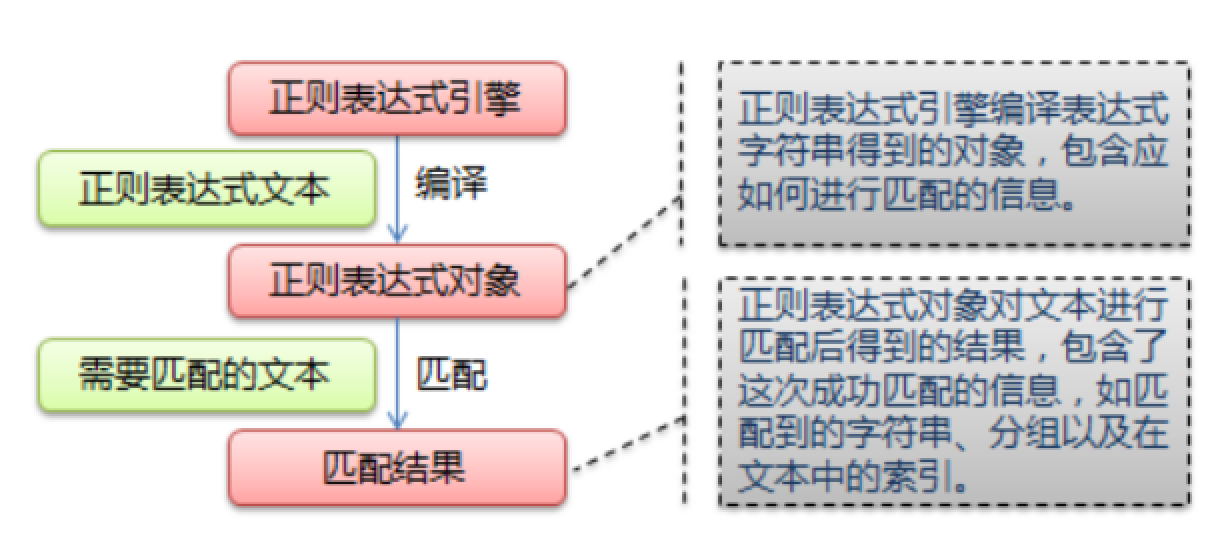
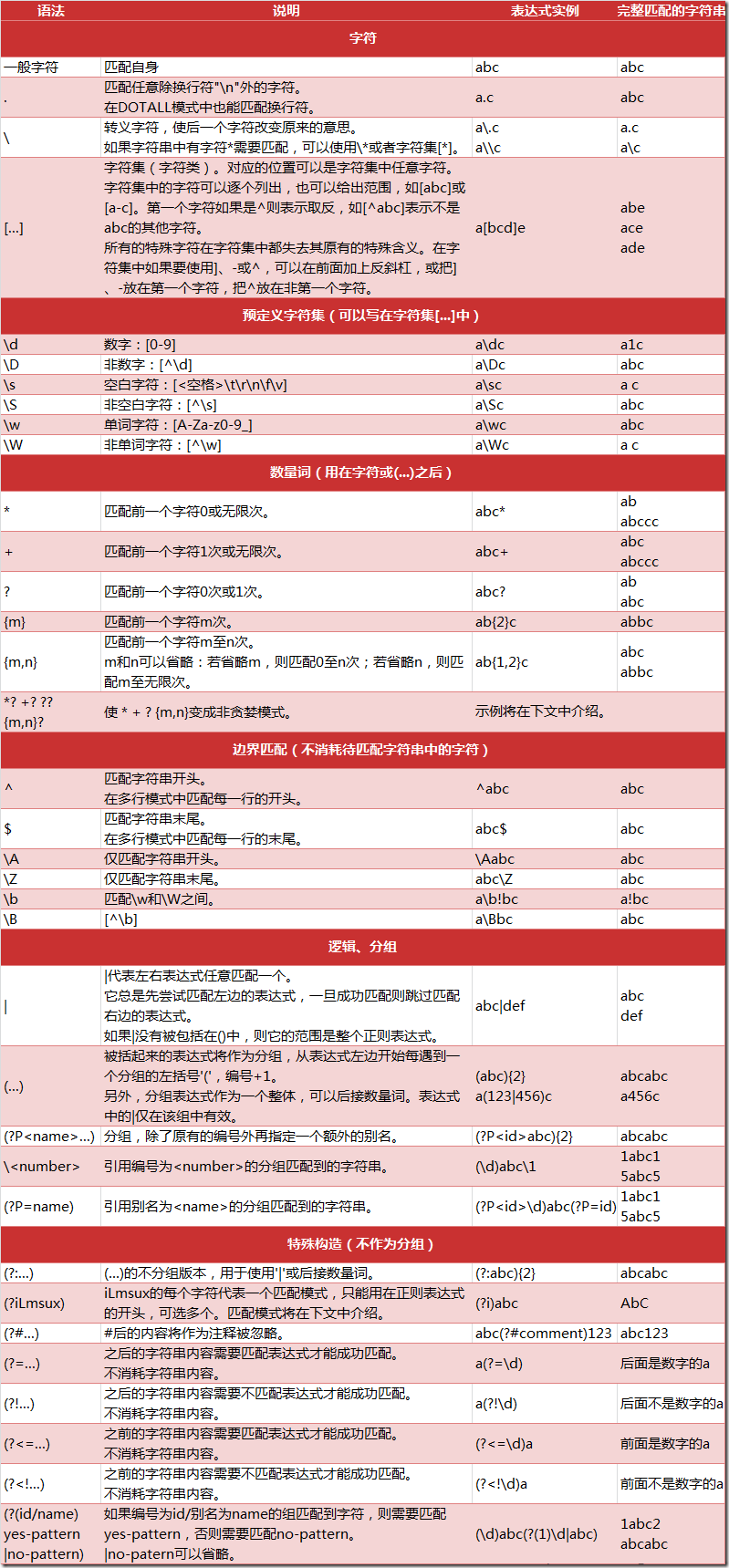
什么是正则表达式
正则表达式,又称规则表达式,通常被用来检索、替换那些符合某个模式(规则)的文本。 正则表达式是对字符串操作的一种逻辑公式,就是用事先定义好的一些特定字符、及这些特定字符的组合,组成一个“规则字符串”,这个“规则字符串”用来表达对字符串的一些过滤逻辑。 给定一个正则表达式和另一个字符串,我们可以达到如下的目的:
- 给定的字符串是否符合正则表达式的过滤逻辑(“匹配”)
- 通过正则表达式,从文本字符串中获取到我们想要的特定部分(“过滤”)
正则表达式匹配规则
Python的re模块
在python中,我们可以使用内置的re模块来使用正则表达式。 有一点需要特别注意的是,正则表达式使用对特殊字符进行转义,所以如果我们要使用原始字符串,只需要一个r前缀,示例:
r'chuanzhiboke\t\.\tpython'
re模块的一般使用步骤如下:
- 使用
compile()函数将正则表达式的字符串形式编译为一个Pattern对象 - 通过
Pattern对象提供的一系列方法将文本进行匹配查找,获得匹配结果(一个Match对象) - 最后使用
Match对象提供的属性和方法获得信息,根据需要进行其他的操作。
compile对象
compile函数用于编译正则表达式,生成一个Pattern对象,它的一般使用形式如下:
import re
#将正则表达式编译为Pattern对象
pattern = re.compile(r'\d+')
在上面,我们已将一个正则表达式编译成Pattern对象,接下来,我们就可以利用pattern的一系列方法对文本进行匹配查找了。 Pattern对象的一些常用方法主要有:
- match对象:从起始位置开始查找,一次匹配。
- search对象:从任何位置开始查找,一次匹配。
- findall()对象:全部匹配,返回列表。
- finditer()对象:全部匹配,返回迭代器。
- spilt()对象:分割字符串,返回列表
- sub()对象:替换
match 方法 match方法用于查找字符串的头部(也可以指定起始位置),它是一次匹配,只要找到了一个匹配的结果返回,而不是查找所有匹配的结果,它的一般使用形式如下:
match(string[, pos[, endpos]])
其中,string是待匹配的字符串,pos和endpos是可选参数,指定字符串的起始和终点位置,默认值分别是0和len(字符串长度)。因此,当你不指定pos和endpos时,match方法默认匹配字符串的头部。
当匹配成功时,返回一个Match对象,如果没有匹配上,则返回None。
