Rust 标准库中包含一系列被称为 集合(collections)的非常有用的数据结构。大部分其他数据类型都代表一个特定的值,不过集合可以包含多个值。不同于内建的数组和元组类型,这些集合指向的数据是储存在堆上的,这意味着数据的数量不必在编译时就已知,并且还可以随着程序的运行增长或缩小。每种集合都有着不同功能和成本,而根据当前情况选择合适的集合,这是一项始终成长的技能。
三个在 Rust 程序中被广泛使用的集合:
- vector 允许一个挨着一个地储存一系列数量可变的值
- 字符串(string)是一个字符的集合。之前见过
String类型,不过在本章将深入了解。 - 哈希 map(hash map)允许我们将值与一个特定的键(key)相关联。这是一个叫做 map 的更通用的数据结构的特定实现。
8.1 vector
第一个类型是 Vec<T>,也被称为 vector。vector 允许我们在一个单独的数据结构中储存多于一个的值,它在内存中彼此相邻地排列所有的值。vector 只能储存相同类型的值。
新建vector
为了创建一个新的空 vector,可以调用 Vec::new 函数
fn main() {
let _v: Vec<i32> = Vec::new();
}
注意这里我们增加了一个类型注解。因为没有向这个 vector 中插入任何值,Rust 并不知道想要储存什么类型的元素,尖括号中就是想要存储的类型。
在更实际的代码中,一旦插入值 Rust 就可以推断出想要存放的类型,所以很少会需要这些类型注解。更常见的做法是使用初始值来创建一个 Vec,而且为了方便 Rust 提供了 vec! 宏。这个宏会根据我们提供的值来创建一个新的 Vec。
fn main() {
let v1 = vec![1, 2, 3];
println!("Hello, world!");
}
Rust 可以推断出 v 的类型是 Vec<i32>,因此类型注解就不是必须的。
更新vector
对于新建一个 vector 并向其增加元素,可以使用 push 方法
fn main() {
let mut v = Vec::new();
v.push(5);
v.push(6);
v.push(7);
v.push(8);
v.push(9);
}
如果想要能够改变它的值,必须使用 mut 关键字使其可变。放入其中的所有值都是 i32 类型的,而且 Rust 也根据数据做出如此判断,所以不需要 Vec<i32> 注解。
丢弃vector时也会丢弃所有元素
当 vector 被丢弃时,所有其内容也会被丢弃,这意味着这里它包含的整数将被清理。这可能看起来非常直观,不过一旦开始使用 vector 元素的引用,情况就变得有些复杂了。
读取vector的元素
访问 vector 中一个值的两种方式,索引语法或者 get 方法:
fn main() {
let v = vec![1, 2, 3, 4, 5];
let third : &i32 = &v[2]; // 索引
println!("The third element is {}", third);
// get方法
match v.get(3) {
Some(three) => println!("match The third element is {}", three),
