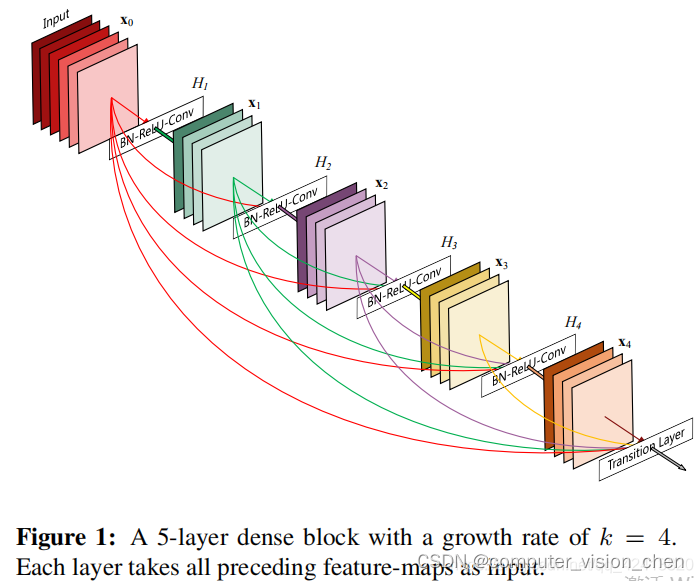
一.思想
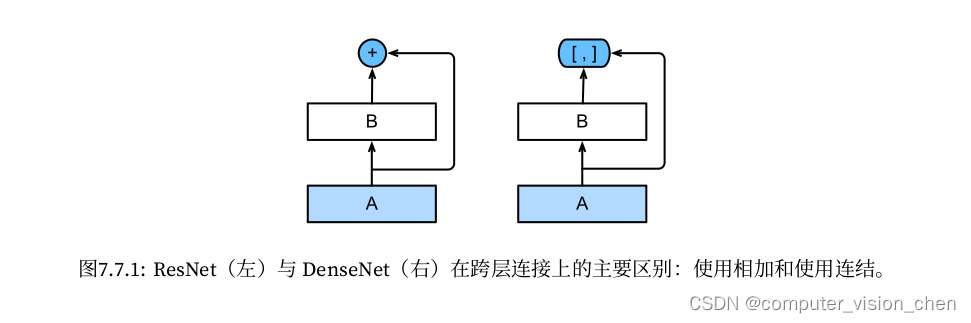
与ResNet的区别
DenseNet这样拼接有什么好处?DenseNet优点
对于每一层,使用前面所有层的特征映射作为输入,并且其自身的特征映射作为所有后续层的输入。
DenseNet的优点: 缓解了消失梯度问题,加强了特征传播,鼓励特征重用,并大大减少了参数的数量,改进了整个网络的信息流和梯度,这使得它们易于训练(这点与ResNet差不多)。
稠密连接的拼接方法
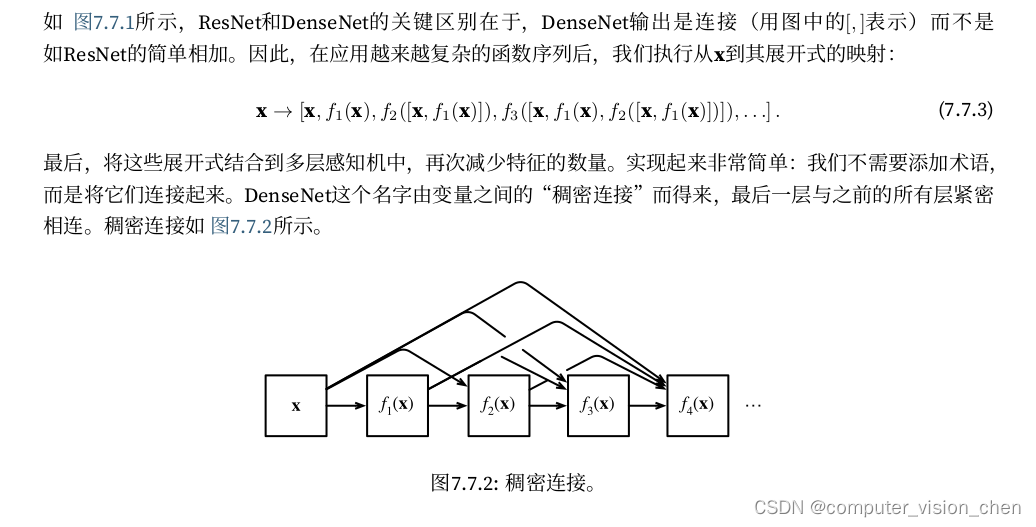
主要由稠密块和过渡层组成
稠密网络主要由2部分构成:稠密块(dense block)和过渡层(transition layer)。前者定义如何连接输入和输出,而后者则控制通道数量,使其不会太复杂。
二.代码
import torch
from torch import nn
from d2l import torch as d2l
import time
# 卷积块,后面的稠密块由多个卷积块组成
def conv_block(input_channels, num_channels):
return nn.Sequential(nn.BatchNorm2d(input_channels), nn.ReLU(),
nn.Conv2d(input_channels, num_channels, kernel_size=3, padding=1))
class DenseBlock(nn.Module):
def __init__(self, num_convs, input_channels, num_channels):
super(DenseBlock, self).__init__()
layer = []
# 一个稠密块由多个卷积块组成,每个卷积块使用相同数量的输出通道。
for i in range(num_convs):
layer.append(conv_block(
num_channels * i + input_channels, num_channels))
self.net = nn.Sequential(*layer)
# 在前向传播中,我们将每个卷积块的输入和输出在通道维上连结。
def forward(self, X):
for blk in self.net:
Y = blk(X)
# 连接通道维度上每个块的输入和输出
X = torch.cat((X, Y), dim=1)
return X
# 定义一个有2个输出通道数为10的DenseBlock。使用通道数为3的输入时,我们会得到通道数为3 + 2 × 10 = 23的输出。卷积块的通道数控制了输出通道数相对于输入通道数的增⻓
blk = DenseBlock(2, 3, 10)
X = torch.randn(4, 3, 8, 8)
Y = blk(X)
Y.shape
torch.Size([4, 23, 8, 8])
# 定义一个有2个输出通道数为10的DenseBlock。使用通道数为3的输入时,我们会得到通道数为3 + 2 × 10 = 23的输出。卷积块的通道数控制了输出通道数相对于输入通道数的增⻓
blk = DenseBlock(2, 3, 10)
X = torch.randn(4, 3, 8, 8)
Y = blk(X)
Y.shape
torch.Size([4, 23, 8, 8])
'''
由于每个稠密块都会带来通道数的增加,使用过多则会过于复杂化模型。而过渡层可以用来控制模型复杂度。