>>>import re
>>>pattern = re.compile(r'\d+') #用于匹配至少一个数字
>>>m = pattern.match('one12twothree34four') #查找头部,没有匹配
>>>print(m) #如果没有匹配上,就什么也不输出
>>>m = pattern.match('one12twothree34four', 2, 10) #从'e'的位置开始匹配,没有匹配到
>>>print(m)
>>>m = pattern.match('one12twothree34four', 3, 10) #从'1' 的位置开始匹配,正好匹配上
>>>print(m)
<_sre.SRE_Match object at 0x10a42aac0>
>>>m.group(0) #可忽略0
'12'
>>>m.start(0) #可忽略0
3
>>>m.end(0) #可忽略0
5
>>>m.span(0) #可忽略0
(3, 5)
在上面,当匹配成功时返回一个Match对象,其中:
- group([group1,…])方法用于获得一个或多个分组匹配的字符串,当要获得整个匹配字符串的子串时,可直接使用group()或group(0);
- start([group])方法用于获取分组匹配的子串在整个字符串中的起始位置(子串第一个字符的索引),参数默认值为0;
- end([group])方法用于获取分组匹配的子串在整个字符串中的结束位置(子串最后一个字符的索引+1),参数默认值是0
- span([group])方法返回(start[group], end(group))
>>>import re
>>>pattern = re.compile(r'([a-z]+) ([a-z]+)', re.I) #表示忽略大小写
>>>m = pattern.match('hello world wide web')
>>>print(m) #匹配成功,返回一个Match对象
<_sre.SRE_Match object at 0x10bea83e8>
>>>m.group(0) #返回匹配成功的整个子串
'Hello World'
>>>m.span(0) #返回匹配成功的整个子串
(0, 11)
>>>m.group(1) #返回第一个分组匹配成功的子串
'Hello'
>>>m.span(1) #返回第一个分组匹配成功
(0, 5)
>>>m.group(2) #返回第2个分组匹配成功的子串
'World'
>>>m.span(2) #返回第2个分组匹配成功的子串的位置
(6, 11)
>>>m.groups() #等价于(m.group(1), m.group(2), ...)
