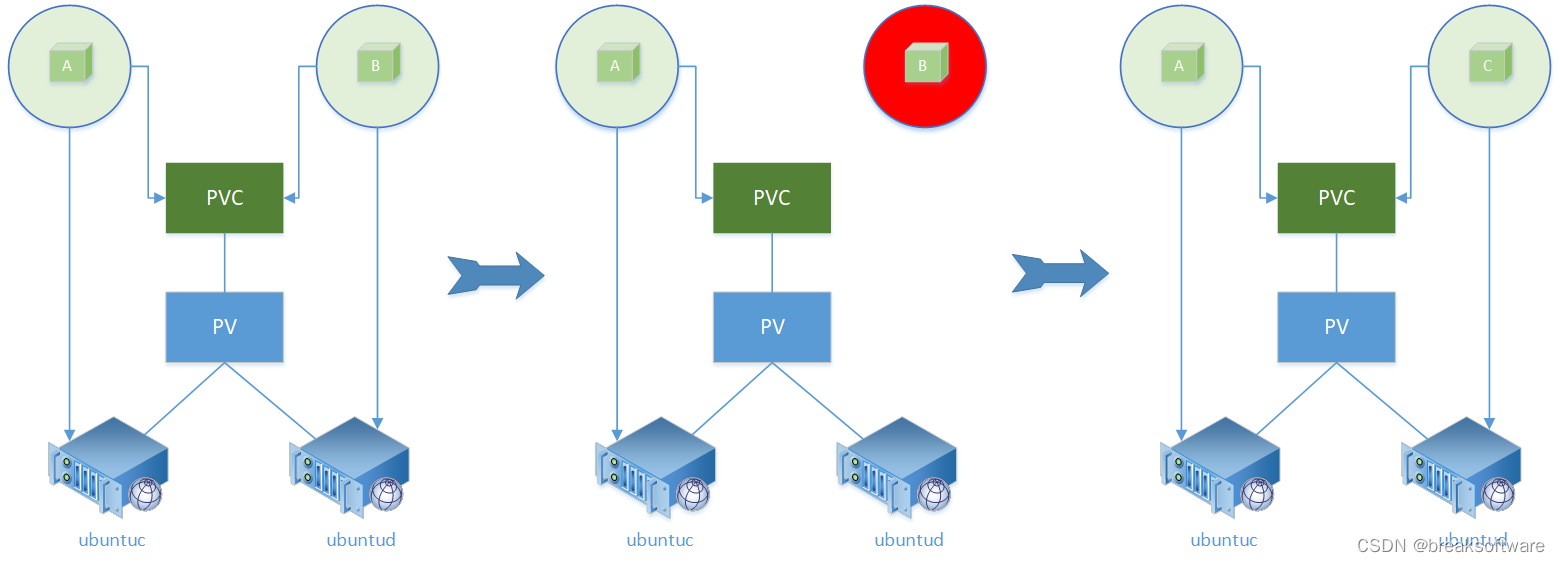
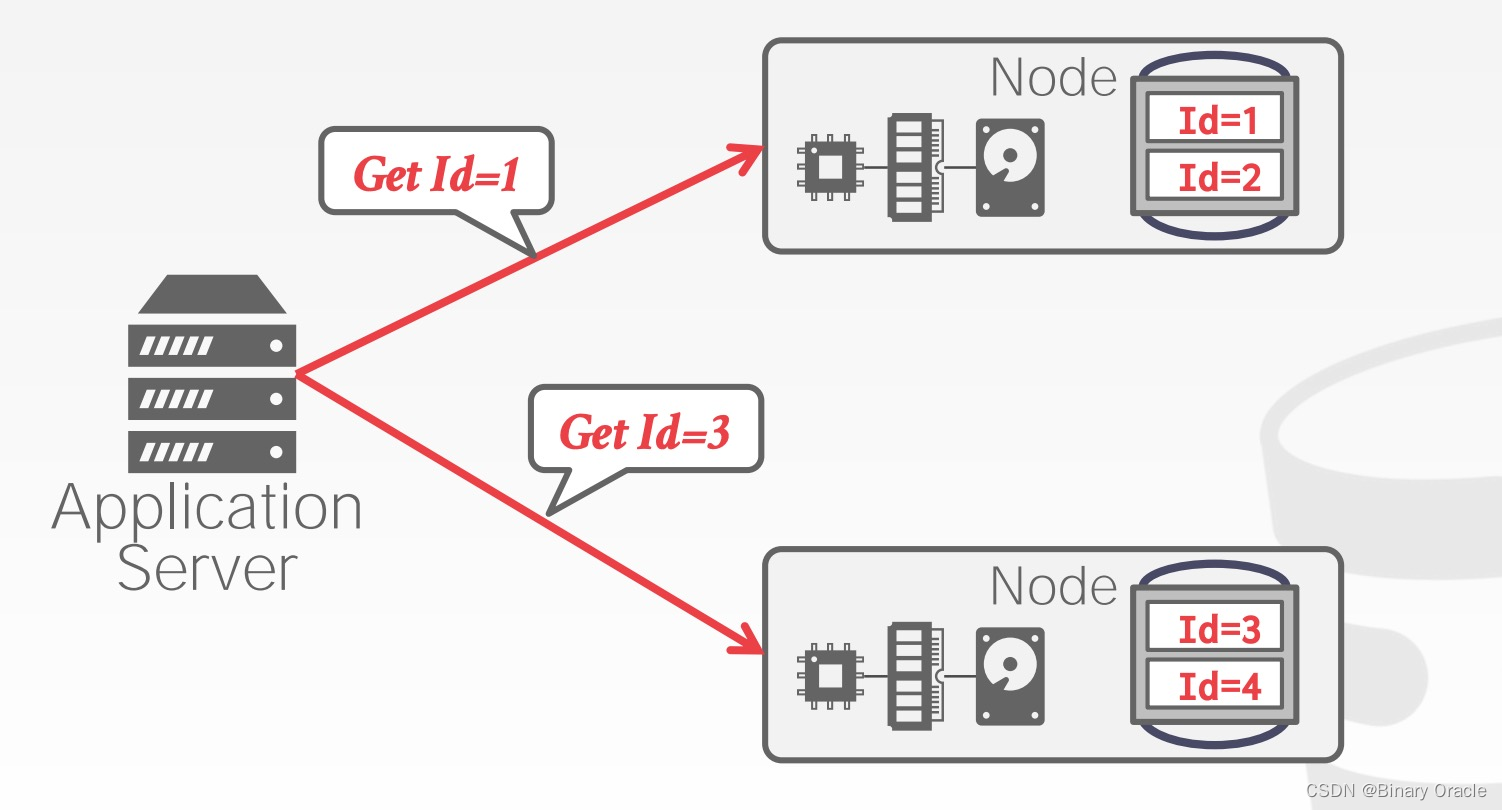
一个 Shared Nothing 的 Distributed DBMS 需要将数据分片到不同的节点上,每个节点拥有整个数据库的一小部分,如果查询所需的数据只落在一个节点上,就与单节点数据库无二,如下图所示:
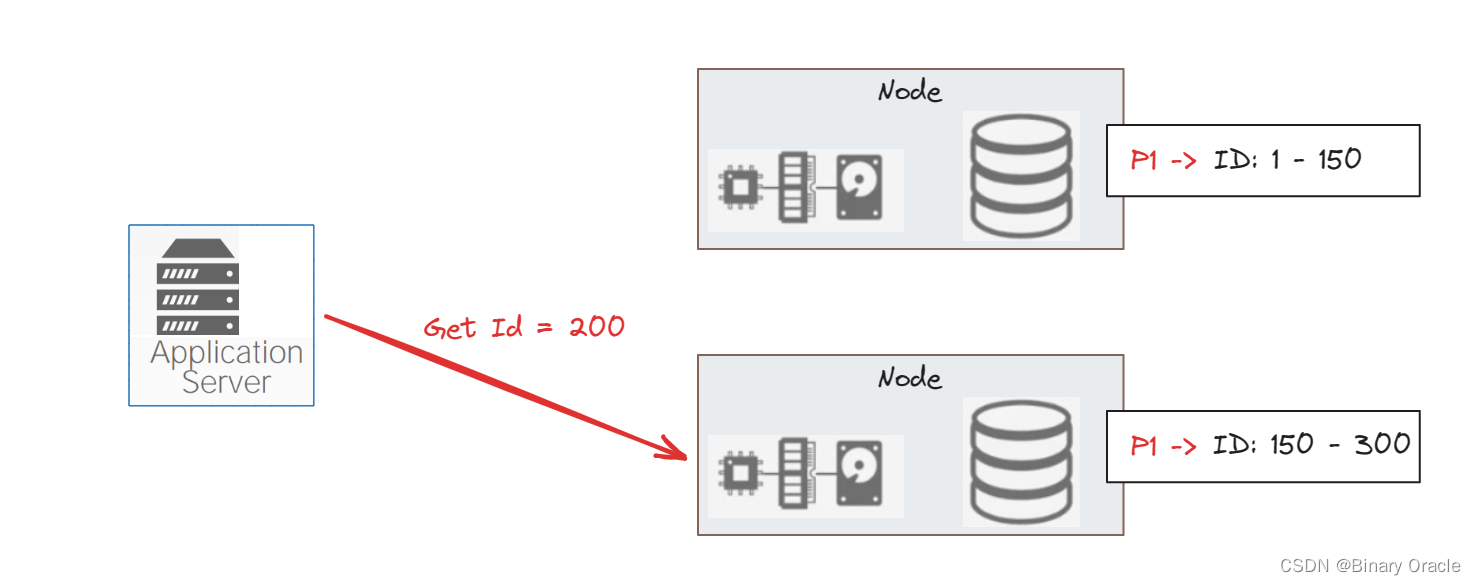
ID 为 1-150 之间的数据落在上面的节点,151-300 之间的数据落在下面的节点。像“哪个节点存储哪些范围的数据”这样的信息会有一个配置中心来存储。如果客户端要查询 Id=200 的数据,那么只需要访问下面的节点即可。如果客户端要同时获取 Id=10 和 Id=200 的数据,事情就会变得更复杂一些:
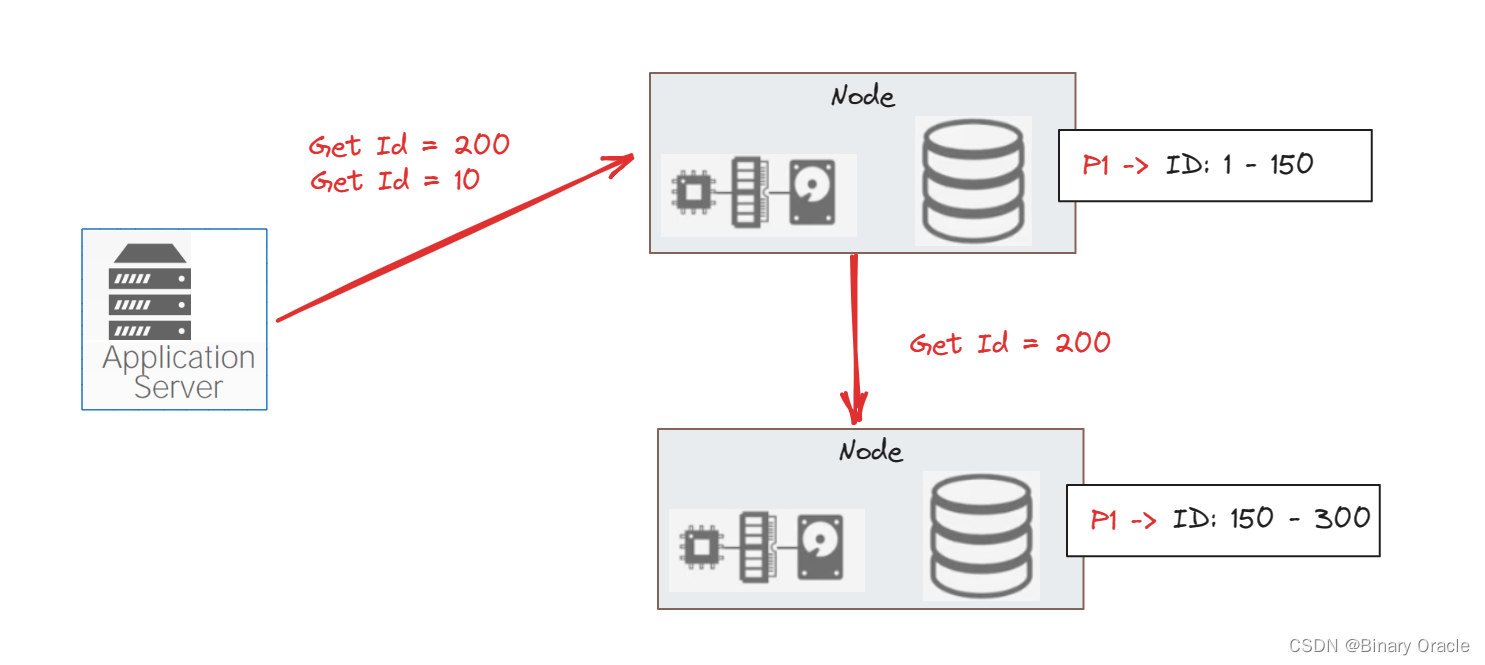
如上面的节点接收到请求,那么它要么将请求转发给下面的节点,要么从下面的节点读取响应的数据,然后在内部同时处理两个请求,这里就有一些设计决定需要做。如果 DBMS 的容量不够,就需要做在线扩容:
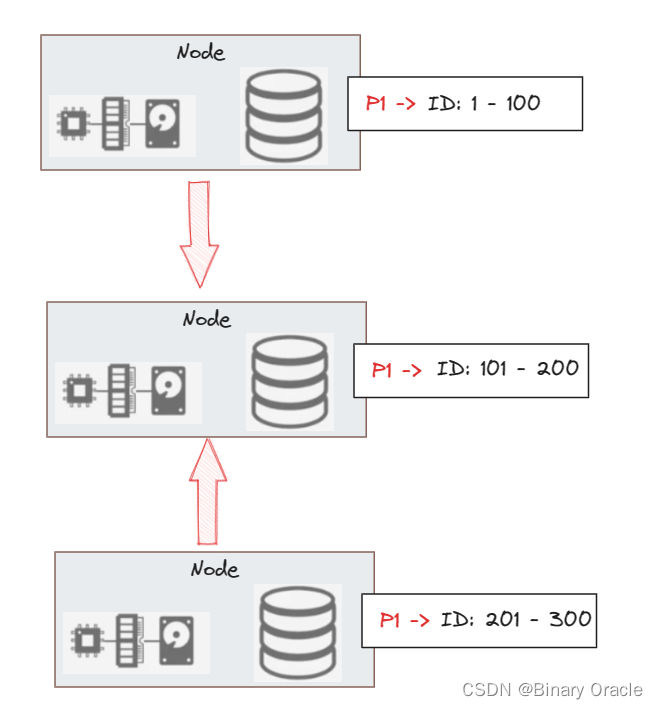
这时候需要对外透明地将上下两个节点中的一部分数据迁移到中间节点,平衡所有节点的数据,这里也有许多问题需要解决。
Early Distributed Database Systems
事实上,分布式数据库并不是新概念。早在 1979 年,Andy Pavlo 的导师 Michael Stonebraker 就开发了 Muffin 数据库,即 Ingress 的分布式版本;SDD-1 (1979) 是 Phil Bernstein 在分布式数据库上的原型系统,并没有真正在正式环境中使用,但许多关于分布式事务的观点和论文都是 Phil 基于 SDD-1 提出的;System R* (1984) 是 IBM Research 的内部项目,是 System R 的分布式版本,但并没有进入市场,然而后继者 DB2 实际上有相应的分布式版本;Gamma (1986) 是 Dewitt 实现的高性能分布式数据库;NonStop SQL 是 Jim Gray 基于高容错系统设计的一款分布式数据库系统,也是上述系统中唯一进入商用的系统,现在仍然运行在许多大型金融系统中。
