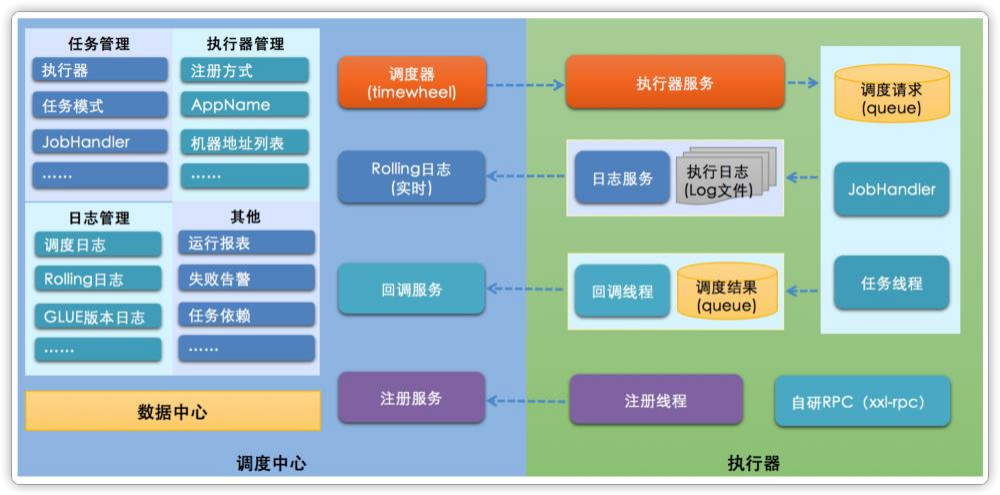
一、说明
作为人类,我们比这个星球上的任何动物都更了解自然语言的许多细微差别。比如说:“你吃了吗”,“企业吃不饱”,“吃豆腐”,“吃醋了”;同样一个“吃”,意义不同,从一个符号出发,有不同的语义轨迹,让计算机也拥有同样的能力,这就是隐马尔可夫的威力。
二、词性标记
从很小的时候起,我们就习惯于识别词性标签。例如,阅读句子并能够识别哪些单词充当名词、代词、动词、副词等。所有这些都被称为词性标签。
让我们看看维基百科对它们的定义:
在语料库语言学中, 词性标记( POS 标记或 PoS 标记或 POST),也称为 语法标记或单词 类别消歧,是根据文本(语料库)中的单词标记为对应于特定词性的过程,基于其定义和上下文——即它与短语中相邻和相关单词的关系, 句子或段落。这种简化形式通常教给学龄儿童,将单词识别为名词、动词、形容词、副词等。
识别词性标签比简单地将单词映射到其词性标签要复杂得多。这是因为POS标记不是通用的。根据不同的上下文,单个单词很有可能在不同的句子中具有不同的词性标签。这就是为什么不可能为 POS 标签提供通用映射的原因。
如您所见,无法手动找出给定语料库的不同词性标签。新类型的上下文和新单词不断出现在各种语言的词典中,手动 POS 标记本身是不可扩展的。这就是我们依赖基于机器的POS标签的原因。
在继续并查看词性标记是如何完成之前,我们应该看看为什么需要 POS 标记以及可以在何处使用它。

三、为什么要进行词性标记?
