What Really Lets ChatGPT Work?
让 ChatGPT 真正起作用的是什么?
Human language—and the processes of thinking involved in generating it—have always seemed to represent a kind of pinnacle of complexity. And indeed it’s seemed somewhat remarkable that human brains—with their network of a “mere” 100 billion or so neurons (and maybe 100 trillion connections) could be responsible for it. Perhaps, one might have imagined, there’s something more to brains than their networks of neurons—like some new layer of undiscovered physics. But now with ChatGPT we’ve got an important new piece of information: we know that a pure, artificial neural network with about as many connections as brains have neurons is capable of doing a surprisingly good job of generating human language.
人类的语言——以及生成它所涉及的思考过程——一直似乎代表着某种复杂性的巅峰。实际上,人类大脑——其网络仅包含大约 1000 亿左右的神经元(以及可能的 100 万亿连接)能够负责它,似乎是相当令人惊讶的。或许,人们可能会想象,大脑比其神经元网络还有更多的内容——比如某种尚未被发现的新的物理层面。但现在,有了 ChatGPT,我们得到了一个重要的新信息:我们知道一个纯粹的、人工的神经网络,其连接数量大约与大脑的神经元数量相当,能够非常好地生成人类语言。
And, yes, that’s still a big and complicated system—with about as many neural net weights as there are words of text currently available out there in the world. But at some level it still seems difficult to believe that all the richness of language and the things it can talk about can be encapsulated in such a finite system. Part of what’s going on is no doubt a reflection of the ubiquitous phenomenon (that first became evident in the example of rule 30) that computational processes can in effect greatly amplify the apparent complexity of systems even when their underlying rules are simple. But, actually, as we discussed above, neural nets of the kind used in ChatGPT tend to be specifically constructed to restrict the effect of this phenomenon—and the computational irreducibility associated with it—in the interest of making their training more accessible.
是的,这仍然是一个庞大而复杂的系统,其神经网络权重数量与目前世界上可获取的文本字数相当。但在某种程度上,我们仍然很难相信所有丰富的语言及其能够表达的事物可以被封装在如此有限的系统中。在很大程度上,这无疑反映了计算过程可以在其基本规则简单的情况下极大地放大系统复杂性的普遍现象(这一现象最早在规则 30 的例子中显现出来)。然而,实际上,正如我们上面所讨论的,ChatGPT 中使用的神经网络类型往往是专门构建的,以限制这种现象及与之相关的计算不可约性,以便使它们的训练更容易进行。
So how is it, then, that something like ChatGPT can get as far as it does with language? The basic answer, I think, is that language is at a fundamental level somehow simpler than it seems. And this means that ChatGPT—even with its ultimately straightforward neural net structure—is successfully able to “capture the essence” of human language and the thinking behind it. And moreover, in its training, ChatGPT has somehow “implicitly discovered” whatever regularities in language (and thinking) make this possible.
那么,像 ChatGPT 这样的系统如何在语言方面取得如此进展呢?我认为,基本答案是,从根本上讲,语言实际上比它看起来更简单。这意味着 ChatGPT,即使其神经网络结构非常直接,也能成功地“捕捉到”人类语言及其背后思维的本质。而且,在训练过程中,ChatGPT 以某种方式“隐含地发现”了语言(和思维)中使这一切成为可能的规律。
The success of ChatGPT is, I think, giving us evidence of a fundamental and important piece of science: it’s suggesting that we can expect there to be major new “laws of language”—and effectively “laws of thought”—out there to discover. In ChatGPT—built as it is as a neural net—those laws are at best implicit. But if we could somehow make the laws explicit, there’s the potential to do the kinds of things ChatGPT does in vastly more direct, efficient—and transparent—ways.