Design Issues
刚才已经提到 Distributed DBMS 的系统架构以及可能遇到的问题,本节就来讨论这些设计问题:
- 应用如何获取数据?
- 如何在分布式数据库上执行查询?
- Push query to data
- Pull data to query
- DBMS 如何保证正确性?
Homogeneous VS. Heterogeneous
如果系统中的每个节点角色、权限相同,那就是同质节点 (Homogeneous Node);如果不同,就是异质节点。同质节点方案中,每个节点可以执行的任务集合是相同的,只是持有的数据不同,在处理扩容和故障恢复时比较简单;异质节点方案中,每个节点有各自的节点类型,可以执行的任务不同,允许在一个物理节点运行多个虚拟节点,执行不同任务。
以 MongoDB 为例:
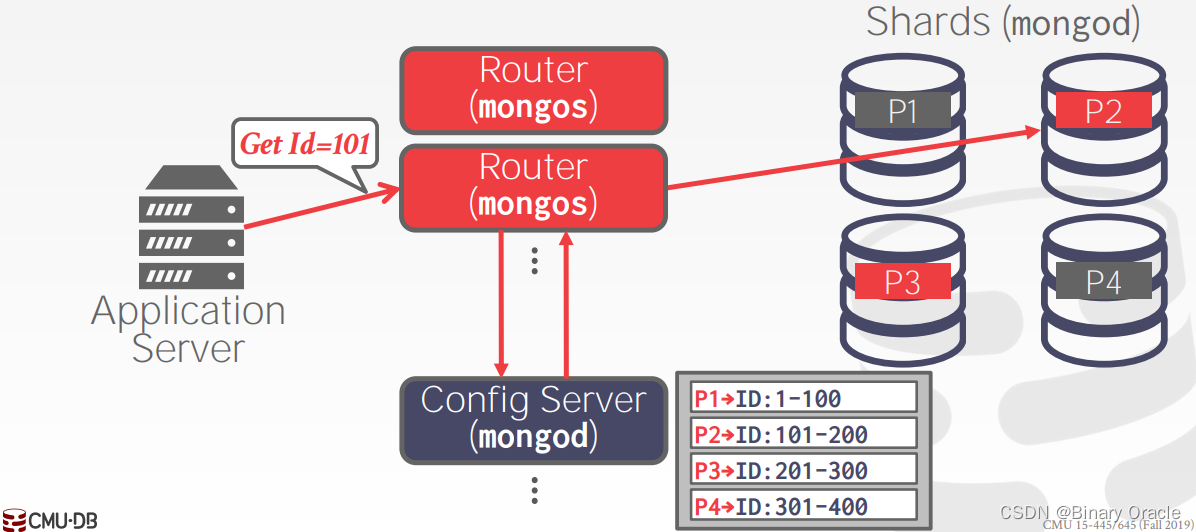
在 MongoDB 集群中有 3 种角色,Router、Config Server 以及 Shard。所有请求都打到 Router 上,Router 从 Config Server 中获取路由信息,即哪些数据存放在哪些分片上,然后根据这些路由信息将请求发送到对应的分片上执行。