词性标记本身可能不是任何特定NLP问题的解决方案。然而,这是简化许多不同问题的先决条件。让我们考虑POS标记在各种NLP任务中的一些应用。
3.1 文本到语音转换
让我们看下面这句话:
They refuse to permit us to obtain the refuse permit. 这个词在这句话中被使用了两次,在这里有两种不同的含义。refUSE (/rəˈfyo۞oz/)是一个动词,意思是“拒绝”,而REFuse(/ˈrefˌyo۞os/)是一个名词,意思是“垃圾”(也就是说,它们不是同音字)。因此,我们需要知道正在使用哪个单词才能正确发音文本。(因此,文本转语音系统通常执行 POS 标记。refuse
看看NLTK包为这句话生成的词性标签。
>>> text = word_tokenize("They refuse to permit us to obtain the refuse permit")>>> nltk.pos_tag(text)[('They', 'PRP'), ('refuse', 'VBP'), ('to', 'TO'), ('permit', 'VB'), ('us', 'PRP'),('to', 'TO'), ('obtain', 'VB'), ('the', 'DT'), ('refuse', 'NN'), ('permit', 'NN')]正如我们从NLTK软件包提供的结果中看到的那样,refUSE和REFuse的POS标签是不同的。为我们的文本到语音转换器使用这两个不同的POS标签可以提供一组不同的声音。
同样,让我们看看POS标记的另一个经典应用:词义消歧。
3.2 词义消歧
让我们谈谈这个叫彼得的孩子。由于他的母亲是一名神经科学家,她没有送他上学。他的生活缺乏科学和数学。
有一天,她做了一个实验,让他坐下来上数学课。尽管他没有任何先前的学科知识,但彼得认为他在第一次考试中取得了好成绩。然后,他的母亲从测试中举了一个例子,并发表如下。(向她致敬!
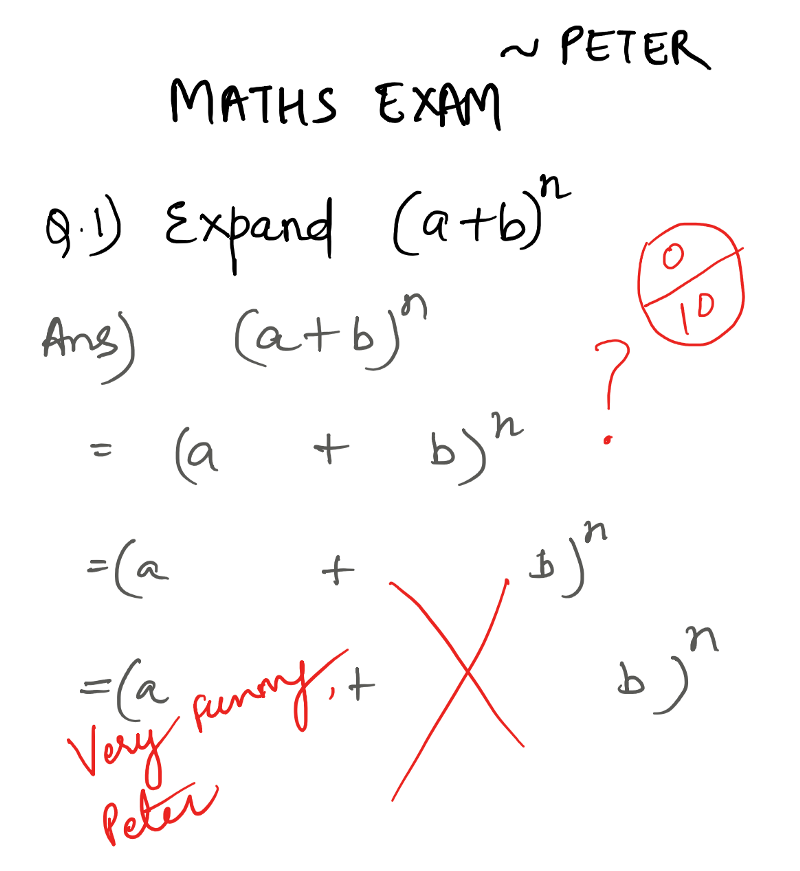
词义消歧示例 — 我儿子彼得的第一个数学问题。
