对于超大数据量的接口来说,如果前端直接一股脑的渲染出来,必然会导致渲染超时、操作卡顿、内存爆表、网页奔溃等情况,因此一般的对于大数据量的列表处理,无非就以下几种方式
- 采取分页的方式,减少每页的数量 比如每页10条
- 采取懒加载的方式,滚到底部再加载第二页数据(缺陷就是后面会越来越卡)
- 采用可见范围渲染的方式,这需要判断当且节点是否在可见范围(利用高度计算或者用IntersectionObserver)
- 采用虚拟列表的方式(原理就是切片+滚动 让用户察觉不到)
由于我们的业务需要每次查看成千上万条数据,并需要对行数据进行各种操作,如下图
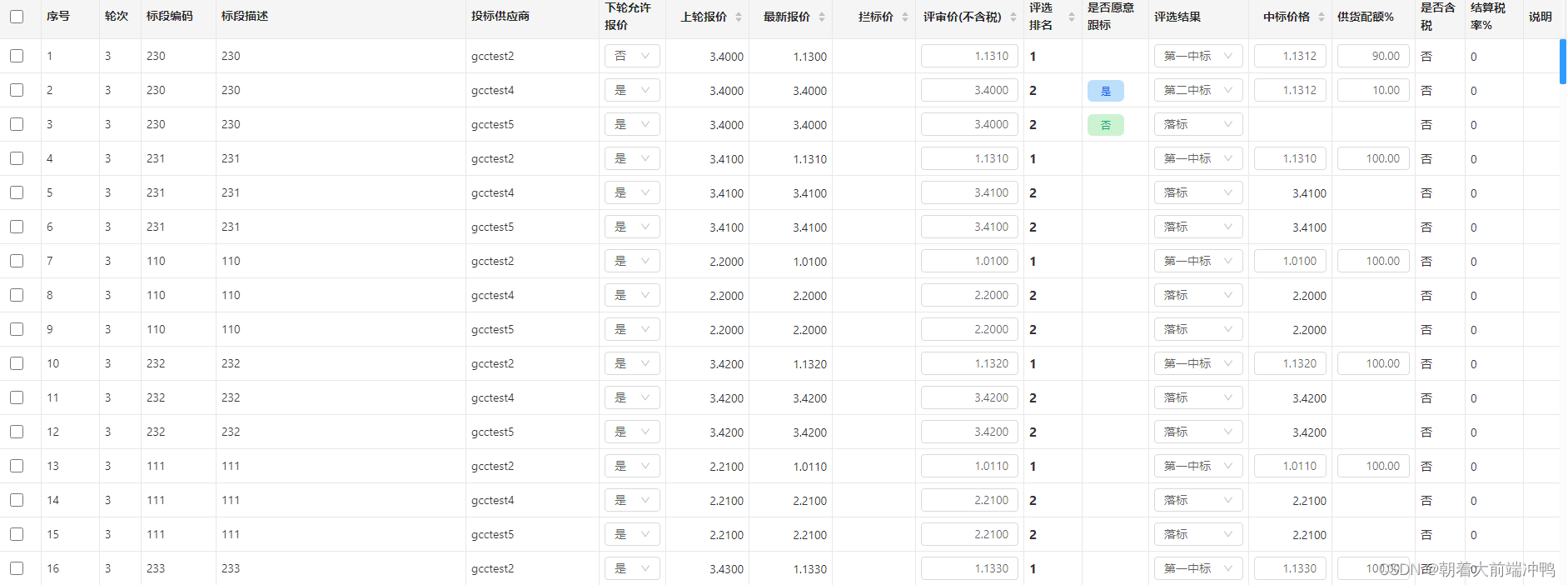
因此用分页是不满足需求的,一开始我也是直接采用渲染的方式,结果就是
