Hadoop介绍
Hadoop是Apache旗下的一个用java语言实现开源软件框架,是一个开发和运行处理大规模数据的软件平台。允许使用简单的编程模型在大量计算机集群上对大型数据集进行分布式处理。

狭义上说,Hadoop指Apache这款开源框架,它的核心组件有:
- HDFS(分布式文件系统):解决海量数据存储
- YARN(作业调度和集群资源管理的框架):解决资源任务调度
- MAPREDUCE(分布式运算编程框架):解决海量数据计算

广义上来说,Hadoop通常是指一个更广泛的概念——Hadoop生态圈。

当下的Hadoop已经成长为一个庞大的体系,随着生态系统的成长,新出现的项目越来越多,其中不乏一些非Apache主管的项目,这些项目对HADOOP是很好的补充或者更高层的抽象。
Hadoop发展简史
Hadoop是Apache Lucene创始人 Doug Cutting 创建的。最早起源于Nutch,它是Lucene的子项目。Nutch的设计目标是构建一个大型的全网搜索引擎,包括网页抓取、索引、查询等功能,但随着抓取网页数量的增加,遇到了严重的可扩展性问题:如何解决数十亿网页的存储和索引问题。
2003年Google发表了一篇论文为该问题提供了可行的解决方案。论文中描述的是谷歌的产品架构,该架构称为:谷歌分布式文件系统(GFS),可以解决他们在网页爬取和索引过程中产生的超大文件的存储需求。
2004年 Google发表论文向全世界介绍了谷歌版的MapReduce系统。
同时期,Nutch的开发人员完成了相应的开源实现HDFS和MAPREDUCE,并从Nutch中剥离成为独立项目HADOOP,到2008年1月,HADOOP成为Apache顶级项目,迎来了它的快速发展期。
2006年Google发表了论文是关于BigTable的,这促使了后来的Hbase的发展。
因此,Hadoop及其生态圈的发展离不开Google的贡献。
Hadoop集群搭建
发行版本
Hadoop发行版本分为开源社区版和商业版。
社区版是指由Apache软件基金会维护的版本,是官方维护的版本体系。
https://hadoop.apache.org/

商业版Hadoop是指由第三方商业公司在社区版Hadoop基础上进行了一些修改、整合以及各个服务组件兼容性测试而发行的版本,比较著名的有cloudera的CDH、mapR、hortonWorks等。
https://www.cloudera.com/products/open-source/apache-hadoop/key-cdh-components.html

Hadoop的版本很特殊,是由多条分支并行的发展着。大的来看分为3个大的系列版本:1.x、2.x、3.x。
Hadoop1.0由一个分布式文件系统HDFS和一个离线计算框架MapReduce组成。架构落后,已经淘汰。
Hadoop 2.0则包含一个分布式文件系统HDFS,一个资源管理系统YARN和一个离线计算框架MapReduce。相比于Hadoop1.0,Hadoop 2.0功能更加强大,且具有更好的扩展性、性能,并支持多种计算框架。

Hadoop 3.0相比之前的Hadoop 2.0有一系列的功能增强。目前已经趋于稳定,可能生态圈的某些组件还没有升级、整合完善。

我们课程中使用的是:Apache Hadoop 3.3.0。
集群简介
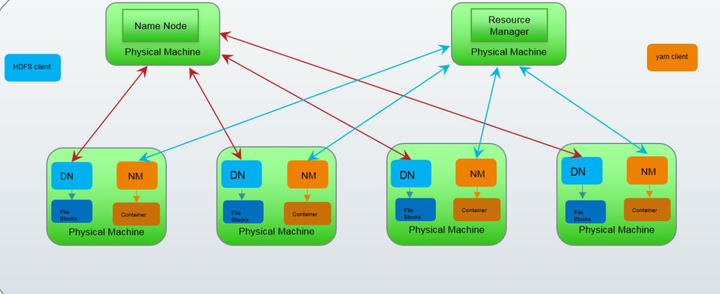
HADOOP集群具体来说包含两个集群:HDFS集群和YARN集群,两者逻辑上分离,但物理上常在一起。
HDFS集群负责海量数据的存储,集群中的角色主要有:
NameNode、DataNode、SecondaryNameNode
YARN集群负责海量数据运算时的资源调度,集群中的角色主要有:
ResourceManager、NodeManager
Hadoop部署方式分三种,Standalone mode(独立模式)、Pseudo-Distributed mode(伪分布式模式)、Cluster mode(群集模式),其中前两种都是在单机部署。
独立模式又称为单机模式,仅1个机器运行1个java进程,主要用于调试。
伪分布模式也是在1个机器上运行HDFS的NameNode和DataNode、YARN的 ResourceManger和NodeManager,但分别启动单独的java进程,主要用于调试。
集群模式主要用于生产环境部署。会使用N台主机组成一个Hadoop集群。这种部署模式下,主节点和从节点会分开部署在不同的机器上。
我们以3节点为例进行搭建,角色分配如下:
node1 NameNode DataNode ResourceManager
node2 DataNode NodeManager SecondaryNameNode
node3 DataNode NodeManager
服务器基础环境准备
1.0 配置好各虚拟机的网络(采用NAT联网模式)
1.1修改各个虚拟机主机名
vi /etc/hostname
node1.itcast.cn
1.2修改主机名和IP的映射关系
vi /etc/hosts
192.168.227.151 node1.itcast.cn node1
192.168.227.152 node2.itcast.cn node2
192.168.227.153 node3.itcast.cn node3
1.3关闭防火墙
#查看防火墙状态
systemctl status firewalld.service
#关闭防火墙
systemctl stop firewalld.service
#关闭防火墙开机启动
systemctl disable firewalld.service
1.4.配置ssh免登陆(配置node1-->node1,node2,node3)
#node1生成ssh免登陆密钥
ssh-keygen -t rsa (一直回车)
执行完这个命令后,会生成两个文件id_rsa(私钥)、id_rsa.pub(公钥)
将公钥拷贝到要免密登陆的目标机器上
ssh-copy-id node1
ssh-copy-id node2
ssh-copy-id node3
1.5 同步集群时间
yum install ntpdate
ntpdate cn.pool.ntp.org
JDK环境安装
2.1上传jdk
jdk-8u65-linux-x64.tar.gz
2.2解压jdk
tar -zxvf jdk-8u65-linux-x64.tar.gz -C /export/server
2.3将java添加到环境变量中
vim /etc/profile
#在文件最后添加
export JAVA_HOME=/export/server/jdk1.8.0_65
export PATH=$PATH:$JAVA_HOME/bin
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
#刷新配置
source /etc/profile