基本操作
创建不同的分词器
ik_smart: 极简分词 ; ik_max_word: 最细力再度分词


基本的rest命令
| method | url地址 | 描述 |
|---|---|---|
| PUT | localhost:9200/索引名称/类型名称/文档id | 创建文档(指定文档id) |
| POST | localhost:9200/索引名称/类型名称 | 创建文档(随机文档id) |
| POST | localhost:9200/索引名称/类型名称/文档id/_update | 修改文档 |
| DELETE | localhost:9200/索引名称/类型名称/文档id | 删除文档 |
| GET | localhost:9200/索引名称/类型名称/文档id | 查询文档通过文档id |
| POST | localhost:9200/索引名称/类型名称/_search | 查询所有数据 |
索引基本操作
查询所有索引

Elasticsearch 7.x 版本
# 返回一个仅包含索引名称的 JSON 数组
GET /_cat/indices?format=json&h=index
扩展:获取ES的其他信息
GET _cat/health # 查看健康值
GET _cat/indices?v #查看所有东西的版本信息
新增索引
# ElasticSearch的7.x.x版本 PUT /索引名/类型名/文档id { 请求体 }# 创建索引
PUT test1 { "mappings": { "properties": { "name": { "type": "text" }, "age":{ "type": "integer" } } } }# 创建加索引时同时添加数据,es会自动给属性设置type # ElasticSearch的8.x.x版本,类型已经弃用,默认写_doc。 PUT /索引名/_doc/文档id { 请求体 } PUT test1/_doc/1 { "name":"小明", "age":23 } # ElasticSearch的8.x.x版本,类型已经弃用,默认写_doc。 PUT /索引名/_doc/文档id { 请求体 }
CreateIndexRequest request = new CreateIndexRequest(INDEX);
CreateIndexResponse response = client.indices().create(request, RequestOptions.DEFAULT);查看索引

name需要指定类型
官网类型文档地址:Keyword type family | Elasticsearch Guide [8.9] | Elastic
字符串类型 text、keyword
数值类型 long,integer,short,byte,double,float,half float,scaled float
日期类型 date
te布尔值类型 boolean·
二进制类型 binary
等等……
设置字段类型

修改索引
索引是不可修改的。一旦创建了索引,您不能直接修改其结构或字段的映射。如果要修改索引的结构,您需要重新创建索引并重新索引数据。
POST _reindex { "source": { "index": "your_old_index" }, "dest": { "index": "new_index" } }新索引和旧索引的字段不一定需要完全一致。在重新创建索引和重新索引数据时,可以对字段进行修改、删除或添加新的字段。
如果字段在新索引中已经存在,则该字段的映射将被保留。如果字段在新索引中不存在,则会根据重新索引的数据动态创建字段的映射。
例如,假设旧索引中有一个 "field1" 字段,而新索引中没有。在重新索引数据时,如果数据中存在 "field1" 字段,Elasticsearch 将自动创建该字段的映射并将其添加到新索引中。
同样地,如果旧索引中存在一个 "field2" 字段,而新索引中也有一个名为 "field2" 的字段,那么在重新索引数据时,新索引中的 "field2" 字段的映射将保留不变。
需要注意的是,如果字段在新索引和旧索引中具有不兼容的类型或映射定义,可能会导致数据转换或丢失。因此,在进行索引结构修改时,请确保对数据和字段映射的变化有充分的了解和计划。
删除索引

关于文档的基本操作
基本操作
添加数据
PUT /index/_doc/1
{
"name": "狂神说",
"age": 3,
"desc": "工资2500",
"tags": ["直男","温暖","技术宅"]
}
PUT /index/_doc/2
{
"name": "张三",
"age": 30,
"desc": "没有工资",
"tags": ["渣男","旅游","交友"]
}查询数据
# 查询索引下,对应文档ID的数据 GET /index/_doc/1 GET /index/_doc/2