None => println!("There is no third element"),
}
}
这里有两个需要注意的地方。首先,使用索引值 2 来获取第三个元素,索引是从 0 开始的。其次,这两个不同的获取第三个元素的方式分别为:使用 & 和 [] 返回一个引用;或者使用 get 方法以索引作为参数来返回一个 Option<&T>。
Rust 有两个引用元素的方法的原因是程序可以选择如何处理当索引值在 vector 中没有对应值的情况。作为一个例子,让我们看看如果有一个有五个元素的 vector 接着尝试访问索引为 100 的元素时程序会如何处理。
fn main() {
let v = vec![1, 2, 3, 4, 5];
let does_not_exist = &v[100];
let does_not_exist = v.get(100);
}
运行
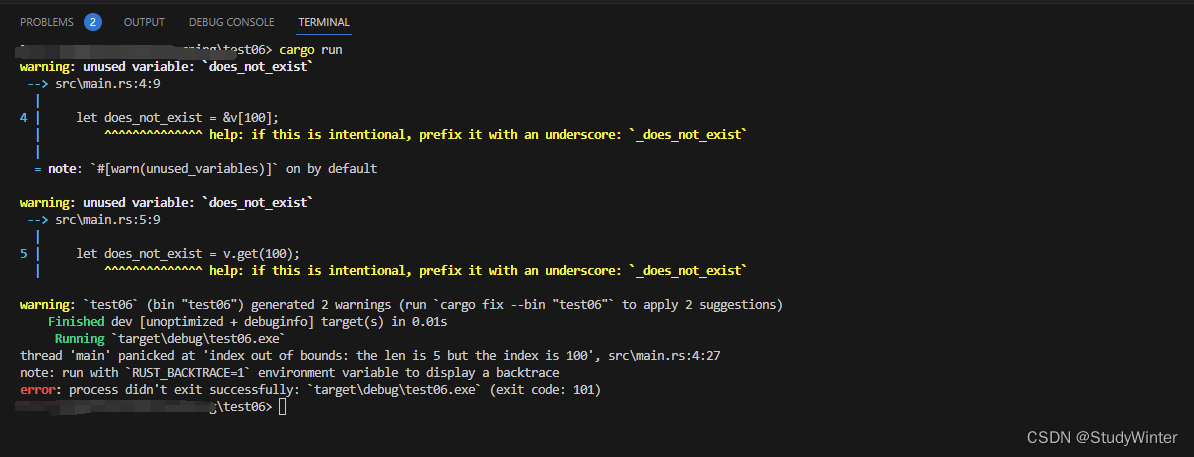
当运行这段代码,你会发现对于第一个 [] 方法,当引用一个不存在的元素时 Rust 会造成 panic。这个方法更适合当程序认为尝试访问超过 vector 结尾的元素是一个严重错误的情况,这时应该使程序崩溃。
当 get 方法被传递了一个数组外的索引时,它不会 panic 而是返回 None。当偶尔出现超过 vector 范围的访问属于正常情况的时候可以考虑使用它。接着你的代码可以有处理 Some(&element) 或 None 的逻辑。
一旦程序获取了一个有效的引用,借用检查器将会执行所有权和借用规则来确保 vector 内容的这个引用和任何其他引用保持有效。
在拥有 vector 中项的引用的同时向其增加一个元素
fn main() {
let v = vec![1, 2, 3, 4, 5];
let first = v[0]; // 不可变引用
v.push(6);
println!("the first element is: {}", first);
}
结果
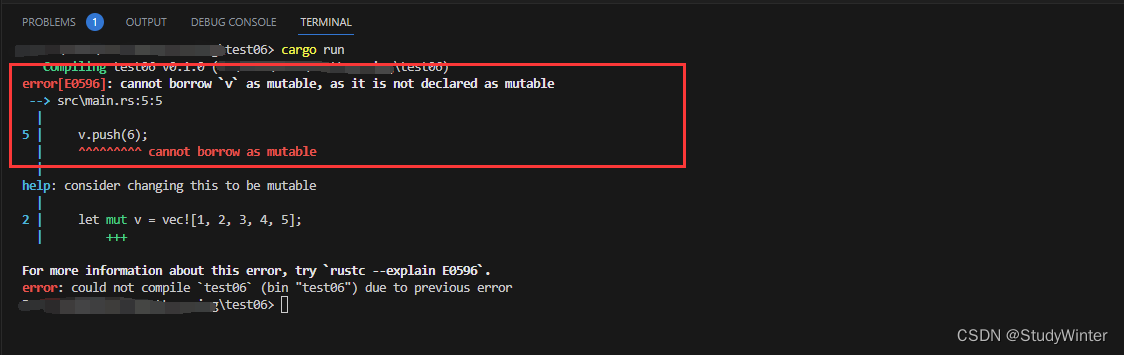
不能这么做的原因是由于 vector 的工作方式:在 vector 的结尾增加新元素时,在没有足够空间将所有所有元素依次相邻存放的情况下,可能会要求分配新内存并将老的元素拷贝到新的空间中。这时,第一个元素的引用就指向了被释放的内存。借用规则阻止程序陷入这种状况。
还有些复杂
遍历vector中的元素
使用 for 循环来获取 i32 值的 vector 中的每一个元素的不可变引用并将其打印:
fn main() {
let v = vec![1, 2, 3, 4, 5];
for i in &v {
println!("{}", i);
}
}
也可以遍历可变 vector 的每一个元素的可变引用以便能改变他们
fn main() {
let mut v = vec![1, 2, 3, 4, 5];
for i in &mut v {
*i += 50;
}
}
使用枚举来储存多种类型
枚举的成员都被定义为相同的枚举类型,所以当需要在 vector 中储存不同类型值时,可以定义并使用一个枚举!
