对象的内存布局
对象在堆内存中的存储布局可以划分为三个部分:对象头(Header)、实例数据(Instance Data)和对齐填充(Padding)。
ps:这个对象所属类的方法信息,静态变量是不存储在对象实例中的,没有必要。
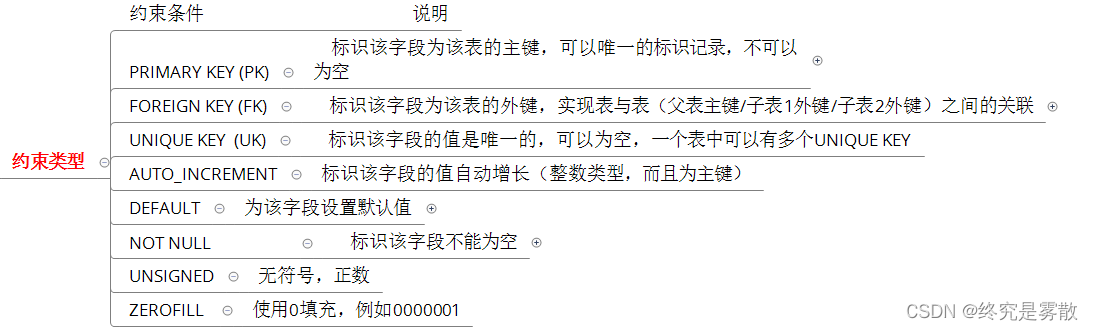
对象头
(类比http 请求头,不存储对象实际数据的)
其中对象头的内存布局如下图:

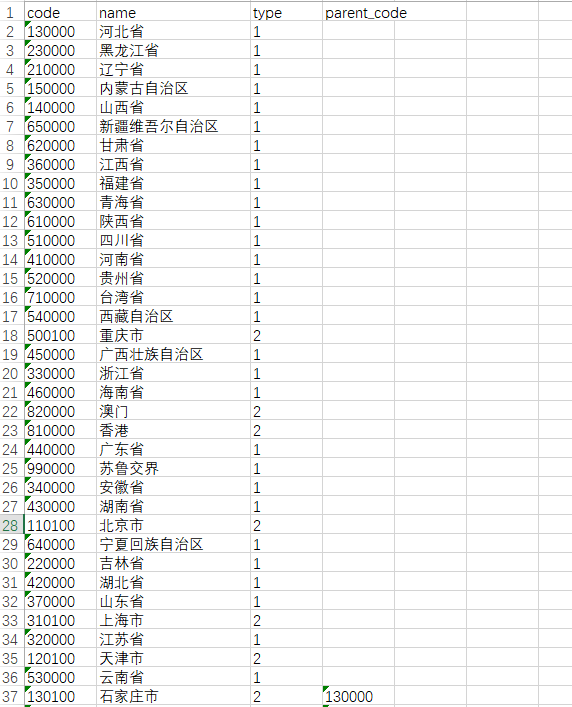
Mark Work
哈希码(HashCode)、GC分代年龄、锁状态标志、线程持有的锁、偏向线程ID、偏向时间戳等信息都存储在mar work。
考虑到虚拟机的空间效率,Mark Work 设计的比较巧妙(32或者64 的BitMap),它是动态的,目的极小的空间内存储尽量多的数据,根据对象的状态复用自己的存储空间。

Klass Work 和数组长度
Klass Work 是类型指针,即对象指向它的类型元数据的指针。Java虚拟机通过这个指针来确定该对象是哪个类的实例。并不是所有的虚拟机实现都必须在对象数据上保留类型指针,换句话说,查找对象的元数据信息并不一定要经过对象本身(下面会说到)
此外,如果对象是一个Java数组,那在对象头中还必须有一块用于记录数组长度的数据,因为虚拟机可以通过普通Java对象的元数据信息确定Java对象的大小,但是如果数组的长度是不确定的,将无法通过元数据中的信息推断出数组的大小。 所以如果对象为数组的话,还需要记录数组大小的一块存储空间。
实例数据
这部分是对象真正存储的有效信息,即我们在程序代码里面所定义的各种类型的字段内容,无论是从父类继承下来的,还是在子类中定义的字段都必须记录起来。
对齐填充
这并不是必然存在的,也没有特别的含义,它仅仅起着占位符的作用。由于HotSpot虚拟机的自动内存管理系统要求对象起始地址必须是8字节的整数倍,换句话说就是任何对象的大小都必须是8字节的整数倍。对象头部分已经被精心设计成正好是8字节的倍数,因此,如果对象实例数据部分没有对齐的话,就需要通过对齐填充来补全。
附:前面说到查找对象的元数据信息并不一定要经过对象本身。下面就说到了
我们知道平时我们在类中定义成员属性或者局部属性,在传递参数的时候是值传递,可以理解是把该属性的一个引用传递过去,通过这个引用(包含了定位信息),可以找到这个引用指向的对象在内存中的位置(也就是通过这个引用,可以访问对象)。
对象访问方式也是由虚拟机实现而定的,主流的访问方式主要有使用句柄和直接指针两种:
- 如果使用句柄访问的话,Java堆中将可能会划分出一块内存来作为句柄池,reference中存储的就是对象的句柄地址,而句柄中包含了对象实例数据与类型数据各自具体的地址信息

