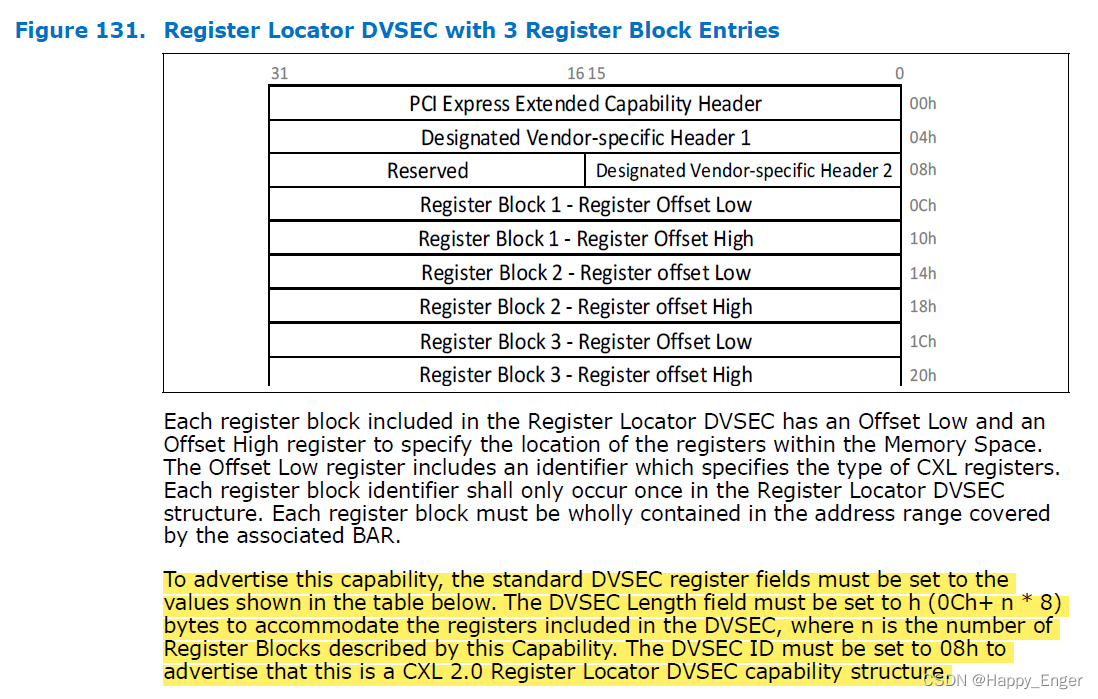
note
- 用图数据库的场景:
- 高性能关系查询:需要快速遍历许多复杂关系的任何用例,如欺诈检测,社交网络分析,网络和数据库基础设施等;
- 模型的灵活性:任何依赖于添加新数据而不会中断现有查询池的用例。模型灵活性包括链接元数据,版本控制数据和不断添加新关系。
- 快速和复杂的分析规则:如子图的比较等这种需要执行复杂的规则时,在推荐、相似度计算和主数据管理等场景。
- 原生图是指采用免索引邻接(Index-free adjacency)构建的图数据库引擎,如: AllegroGraph, Neo4j等。 可以通过
py2neo实现用python操作neo4j;而如果使用neo4j模块:执行CQL ( cypher ) 语句,可以参考Introduction to Cypher。
文章目录
- note
- 一、基于关系型数据库的知识图谱存储
- 二、基于原生图数据库的知识图谱
- 2.1 原生图数据库:利用图的结构特征建索引
- 2.2 Cypher图查询语言
- (1)跨领域图建模与查询
- (2)Cypher图查询举例
- 2.3 常见的图数据库
- 三、原生图数据库实现原理浅析
- 3.1 实现原理:免索引邻接
- 3.2 知识图谱存储的选择
- 3.3 关于图模型和图数据库
- 四、neo4j实践环节
- 4.1 Schema 和引言
- 4.2 创建节点
- 4.3 创建关系
- 4.4 创建 出生地关系
- 4.5 图数据库查询
- 4.6 删除和修改
- 五、通过 Python 操作 Neo4j
- 5.1 neo4j模块:执行CQL ( cypher ) 语句
- 5.2 py2neo模块:通过操作python变量,达到操作neo4j的目的
- 六、通过csv文件批量导入图数据
- 时间安排
- Reference
一、基于关系型数据库的知识图谱存储