('Hello', 'World')
>>>m.group(3) #不存在第3个分组
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
IndexError: no such group
search方法 search方法用于查找字符串的任何位置,它也是一次匹配,只要找到了一个匹配的结果就返回,而不是查找所有匹配的结果,它的一般使用形式如下:
search[string[, pos[, endpos]]]
其中,string是待匹配的字符串,pos和endpos是可选参数,指定字符串的起始和终点位置,默认值分别是0和len(字符串长度)。 当匹配成功时,返回一个Match对象,如果没有匹配上,则返回None。 让我们看看例子:
>>>import re
>>>pattern = re.compile('\d+')
>>>m = pattern.search('one12twothree34four') #这里如果使用match方法则不匹配
>>>m
<_sre.SRE_Match object at 0x10cc03ac0>
>>>m.group()
'12'
>>>m = pattern.search('one12twothree34four', 10, 30) #指定字符串区间
>>>m
<_sre.SRE_Match object at 0x10cc03b28>
>>>m.group()
'34'
>>>m.span()
(13, 15)
在看一个例子:
# coding:utf-8
import re
#将正则表达式编译成Pattern对象
pattern = re.compile(r'\d+')
#使用search()方法查找匹配的字符串,不存在匹配的子串时将不返回
m = pattern.search('hello 123456 789')
if m:
#使用Match获得分组信息
print('matching string:',m.group())
#起始位置和结束位置
print('position: ',m.span())
执行结果:
matching string: 123456
position:(6,12)
findall 方法 上面的match和search方法都是一次匹配,只要找到了一个匹配的结果就返回。然而,在大多数时候,我们需要搜索整个字符串,获得所有匹配的结果。 findall方法的使用形式如下:
findall(string[, pos[, endpos]])
其中,string是待匹配的字符串,pos和endpos是可选参数,指定字符串的起始和终点位置分别是0和len(字符串长度)。 findall是以列表形式返回全部能匹配到的子串,如果没有匹配,则返回一个空列表。
import re
pattern = re.compile(r'\d+') #查找数字
result1 = pattern.findall('hello 123456 789')
result2 = pattern.findall('one1two2three3four4', 0, 10)
print(result1)
print(2)
执行结果如下:
['123456', '789']
['1', '2']
再来看一个例子:
import re
#re模块提供一个方法叫compile提供,提供我们输入一个匹配的规则
#然后返回一个pattern实例,我们根据这个规则去匹配字符串
pattern = re.compile(r'd+\.\d*')
#通过pattern.findall()方法能够全部匹配到我们得到的字符串
result = pattern.findall("123.141593, 'bigcat', 232312, 3.15")
#findall以列表形式 返回全部能匹配到的子串给result
for item in result:
print(item)
运行结果:
123.141593
3.15
finditer方法 finditer方法的行为跟findall的行为类似,也是搜索整个字符串,获得所有匹配的结果。但它返回一个顺序访问每一个匹配结果(Match对象)的迭代器。
#coding:utf-8
import re
pattern = re.compile(r'\d+')
result1 = pattern.finditer('hello 123456 789')
result2 = pattern.finditer('one1two2three3four4', 0, 10)
print(result1)
print(result2)
print('result1....')
for m1 in result1:
print("matching string:{} position:{}".format(m1.group(), m1.span()))
print('result2....')
for m2 in result2:
print("matching string:{} position:{}".format(m2.group(), m2.span()))
执行结果:
<type 'callable-iterator'>
<type 'callable-iterator'>
result1.