单词通常作为词性的不同而以不同的含义出现。例如:
- 她看到了一只熊。
- 你们的努力将取得成果。
以上句子中的“熊”一词具有完全不同的含义,但更重要的是一个是名词,一个是动词。如果您可以使用POS标签标记单词,则可以进行基本的词义消除歧义。
词义消歧 (WSD) 是当单词具有多种含义时,识别单词在句子中使用的单词的哪个含义(即哪个含义)。
试着想一想这句话的多重含义:
时间如箭般飞逝
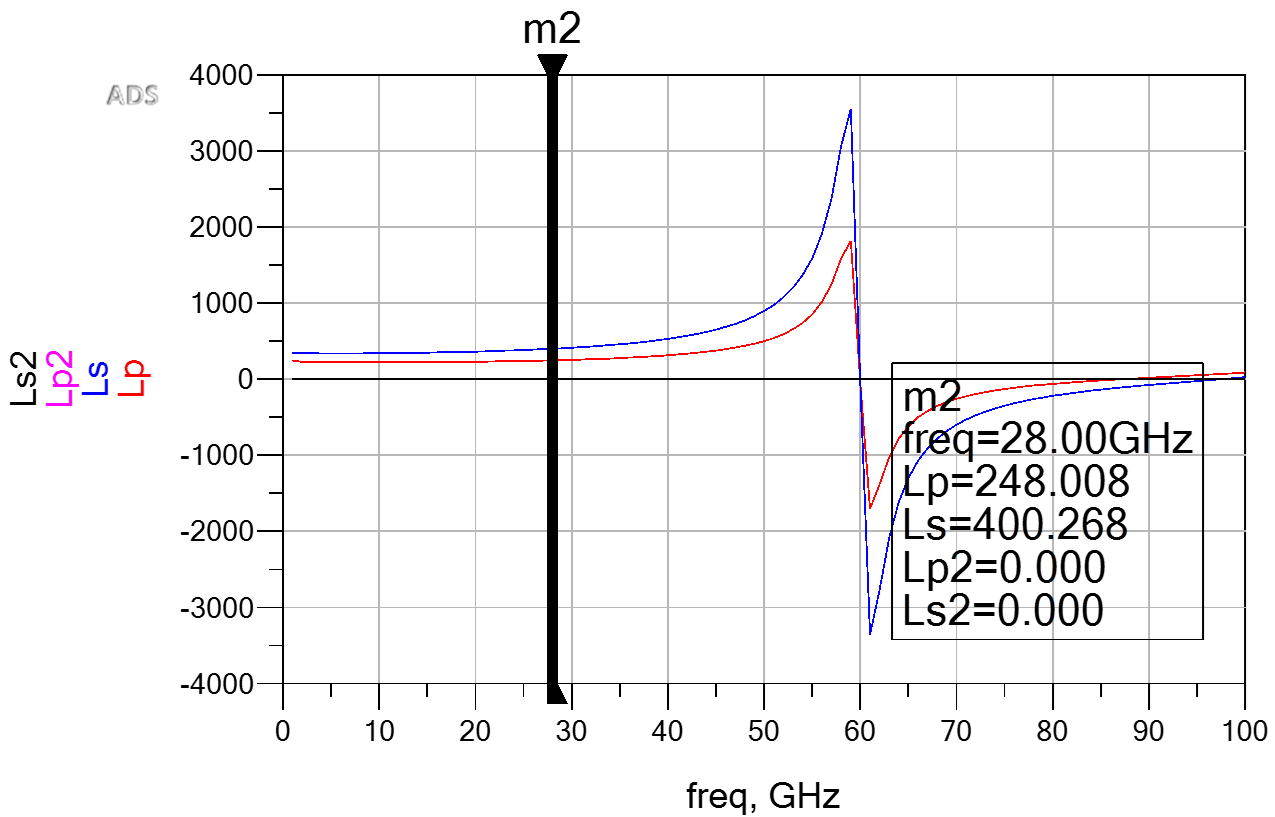
以下是对给定句子的各种解释。每个单词的含义和词性可能会有所不同。
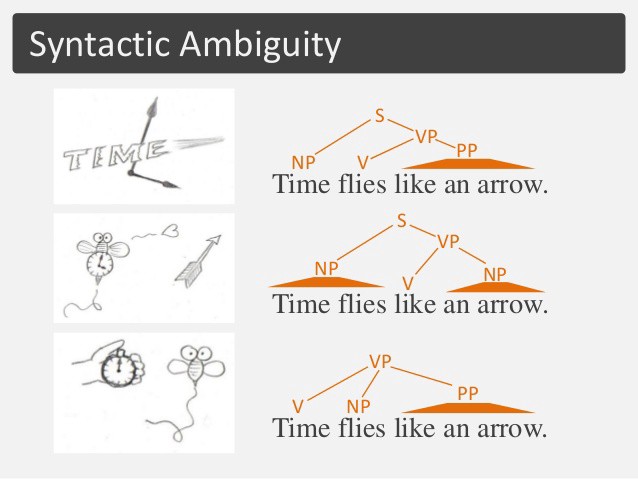
词性标签根据上下文定义句子的含义
我们可以清楚地看到,给定的句子有多种可能的解释。不同的解释为单词产生不同类型的词性标签。这些信息,如果我们可用,可以帮助我们找出句子的确切版本/解释,然后我们可以从那里继续。
上面的示例向我们展示了单个句子可以分配三个相同的不同 POS 标签序列。这意味着无论何时出现给定的句子,了解它所传达的具体含义非常重要。这是词义消歧,因为我们试图找出序列。
这些只是我们需要POS标记的众多应用程序中的两个。还有其他需要POS标记的应用程序,例如问答,语音识别,机器翻译等。
现在我们已经对POS标记的不同应用有了基本的了解,让我们看看如何实际将POS标签分配给语料库中的所有单词。
四、POS 标记机的类型
POS 标记算法分为两组:
- 基于规则的 POS 标记器
- 随机 POS 标记器
E. Brill的标记器是最早也是使用最广泛的英语POS标记器之一,采用基于规则的算法。让我们首先简要概述一下基于规则的标记的全部内容。
4.1 基于规则的标记
自动词性标记是自然语言处理的一个领域,其中统计技术比基于规则的方法更成功。
典型的基于规则的方法使用上下文信息将标记分配给未知或不明确的单词。消除歧义是通过分析单词的语言特征、其前一个单词、其后一个单词和其他方面来完成的。
例如,如果前面的单词是冠词,则所讨论的单词必须是名词。此信息以规则的形式进行编码。
规则示例:
如果一个模棱两可/未知的单词 X 前面有一个决定词,后面跟着一个名词,请将其标记为形容词。
手动定义一组规则是一个非常繁琐的过程,并且根本不可扩展。因此,我们需要一些自动的方式来做到这一点。
Brill 的标记器是一种基于规则的标记器,它遍历训练数据并找出最能定义数据并最大限度地减少 POS 标记错误的标记规则集。关于 Brill 的标记器,这里要注意的最重要的一点是,规则不是手工制作的,而是使用提供的语料库找到的。唯一需要的特征工程是一组规则模板,模型可以使用这些模板来提出新功能。
现在让我们继续看一下随机POS标记。
4.2 随机词性标记
术语“随机标记器”可以指解决POS标记问题的任意数量的不同方法。任何以某种方式包含频率或概率的模型都可以被正确地标记为随机指标。
最简单的随机标记器仅根据单词与特定标记一起出现的概率来消除单词的歧义。换句话说,在训练集中最常遇到的带有单词的标签是分配给该单词的不明确实例的标签。这种方法的问题在于,虽然它可能为给定单词生成有效的标签,但它也可能产生不允许的标签序列。
词频方法的替代方法是计算给定标签序列出现的概率。这有时被称为 n-gram 方法,指的是给定单词的最佳标签由它与前面的 n 个标签一起出现的概率决定。这种方法比之前定义的方法更有意义,因为它根据上下文考虑单个单词的标签。
可以引入随机标记器的下一个复杂程度结合了前两种方法,同时使用标记序列概率和词频测量。这被称为隐马尔可夫模型(HMM)。
在继续什么是隐马尔可夫模型之前,让我们先看看什么是马尔可夫模型。这将有助于更好地理解术语“隐藏在HMM中”的含义。
4.3 马尔可夫模型
假设只有三种天气条件,即
- 雨
- 晴朗
- 多云
现在,由于我们上面介绍的年轻朋友彼得是个小孩,他喜欢在外面玩。他喜欢天气晴朗的时候,因为他所有的朋友都在阳光明媚的条件下出来玩。
他讨厌下雨的天气,原因很明显。
每天,他的母亲都会在早上观察天气(也就是他通常出去玩的时候),像往常一样,彼得起床后马上走到她身边,让她告诉他天气会是什么样子。由于她是一个负责任的父母,她想尽可能准确地回答这个问题。但她唯一拥有的是多天来对天气情况的观察。
她如何根据过去N天的天气情况预测今天的天气?