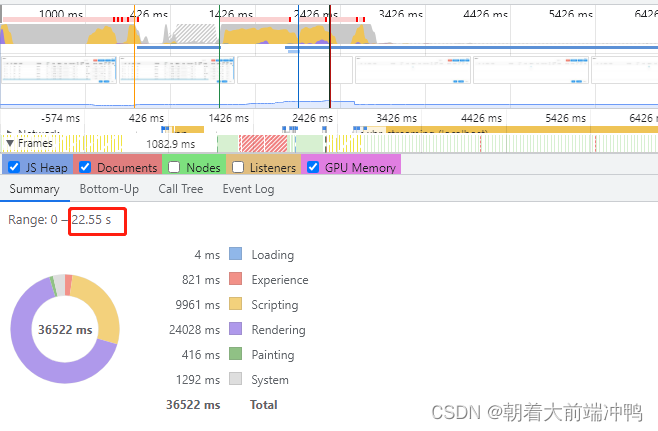
![]()
这种结果肯定达不到上线的性能要求的,经过对比 我决定采用虚拟列表+滚动分页加载数据的方式来处理,最终优化后的性能达到2s内渲染完成。下面就将改造步骤和遇到的问题跟大家进行分享。
首先跟大家简单讲讲虚拟列表的原理,这里借用下网络上大神总结的图
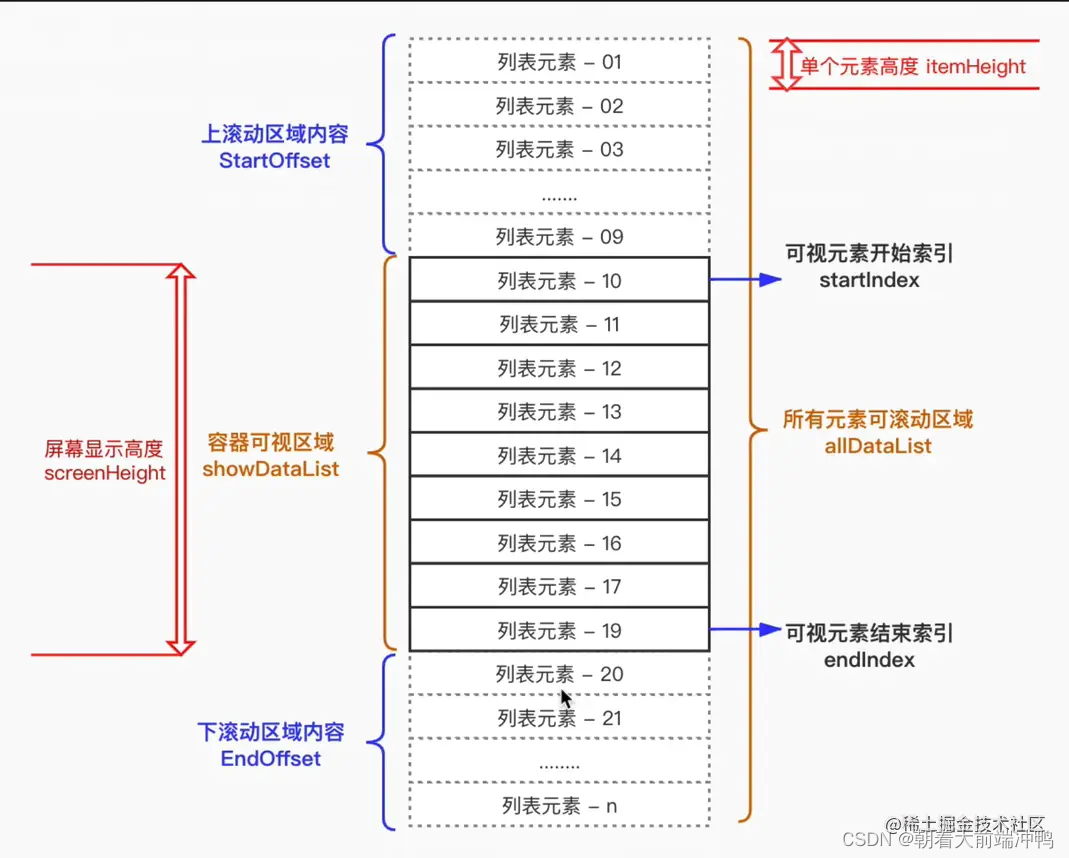
简单说就是将大数据切片成只显示在可见范围内的一小段,然后结合容器的滚动事件不断地改变前后下标从而切割大数据,再结合缓冲区和填充以及requestAnimationFrame等api的运用让滚动更丝滑,让用户无感。
那具体怎么做呢?