我认为,ChatGPT 的成功为我们提供了一项关于基础科学的重要证据:它表明我们可以期待发现全新的“语言规律”以及实际上的“思维规律”。在作为神经网络构建的 ChatGPT 中,这些规律充其量只是隐含的。但是,如果我们能以某种方式让这些规律显式化,那么有可能以更直接、更高效且更透明的方式完成类似 ChatGPT 的事情。
But, OK, so what might these laws be like? Ultimately they must give us some kind of prescription for how language—and the things we say with it—are put together. Later we’ll discuss how “looking inside ChatGPT” may be able to give us some hints about this, and how what we know from building computational language suggests a path forward. But first let’s discuss two long-known examples of what amount to “laws of language”—and how they relate to the operation of ChatGPT.
那么,这些规律可能是什么样的呢?从根本上讲,它们必须为我们提供关于语言及其所表达内容的组织方式的某种指导。稍后我们将讨论如何“观察 ChatGPT 内部”以获取关于这方面的一些线索,以及我们从构建计算语言中所了解到的推动这一进程的途径。但首先,让我们讨论两个长期以来已知的“语言规律”的例子以及它们与 ChatGPT 运作的关系。
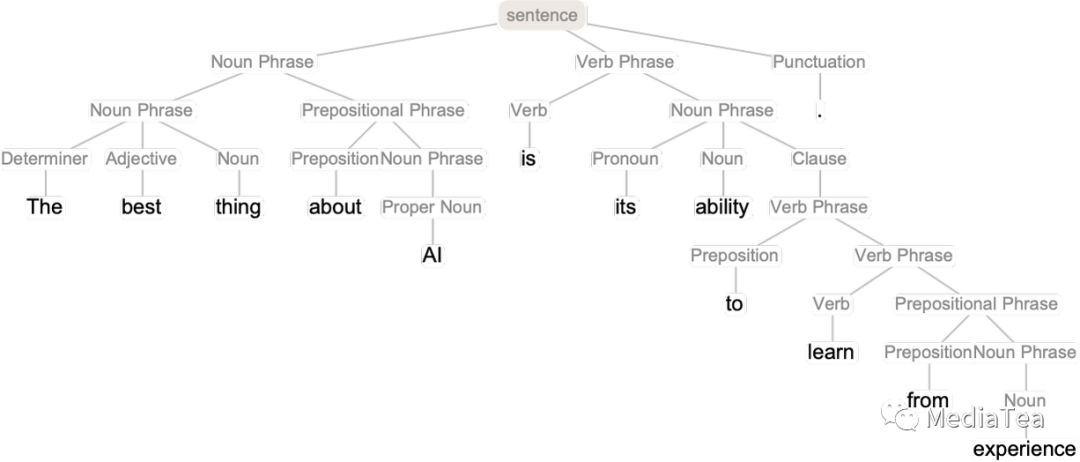
The first is the syntax of language. Language is not just a random jumble of words. Instead, there are (fairly) definite grammatical rules for how words of different kinds can be put together: in English, for example, nouns can be preceded by adjectives and followed by verbs, but typically two nouns can’t be right next to each other. Such grammatical structure can (at least approximately) be captured by a set of rules that define how what amount to “parse trees” can be put together:
首先是语言的语法。语言并非随机的词汇混合体。相反,有(相当)明确的语法规则来规定不同类型的词汇如何组合:例如在英语中,名词可以被形容词修饰并跟在动词后面,但通常两个名词不能紧挨在一起。这种语法结构可以(至少近似地)通过一组规则来捕捉,这些规则定义了如何组合起“解析树”:
ChatGPT doesn’t have any explicit “knowledge” of such rules. But somehow in its training it implicitly “discovers” them—and then seems to be good at following them. So how does this work? At a “big picture” level it’s not clear. But to get some insight it’s perhaps instructive to look at a much simpler example.