假如我们想要从电子表格的一行中获取值,而这一行的有些列包含数字,有些包含浮点值,还有些是字符串。我们可以定义一个枚举,其成员会存放这些不同类型的值,同时所有这些枚举成员都会被当作相同类型,那个枚举的类型。接着可以创建一个储存枚举值的 vector,这样最终就能够储存不同类型的值了。
#[derive(Debug)]
enum SpreadsheetCell {
Int(i32),
Float(f64),
Text(String),
}
fn main() {
let row = vec![
SpreadsheetCell::Int(3),
SpreadsheetCell::Float(10.12),
SpreadsheetCell::Text(String::from("blue")),
];
// 打印
for item in row.iter() {
println!("Enum item: {:?}", item);
}
}
Rust 在编译时就必须准确的知道 vector 中类型的原因在于它需要知道储存每个元素到底需要多少内存。第二个好处是可以准确的知道这个 vector 中允许什么类型。如果 Rust 允许 vector 存放任意类型,那么当对 vector 元素执行操作时一个或多个类型的值就有可能会造成错误。
vector除了 push 之外还有一个 pop 方法,它会移除并返回 vector 的最后一个元素。
8.2 字符串
在集合章节中讨论字符串的原因是,字符串就是作为字节的集合外加一些方法实现的,当这些字节被解释为文本时,这些方法提供了实用的功能。
什么是字符串
在开始深入这些方面之前,我们需要讨论一下术语 字符串 的具体意义。Rust 的核心语言中只有一种字符串类型:str,字符串 slice,它通常以被借用的形式出现,&str。第四章讲到了 字符串 slice:它们是一些储存在别处的 UTF-8 编码字符串数据的引用。比如字符串字面值被储存在程序的二进制输出中,字符串 slice 也是如此。
称作 String 的类型是由标准库提供的,而没有写进核心语言部分,它是可增长的、可变的、有所有权的、UTF-8 编码的字符串类型。当 Rustacean 们谈到 Rust 的 “字符串”时,它们通常指的是 String 和字符串 slice &str 类型,而不仅仅是其中之一。虽然本部分内容大多是关于 String 的,不过这两个类型在 Rust 标准库中都被广泛使用,String 和字符串 slice 都是 UTF-8 编码的。
新建字符串
很多 Vec 可用的操作在 String 中同样可用,从以 new 函数创建字符串开始
fn main() {
let mut s = String::new();
}
这新建了一个叫做 s 的空的字符串,接着我们可以向其中装载数据。通常字符串会有初始数据,因为我们希望一开始就有这个字符串。为此,可以使用 to_string 方法,它能用于任何实现了 Display trait 的类型,字符串字面值也实现了它。
fn main() {
let data = "hello world";
let s = data.to_string();
// 也可以直接用于字符串字面值
let s = "hello world".to_string();
}
也可以使用 String::from 函数来从字符串字面值创建 String。
fn main() {
let s = String::from("value");
}
字符串是 UTF-8 编码的,所以可以包含任何可以正确编码的数据
fn main() {
let hello = String::from("السلام عليكم");
let hello = String::from("Dobrý den");
let hello = String::from("Hello");
let hello = String::from("שָׁלוֹם");
let hello = String::from("नमस्ते");
let hello = String::from("こんにちは");
let hello = String::from("안녕하세요");
let hello = String::from("你好");
let hello = String::from("Olá");
let hello = String::from("Здравствуйте");
let hello = String::from("Hola");
}
更新字符串
String 的大小可以增加,其内容也可以改变,就像可以放入更多数据来改变 Vec 的内容一样。另外,可以方便的使用 + 运算符或 format! 宏来拼接 String 值。
使用push_str和push附加字符串
可以通过 push_str 方法来附加字符串 slice,从而使 String 变长
fn main() {
let mut hello = String::from("foo");
hello.push_str("bar");
println!("{}", hello);
}
执行这两行代码之后,s 将会包含 foobar。push_str 方法采用字符串 slice,因为我们并不需要获取参数的所有权。
如果将 s2 的内容附加到 s1 之后,自身不能被使用就糟糕了。
fn main() {
let mut s1 = String::from("hello");
let s2 = "world";
s1.push_str(s2);
println!("s2 is {}", s2);
}
如果 push_str 方法获取了 s2 的所有权,就不能在最后一行打印出其值了。好在代码如我们期望那样工作!