Distributed DBMS 的用户不应该知道数据具体存储的地点,或者数据表本身是如何分片和复制的,对于用户来说,一个 SQL 在 Distributed DBMS 上运行的效果应该和在单节点 DBMS 上运行的效果等价。
Database Partitioning
既然要做 Distributed DBMS,势必要将数据库的资源分布到多个节点上,如磁盘、内存、CPU,这就是广义的分片,Partitioning 或 Sharding。DBMS 需要在各个分片上执行查询的一部分,然后将结果整合后得到最终答案。本节我们来关注数据如何在磁盘上分片。
Naive Table Partitioning
假设单个节点有足够的容量存储单张表,我们可以简单地让每个节点只存储一张表:
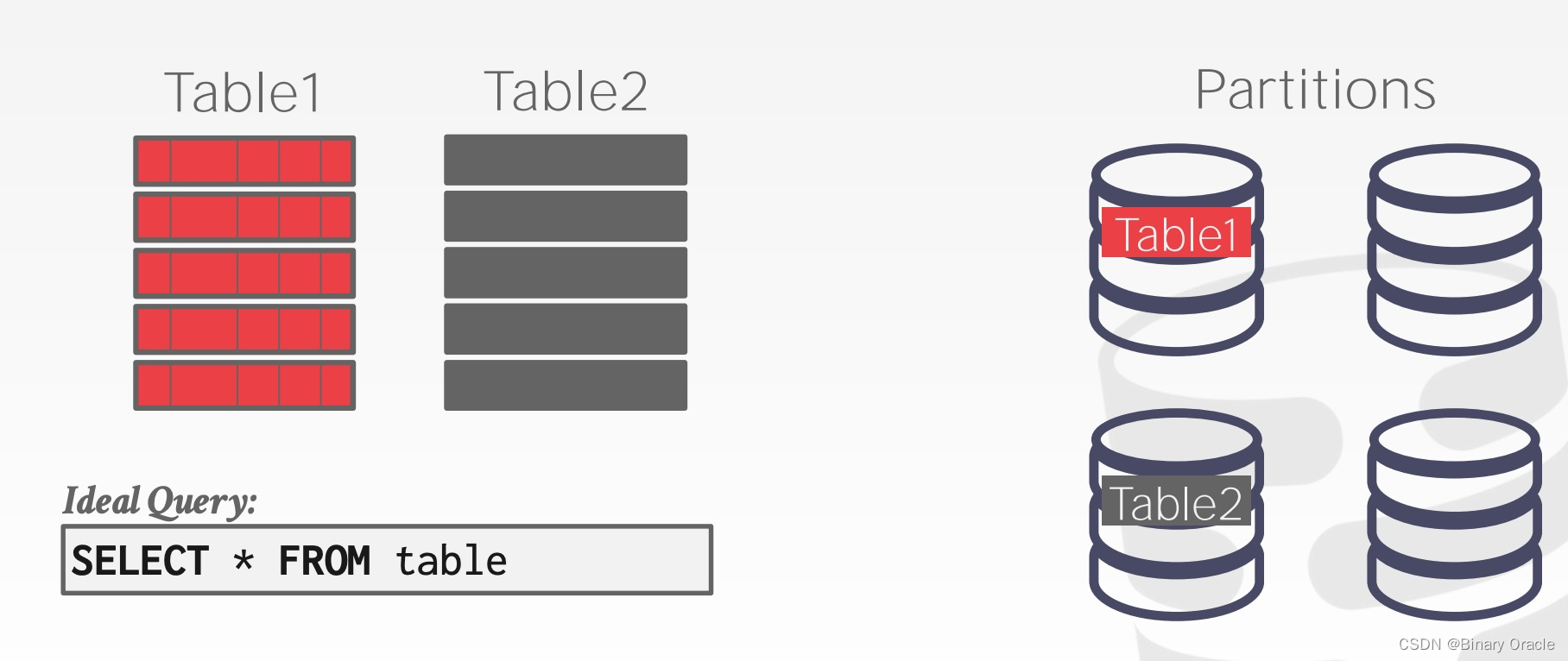
如果只存在单表查询,这种方案是最理想的。但问题也很多,如数据分布不均匀,只能在应用层做 Join 等等。
Horizontal Partitioning