更新 PUT(不推荐)
PUT 修改数据,需要全属性字段都存在,否则会丢失缺失的属性字段
# 修改数据
put index/_doc/1
{
"name": "杨光1",
"age": 3,
"desc": "工资2500",
"tags": ["直男","温暖","技术宅"]
}
# PUT 修改时,会更新该ID下的所有字段,如果缺失字段,则会删除原有字段
put index/_doc/1
{
"name": "杨光1",
"age": 3,
"desc": "工资2500"
}
更新 POST(推荐)
# POST 更新,会修改该文档ID下对应属性的值
POST index/_update/1
{
"doc": {
"name":"杨光3"
}
}
# POST 更新,会修改该文档ID下对应属性的值,不推荐这样写,ES8执行不支持这种语法
POST index/_doc/1/_update
{
"doc": {
"name":"杨光4"
}
} 
条件查询
PUT /index/_doc/1
{
"name": "杨光",
"age": 3,
"desc": "工资2500",
"tags": ["直男","温暖","技术宅"]
}
PUT /index/_doc/2
{
"name": "张三",
"age": 30,
"desc": "没有工资",
"tags": ["渣男","旅游","交友"]
}
# 根据name查询
GET index/_search?q=name:张三
PUT index
{
"mappings": {
"properties": {
"name":{
"type": "keyword"
},
"xm":{
"type": "text",
"analyzer": "ik_smart"
},
"age":{
"type": "integer"
},
"desc":{
"type": "text"
},
"tags":{
"type": "text"
}
}
}
}
# 测试数据
PUT /index/_doc/1
{
"name": "杨光",
"xm": "杨光",
"age": 3,
"desc": "工资2500",
"tags": ["直男","温暖","技术宅"]
}
PUT /index/_doc/2
{
"name": "张三",
"xm": "张三",
"age": 30,
"desc": "没有工资",
"tags": ["渣男","旅游","交友"]
}
PUT /index/_doc/3
{
"name": "李三",
"xm": "李三",
"age": 23,
"desc": "工资5000",
"tags": ["健身","旅游","购物"]
}
PUT /index/_doc/4
{
"name": "张三丰",
"xm": "张三丰",
"age": 10,
"desc": "工资5000",
"tags": ["健身","旅游","购物"]
}
PUT /index/_doc/5
{
"name": "张",
"xm": "张",
"age": 10,
"desc": "工资5000",
"tags": ["健身","旅游","购物"]
}
PUT /index/_doc/6
{
"name": "三",
"xm": "三",
"age": 10,
"desc": "工资5000",
"tags": ["健身","旅游","购物"]
}match和term
Match查询和Term查询是Elasticsearch中常用的查询类型,它们有以下区别:
匹配方式:
Term查询:对查询条件不进行分词,直接按照完全匹配的方式进行查询。
Match查询:对查询条件进行分词,然后对分词后的词项进行匹配。
查询字段类型:
Term查询:适用于精确匹配的字段,如关键字(keyword)类型或未分词的文本类型(如"张三",不会被分词)。
Match查询:适用于全文本字段,如全文本(text)类型或已分词的文本类型(如"张三 张三",会被分词成两个词项"张三")。
匹配精度:
Term查询:精确匹配,只有完全匹配的词项才会被返回。
Match查询:默认为词项级别的匹配,可以根据分析器的分词规则进行模糊匹配。
执行效率:
Term查询:由于不进行分词,查询速度较快。
Match查询:需要对查询条件进行分词,可能会影响查询性能。
根据具体的查询需求,选择合适的查询类型可以提高查询的准确性和效率。如果需要精确匹配的查询,且不需要分词,可以选择Term查询;如果需要对分词后的文本进行匹配,可以选择Match查询。
match查询
# match 查询时,会对查询条件先分词
# 而name字段类型为keyword,不会分词,所以只能搜到name=张三的数据
GET index/_search
{
"query": {
"match": {
"name": "张三"
}
},
"_source": ["name","xm"]
}
# match 查询,会对查询条件先分词
# xm字段类型为text,用ik_max_smart分词,会分词,所以只能搜到文档xm字段分词后,结果为张三分词后的所有数据
GET index/_search
{
"query": {
"match": {
"xm": "张三"
}
},
"_source": ["name","xm"]
}


term查询
# term 查询时,不会对查询条件进行分词,name为keyword,所以只能完全匹配
GET index/_search
{
"query": {
"term": {
"name": "张三"
}
}
}
# term 查询,不会对查询条件进行分词
# xm字段类型为text,用ik_max_smart分词,会分词,所以能查到文档分词后为张三的数据
GET index/_search
{
"query": {
"term": {
"xm": "张三"
}
},
"_source": ["name","xm"]
}

过滤字段查询
# 查询结果只展示 name和xm两个字段
GET index/_search
{
"_source": ["name","xm"]
}
排序
# 查询结果排序
GET index/_search
{
"_source": ["name", "age"],
"sort": [
{
"age": {
"order": "desc"
}
}
]
}
分页查询
# 分页查询
GET index/_search
{
"_source": ["name", "age"],
"from": 0,
"size": 2
}
多条件查询(布尔值查询)
must
类似sql中的 and
# 查询 name = 张三 并且 age = 30
GET index/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"name": "张三"
}
},
{
"match": {
"age": "30"
}
}
]
}
}
}should
类似sql中的 or
# 查询 name = 张三 或者 name = 李三
GET index/_search
{
"query": {
"bool": {
"should": [
{
"match": {
"name": "张三"
}
},
{
"match": {
"name": "李三"
}
}
]
}
}
}
must_not
类似sql中的 not in
# 查询 name != 张三 并且 name != 李三
GET index/_search
{
"query": {
"bool": {
"must_not": [
{
"match": {
"name": "张三"
}
},
{
"match": {
"name": "李三"
}
}
]
}
}
}
filter
在Elasticsearch中,过滤器(Filter)是一种用于精确筛选文档的查询子句,主要用于限制搜索结果的范围。与查询(Query)不同,过滤器不会评分和排序结果,而是根据指定的条件进行筛选。这可以提高查询性能,特别是在过滤大量文档的情况下。
过滤器可以用于各种条件,如范围查询、存在性检查、逻辑运算等。常见的过滤器类型包括:
Term Filter:根据指定的词项进行精确匹配筛选。
Range Filter:通过指定的范围进行筛选,可以用于数值、日期等字段。
Exists Filter:检查字段是否存在于文档中。
Bool Filter:通过逻辑运算符(AND、OR、NOT)对其他过滤器进行组合。
Geo Distance Filter:通过指定的地理位置和距离范围进行地理位置过滤。
Script Filter:使用自定义脚本进行筛选。
过滤器可以单独使用,也可以与查询结合使用。如果需要对搜索结果进行精确的筛选,并且不需要评分和排序,建议使用过滤器来提高查询性能。
# 查询xm=张三,并且age < 30 且 age >= 10 ,并且age 倒序
GET index/_search
{
"_source": ["xm","age"],
"query": {
"bool": {
"must": [
{
"match": {
"xm": "张三"
}
}
],
"filter": [
{
"range": {
"age": {
"gte": 10,
"lt": 30
}
}
}
]
}
},"sort": [
{
"age": {
"order": "desc"
}
}
]
}
# 查询xm=张三,并且age < 30 且 age >= 10 ,并且 xm 字段值
GET index/_search
{
"_source": ["xm","age"],
"query": {
"bool": {
"must": [
{
"match": {
"xm": "张三"
}
}
],
"filter": [
{
"range": {
"age": {
"gte": 10,
"lt": 30
}
}
},
{
"exists": {
"field": "xm"
}
}
]
}
}
}