假设你有一个序列。像这样:
Sunny, Rainy, Cloudy, Cloudy, Sunny, Sunny, Sunny, Rainy
因此,任何给定日的天气都可以在这三个州中的任何一个。
假设我们决定使用马尔可夫链模型来解决这个问题。现在使用我们拥有的数据,我们可以用标记的概率构建以下状态图。
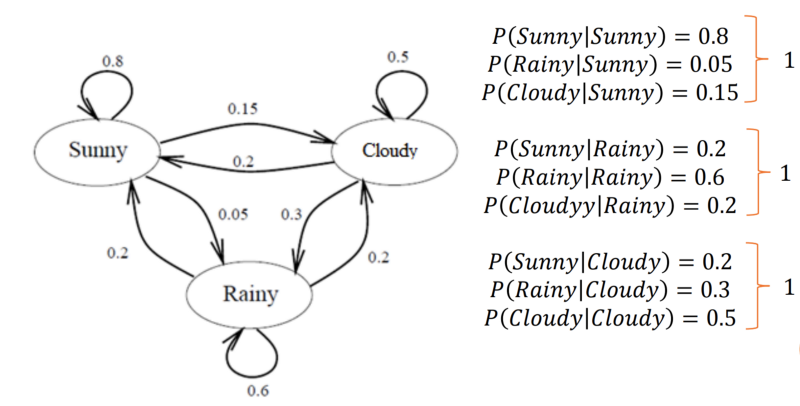
为了在给定 N 个先前观测值的情况下计算今天天气的概率,我们将使用马尔可夫性质。
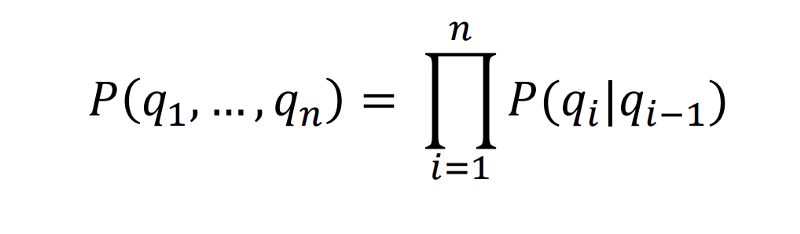
马尔可夫链本质上是已知最简单的马尔可夫模型,即它服从马尔可夫性质。
马尔可夫性质表明,未来随机变量的分布仅取决于其在当前状态下的分布,并且先前的状态对未来状态没有任何影响。
有关马尔可夫链工作的更详细说明,请参阅此链接。
另外,看看下面的例子,看看如何使用上面的公式计算当前状态的概率,同时考虑到马尔可夫属性。

在下面的示例中应用 Markov 属性。
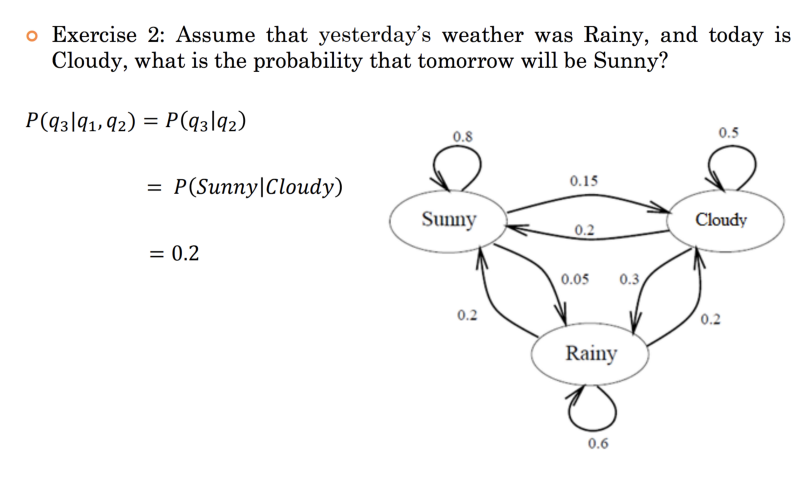
我们可以清楚地看到,根据马尔可夫属性,天气晴朗的概率完全取决于天气而不是 。tomorrow'stoday'syesterday's