关系型数据库的局限性:
- 关系模型不善于处理“关系”:如要找到Bob用户的朋友可以很方便的通过关系数据库用户id表和朋友表进行join,但是要找到谁是Bob的朋友则需要遍历表所有行。
- 处理关联查询:如要查询多跳关系,用关系数据库的效率很慢。
- 知识图谱需要更加丰富的关系语义表达与关联推理能力
- 在需要更加深入的研究数据之间的关系时,需要更加丰富的关系语义的表达能力, 除了前述Reflesive和多跳关系、还包括传递关系Transitive、对称关系(非对 称关系)Symmetric、反关系(Inverse)、函数关系(Functional)。
- 除了关联查询能力,深层次的关系建模还将提供关联推理的能力,属性图数据库 如Neo4J提供了由于关系模型的关联查询能力,AllegroGraph等RDF图数据库提供 了更多的关联推理能力。
- NoSQL也不是善于处理关联关系

上表截图自《知识图谱数据管理研究综述》王鑫
二、基于原生图数据库的知识图谱
2.1 原生图数据库:利用图的结构特征建索引

2.2 Cypher图查询语言

(1)跨领域图建模与查询
- 查询语句能表示跨多个领域的关联逻辑
(2)Cypher图查询举例

2.3 常见的图数据库

在常用的neo4j图数据库中还有封装好的图算法:

三、原生图数据库实现原理浅析
3.1 实现原理:免索引邻接
- 原生图是指采用免索引邻接(Index-free adjacency)构建的图数据库引擎,如: AllegroGraph, Neo4j等。
- 采用免索引邻接的数据库为每一个节点维护了一组指向其相邻节点的引用,这组引用本质上可 以看做是相邻节点的微索引(Micro Index)。
- 这种微索引比起全局索引在处理图遍历查询时非常廉价,其查询复杂度与数据集整体大小无关, 仅正比于相邻子图的大小。

3.2 知识图谱存储的选择
- 知识图谱存储方式的选择需要综合考虑性能、动态扩展、实施成本等多方 面综合因素。
- 区分原生图存储和非原生图存储:原生图存储在复杂关联查询和图计算方 面有性能优势,非原生图存储兼容已有工具集通常学习和协调成本会低。
- 区分RDF图存储和属性图存储:RDF存储一般支持推理,属性图存储通常具 有更好的图分析性能优势。在大规模处理情况下,需要考虑与底层大数据存储引擎和上层图计算引擎 集成需求。
3.3 关于图模型和图数据库
- 图模型是更加接近于人脑认知和自然语言的数据模型,图数据库是处理复杂的、 半结构化、多维度的、紧密关联数据的最好技术。
- 图数据库的弱处:假如你的应用场景不包含大量的关联查询,对于简单查询, 传统关系模型和NoSQL数据库目前在性能方面更加有优势。
- RDF作为一种知识图谱表示框架的参考标准,向上对接OWL等更丰富的语义表示 和推理能力,向下对接简化后的属性图模型以及图计算引擎,是最值得重视的知识图谱表示框架。
四、neo4j实践环节
4.1 Schema 和引言
- 知识图谱另外一个很重要的概念是 Schema:
- 介绍:限定待加入知识图谱数据的格式;相当于某个领域内的数据模型,包含了该领域内有意义的概念类型以及这些类型的属性
- 作用:规范结构化数据的表达,一条数据必须满足Schema预先定义好的实体对象及其类型,才被允许更新到知识图谱中, 一图胜千言
- 图中的DataType限定了知识图谱节点值的类型为文本、日期、数字(浮点型与整型)
- 图中的Thing限定了节点的类型及其属性(即图1-1中的边)
- 举例说明:基于下图Schema构建的知识图谱中仅可含作品、地方组织、人物;其中作品的属性为电影与音乐、地方组织的属性为当地的商业(eg:饭店、俱乐部等)、人物的属性为歌手