高亮查询
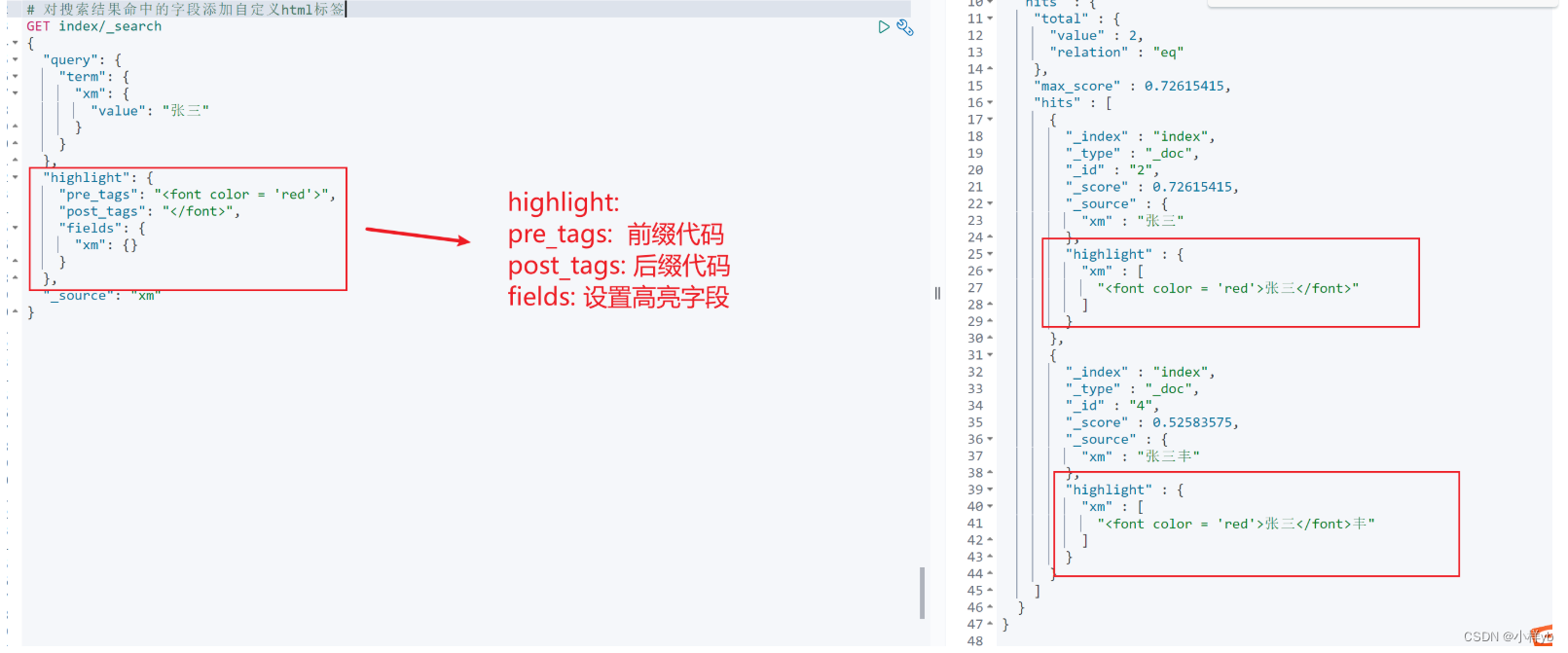
# 对搜索结果命中的字段添加自定义html标签
GET index/_search
{
"query": {
"term": {
"xm": {
"value": "张三"
}
}
},
"highlight": {
"pre_tags": "<font color = 'red'>",
"post_tags": "</font>",
"fields": {
"xm": {}
}
},
"_source": "xm"
}