继Stable Diffusion爆火之后,StabilityAI近期又放大招,推出了号称是革命性的编程大模型StableCode。StableCode是其首款用于编码的LLM生成式AI产品,该产品旨在帮助程序员完成日常工作。目前已发布的版本为StableCode-Completion-Alpha-3B,是一个包含30亿个参数的代码补全模型,针对多种编程语言进行了预训练,这些编程语言是基于2023年stackoverflow开发者调查的最常用语言。
StableCode模型特性StableCode模型的特色在于,能够理解和处理长篇幅上下文,也就是模型在做决策时,能够更广泛地考虑前后相邻的数据,也就是具有一次处理更多程序代码Token的能力,进而提供更精确有用的建议。官方提到,StableCode一次可以处理的程序代码Token为16000,是此前开源模型的2-4倍,用户能够一次处理的文件量,约是5个一般大小的Python文件。
StableCode模型训练分为三个阶段
- 最初Stability AI使用来自BigCode项目的stack-dataset v1.2数据集,对基础模型进行多语言训练。- 接着针对热门程序语言,诸如Python、Go、Java、Javascript、C、markdown和C++进行特化训练,总共使用了5,600亿个Token训练模型。- 基础模型创建完成后,官方进一步针对特定用途调校指令模型,以解决复杂的程序开发任务,在基础模型上训练了约12万个Alpaca格式的程序代码指令和回应数据对。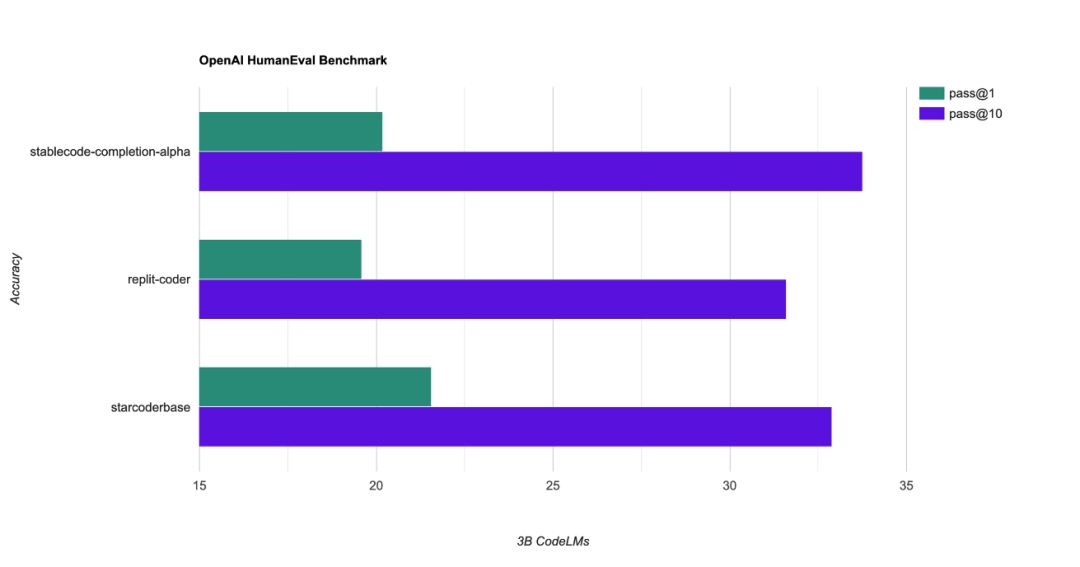
StableCode如何使用
StableCode模型旨在遵循指令来生成代码,用于训练模型的数据集采用羊驼格式。16K上下文
from transformers import AutoModelForCausalLM, AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("stabilityai/stablecode-completion-alpha-3b")
model = AutoModelForCausalLM.from_pretrained(
"stabilityai/stablecode-completion-alpha-3b",
trust_remote_code=True,
torch_dtype="auto",
)
model.cuda()
inputs = tokenizer("import torch\nimport torch.nn as nn", return_tensors="pt").to("cuda")
tokens = model.generate(
**inputs,
max_new_tokens=48,
temperature=0.2, do_sample=True,
)
print(tokenizer.decode(tokens[0], skip_special_tokens=True))
4K上下文
from transformers import AutoModelForCausalLM, AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("stabilityai/stablecode-completion-alpha-3b-4k")
model = AutoModelForCausalLM.from_pretrained(
"stabilityai/stablecode-completion-alpha-3b-4k",
trust_remote_code=True,
torch_dtype="auto",)
model.cuda()
inputs = tokenizer("import torch\nimport torch.nn as nn", return_tensors="pt").to("cuda")
tokens = model.generate(
**inputs, max_new_tokens=48,
temperature=0.2, do_sample=True,
)
print(tokenizer.decode(tokens[0], skip_special_tokens=True))
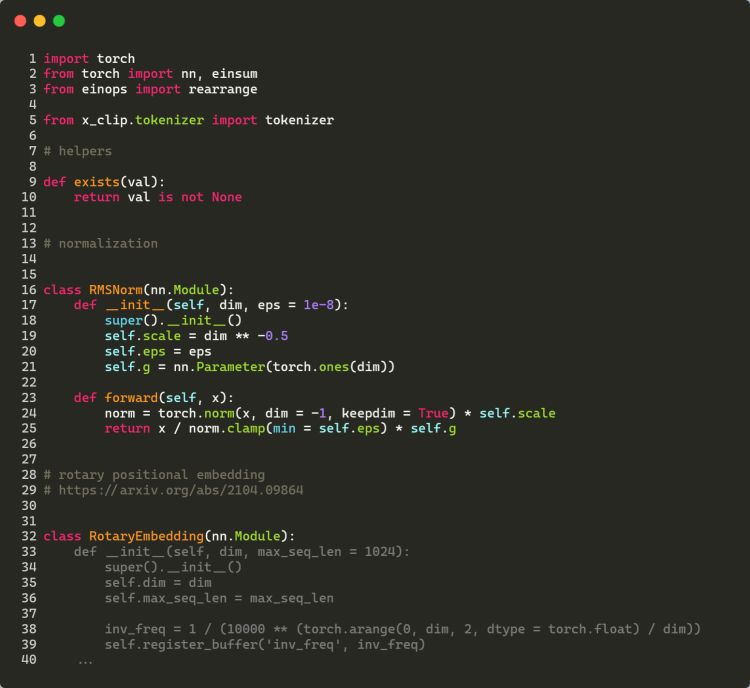
下面是一个StableCode利用Pytorch深度学习库完成一个相对复杂的Python文件展示(灰色文本显示了StableCode的预测)。