第二种就是我们常用的横向分片,将一张表的数据切分成多个不相交的子集。这种分片方式要求 DBMS 要找到在大小、负载上能均匀分配的键。常用的分片方案如下:
- Hash Partitioning:计算哈希值后分片
- Range Partitioning:直接按号段分片
具体的分片案例如下:

对于这种分片方案,最理想的查询就是按 partitionKey 来点查数据。常用的 Hash Partitioning 算法就是一致性哈希 (Consistent Hashing):
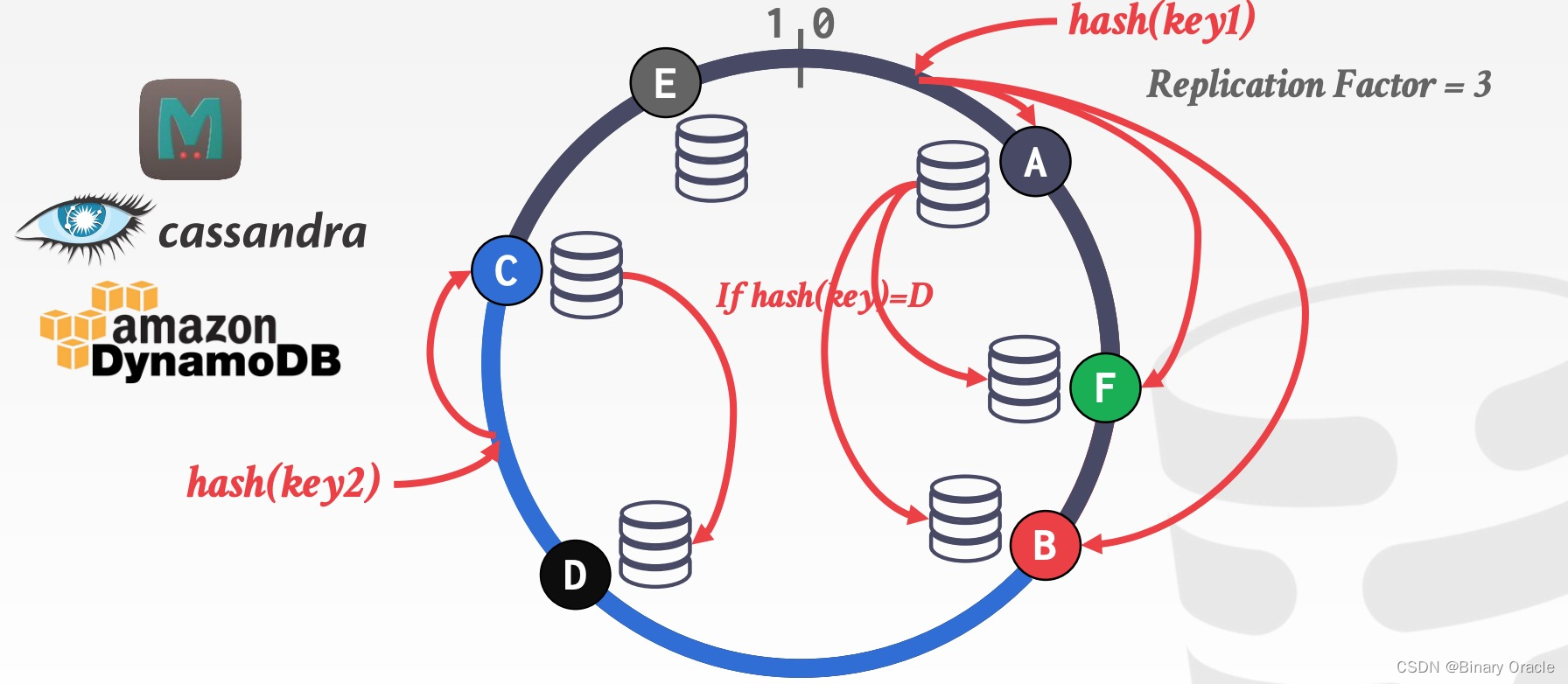
在 Shared Nothing 架构下,通常是物理分片:
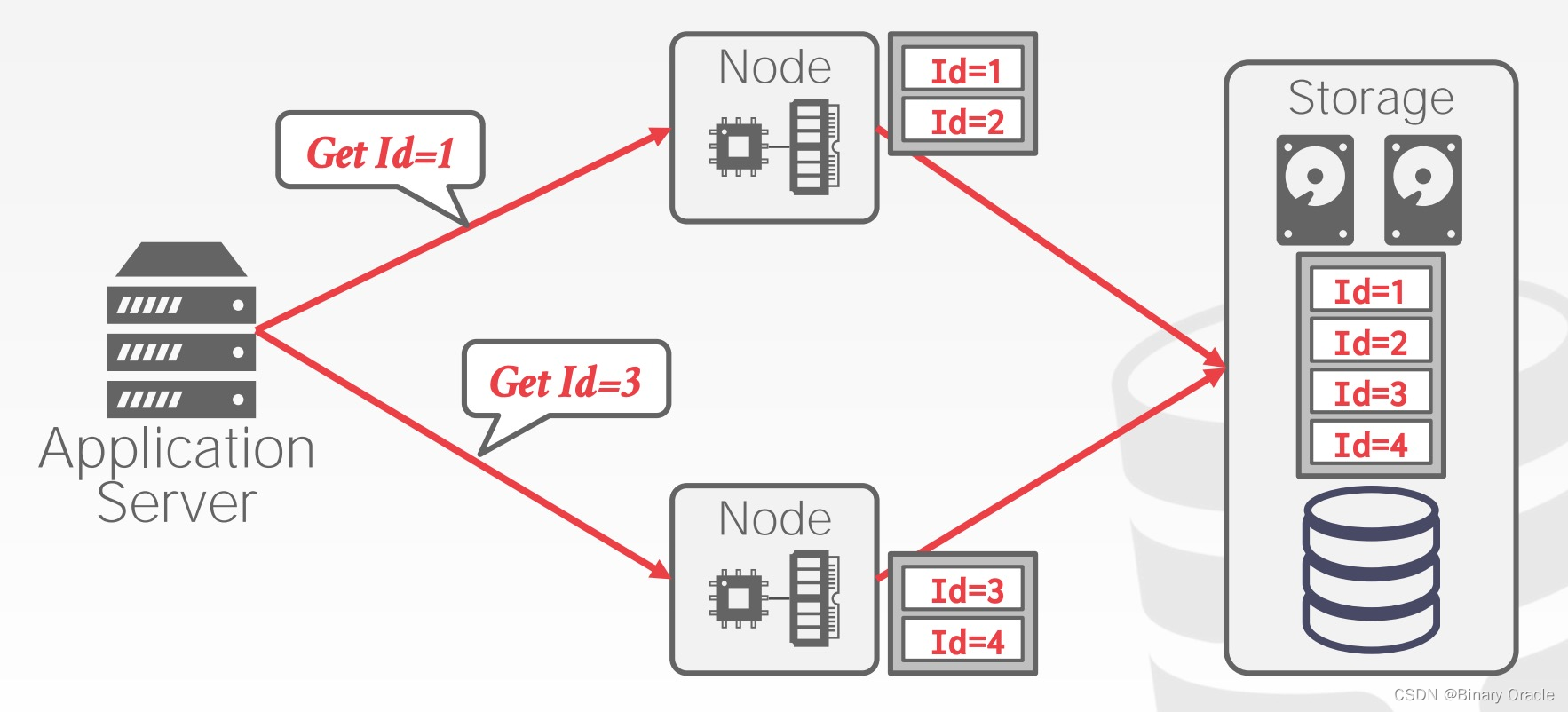
在 Shared Disk 架构下,通常是逻辑分片:
Transaction Coordination
对于 Distributed DBMS 来说,如果一个写事务只涉及单个节点上的数据,那 DBMS 无需关心在其它节点上并发执行的事务状态;如果涉及多个节点数据,就需要去协调多个节点上的事务执行方案,即所谓的 Transaction Coordination,后者主要有两种方案:中心化 (Centralized) 和去中心化 (Decentralized)。