它通过1 × 1卷积层来减小通道数,并使用步幅为2的平均汇聚层减半高和宽,从而进一步降低模型复杂度。
'''
def transition_block(input_channels, num_channels):
return nn.Sequential(nn.BatchNorm2d(input_channels), nn.ReLU(),
# 1x1的卷积层
nn.Conv2d(input_channels, num_channels, kernel_size=1),
nn.AvgPool2d(kernel_size=2, stride=2)
)
blk = transition_block(23, 10) # 如输入通道23,让它输出通道为10
blk(Y).shape
torch.Size([4, 10, 4, 4])
# 我们来构造DenseNet模型。DenseNet首先使用同ResNet一样的单卷积层和最大汇聚层。
b1 = nn.Sequential(
nn.Conv2d(1, 64, kernel_size=7, stride=2, padding=3),
nn.BatchNorm2d(64), nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
)
'''
类似于ResNet使用的4个残差块,DenseNet使用的是4个稠密块。与ResNet类似,我们可以设置每个
稠密块使用多少个卷积层。这里我们设成4,从而与 7.6节的ResNet-18保持一致。稠密块里的卷积层通道数(即增⻓率)设为32,所以每个稠密块
将增加128个通道。在每个模块之间,ResNet通过步幅为2的残差块减小高和宽,DenseNet则使用过渡层来减半高和宽,并减半通道数。
'''
# num_channels为当前的通道数
num_channels, growth_rate = 64, 32
num_convs_in_dense_blocks = [4, 4, 4, 4]
blks = []
for i, num_convs in enumerate(num_convs_in_dense_blocks):
blks.append(DenseBlock(num_convs, num_channels, growth_rate))
# 上一个稠密块的输出通道数
num_channels += num_convs * growth_rate
# 在稠密块之间添加一个转换层,使通道数量减半
if i != len(num_convs_in_dense_blocks) - 1:
blks.append(transition_block(num_channels, num_channels // 2))
num_channels = num_channels // 2
# 与ResNet类似,最后接上全局汇聚层和全连接层来输出结果。
net = nn.Sequential(
b1, *blks,
nn.BatchNorm2d(num_channels), nn.ReLU(),
nn.AdaptiveAvgPool2d((1, 1)),
nn.Flatten(),
nn.Linear(num_channels, 10))
# 库中的函数没有取最优的准确率,自己实现一个
def train_ch6(net, train_iter, test_iter, num_epochs, lr, device):
"""Train a model with a GPU (defined in Chapter 6).