现在让我们继续看看隐藏马尔可夫模型中隐藏了什么。
五、隐马尔可夫模型
又是小孩子彼得,这一次他要缠着他的新看护人——就是你。(哎呀!!
作为看护人,对你来说最重要的任务之一就是把彼得塞到床上,确保他睡得很熟。一旦你把他塞进去,你要确保他真的睡着了,而不是恶作剧。
但是,你不能再进入房间,因为这肯定会吵醒彼得。因此,您所要做的就是可能来自房间的噪音。房间很安静,或者房间里有噪音。这些是你的状态。
彼得的母亲在把你留给这场噩梦之前说:
愿声音与你同在:)
他的母亲给了你下面的状态图。该图具有一些状态、观测值和概率。
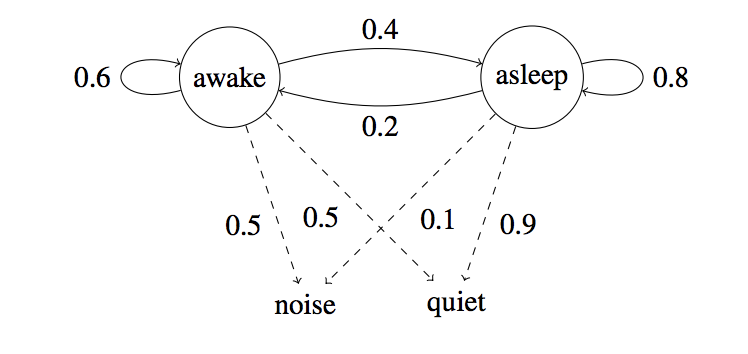
您好看守人,这可能会有所帮助。~彼得斯的母亲。玩得愉快!
请注意,房间里的声音与彼得睡着之间没有直接关系。
从状态图中我们可以看到两种概率。
- 一个是发射概率,它表示在特定状态下进行某些观测的概率。例如,我们有.这是一个发射概率。
P(noise | awake) = 0.5 - 另一个是转移概率,它表示给定特定状态过渡到另一个状态的概率。例如,我们有.这是一个转移概率。
P(asleep | awake) = 0.4
马尔可夫属性也适用于此模型。所以不要把事情复杂化太多。马尔科夫,你的救世主说:
不要过多地了解历史...