Centralized Coordinator
TP Monitor
- 实现 Centralized Coordinator 的其中一种思路就是构建一个独立的组件负责管理事务,叫 Transaction Processing Monitor,即 TP Monitor。
- TP Monitor 与其之下运行的单节点 DBMS 无关,DBMS 无需感知 TP Monitor 的存在。
- 每次应用在发送事务请求时,需要先通过 TP Monitor 确认事务是否可以执行。
举例如下:
- 假设一个 DBMS 有 4 个分片,应用需要通过一个事务修改 P1、P3、P4 上的数据,首先需要从 Coordinator 上请求 P1、P3、P4 的锁,
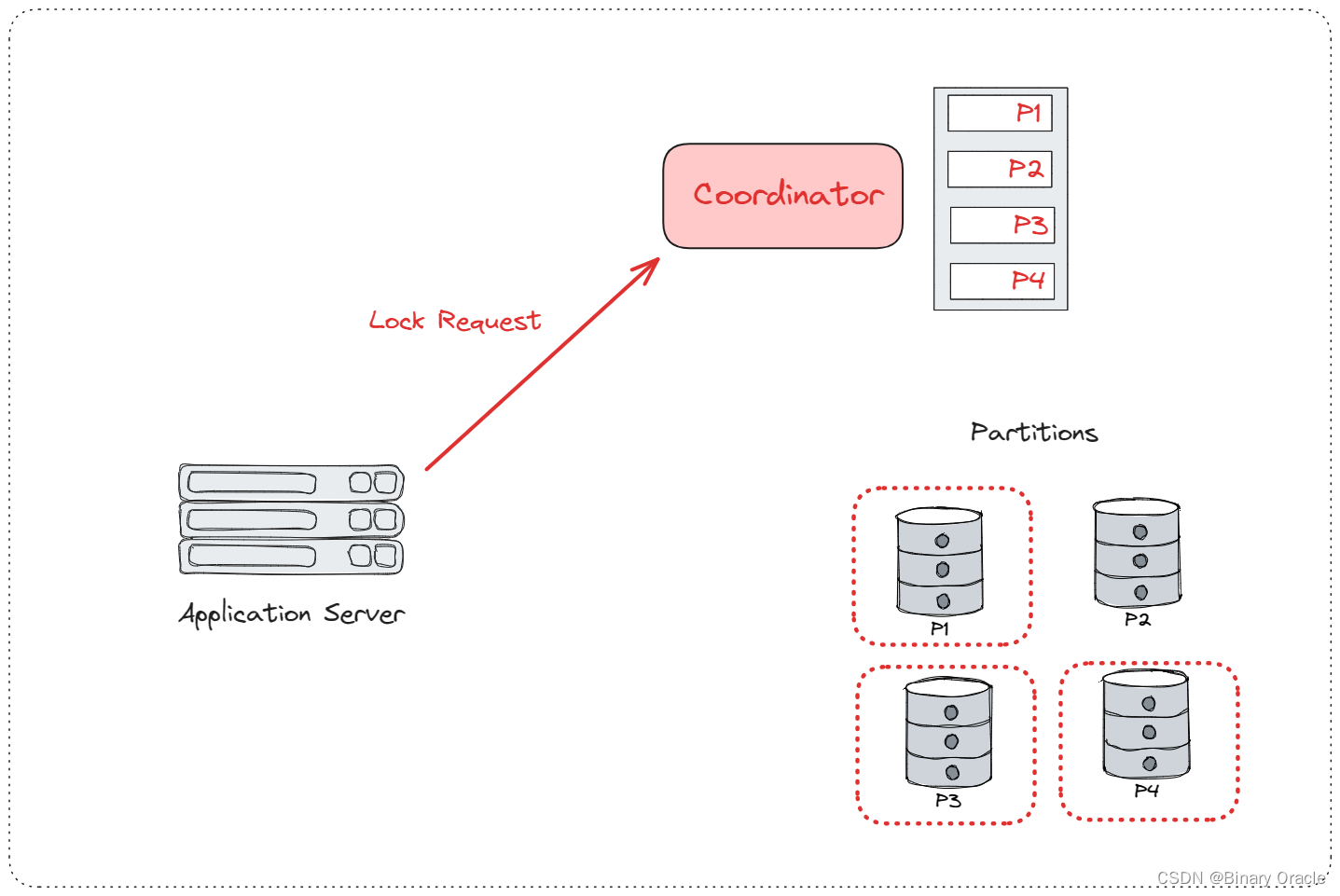
拿到锁后,应用就可以到 P1、P3、P4 上修改数据 (未提交),修改完毕后再向 Coordinator 发送 Commit 请求,Coordinator 询问各个分片刚才的修改是否可以安全地提交,可以就提交,然后 Coordinator 返回 Ack:
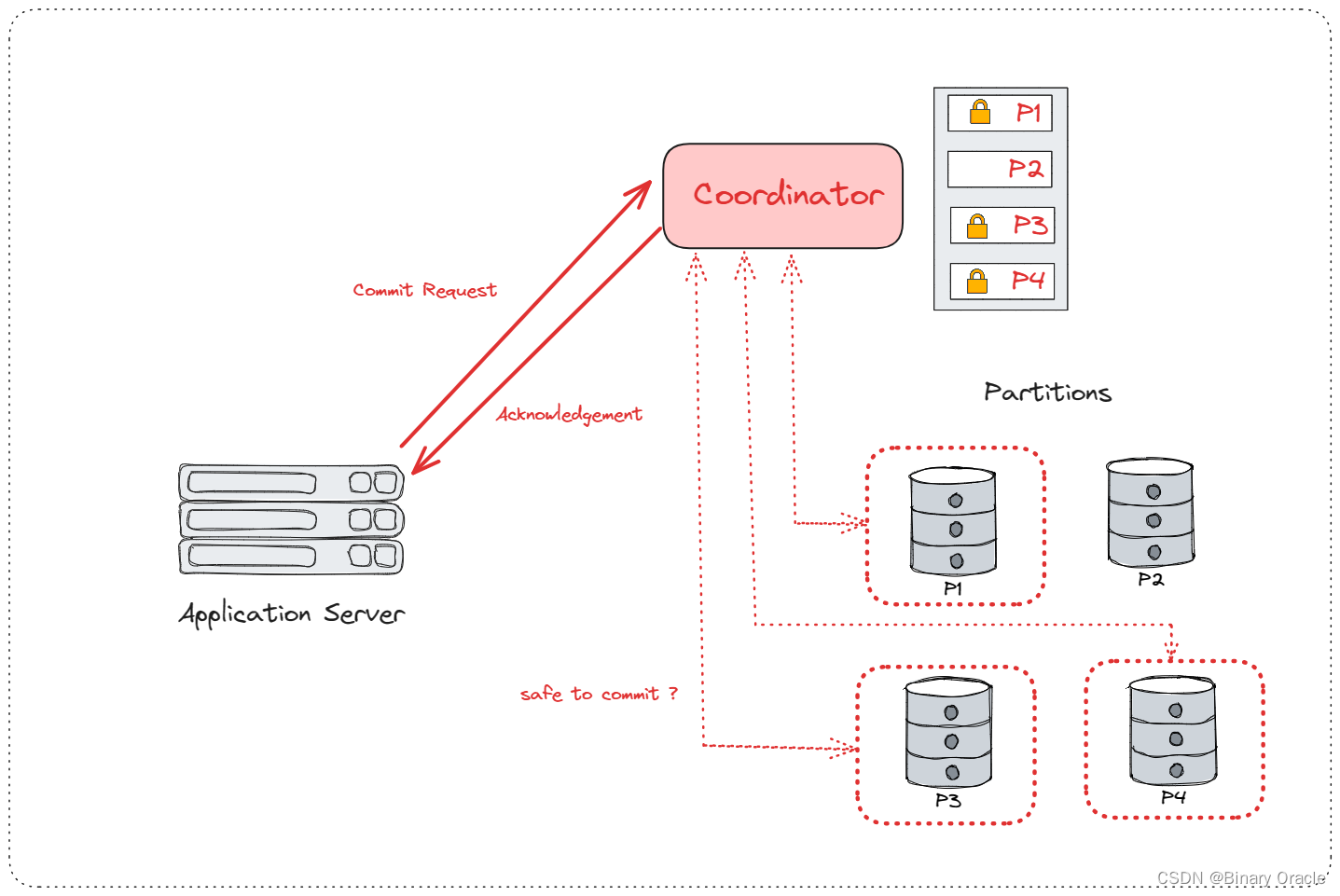
许多数据库厂商也出售类似 TP Monitor 的产品,如 Apache Omid、IBM Transac 等等。
Middleware
实现 Centralized Coordinator 的另一种方案是 Middleware,对于应用来说,Middleware 就是 Distributed Database 本身,Middleware 负责与后面的所有分片交互,协调事务的执行。如下图所示:
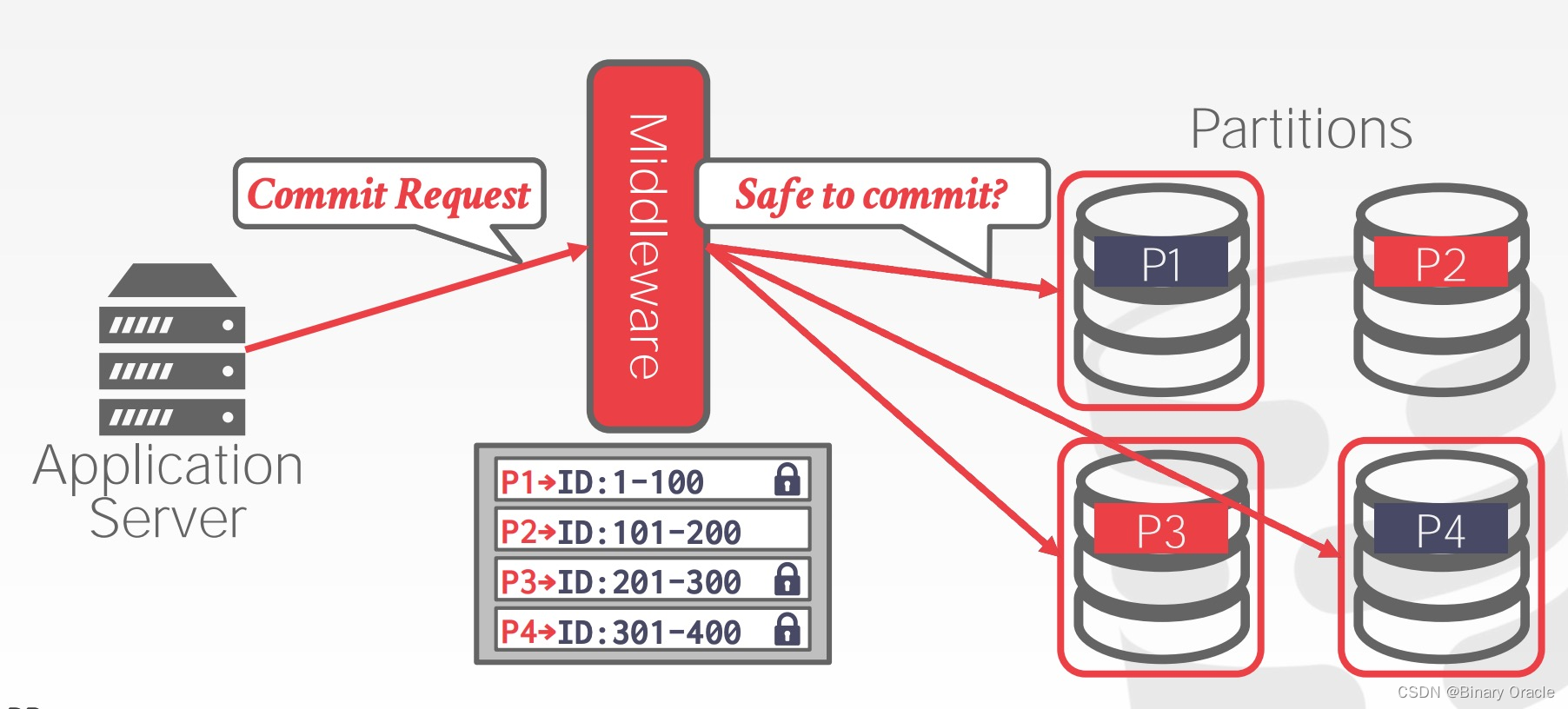
Facebook 运行着世界上最大的 MySQL 集群,采用的就是这种方案。它们的 Middleware 负责处理分布式事务、路由、分片等所有逻辑。
Decentralized Coordinator
Decentralized Coordinator 的基本思路就是,执行某个事务时,会选择一个分片充当 Master,后者负责询问涉及事务的其它分片是否可以执行事务,完成事务的提交或中止:
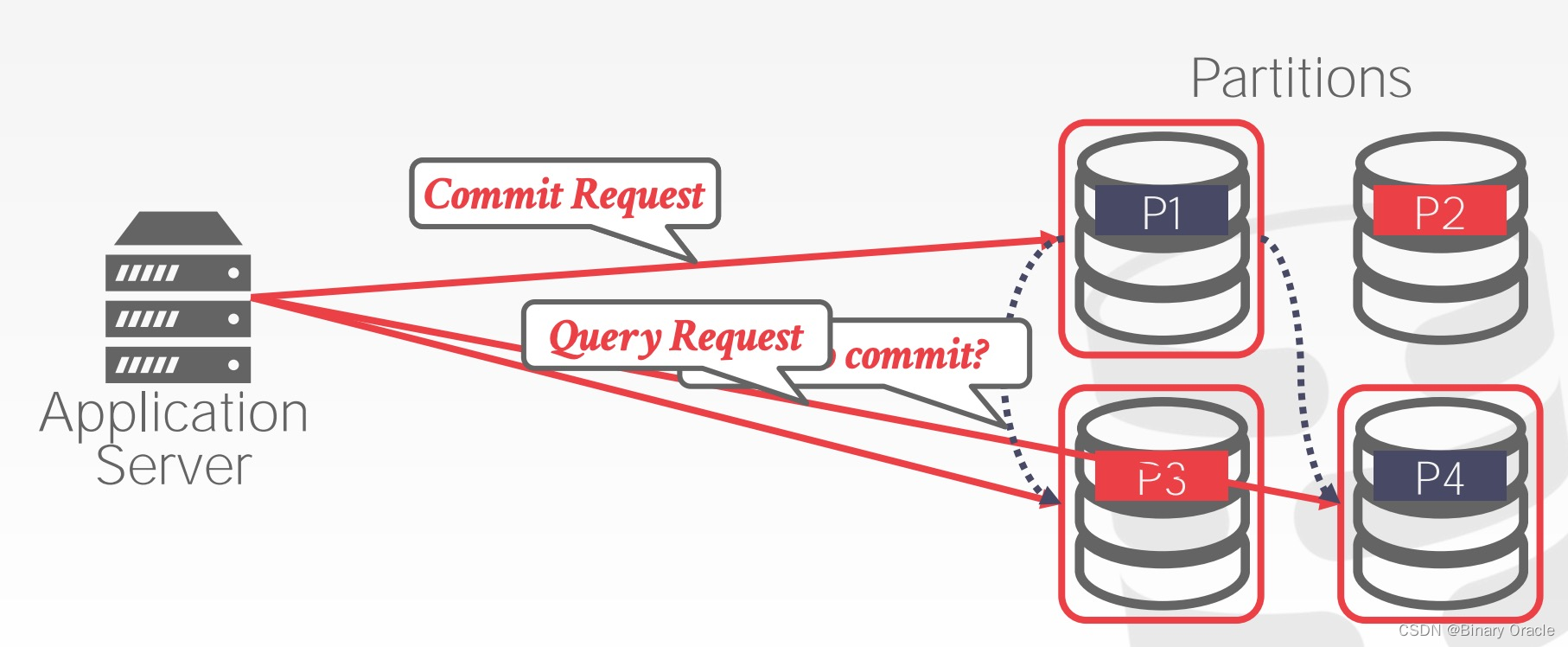
