01 OCR原理分析
本文中采用的车辆号牌识别部分的是采用CNN+LSTM+CTC组合而成,整个网络部分可以分为三个部分,首先是主干网络CNN用于提取字符的特征信息,其次采用深层双向LSTM网络在卷积特征的基础上提取文字或字符的序列特征,最终引入CTC结构解决训练时字符无法对齐的问题。详细组合结构如图1所示。
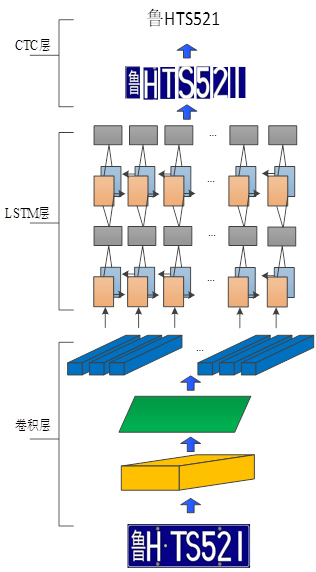
图1 OCR算法结构图
(1)主干网络CNN提取特征。由于该网络只是通过卷积的形式来提取号牌的整个特征信息来做号牌上字符的识别,因此,该算法的输入是整个号牌图像。
(2)LSTM提取序列信息。LSTM作为长短时记忆网络是一种特殊的RNN结构,使用该结构能够避免长期依赖的问题。与循环卷积神经网络(RNN)不同的RNN能保存不同时刻的状态,而LSTM的独特网络结构能够保存四个不同状态的特征,LSTM网络结构单元主要由遗忘门、输入门和输出门三种组合而成,单元结构图如下图2所示。

图2 LSTM网络单元
遗忘门主要是决定从网络中丢弃和保留其中的部分特征,实现过程是通过读取网络输入参数Xt和上一层的输出状态ht-1,并将其通过Sigmoid函数归一化到0-1范围区间中,0表示丢弃的特征,1表示需要保留的特征。遗忘门实现公式如式1所示:
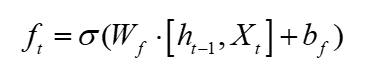
输入门与遗忘门的结构不同,该部分分为两部分结构,一部分与遗忘门类似,另外一部分则是在遗忘门的基础上通过tanh函数将特征映射至-1和1之间,其中-1表示不同更新的部分,1表示需要更新的特征部分,如式2和3所示:
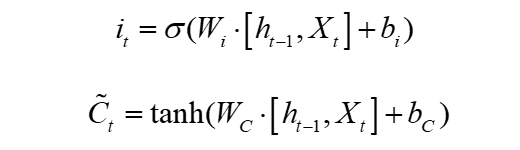
输出门中的sigmoid函数决定哪部分的函数是需要进行输出的,输出部分的特征通过tanh函数,并将其与sigmoid函数的输出进行乘积,最终决定输出部分的特征。实现部分公式如式4和5所示:
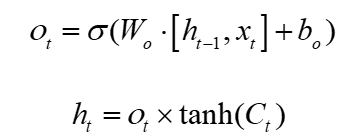
(3)CTC结构。CTC结构是解决语音识别中自动对齐的一种方案,CTC网络结构在字符识别上的应用解决了人为切割字符带来的问题,从而提高整个算法的准确率。
02 车牌号数据集制作
本章中该部分采用的数据集,是在第一部分数据集的基础上截取图片中的号牌得到,在配有Python环境的机器上编写Python脚本读取数据集,从已经标注的xml文件解析出号牌所在图片的位置。为了保证切割图片的完整性,同样采取扩大像素值的办法,xml文件中保存的号牌位置,其中左上角位置坐标点分别减少5个像素,右下角位置坐标点分别增加5个像素。与目标检测不同,识别号牌上的文本除了数据图片之外,还需要将图片名称根据号牌上的文本进行修改。如图3为处理后的可训练号牌数据集。

图3 号牌数据集
初步处理后的数据只是得到具体号牌的图片,尚未对图片进行标注处理,因此并不能直接作为数据集来训练OCR算法,该部分主要实现号牌上文本的识别,本章3.2小节中已经通过YOLOv3算法实现全部遮挡号牌、未悬挂号牌和其他类号牌的定位和分类,在目标检测算法基础上选择识别结果中其他类的图片进行进一步处理,除了与图片标注的质量有关之外,图片的数量也直接影响最终的模型是否更好的泛化能力,数据集中的车辆号牌图片除了包括正常号牌之外,还存在半遮挡的号牌。在进行训练之前还要对图片进行处理,实施过程如图4所示。
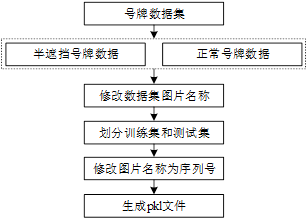
图4 训练集数据处理流程图
(1)修改图片名称为号牌的文本。与目标检测的标注方式不同,号牌的标注要根据实际图片中的文本修改为图片的名称,并且图片的后缀保持不变,对数据集标注完成之后还要根据实际项目需要的格式修改数据集,按照使用Python脚本程序将图片按照6:1的比例分为训练集和测试集,在项目中新建data目录,并在data文件夹中分别新建train/text和test/text两个路径,其中train/text用来存放处理后的训练集图片,train中存放处理的train.pkl二进制文件,test/text中存放测试集图片,同样,test中存放测试集的test.pkl二进制文件。