下面案例的节点主要包括人物和城市两类,人物和人物之间有朋友、夫妻等关系,人物和城市之间有出生地的关系。参考:异尘手把手教你快速入门知识图谱 - Neo4J教程
- Person-Friends-PERSON
- Person-Married-PERSON
- Person-Born_in-Location
4.2 创建节点
- 删除数据库中以往的图,确保一个空白的环境进行操作【注:慎用,如果库内有重要信息的话】:
-- Neo4J 删库操作
MATCH (n) DETACH DELETE n
这里,MATCH是匹配操作,而小括号()代表一个节点node(可理解为括号类似一个圆形),括号里面的n为标识符。
- 创建一个人物节点:
CREATE (n:Person {name:'John'}) RETURN n
注:
CREATE是创建操作,Person是标签,代表节点的类型。
花括号{}代表节点的属性,属性类似Python的字典。
这条语句的含义就是创建一个标签为Person的节点,该节点具有一个name属性,属性值是John。
- 创建更多的人物节点,并分别命名:
CREATE (n:Person {name:'Sally'}) RETURN n
CREATE (n:Person {name:'Steve'}) RETURN n
CREATE (n:Person {name:'Mike'}) RETURN n
CREATE (n:Person {name:'Liz'}) RETURN n
CREATE (n:Person {name:'Shawn'}) RETURN n
6个人物节点创建成功

- 创建地区节点
CREATE (n:Location {city:'Miami', state:'FL'})
CREATE (n:Location {city:'Boston', state:'MA'})
CREATE (n:Location {city:'Lynn', state:'MA'})
CREATE (n:Location {city:'Portland', state:'ME'})
CREATE (n:Location {city:'San Francisco', state:'CA'})
节点类型为Location,属性包括city和state。
4.3 创建关系
- 朋友关系
MATCH (a:Person {name:'Liz'}),
(b:Person {name:'Mike'})
MERGE (a)-[:FRIENDS]->(b)
注意:方括号[]即为关系,FRIENDS为关系的类型。注意这里的箭头–>是有方向的,表示是从a到b的关系。 这样,Liz和Mike之间建立了FRIENDS关系。
- 关系增加属性
MATCH (a:Person {name:'Shawn'}),
(b:Person {name:'Sally'})
MERGE (a)-[:FRIENDS {since:2001}]->(b)

- 增加更多的朋友关系:
MATCH (a:Person {name:'Shawn'}), (b:Person {name:'John'}) MERGE (a)-[:FRIENDS {since:2012}]->(b)
MATCH (a:Person {name:'Mike'}), (b:Person {name:'Shawn'}) MERGE (a)-[:FRIENDS {since:2006}]->(b)
MATCH (a:Person {name:'Sally'}), (b:Person {name:'Steve'}) MERGE (a)-[:FRIENDS {since:2006}]->(b)
MATCH (a:Person {name:'Liz'}), (b:Person {name:'John'}) MERGE (a)-[:MARRIED {since:1998}]->(b)
图谱就已经建立好了:

4.4 创建 出生地关系
- 建立不同类型节点之间的关系-人物和地点的关系
MATCH (a:Person {name:'John'}), (b:Location {city:'Boston'}) MERGE (a)-[:BORN_IN {year:1978}]->(b)
MATCH (a:Person {name:'Liz'}), (b:Location {city:'Boston'}) MERGE (a)-[:BORN_IN {year:1981}]->(b)
MATCH (a:Person {name:'Mike'}), (b:Location {city:'San Francisco'}) MERGE (a)-[:BORN_IN {year:1960}]->(b)
MATCH (a:Person {name:'Shawn'}), (b:Location {city:'Miami'}) MERGE (a)-[:BORN_IN {year:1960}]->(b)
MATCH (a:Person {name:'Steve'}), (b:Location {city:'Lynn'}) MERGE (a)-[:BORN_IN {year:1970}]->(b)
这里的关系是BORN_IN,表示出生地,同样有一个属性,表示出生年份。在人物节点和地区节点之间,人物出生地关系已建立好。
- 创建节点的时候就建好关系
CREATE (a:Person {name:'Todd'})-[r:FRIENDS]->(b:Person {name:'Carlos'})
最终该图谱如下图所示:

4.5 图数据库查询
-- 查询下所有在Boston出生的人物
MATCH (a:Person)-[:BORN_IN]->(b:Location {city:'Boston'}) RETURN a,b
-- 查询所有对外有关系的节点
MATCH (a)--() RETURN a
-- 查询所有有关系的节点
MATCH (a)-[r]->() RETURN a.name, type(r)
-- 查询所有对外有关系的节点,以及关系类型
MATCH (a)-[r]->() RETURN a.name, type(r)
-- 查询所有有结婚关系的节点
MATCH (n)-[:MARRIED]-() RETURN n
-- 查找某人的朋友的朋友(返回Mike的朋友的朋友)
MATCH (a:Person {name:'Mike'})-[r1:FRIENDS]-()-[r2:FRIENDS]-(friend_of_a_friend) RETURN friend_of_a_friend.name AS fofName
4.6 删除和修改
-- 增加/修改节点的属性
MATCH (a:Person {name:'Liz'}) SET a.age=34
MATCH (a:Person {name:'Shawn'}) SET a.age=32
MATCH (a:Person {name:'John'}) SET a.age=44
MATCH (a:Person {name:'Mike'}) SET a.age=25
-- 删除节点的属性
MATCH (a:Person {name:'Mike'}) SET a.test='test'
MATCH (a:Person {name:'Mike'}) REMOVE a.test
-- 删除节点操作是DELETE
MATCH (a:Location {city:'Portland'}) DELETE a
-- 删除有关系的节点
MATCH (a:Person {name:'Todd'})-[rel]-(b:Person) DELETE a,b,rel
五、通过 Python 操作 Neo4j
5.1 neo4j模块:执行CQL ( cypher ) 语句
# step 1:导入 Neo4j 驱动包
from neo4j import GraphDatabase
# step 2:连接 Neo4j 图数据库
driver = GraphDatabase.driver("bolt://localhost:7687", auth=("neo4j", "password"))
# 添加 关系 函数
def add_friend(tx, name, friend_name):
tx.run("MERGE (a:Person {name: $name}) "
"MERGE (a)-[:KNOWS]->(friend:Person {name: $friend_name})",
name=name, friend_name=friend_name)
# 定义 关系函数
def print_friends(tx, name):
for record in tx.run("MATCH (a:Person)-[:KNOWS]->(friend) WHERE a.name = $name "
"RETURN friend.name ORDER BY friend.name", name=name):
print(record["friend.name"])
# step 3:运行
with driver.session() as session:
session.write_transaction(add_friend, "Arthur", "Guinevere")
session.write_transaction(add_friend, "Arthur", "Lancelot")
session.write_transaction(add_friend, "Arthur", "Merlin")
session.read_transaction(print_friends, "Arthur")
上述程序的核心部分,抽象一下就是:
neo4j.GraphDatabase.driver(xxxx).session().write_transaction(函数(含tx.run(CQL语句)))
或者
neo4j.GraphDatabase.driver(xxxx).session().begin_transaction.run(CQL语句)
5.2 py2neo模块:通过操作python变量,达到操作neo4j的目的
# step 1:导包
from py2neo import Graph, Node, Relationship
# step 2:构建图
g = Graph()
# step 3:创建节点
tx = g.begin()
a = Node("Person", name="Alice")
tx.create(a)
b = Node("Person", name="Bob")
# step 4:创建边
ab = Relationship(a, "KNOWS", b)