Distributed Concurrency Control
分布式并发控制的难度在于:
- Replication
- Network Communication Overhead
- Node Failures
- Clock Skew
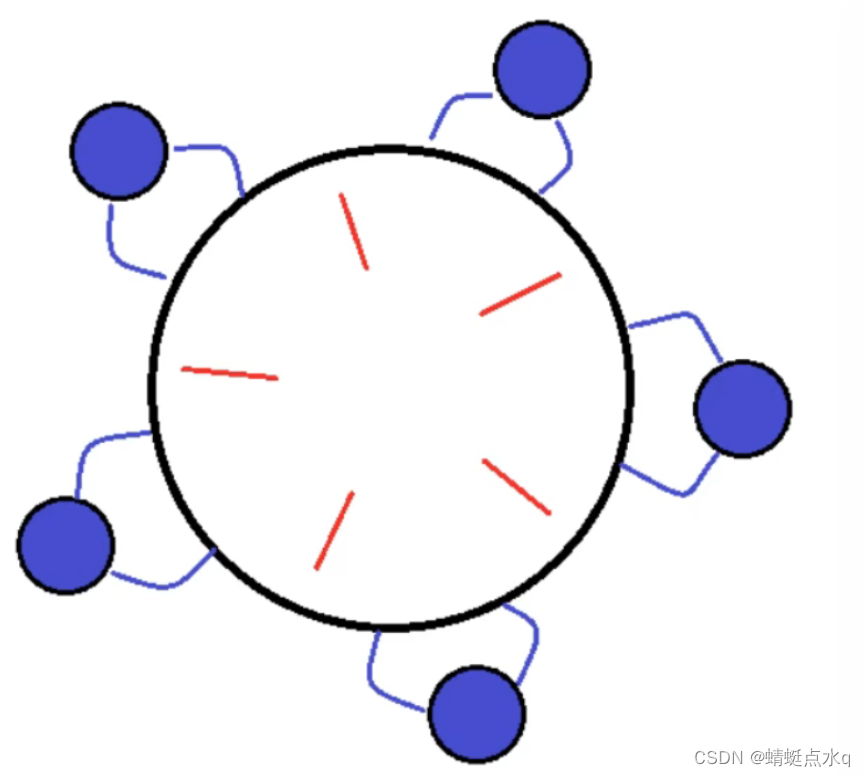
举个例子,假如我们要实现分布式的 2PL:
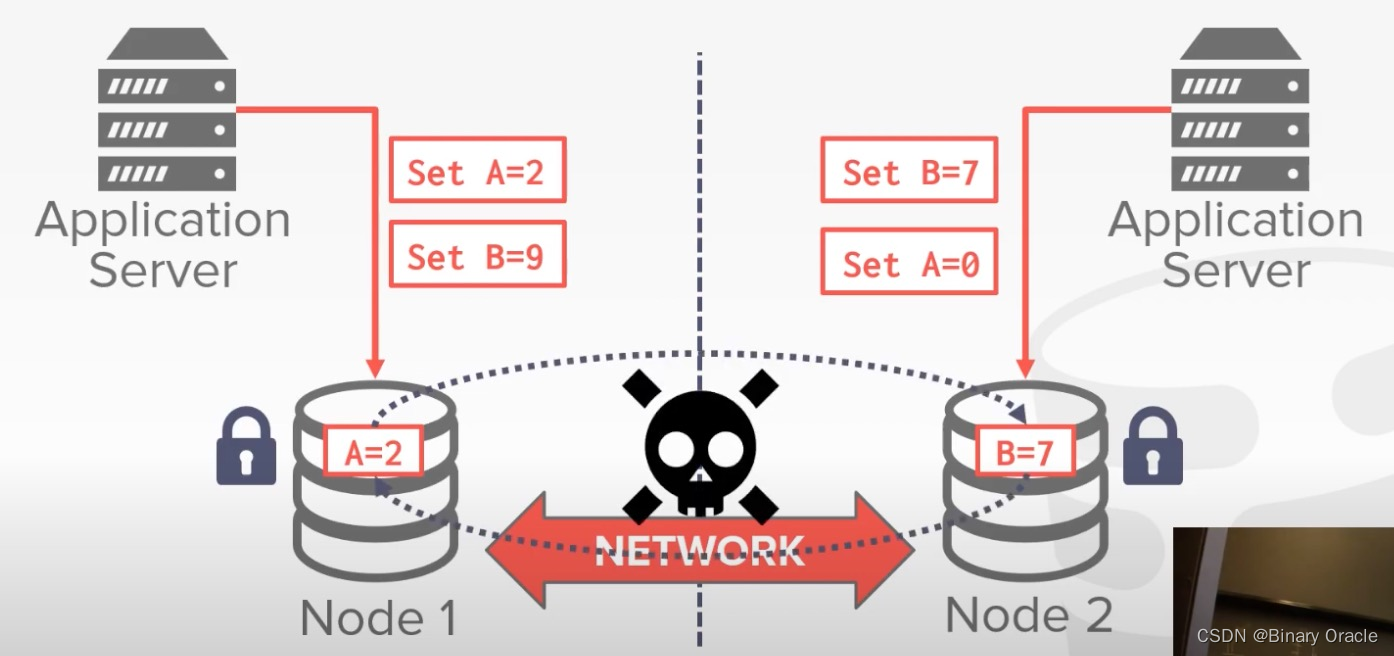
A 数据在 Node 1 上,B 数据在 Node 2 上,因为没有中心化的角色存在,一旦发现如上图所示的死锁,双方都不知道是应该中止还是继续等待。从这个例子我们可以看出将并发控制升级到分布式并发控制,有许多问题要解决。
Conclusion
本节我们了解了 Distributed DBMS 的皮毛,也看到了实现它的难度。有一个 Jepsen Project,它设置了一系列分布式事务测试用例,来验证市面上的系统是否真如其声明的那样可靠。即便是 MongoDB、TiDB 这些数据库的一些版本都被验证无法提供它们声明的保证。
本节对应教材PDF