push 方法被定义为获取一个单独的字符作为参数,并附加到 String 中。
fn main() {
let mut s1 = String::from("hello");
s1.push('L');
}
使用+运算符或format!宏拼接字符串
通常你会希望将两个已知的字符串合并在一起。一种办法是像这样使用 + 运算符
fn main() {
let s1 = String::from("hello");
let s2 = String::from("world");
let s3 = s1 + &s2;
// s1被移动了,不能使用
}
字符串 s3 将会包含 Helloworld。s1 在相加后不再有效的原因,和使用 s2 的引用的原因,与使用 + 运算符时调用的函数签名有关。+ 运算符使用了 add 函数,这个函数签名看起来像这样:
fn add(self, s: &str) -> String {首先,s2 使用了 &,意味着我们使用第二个字符串的 引用 与第一个字符串相加。这是因为 add 函数的 s 参数:只能将 &str 和 String 相加,不能将两个 String 值相加。不过等一下 —— 正如 add 的第二个参数所指定的,&s2 的类型是 &String 而不是 &str。那么为什么示例还能编译呢?
之所以能够在 add 调用中使用 &s2 是因为 &String 可以被 强转(coerced)成 &str。当add函数被调用时,Rust 使用了一个被称为 解引用强制多态(deref coercion)的技术,你可以将其理解为它把 &s2 变成了 &s2[..]。
其次,可以发现签名中 add 获取了 self 的所有权,因为 self 没有 使用 &。这意味着示例中的 s1 的所有权将被移动到 add 调用中,之后就不再有效。所以虽然 let s3 = s1 + &s2; 看起来就像它会复制两个字符串并创建一个新的字符串,而实际上这个语句会获取 s1 的所有权,附加上从 s2 中拷贝的内容,并返回结果的所有权。换句话说,它看起来好像生成了很多拷贝,不过实际上并没有:这个实现比拷贝要更高效。
索引字符串
在很多语言中,通过索引来引用字符串中的单独字符是有效且常见的操作。然而在 Rust 中,如果你尝试使用索引语法访问 String 的一部分,会出现一个错误。
fn main() {
let s1 = String::from("hello");
let h = s1[0];
}
结果
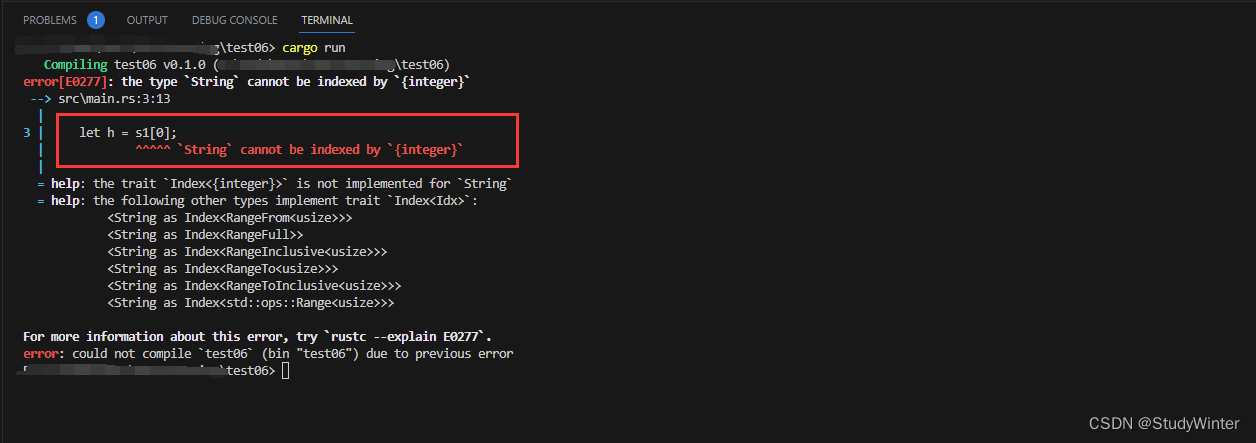
错误和提示说明了全部问题:Rust 的字符串不支持索引。那么接下来的问题是,为什么不支持呢?为了回答这个问题,我们必须先聊一聊 Rust 是如何在内存中储存字符串的。
内部表现
String 是一个 Vec<u8> 的封装。
fn main() {
let len1 = String::from("Hola").len();
let len2 = String::from("Здравствуйте").len();
println!("{}, {}", len1, len2);
}
在这里,len 的值是 4 ,这意味着储存字符串 “Hola” 的 Vec 的长度是四个字节:这里每一个字母的 UTF-8 编码都占用一个字节。当问及Здравствуйте这个字符是多长的时候有人可能会说是 12。然而,Rust 的回答是 24。这是使用 UTF-8 编码 “Здравствуйте” 所需要的字节数,这是因为每个 Unicode 标量值需要两个字节存储。
