CBAM(Convolutional Block Attention Module)是一种用于增强卷积神经网络(CNN)性能的注意力机制模块。它由Sanghyun Woo等人在2018年的论文[1807.06521] CBAM: Convolutional Block Attention Module (arxiv.org)中提出。CBAM的主要目标是通过在CNN中引入通道注意力和空间注意力来提高模型的感知能力,从而在不增加网络复杂性的情况下改善性能。
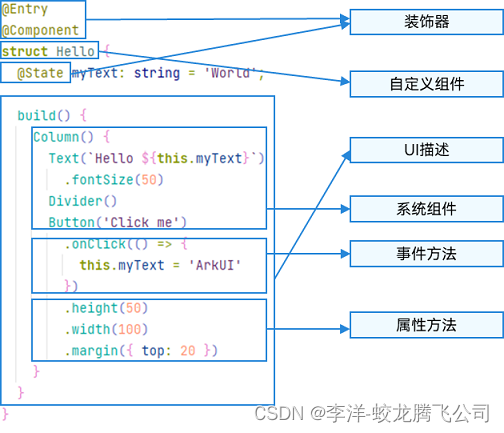
1、概述
CBAM旨在克服传统卷积神经网络在处理不同尺度、形状和方向信息时的局限性。为此,CBAM引入了两种注意力机制:通道注意力和空间注意力。通道注意力有助于增强不同通道的特征表示,而空间注意力有助于提取空间中不同位置的关键信息。
2、模型结构
CBAM由两个关键部分组成:通道注意力模块(C-channel)和空间注意力模块(S-channel)。这两个模块可以分别嵌入到CNN中的不同层,以增强特征表示。
2.1 通道注意力模块
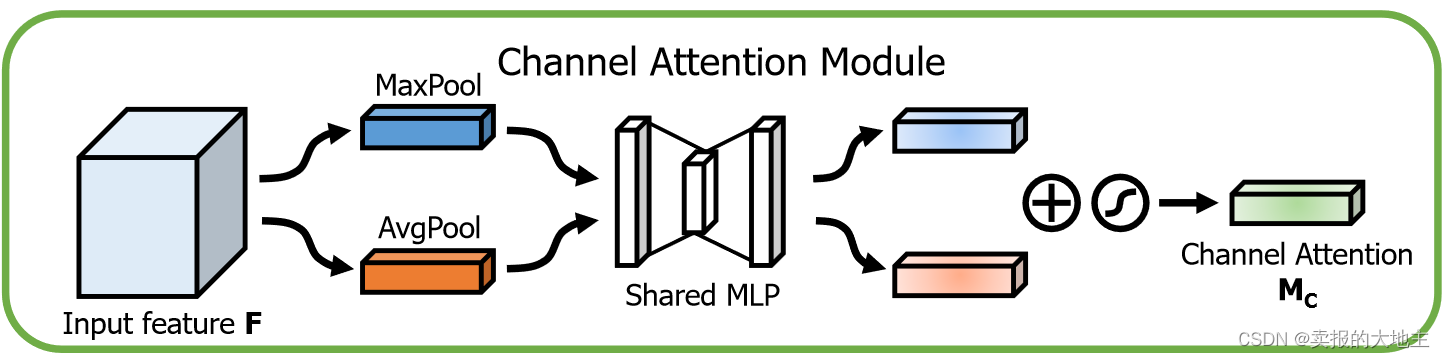
通道注意力模块的目标是增强每个通道的特征表达。以下是实现通道注意力模块的步骤:
-
全局最大池化和全局平均池化: 对于输入特征图,首先对每个通道执行全局最大池化和全局平均池化操作,计算每个通道上的最大特征值和平均特征值。这会生成两个包含通道数的向量,分别表示每个通道的全局最大特征和平均特征。
-
全连接层: 将全局最大池化和平均池化后的特征向量输入到一个共享全连接层中。这个全连接层用于学习每个通道的注意力权重。通过学习,网络可以自适应地决定哪些通道对于当前任务更加重要。将全局最大特征向量和平均特征向相交,得到最终注意力权重向量。
-
Sigmoid激活: 为了确保注意力权重位于0到1之间,应用Sigmoid激活函数来产生通道注意力权重。这些权重将应用于原始特征图的每个通道。
-
注意力加权: 使用得到的注意力权重,将它们与原始特征图的每个通道相乘,得到注意力加权后的通道特征图。这将强调对当前任务有帮助的通道,并抑制无关的通道。
代码实现:
class ChannelAttention(nn.Module):
"""
CBAM混合注意力机制的通道注意力
"""
def __init__(self, in_channels, ratio=16):
super(ChannelAttention, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.max_pool = nn.AdaptiveMaxPool2d(1)
self.fc = nn.Sequential(
# 全连接层
# nn.Linear(in_planes, in_planes // ratio, bias=False),
# nn.ReLU(),
# nn.Linear(in_planes // ratio, in_planes, bias=False)
# 利用1x1卷积代替全连接,避免输入必须尺度固定的问题,并减小计算量
nn.Conv2d(in_channels, in_channels // ratio, 1, bias=False),
nn.ReLU(inplace=True),
nn.Conv2d(in_channels // ratio, in_channels, 1, bias=False)
)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
avg_out = self.fc(self.avg_pool(x))