# step 5:运行
tx.create(ab)
tx.commit()
六、通过csv文件批量导入图数据
前面学习的是单个创建节点,不适合大批量导入。这里介绍使用neo4j-admin import命令导入,适合部署在docker环境下的neo4j。其他导入方法也可以参考Neo4j之导入数据。csv分为两个nodes.csv和relations.csv,注意关系里的起始节点必须是在nodes.csv里能找到的:
# nodes.csv需要指定唯一ID和nam,
headers = [
'unique_id:ID', # 图数据库中节点存储的唯一标识
'name', # 节点展示的名称
'node_type:LABEL', # 节点的类型,比如Person和Location
'property' # 节点的其他属性
]
# relations.csv
headers = [
'unique_id', # 图数据库中关系存储的唯一标识
'begin_node_id:START_ID', # begin_node和end_node的值来自于nodes.csv中节点
'end_node_id:END_ID',
'begin_node_name',
'end_node_name',
'begin_node_type',
'end_node_type',
'relation_type:TYPE', # 关系的类型,比如Friends和Married
'property' # 关系的其他属性
]
制作出两个csv后,通过以下步骤导入neo4j:
- 两个文件nodes.csv ,relas.csv放在
neo4j安装绝对路径/import
- 导入到图数据库mygraph.db
neo4j bin/neo4j-admin import --nodes=/var/lib/neo4j/import/nodes.csv --relationships=/var/lib/neo4j/import/relas.csv --delimiter=^ --database=xinfang*.db
delimiter=^ 指的是csv的分隔符
- 指定neo4j使用哪个数据库
修改 /root/neo4j/conf/neo4j.conf 文件中的 dbms.default_database=mygraph.db
- 重启neo4j就可以看到数据已经导入成功了
时间安排
| 任务 | 任务信息 | 截止时间 |
|---|---|---|
| - | 12月12日正式开始 | |
| Task01: | CP1知识图谱概论(2天) | 12月12-13日 周二 |
| Task02: | CP2知识图谱表示 + CP3知识图谱的存储和查询(上)(6天) | 12月14-19日 周六 |
| Task03: | CP3知识图谱的存储和查询(下)(3天) | 12月20-22日 周二 |
| Task04: | CP4知识图谱的抽取和构建(3天) | 12月23-25日 周五 |
| Task05: | CP5知识图谱推理(4天) | 12月26-29日 周二 |
Reference
[1] 推荐系统前沿与实践. 李东胜等
[2] 自然语言处理cs224n-2021–Lecture15: 知识图谱
[3] 东南大学《知识图谱》研究生课程课件
[4] 2022年中国知识图谱行业研究报告
[5] 浙江大学慕课:知识图谱导论.陈华钧老师
[6] https://conceptnet.io/
[7] KG paper:https://github.com/km1994/nlp_paper_study_kg
[8] 北大gStore - a graph based RDF triple store
[9] Natural Language Processing Demystified
[10] 玩转Neo4j知识图谱和图数据挖掘
[11] 锋哥的NLP知识图谱学习笔记
[12] https://github.com/datawhalechina/team-learning-nlp/tree/master/KnowledgeGraph_Basic
[13] neo4j官方文档
[14] 干货 | 从零到一学习知识图谱的技术与应用
[15] 手把手教你快速入门知识图谱 - Neo4J教程
[16] python操作图数据库neo4j的两种方式
[17] Neo4j之导入数据
[18] schema 介绍
[19] 知识图谱Schema
[20] 美团大脑:知识图谱的建模方法及其应用
[21] 肖仰华. 知识图谱:概念与技术.北京:电子工业出版社, 2020.2-39.
[22] 图数据库neo4j的编程语句(详解)
[23] 医疗知识图谱问答系统:https://github.com/zhihao-chen/QASystemOnMedicalGraph
[24] 新一代知识图谱关键技术综述. 东南大学 王萌
[25] neo4j官方文档:https://neo4j.com/docs/getting-started/current/
[26] Introduction to Cypher