因为编码的原因,字符串使用索引时要特别谨慎。
遍历字符串的方法
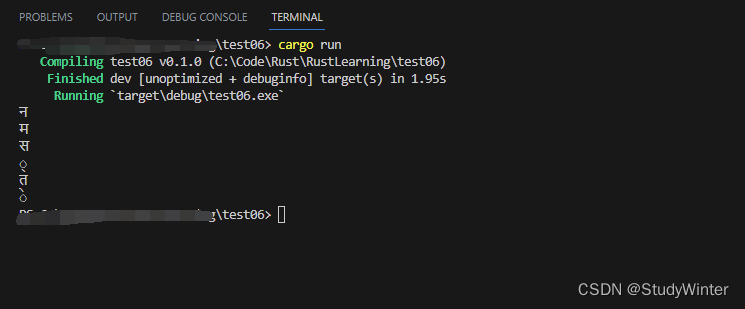
如果你需要操作单独的 Unicode 标量值,最好的选择是使用 chars 方法。对 “नमस्ते” 调用 chars 方法会将其分开并返回六个 char 类型的值,接着就可以遍历其结果来访问每一个元素了:
fn main() {
for c in "नमस्ते".chars() {
println!("{}", c);
}
}
结果
bytes 方法返回每一个原始字节,这可能会适合你的使用场景:
fn main() {
for c in "नमस्ते".bytes() {
println!("{}", c);
}
}
结果

总结
总而言之,字符串还是很复杂的。不同的语言选择了不同的向程序员展示其复杂性的方式。Rust 选择了以准确的方式处理 String 数据作为所有 Rust 程序的默认行为,这意味着程序员们必须更多的思考如何预先处理 UTF-8 数据。这种权衡取舍相比其他语言更多的暴露出了字符串的复杂性,不过也使你在开发生命周期后期免于处理涉及非 ASCII 字符的错误。
8.3 哈希map
HashMap<K, V> 类型储存了一个键类型 K 对应一个值类型 V 的映射。它通过一个 哈希函数(hashing function)来实现映射,决定如何将键和值放入内存中。
新建一个哈希map
可以使用 new 创建一个空的 HashMap,并使用 insert 增加元素。
use std::collections::HashMap;
fn main() {
let mut scores = HashMap::new();
// 使用insert
scores.insert(String::from("Blue"), 10);
scores.insert(String::from("Green"), 50);
}
注意必须首先 use 标准库中集合部分的 HashMap。在这三个常用集合中,HashMap 是最不常用的,所以并没有被 prelude 自动引用。
像 vector 一样,哈希 map 将它们的数据储存在堆上,这个 HashMap 的键类型是 String 而值类型是 i32。类似于 vector,哈希 map 是同质的:所有的键必须是相同类型,值也必须都是相同类型。
另一个构建哈希 map 的方法是使用一个元组的 vector 的 collect 方法,其中每个元组包含一个键值对。
use std::collections::HashMap;
fn main() {
let teams = vec![String::from("Blue"), String::from("Green")];
let data = vec![10, 50];
// 复杂
let scores : HashMap<_, _> = teams.iter().zip(data.iter()).collect();
for i in &scores {
println!("{}, {}", i.0, i.1);
}
