实现功能
建立AdaBoost模型(集成学习)预测肾脏疾病
实现代码
import pandas as pd
import warnings
warnings.filterwarnings("ignore")
pd.set_option('display.max_columns', 26)
#==========================读取数据======================================
df = pd.read_csv("E:\数据杂坛\datasets\kidney_disease.csv")
df=pd.DataFrame(df)
pd.set_option('display.max_rows', None)
pd.set_option('display.width', None)
df.drop("id",axis=1,inplace=True)
print(df.head())
print(df.dtypes)
df["classification"] = df["classification"].apply(lambda x: x if x == "notckd" else "ckd")
# 分类型变量名
cat_cols = [col for col in df.columns if df[col].dtype == "object"]
# 数值型变量名
num_cols = [col for col in df.columns if df[col].dtype != "object"]
# ========================缺失值处理============================
def random_value_imputate(col):
"""
函数:随机填充方法(缺失值较多的字段)
"""
# 1、确定填充的数量;在取出缺失值随机选择缺失值数量的样本
random_sample = df[col].dropna().sample(df[col].isna().sum())
# 2、索引号就是原缺失值记录的索引号
random_sample.index = df[df[col].isnull()].index
# 3、通过loc函数定位填充
df.loc[df[col].isnull(), col] = random_sample
def mode_impute(col):
"""
函数:众数填充缺失值
"""
# 1、确定众数
mode = df[col].mode()[0]
# 2、fillna函数填充众数
df[col] = df[col].fillna(mode)
for col in num_cols:
random_value_imputate(col)
for col in cat_cols:
if col in ['rbc','pc']:
# 随机填充
random_value_imputate('rbc')
random_value_imputate('pc')
else:
mode_impute(col)
# ======================特征编码============================
from sklearn.preprocessing import MinMaxScaler
mms = MinMaxScaler()
df[num_cols] = mms.fit_transform(df[num_cols])
from sklearn.preprocessing import LabelEncoder
led = LabelEncoder()
for col in cat_cols:
df[col] = led.fit_transform(df[col])
print(df.head())
#===========================数据集划分===============================
X = df.drop("classification",axis=1)
y = df["classification"]
from sklearn.utils import shuffle
df = shuffle(df)
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.20, random_state = 0)
#===========================建模=====================================
from sklearn.metrics import accuracy_score, confusion_matrix, classification_report
def create_model(model):
# 模型训练
model.fit(X_train, y_train)
# 模型预测
y_pred = model.predict(X_test)
# 准确率acc
acc = accuracy_score(y_test, y_pred)
# 混淆矩阵
cm = confusion_matrix(y_test, y_pred)
# 分类报告
cr = classification_report(y_test, y_pred)
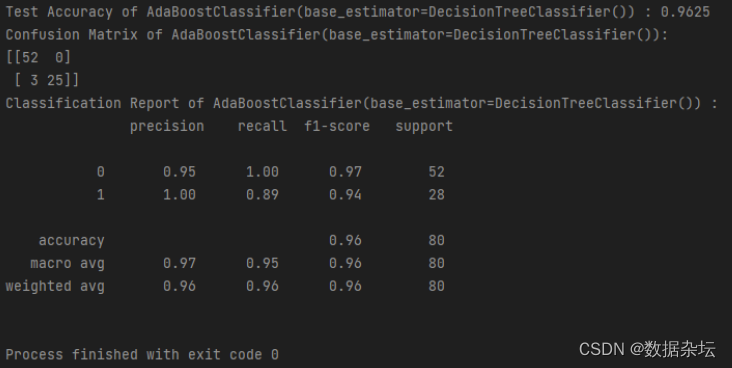
print(f"Test Accuracy of {model} : {acc}")
print(f"Confusion Matrix of {model}: \n{cm}")
print(f"Classification Report of {model} : \n {cr}")
from sklearn.ensemble import AdaBoostClassifier
from sklearn.tree import DecisionTreeClassifier
dt = DecisionTreeClassifier()
ada = AdaBoostClassifier(base_estimator = dt)
create_model(ada)实现效果
本人读研期间发表5篇SCI数据挖掘相关论文,现在某研究院从事数据挖掘相关科研工作,对数据挖掘有一定认知和理解,会结合自身科研实践经历不定期分享关于python机器学习、深度学习、数据挖掘基础知识与案例。
致力于只做原创,以最简单的方式理解和学习,关注我一起交流成长。
关注V订阅号:数据杂坛,即可在后台联系我获取相关数据集和源码,送有关数据分析、数据挖掘、机器学习、深度学习相关的电子书籍。