ChatGPT 并没有关于这些规则的显式“知识”。但是在训练过程中,它以某种方式隐含地“发现”了这些规则,并且似乎很擅长遵循它们。那么这是如何实现的呢?从“大局”的层面上来看,这还不清楚。但是,为了获得一些启示,也许可以参考一个更简单的例子。
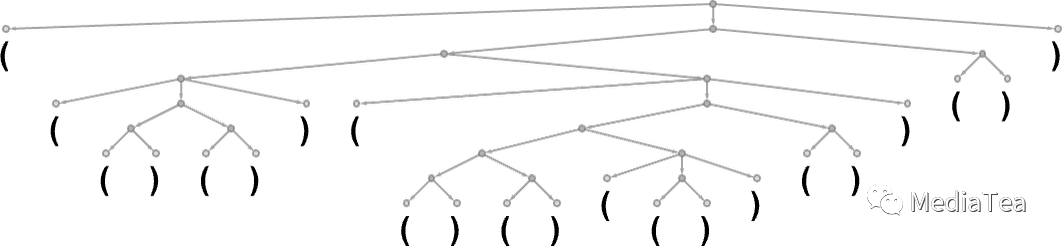
Consider a “language” formed from sequences of (’s and )’s, with a grammar that specifies that parentheses should always be balanced, as represented by a parse tree like:
考虑一种由序列('s 和 )'s 组成的“语言”,其语法规定括号应始终保持平衡,如下面的解析树所示:
Can we train a neural net to produce “grammatically correct” parenthesis sequences? There are various ways to handle sequences in neural nets, but let’s use transformer nets, as ChatGPT does. And given a simple transformer net, we can start feeding it grammatically correct parenthesis sequences as training examples. A subtlety (which actually also appears in ChatGPT’s generation of human language) is that in addition to our “content tokens” (here “(” and “)”) we have to include an “End” token, that’s generated to indicate that the output shouldn’t continue any further (i.e. for ChatGPT, that one’s reached the “end of the story”).
我们能否训练神经网络生成“语法正确”的括号序列呢?在神经网络中处理序列有多种方法,但是让我们使用 ChatGPT 所使用的转换器网络。给定一个简单的转换器网络,我们可以开始用语法正确的括号序列作为训练示例。一个微妙之处(实际上也出现在 ChatGPT 生成人类语言中)是除了我们的“内容标记”(这里是“(”和“)”)之外,我们还需要包括一个“结束”标记,该标记生成表示输出不应再继续(也就是说,对于 ChatGPT 来说,它已经达到了“故事的结尾”)。
If we set up a transformer net with just one attention block with 8 heads and feature vectors of length 128 (ChatGPT also uses feature vectors of length 128, but has 96 attention blocks, each with 96 heads) then it doesn’t seem possible to get it to learn much about parenthesis language. But with 2 attention blocks, the learning process seems to converge—at least after 10 million or so examples have been given (and, as is common with transformer nets, showing yet more examples just seems to degrade its performance).
如果我们设置一个转换器网络,其中只有一个具有 8 个头部和长度为 128 的特征向量的注意力块(ChatGPT 也使用长度为 128 的特征向量,但具有 96 个注意力块,每个块有 96 个头部),那么似乎不可能让它学习到关于括号语言的知识。但是,对于两个注意力块,学习过程似乎在给出大约一千万个示例后收敛(正如转换器网络中常见的情况,再展示更多示例似乎只会降低其性能)。
So with this network, we can do the analog of what ChatGPT does, and ask for probabilities for what the next token should be—in a parenthesis sequence:
因此,对于这个网络,我们可以做类似于 ChatGPT 所做的事情,询问在括号序列中下一个标记的概率:
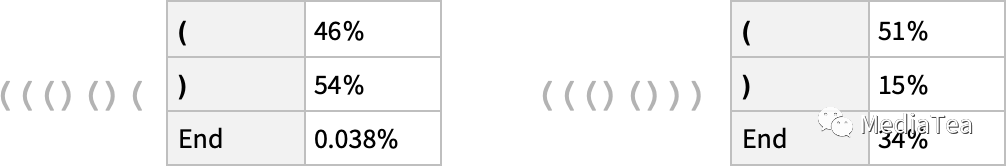
And in the first case, the network is “pretty sure” that the sequence can’t end here—which is good, because if it did, the parentheses would be left unbalanced. In the second case, however, it “correctly recognizes” that the sequence can end here, though it also “points out” that it’s possible to “start again”, putting down a “(”, presumably with a “)” to follow. But, oops, even with its 400,000 or so laboriously trained weights, it says there’s a 15% probability to have “)” as the next token—which isn’t right, because that would necessarily lead to an unbalanced parenthesis.