}这里 HashMap<_, _> 类型注解是必要的,因为可能 collect 很多不同的数据结构,而除非显式指定否则 Rust 无从得知你需要的类型。但是对于键和值的类型参数来说,可以使用下划线占位,而 Rust 能够根据 vector 中数据的类型推断出 HashMap 所包含的类型。
哈希map和所有权
对于像 i32 这样的实现了 Copy trait 的类型,其值可以拷贝进哈希 map。对于像 String 这样拥有所有权的值,其值将被移动而哈希 map 会成为这些值的所有者。
use std::collections::HashMap;
fn main() {
let field_name = String::from("Favorite color");
let field_value = String::from("Blue");
let mut map = HashMap::new();
map.insert(field_name, field_value);
// 这里 field_name 和 field_value 不再有效,
println!("{}, {}", field_name, field_value);
}
结果
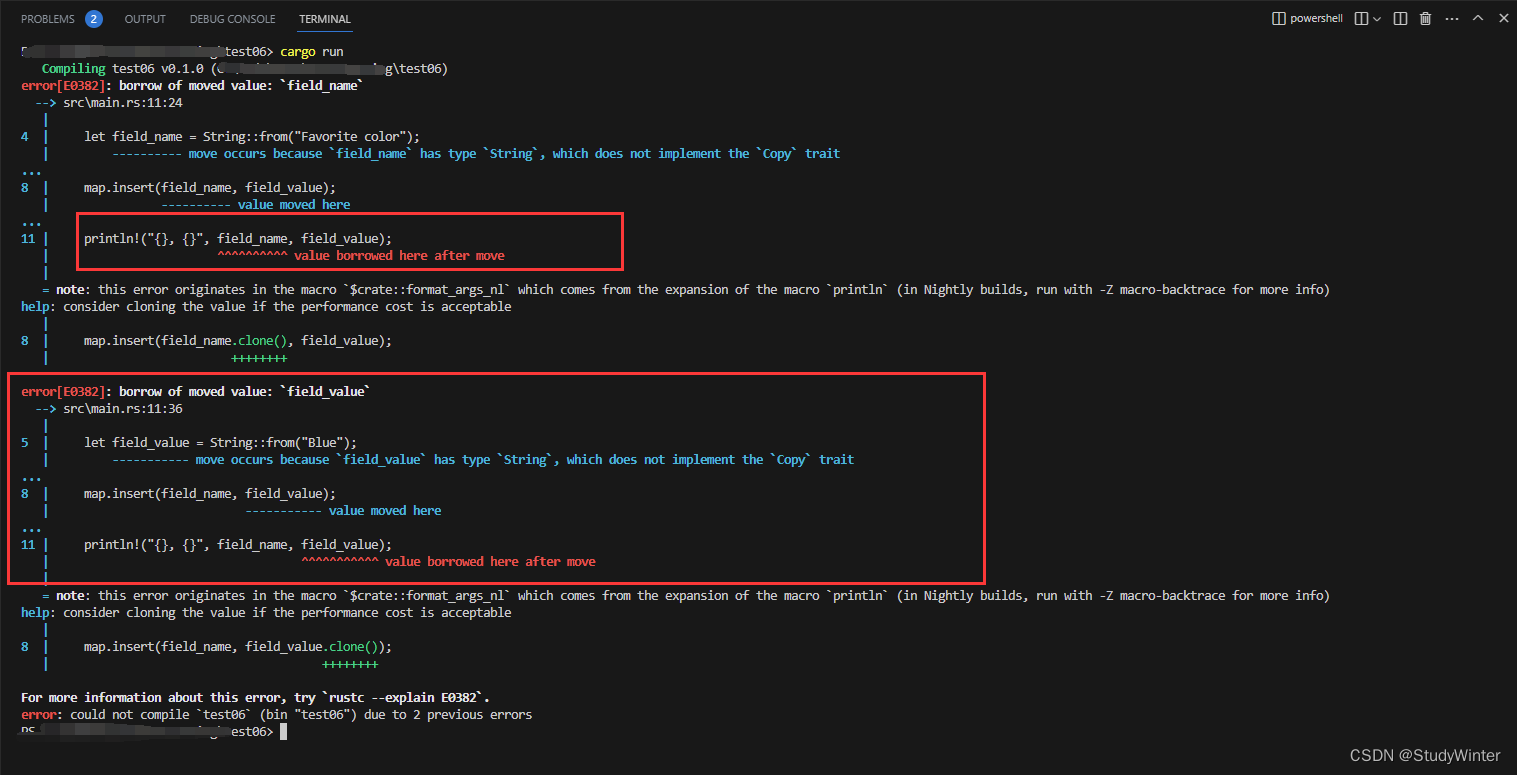
访问哈希map中的值
可以通过 get 方法并提供对应的键来从哈希 map 中获取值
use std::collections::HashMap;
fn main() {
let mut scores = HashMap::new();
scores.insert(String::from("Blue"), 10);
scores.insert(String::from("Yellow"), 50);
let team_name = String::from("Blue");
//使用get
let score = scores.get(&team_name);
println!("{:?}", score);
}
可以使用与 vector 类似的方式来遍历哈希 map 中的每一个键值对,也就是 for 循环:
use std::collections::HashMap;
fn main() {
let mut scores = HashMap::new();
scores.insert(String::from("Blue"), 10);
scores.insert(String::from("Yellow"), 50);
for (k, v) in &scores {
println!("{}, {}", k, v)
}
}
这样也可以
use std::collections::HashMap;
fn main() {
let mut scores = HashMap::new();
scores.insert(String::from("Blue"), 10);
scores.insert(String::from("Yellow"), 50);
for item in &scores {
println!("{}, {}", item.0, item.1)
}
}
更新哈希map
尽管键值对的数量是可以增长的,不过任何时候,每个键只能关联一个值。当我们想要改变哈希 map 中的数据时,必须决定如何处理一个键已经有值了的情况。可以选择完全无视旧值并用新值代替旧值。可以选择保留旧值而忽略新值,并只在键 没有 对应值时增加新值。或者可以结合新旧两值。
覆盖一个值