Defined in :numref:`sec_lenet`"""
def init_weights(m):
if type(m) == nn.Linear or type(m) == nn.Conv2d:
nn.init.xavier_uniform_(m.weight)
net.apply(init_weights)
print('training on', device)
net.to(device)
optimizer = torch.optim.SGD(net.parameters(), lr=lr)
loss = nn.CrossEntropyLoss()
animator = d2l.Animator(xlabel='epoch', xlim=[1, num_epochs],
legend=['train loss', 'train acc', 'test acc'])
timer, num_batches = d2l.Timer(), len(train_iter)
best_test_acc = 0
for epoch in range(num_epochs):
# Sum of training loss, sum of training accuracy, no. of examples
metric = d2l.Accumulator(3)
net.train()
for i, (X, y) in enumerate(train_iter):
timer.start()
optimizer.zero_grad()
X, y = X.to(device), y.to(device)
y_hat = net(X)
l = loss(y_hat, y)
l.backward()
optimizer.step()
with torch.no_grad():
metric.add(l * X.shape[0], d2l.accuracy(y_hat, y), X.shape[0])
timer.stop()
train_l = metric[0] / metric[2]
train_acc = metric[1] / metric[2]
if (i + 1) % (num_batches // 5) == 0 or i == num_batches - 1:
animator.add(epoch + (i + 1) / num_batches,
(train_l, train_acc, None))
test_acc = d2l.evaluate_accuracy_gpu(net, test_iter)
if test_acc>best_test_acc:
best_test_acc = test_acc
animator.add(epoch + 1, (None, None, test_acc))
print(f'loss {train_l:.3f}, train acc {train_acc:.3f}, '
f'test acc {test_acc:.3f}, best test acc {best_test_acc:.3f}')
# 取的好像是平均准备率
print(f'{metric[2] * num_epochs / timer.sum():.1f} examples/sec '
f'on {str(device)}')
'''开始计时'''
start_time = time.time()
lr, num_epochs, batch_size = 0.1, 10, 256
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size, resize=96)
train_ch6(net, train_iter, test_iter, num_epochs, lr, d2l.try_gpu())
'''计时结束'''
end_time = time.time()
run_time = end_time - start_time
# 将输出的秒数保留两位小数
if int(run_time)<60:
print(f'{round(run_time,2)}s')
else:
print(f'{round(run_time/60,2)}minutes')
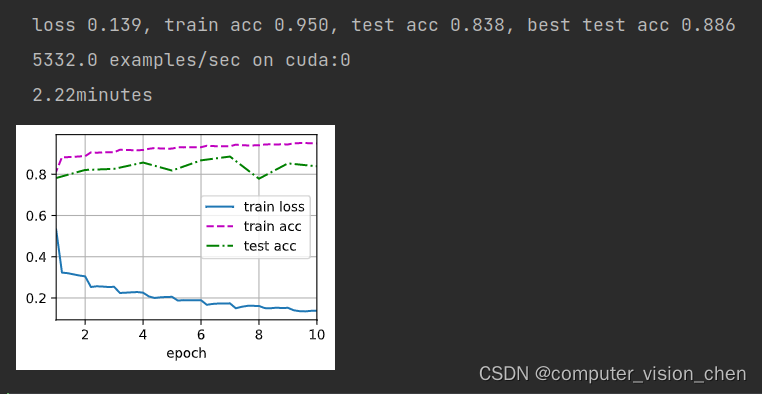
ResNet训练时间是2.92,在这个数据集上denseNet比resnet快。
三.思考
拼接这么多,怎么处理的输出?
该模型输入X,拼接
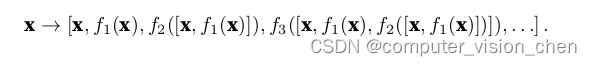
会得到很多的通道数。
用过渡层中的1x1卷积层来减小的通道数,并使用步幅为2的平均汇聚层减半高和宽,从而进一步降低模型复杂度。
densenet比resnet参数少的原因
densenet比resnet参数少的原因在于每一次卷积输入输出的chanenl个数要比resnet少很多,这样bn层的参数也会少很多,channel数对此的影响很大,全连接层的参数也比resnet少很多;
参考资料
densenet比resnet参数量少,但训练速度慢的原因分析
原文链接:https://blog.csdn.net/dulingtingzi/article/details/90514060
DenseNet—比ResNet更优模型
https://blog.csdn.net/qq_42413820/article/details/107427936