马尔可夫性质,适用于我们在这里考虑的例子,是彼得处于某种状态的概率仅取决于前一种状态。
但是马尔可夫属性存在明显的缺陷。如果彼得醒了一个小时,那么他睡着的概率比只醒着5分钟的概率要高。所以,历史很重要。因此,基于马尔可夫状态机的模型并不完全正确。这只是一种简化。
马尔可夫性质虽然是错误的,但使这个问题非常容易处理。
我们通常会观察到孩子醒着和睡着的较长时间。如果彼得现在醒着,他保持清醒的可能性比他睡觉的可能性要高。因此,上图中的 0.6 和 0.4。P(awake | awake) = 0.6 and P(asleep | awake) = 0.4

转移概率矩阵。

发射概率矩阵。
在实际尝试使用 HMM 解决手头的问题之前,让我们将此模型与词性标记任务相关联。
5.1 用于词性标记的 HMM
我们知道,要使用隐马尔可夫模型对任何问题进行建模,我们需要一组观察和一组可能的状态。HMM 中的状态是隐藏的。
在词性标记问题中,观察是给定序列中的单词本身。
至于隐藏的状态,这些将是单词的POS标签。
转换概率有点像这样,假设前一个标签是名词短语,当前单词具有动词短语标签的概率是多少。P(VP | NP)
排放概率是,如果标签是名词短语,那么这个词是约翰的概率是多少。P(john | NP) or P(will | VP)
请注意,这只是问题的非正式建模,目的是提供有关如何使用 HMM 对词性标记问题进行建模的非常基本的了解。
5.2 我们如何解决这个问题?
回到我们照顾彼得的问题。
我们生气了吗? ?。
我们的问题是,我们有一个初始状态:当你把彼得塞到床上时,他是醒着的。之后,您记录了一系列观测结果,即噪声或安静,在不同的时间步长。使用这组观察和初始状态,你想找出彼得在说N个时间步后是醒着还是睡着了。
我们从初始状态开始绘制所有可能的过渡。随着我们不断前进,出现了指数级数量的分支。因此,模型在几个时间步长后呈指数级增长。即使不考虑任何观察结果。看看下面的模型呈指数级扩展。
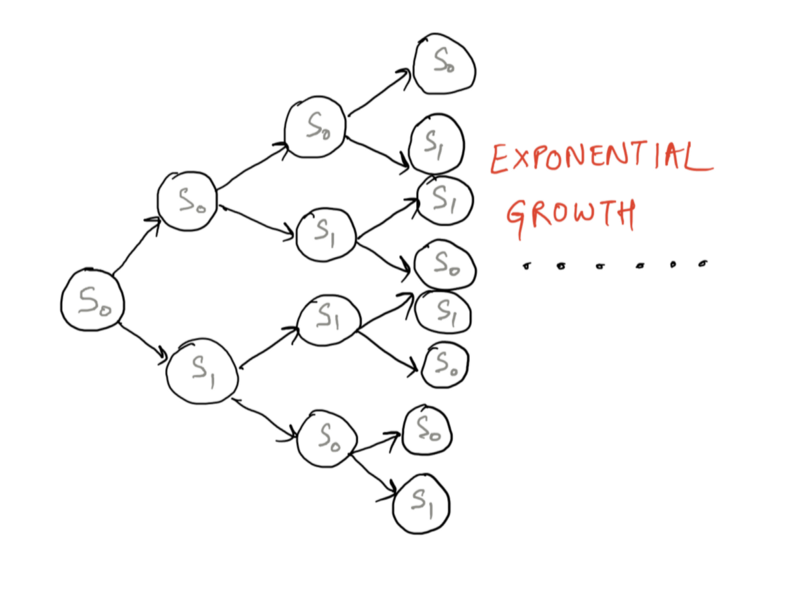
S0 处于唤醒状态,S1 处于睡眠状态。由于过渡,通过模型呈指数增长。
如果我们有一组状态,我们可以计算序列的概率。但我们没有州。我们所拥有的只是一系列的观察。这就是为什么这个模型被称为隐马尔可夫模型——因为随着时间的推移,实际状态是隐藏的。
所以,看守人,如果你已经走到了这一步,这意味着你至少对问题的结构有一个相当好的理解。现在剩下的就是使用一些算法/技术来实际解决问题。现在,恭喜你升级了!
参考资料
Sachin Malhotra和Divya Godayal