在第一个例子中,网络“非常确定”序列不能在这里结束,这是很好的,因为如果序列在这里结束,那么括号将会不平衡。然而,在第二个例子中,它“正确地识别出”序列可以在这里结束,尽管它也“指出”可以“重新开始”,放下一个“(”,然后紧跟着一个“)”。但是,哎呀,即使经过 40 万个辛苦训练的权重,它还是认为下一个标记为“)”的概率有 15%,这是错误的,因为这将不可避免地导致括号不平衡。
Here’s what we get if we ask the network for the highest-probability completions for progressively longer sequences of (’s:
如果我们要求网络为逐渐变长的('s 序列提供最高概率的补全,我们将得到什么结果呢:

And, yes, up to a certain length the network does just fine. But then it starts failing. It’s a pretty typical kind of thing to see in a “precise” situation like this with a neural net (or with machine learning in general). Cases that a human “can solve in a glance” the neural net can solve too. But cases that require doing something “more algorithmic” (e.g. explicitly counting parentheses to see if they’re closed) the neural net tends to somehow be “too computationally shallow” to reliably do. (By the way, even the full current ChatGPT has a hard time correctly matching parentheses in long sequences.)
是的,到一定长度时,网络表现得很好。但是随后它开始失败。在神经网络(或一般的机器学习)中处理这种“精确”的情况时,这是一种非常典型的现象。人类“一眼就能解决”的案例,神经网络也能解决。但是,需要做一些“更具算法性”的情况(例如明确计算括号以查看它们是否已关闭),神经网络往往在某种程度上“计算能力不足”以可靠地实现。(顺便说一下,即使是目前功能齐全的 ChatGPT,在处理长序列中的括号匹配方面也很困难。)
So what does this mean for things like ChatGPT and the syntax of a language like English? The parenthesis language is “austere”—and much more of an “algorithmic story”. But in English it’s much more realistic to be able to “guess” what’s grammatically going to fit on the basis of local choices of words and other hints. And, yes, the neural net is much better at this—even though perhaps it might miss some “formally correct” case that, well, humans might miss as well. But the main point is that the fact that there’s an overall syntactic structure to the language—with all the regularity that implies—in a sense limits “how much” the neural net has to learn. And a key “natural-science-like” observation is that the transformer architecture of neural nets like the one in ChatGPT seems to successfully be able to learn the kind of nested-tree-like syntactic structure that seems to exist (at least in some approximation) in all human languages.
那么,这对于诸如 ChatGPT 之类的事物以及像英语这样的语言语法意味着什么呢?括号语言是“简朴的”,并且更具有“算法性”。但在英语中,基于单词的局部选择和其他提示来“猜测”什么是在语法上合适的可能更为现实。是的,神经网络在这方面做得更好,尽管可能会错过一些“正式正确”的情况。嗯,人类也可能会错过。但是,要点是语言具有整体句法结构的事实——以及所有这些结构所暗示的规律性——从某种意义上限制了神经网络需要学习的“程度”。一个关键的“自然科学观察”是,像 ChatGPT 中的神经网络这样的转换器架构似乎能够成功地学习嵌套树状句法结构,这种结构似乎(至少在某种程度上)存在于所有人类语言中。
Syntax provides one kind of constraint on language. But there are clearly more. A sentence like “Inquisitive electrons eat blue theories for fish” is grammatically correct but isn’t something one would normally expect to say, and wouldn’t be considered a success if ChatGPT generated it—because, well, with the normal meanings for the words in it, it’s basically meaningless.