- 获取容器元素
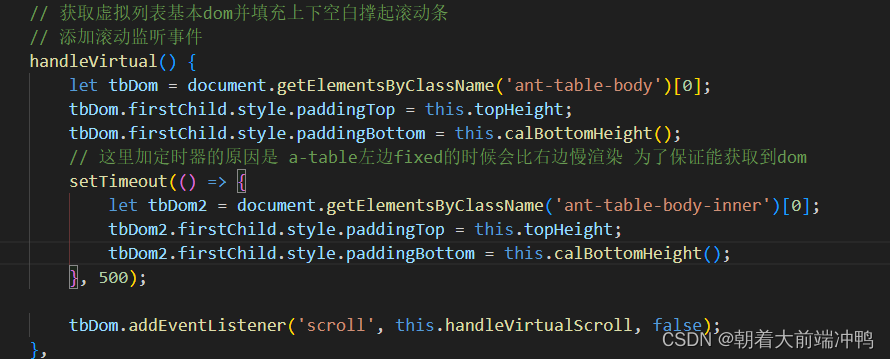
- 计算容器可视高度及上下padding 从而撑开容器
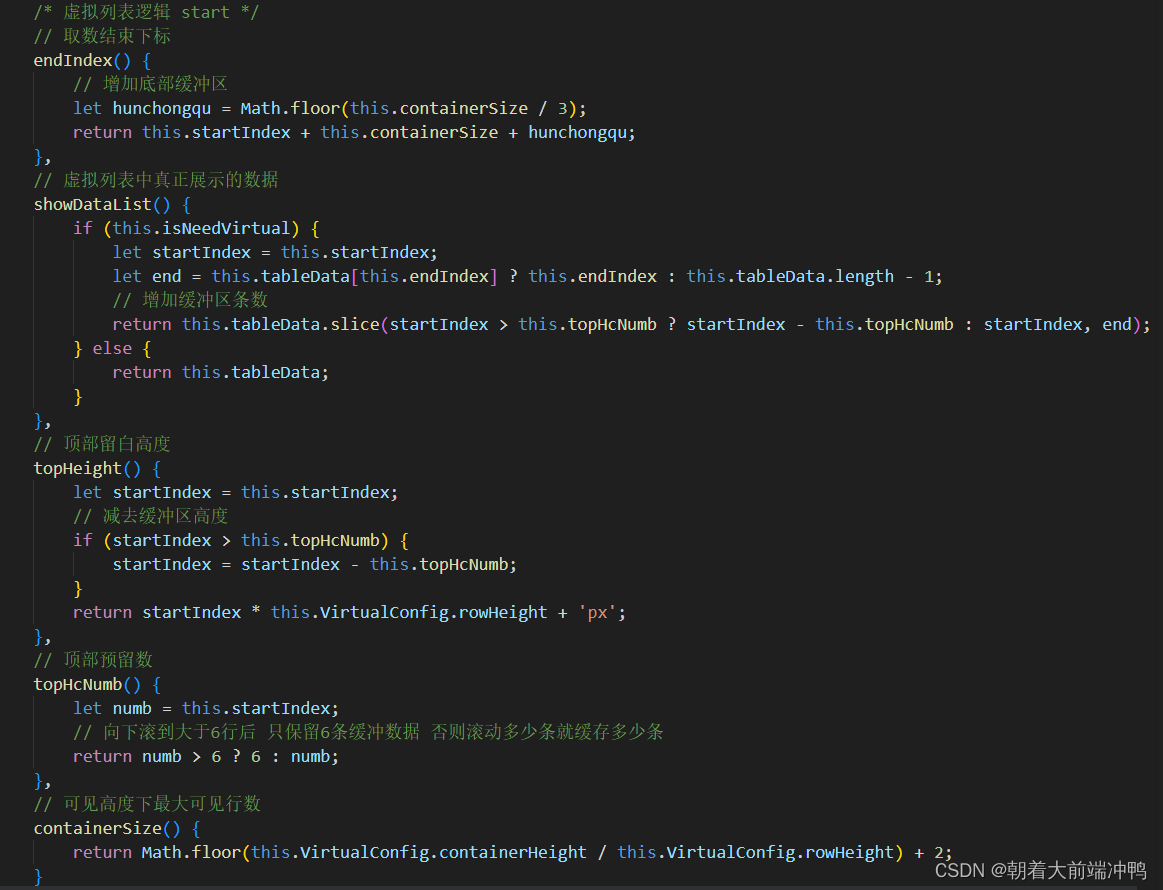

- 监听容器的滚动事件,滚动的时候不断修改startIndex 和endIndex
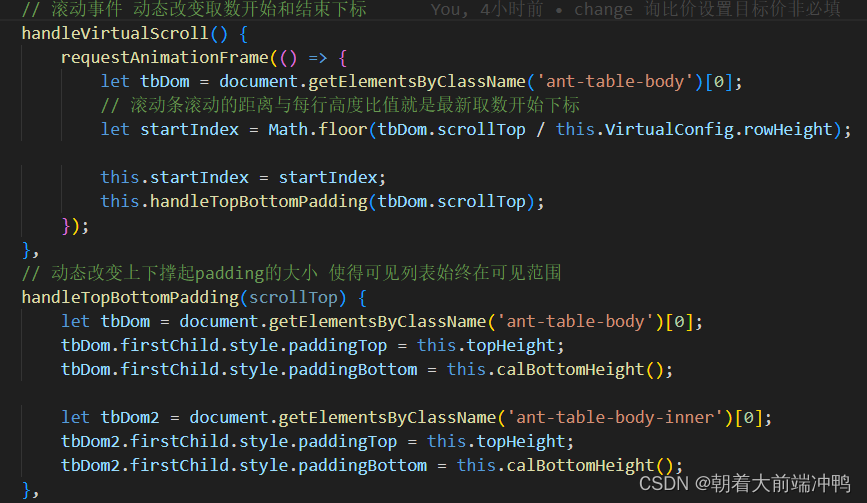
以上都完成就能实现基本的虚拟滚动了,这里为了解决快速滚动出现白屏现象,采用了缓冲区的方式,往下滚动时设置了Math.floor(this.containerSize / 3)范围的缓冲,向上滚动的时候采用了startIndex>6就为6行缓存。同时解决全选和排序等table原有的功能。