max_out = self.fc(self.max_pool(x))
out = avg_out + max_out
out = self.sigmoid(out)
return out * x
2.2 空间注意力模块

空间注意力模块的目标是强调图像中不同位置的重要性。以下是实现空间注意力模块的步骤:
- 全局最大池化和全局平均池化: 对于输入特征图,分别执行全局最大池化和全局平均池化操作,生成不同上下文尺度的特征。
- 连接和卷积: 将全局最大池化和全局平均池化后的特征沿着通道维度进行连接(拼接),得到一个具有不同尺度上下文信息的特征图。然后,通过卷积层处理这个特征图,以生成空间注意力权重。
- Sigmoid激活: 类似于通道注意力模块,对生成的空间注意力权重应用Sigmoid激活函数,将权重限制在0到1之间。
- 注意力加权: 将得到的空间注意力权重应用于原始特征图,对每个空间位置的特征进行加权。这样可以突出重要的图像区域,并减少不重要的区域的影响。
代码实现:
class SpatialAttention(nn.Module):
"""
CBAM混合注意力机制的空间注意力
"""
def __init__(self, kernel_size=7):
super(SpatialAttention, self).__init__()
assert kernel_size in (3, 7), 'kernel size must be 3 or 7'
padding = 3 if kernel_size == 7 else 1
self.conv1 = nn.Conv2d(2, 1, kernel_size, padding=padding, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
avg_out = torch.mean(x, dim=1, keepdim=True)
max_out, _ = torch.max(x, dim=1, keepdim=True)
out = torch.cat([avg_out, max_out], dim=1)
out = self.sigmoid(self.conv1(out))
return out * x
2.3 混合注意力模块
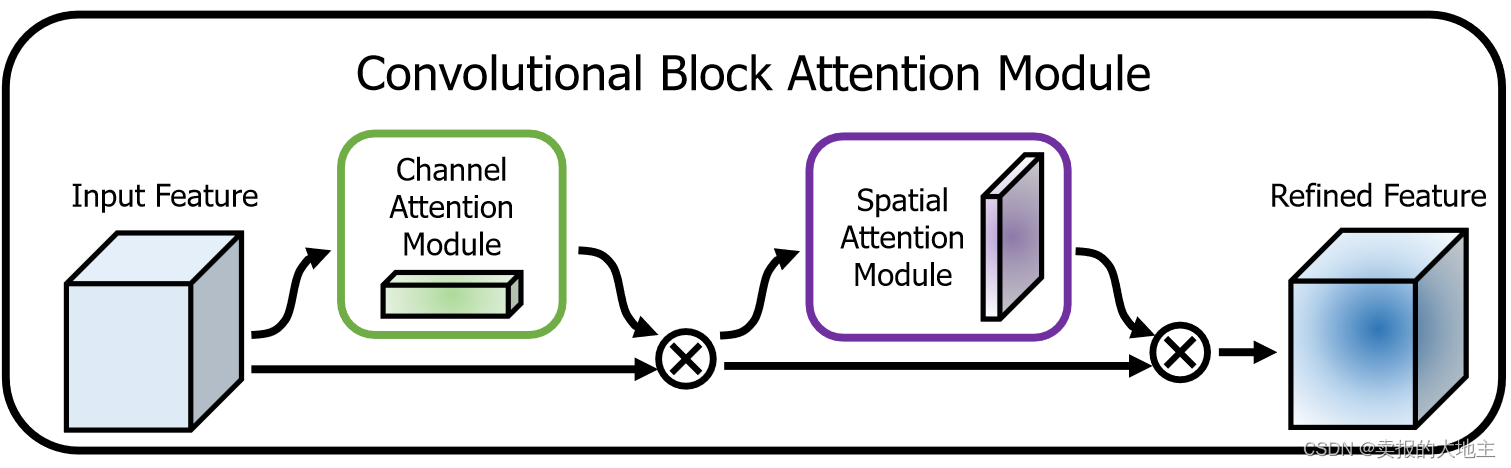
CBAM就是将通道注意力模块和空间注意力模块的输出特征逐元素相乘,得到最终的注意力增强特征。这个增强的特征将用作后续网络层的输入,以在保留关键信息的同时,抑制噪声和无关信息。原文实验证明先进行通道维度的整合,再进行空间维度的整合,模型效果更好(有效玄学炼丹的感觉)。
代码实现:
class CBAM(nn.Module):
"""
CBAM混合注意力机制
"""
def __init__(self, in_channels, ratio=16, kernel_size=3):
super(CBAM_Block, self).__init__()
self.channelattention = ChannelAttention(in_channels, ratio=ratio)
self.spatialattention = SpatialAttention(kernel_size=kernel_size)
def forward(self, x):
x = self.channelattention(x)
x = self.spatialattention(x)
return x
总结
总之,CBAM模块通过自适应地学习通道和空间注意力权重,以提高卷积神经网络的特征表达能力。通过将通道注意力和空间注意力结合起来,CBAM模块能够在不同维度上捕获特征之间的相关性,从而提升图像识别任务的性能。