如果我们插入了一个键值对,接着用相同的键插入一个不同的值,与这个键相关联的旧值将被替换。
use std::collections::HashMap;
fn main() {
let mut scores = HashMap::new();
scores.insert(String::from("Blue"), 10);
scores.insert(String::from("Blue"), 50); // 后面出現的覆蓋前面出現的
println!("{:?}", scores);
}
只在键没有对应值时插入
经常会检查某个特定的键是否有值,如果没有就插入一个值。
use std::collections::HashMap;
fn main() {
let mut scores = HashMap::new();
scores.insert(String::from("Green"), 10);
scores.insert(String::from("Blue"), 50); // 后面出現的覆蓋前面出現的
scores.entry(String::from("Green")).or_insert(90); // Green不存在就插入,存在就不插入
println!("{:?}", scores);
}
Entry 的 or_insert 方法在键对应的值存在时就返回这个值的 Entry,如果不存在则将参数作为新值插入并返回修改过的 Entry。
根据旧值更新一个值
另一个常见的哈希 map 的应用场景是找到一个键对应的值并根据旧的值更新它。
use std::collections::HashMap;
fn main() {
// 統計單詞出現的次數
let text = "hello world wonderful world";
let mut map = HashMap::new();
for word in text.split_ascii_whitespace() {
let count = map.entry(word).or_insert(0);
*count += 1;
}
println!("{:?}", map);
}
这会打印出 {"world": 2, "hello": 1, "wonderful": 1},or_insert 方法事实上会返回这个键的值的一个可变引用(&mut V)。这里我们将这个可变引用储存在 count 变量中,所以为了赋值必须首先使用星号(*)解引用 count。这个可变引用在 for 循环的结尾离开作用域,这样所有这些改变都是安全的并符合借用规则。
哈希函数
HashMap 默认使用一种 “密码学安全的”(“cryptographically strong” )1 哈希函数,它可以抵抗拒绝服务(Denial of Service, DoS)攻击。然而这并不是可用的最快的算法,不过为了更高的安全性值得付出一些性能的代价。如果性能监测显示此哈希函数非常慢,以致于你无法接受,你可以指定一个不同的 hasher 来切换为其它函数。hasher 是一个实现了 BuildHasher trait 的类型。
参考:常见集合 - Rust 程序设计语言 简体中文版 (bootcss.com)







![Vue [Day6]](https://img-blog.csdnimg.cn/c4ec03e6d0a2450890eb83fc51539d91.png)