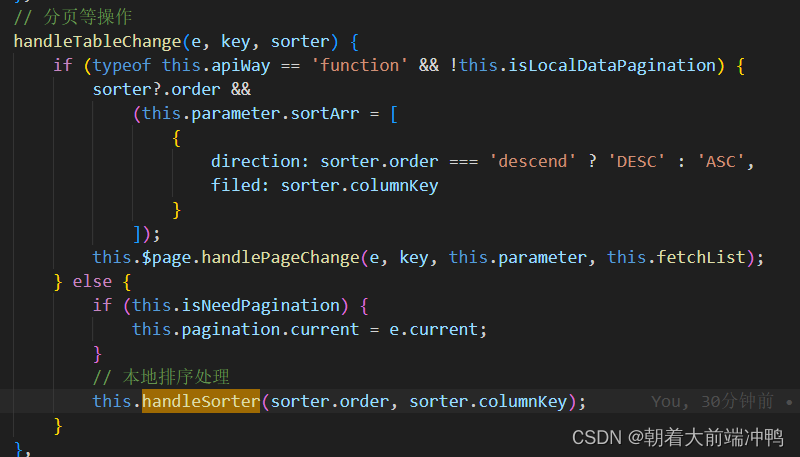
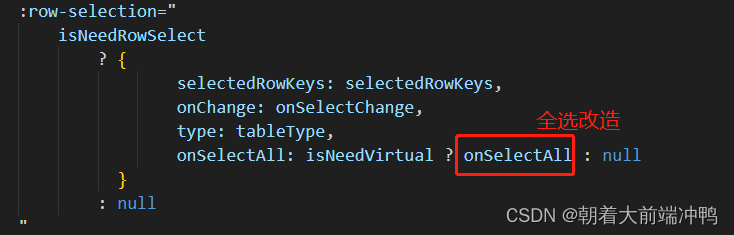
改造了table的onChange方法:
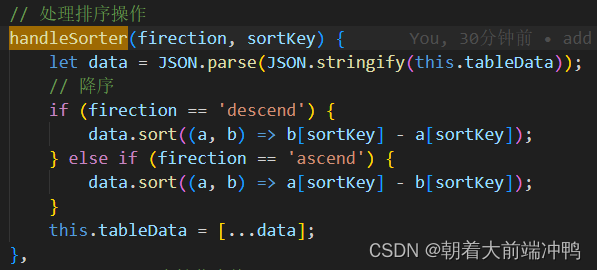
排序:
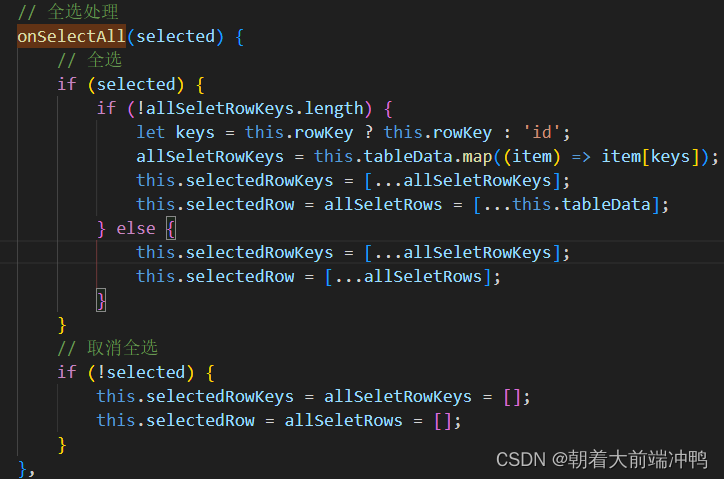
全选:
首先定义了两个变量来存储全选的key和rows数据

其次通过onSelectAll事件来判断是否点击了全选按钮
那么我们怎么判断是否滚动到了当前数据的底部,从而再次获取数据呢?我的思路就是判断endIndex是否大于或等于了tableData.length 当然为了保证在一定高度就去请求新数据 我们这里不能直接判断 而应该使用一个缓冲数 比如 tableData.length-endIndex >=4 距离底部还有4行的时候就去请求数据,从而优化体验。具体代码就交给大家 自己实现啦,相信你一定行
至于table里每行的操作,比如input select radio 等如何保证修改后能保存呢,这里我充分利用了数组的浅拷贝,就是响应式的数据+computed+v-model 修改后依然会修改原数组的值 从而不需要在每行的input都增加@change事件,省了一大堆代码

看看chatGPT的解释



![数字孪生工厂分享交流方案[53页PPT]](https://img-blog.csdnimg.cn/img_convert/652182aca6d1bf06b83ce7b1ab212fb6.jpeg)