matching string: 123456, position: (6, 12)
matching string: 789, position: (13, 16)
result2
matching string: 1, position: (3, 4)
matching string: 2, position: (7, 8)
split 方法 split方法按照能够匹配的子串将字符串分割后返回列表,它的使用形式如下:
split(string[, maxsplit])
其中,maxsplit用于指导最大分割次数,不知道静全部分割。 看看例子:
import re
p = re.compile(r'[\s\,;]+')
print(p.split('a,b;;c d'))
执行结果:
['a', 'b', 'c', 'd']
sub方法 sub方法用于替换。它的使用形式如下:
sub(repl, string[, count])
其中,repl可以是字符串也可以是一函数:
- 如果repl是字符串,则会使用repl去替换字符串每一个匹配的子串,并返回替换后的字符串,repl还可以使用id的形式来引用过分组,但不能使用编号0;
- 如果repl是函数,这个方法应当只接受一个参数(Match对象),并返回一个字符串用于替换(返回的字符串中不能再引用分组)。
- count用于指导最多替换次数,不指定时全部替换。
看看例子:
import re
p = re.compile(r'(\w+) (\w+)') #\w=[A-Za-z0-9]
s = 'hello 123, hello 456'
print(p.sub(r'hello world', s)) #使用'hello world'替换'hello 123'和'hello 456'
print(p.sub(r'\2 \1', s))
def func(m):
return 'hi' + ' ' + m.group(2)
print(p.sub(func, s))
print(p.sub(func, s, 1))
执行结果:
hello world, hello world
123 hello, 456 hello
hi 123, hi 456
hi 123, hello 456
匹配中文 在某些情况下,我们想要匹配文本中的汉字,有一点需要注意的是,中文的unicode编码范围主要在[u4e00-u9fa5],这里说主要是因为这个范围并不完整,比如没有包括全角(中文)标点,不过,在大部分情况下,应该是够用的。 假设现在想把字符串title=u’你好,hello,世界’中的中文提取出来,可以这么做:
import re
title = u'你好,hello,世界'
pattern = re.compile(u'[\u4e00-\u9fa5]+')
result = pattern.findall(title)
print(result)
注意到,我们在正则表达式前面加上了前缀u,u表示unicode字符串。 执行结果:
['你好', '世界']
注意:贪婪模式与非贪婪模式
- 贪婪模式:在整个表达式匹配成功的前提下,尽可能多的匹配(*);
- 非贪婪模式:在整个表达式匹配成功的前提下,尽可能少的匹配(?);
- Python里数量词默认是贪婪的。
实例一:源字符串:abbbc
- 使用贪婪的数量词的正则表达式
ab+,匹配结果:abbb。 *决定了尽可能多匹配b,所以a后面所有的b都出现了。 - 使用非贪婪的数量词的正则表达式
ab*?,匹配结果:a。 即使前面有*,但是?决定了尽可能少匹配b,所以没有b。
实例二:源字符串:aa<div>test1</div>bb<div>test2</div>cc
- 使用贪婪的数量词的正则表达式:
<div>.*</div> - 匹配结果:
<div>test1</div>bb<div>test2</div>这里采用的是贪婪模式。在匹配到第一个“</div>”时已经可以使整个表达式匹配成功,但是由于采用的是贪婪模式,所以仍然要向右尝试匹配,查看是否还有更长的可以成功匹配的子串。匹配到第二个“</div>”后,向右再没有可以成功匹配的子串,匹配结束,匹配结果为“<div>test1</div>bb<div>test2</div>” - 使用非贪婪的数量词的正则表达式:
<div>.*?</div> - 匹配结果:
<div>test1</div>正则表达式二采用的是非贪婪模式,在匹配到第一个“</div>”时使整个表达式匹配成功,由于采用的是非贪婪模式,所以结束匹配,不再向右尝试,匹配结果为“<div>test1</div>”。
更多Python的学习资料可以扫描下方二维码无偿领取!!!

1)Python所有方向的学习路线(新版)
总结的Python爬虫和数据分析等各个方向应该学习的技术栈。

比如说爬虫这一块,很多人以为学了xpath和PyQuery等几个解析库之后就精通的python爬虫,其实路还有很长,比如说移动端爬虫和JS逆向等等。
(2)Python学习视频
包含了Python入门、爬虫、数据分析和web开发的学习视频,总共100多个,虽然达不到大佬的程度,但是精通python是没有问题的,学完这些之后,你可以按照我上面的学习路线去网上找其他的知识资源进行进阶。

(3)100多个练手项目
我们在看视频学习的时候,不能光动眼动脑不动手,比较科学的学习方法是在理解之后运用它们,这时候练手项目就很适合了,只是里面的项目比较多,水平也是参差不齐,大家可以挑自己能做的项目去练练。

。