- 如果使用直接指针访问的话,Java堆中对象的内存布局就必须考虑如何放置访问类型数据的相关信息,reference中存储的直接就是对象地址,如果只是访问对象本身的话,就不需要多一次间接访问的开销
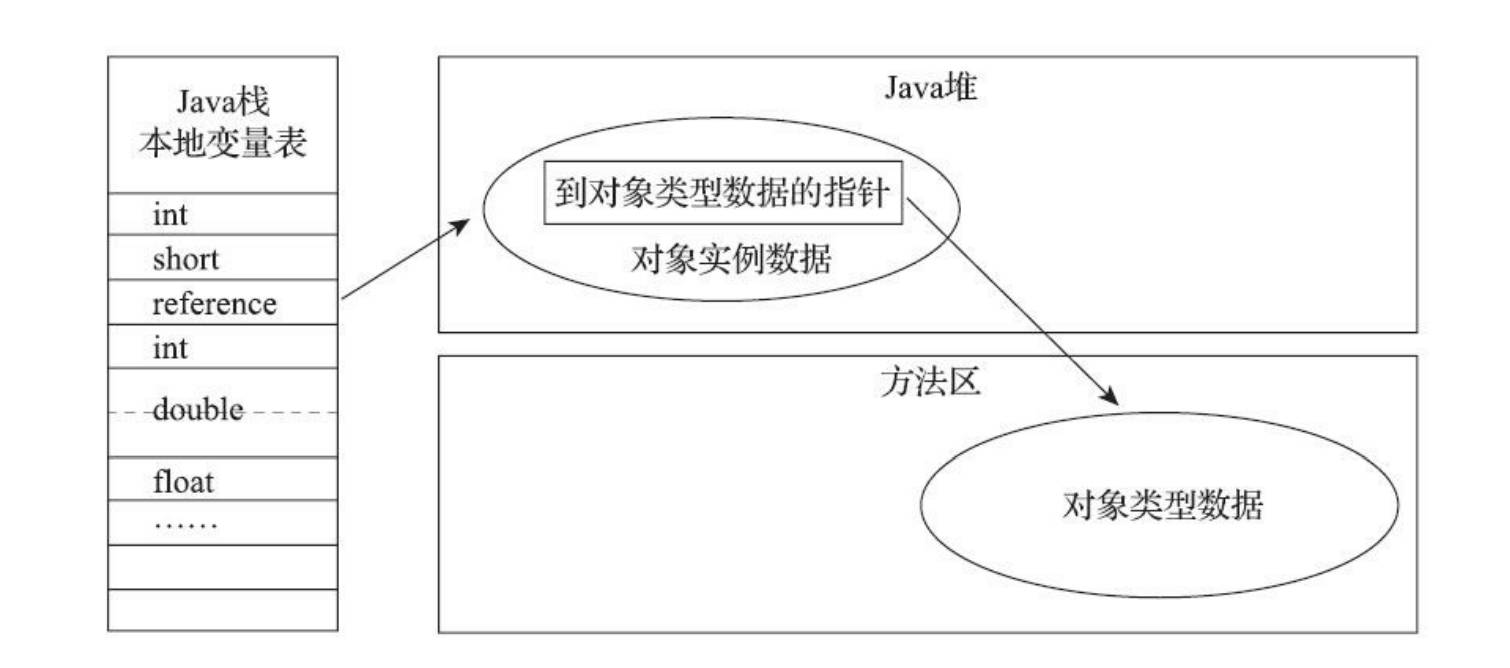
使用直接指针来访问最大的好处就是速度更快,它节省了一次指针定位的时间开销,由于对象访问在Java中非常频繁,因此这类开销积少成多也是一项极为可观的执行成本,就虚拟机HotSpot而言,它主要使用第二种方式进行对象访问(有例外情况,如果使用了Shenandoah收集器的话也会有一次额外的转发),但从整个软件开发的范围来看,在各种语言、框架中使用句柄来访问的情况也十分常见





![Java并发编程(二)并发理论[JMM/重排序/内存屏障/Happens-Before 规则]](https://img-blog.csdnimg.cn/e68f405fe4fa420fad74e04cdfe2fae1.png)