句法为语言提供了一种约束。但是显然还有更多。像“好奇的电子吃蓝色理论为鱼”的句子在语法上是正确的,但不是人们通常会说的内容,如果 ChatGPT 生成了这样的句子,也不会被认为是成功的——因为,嗯,用其中的词的正常含义来说,这基本上是毫无意义的。
But is there a general way to tell if a sentence is meaningful? There’s no traditional overall theory for that. But it’s something that one can think of ChatGPT as having implicitly “developed a theory for” after being trained with billions of (presumably meaningful) sentences from the web, etc.
但是,有没有一种通用的方法来判断一个句子是否有意义呢?没有传统的整体理论可以解释这一点。但这是我们可以将 ChatGPT 视为在经过数十亿来自网络等的(可能有意义的)句子训练之后隐含地“发展出理论”的事物。
What might this theory be like? Well, there’s one tiny corner that’s basically been known for two millennia, and that’s logic. And certainly in the syllogistic form in which Aristotle discovered it, logic is basically a way of saying that sentences that follow certain patterns are reasonable, while others are not. Thus, for example, it’s reasonable to say “All X are Y. This is not Y, so it’s not an X” (as in “All fishes are blue. This is not blue, so it’s not a fish.”). And just as one can somewhat whimsically imagine that Aristotle discovered syllogistic logic by going (“machine-learning-style”) through lots of examples of rhetoric, so too one can imagine that in the training of ChatGPT it will have been able to “discover syllogistic logic” by looking at lots of text on the web, etc. (And, yes, while one can therefore expect ChatGPT to produce text that contains “correct inferences” based on things like syllogistic logic, it’s a quite different story when it comes to more sophisticated formal logic—and I think one can expect it to fail here for the same kind of reasons it fails in parenthesis matching.)
这种理论可能是什么样的呢?嗯,有一个小角落基本上已经为人所知两千年了,那就是逻辑。当然,在亚里士多德发现的三段论形式中,逻辑基本上是一种说法,即遵循某些模式的句子是合理的,而其他句子则不合理。因此,例如,合理的说法是“所有 X 都是 Y,这不是 Y,所以它不是 X”(如“所有鱼都是蓝色的。这不是蓝色的,所以它不是鱼。”)。正如人们可以想象亚里士多德通过大量修辞例子(“机器学习风格”)发现三段论逻辑一样,我们也可以想象,在 ChatGPT 的训练过程中,它可以通过查看大量的网页文本等来“发现三段论逻辑”。(是的,尽管人们因此可以期望 ChatGPT 生成基于诸如三段论逻辑之类的事物的“正确推论”的文本,但在更复杂数学逻辑方面,情况完全不同——我认为它在这方面的失败原因与在括号匹配中的失败原因相同。)
But beyond the narrow example of logic, what can be said about how to systematically construct (or recognize) even plausibly meaningful text? Yes, there are things like Mad Libs that use very specific “phrasal templates”. But somehow ChatGPT implicitly has a much more general way to do it. And perhaps there’s nothing to be said about how it can be done beyond “somehow it happens when you have 175 billion neural net weights”. But I strongly suspect that there’s a much simpler and stronger story.
但是除了逻辑这个狭义的例子之外,关于如何系统地构建(或识别)甚至看似有意义的文本还能说些什么呢?是的,有像疯狂填词游戏这样的东西,它们使用非常具体的“短语模板”。但是,ChatGPT 隐含地具有一种更加通用的方法来实现这一点。也许关于如何做到这一点,除了“当你拥有 1750 亿个神经网络权重时,不知何故就会发生这种情况”之外,没有别的可说的。但我强烈怀疑还有一个更简单、更有力的故事。

“点赞有美意,赞赏是鼓励”