(2)生成pkl文件。pkl文件是存储二进制内容的文件格式,训练过程中网络从pkl文件中读取文本信息和对应的图片进行训练。分别将训练集和验证集中的图片名称按照次序依次存入新建的pkl文件中,命名为train.pkl和test.pkl,并把对应的图片名称存储为序号。
03 修改预权重文件
本章中采用在预训练权重的基础上进行训练,使用预训练权重的好处在于,不仅能够保证模型快速收敛,减少训练模型的时间,也能避免从零开始训练导致训练过程中出现梯度爆炸和梯度消失的情况发生。预训练权重是通过Python的第三方模块Collections中的子类OrderedDict模块对数据进行存储,OrderedDict是一种有序字典,能够按照输入的顺序对元素进行存储并保证顺序不发生变化,也因此OrderedDict的使用能够保证权重文件中的参数按照训练网络结构的层次和顺序进行存储,权重文件的存储除了在保证权重文件中数据存储的格式顺序之外,还与训练过程中的设备、存储方式和网络结构相关,因此使用预训练权重需要首先对预训练权重的结构以及其存储训练的方式进行了解。本章中对预训练权重的修改包括分析权重文件,修改权重文件的维度两部分,共同实现修改预训练权重文件的目的。具体的实现方式如图5所示。
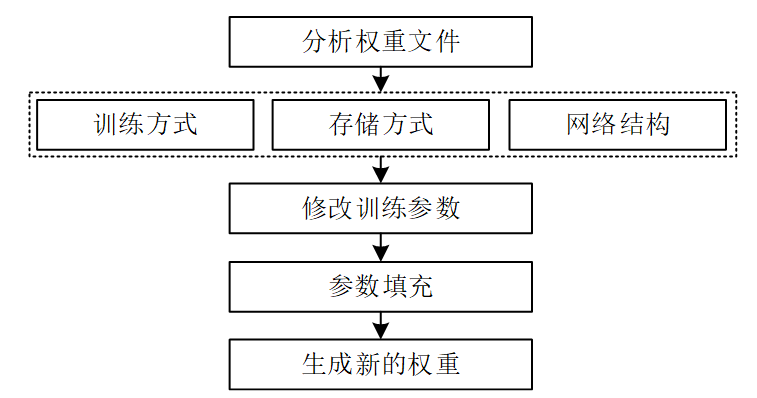
图5 修改权重文件实现方式
(1)分析权重结构。预训练权重的存储方式根据其训练方式可以分为CPU训练、单GPU训练和多GPU训练,其中CPU和单GPU的情况下保存的模型结构相同;根据存储的方式可以分为保存模型的网络结构和训练参数到权重文件,只保存训练参数到权重文件两种;根据存储的方式可以分为保存训练过程中训练的批次、训练参数、网络结构的中间结构的权重文件和只保存最终训练参数的权重文件两种方式;根据网络的结构可以通过Python脚本打印出权重文件的网络结构,根据需求可以修改权重中需要修改的网络参数。
(2)修改预训练权重的维度。修改网络中的参数会导致网络发生变化,因此,要修改预训练权重文件来适配当前网络,解决的方法有两种:剔除其中不合适的网络的节点训练参数;修改不适合训练的网络节点,将其节点进行填充。本章采用第二种方式来匹配网络,使用Python读取权重中的节点名称和维度信息,修改权重文件中的第一层的参数维度和最后对应种类数的网络节点参数为修改后的种类数。保存修改后的权重文件为新的权重文件。
04 模型参数设置及训练过程
OCR识别的训练过程之前,要根据自己训练的数据集和硬件配置来设置具体的参数,具体的参数配置如下。
(1)加载数据集的位置 在工程目录cnn+lstm下,打开trian_crnn.py文件,修改类OCRIter中初始化加载函数中图片和pkl文件的相对路径,训练集图片路径为./data/train/text,训练集标签pkl文件./data/train,测试集图片路径./data/test/text,测试集标签pkl文件./data/test,同时设置参数train_flag为True,在工程代码中修改读取的pkl文件名称。数据集的代码如下:
if train_flag:self.data_path = os.path.join(os.getcwd(), "data", "train", "text")self.label_path = os.path.join(os.getcwd(), "data", "train")else:self.data_path = os.path.join(os.getcwd(), "data", "test", "text")self.label_path = os.path.join(os.getcwd(), "data", "test")
生成pkl文件的代码如下:
def _label_path_from_index(self):label_file = os.path.join(self.label_path, "train_pkl")assert os.path.exists(label_file, "path dose not exits:{}".format(label_file))gt_file = open(label_file, "rb")label_file = cPickle.load(gt_file)gt_file.close()return label_file
注意:在Python代码中以下滑线开始的Python函数表示的是私有函数,其中以单前导下划线_开头的方法或变量,仅允许类内部和子类进行访问,类的实例无法访问此属性和方法。和单前导下划线类似的是双前导下划线__,以此为开头的变量和方法,仅允许类内部进行访问,类实例和派生类均不能进行访问此属性和方法。
(1)修改识别的标签的个数。识别的字符中包含数字、字母和汉字,OCR识别原理上相当于多分类算法,因此,类别上设置包含数字0-1,包含汉字甲-亥和地域简称京、津、晋、冀、蒙、辽、吉、黑、沪、苏、浙、皖、闽、鲁、豫、鄂、湘、粤、桂、琼、川、贵、云、藏、陕、甘、青、宁、渝、赣、新、台、港、澳。具体的修改参数如图6所示。

图6 数据集代码配置
(2)修改num_epoch=6000,BATCH_SIZE=64,配置使用GPU-0训练,contexts = [mx.context.gpu(0)],默认生成并保存权重的路径为工程项目中的model文件夹。
05 阈值分析
实际应用中,污损遮挡号牌的识别不仅和算法的识别率有关,更与所采集的车辆图像质量和实际车牌质量息息相关,车牌质量的好坏直接影响最终的识别性能,例如车牌会受到主观因素上的车辆套牌、车牌遮挡、多车牌等影响,也会受到客观因素上的生锈、字体脱落掉漆、号牌倾斜等影响。除此之外,也会在拍摄过程中受到天气等各种因素影响,这些因素的不同也在不同程度上影响了最终的识别效果。
OCR识别算法是通过识别号牌上的文本来实现正常号牌和半遮挡号牌的分类,因此,OCR算法对每个识别到的字符都会产生一个置信度,且各字符之间相互独立,为了能描述整个识别号牌的置信度,采用识别出各字符的置信度相乘的方式作为号牌的置信度,confi表示第i个字符的置信度,conf表示号牌的整体置信度,实现的公式如式6所示:
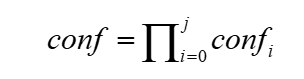
从公式中可以看出,识别到的字符中任何一个字符存在过低置信度的字符会直接导致整个号牌的置信度降低,因此,可以选择直接根据整个号牌的置信度设置阈值进行过滤,从而可以达到区分正常号牌和半遮挡号牌的目的,详细的实现过程如图7所示。
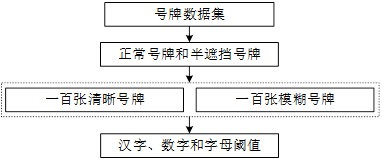
图7 阈值分析流程图
(1)准备数据。各准备清晰号牌和模糊或半遮挡的号牌一百张,其中号牌的种类还应该包括各种不同颜色、不同种类的号牌数据。其中正常号牌命名为正常号牌+序号的方式,序号从1-100,半遮挡号牌命名方式为半遮挡号牌+序号,序号同样为1-100,处理后的数据放置文件夹dataset下。
(2)编写代码。处理后的数据通过程序计算不同阈值情况下的准确率,并保存每次修改阈值后计算得出的准确率,最后生成折线图。实现过程中判断号牌的置信度是否大于设置的阈值,高于阈值的号牌并被判断其命名为正常号牌的作为正常号牌,低于阈值并被判断命名方式中含有半遮挡号牌的同样作为正确识别,在这两个条件下计算号牌的准确率。
(3)选择阈值。经过公式3-6可以得出整个号牌的置信度,因此使用号牌的置信度增加过滤的阈值可以达到分类的效果。编写脚本统计在不同阈值情况下验证数据集的准确率,低于设定阈值的号牌作为半遮挡号牌,否则为正常号牌,设定初始值为0.5并以0.02的速度递增,从而测试出在最高准确率的情况下最合适的阈值,从图中可见,阈值大致随准确率呈正比状态,阈值为0.95左右时趋向平稳,达到96%的准确率,因此,选取合适的阈值为0.95,实验部分的涨幅图如图8所示。
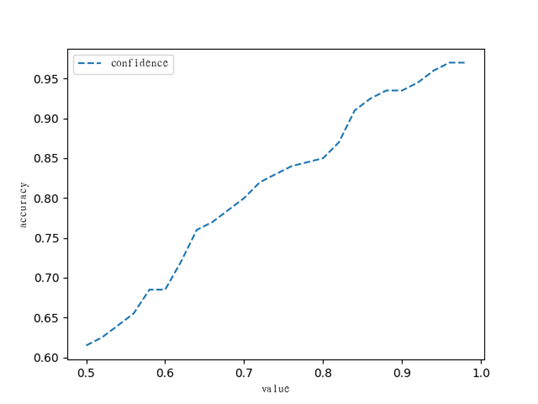
图8 阈值图
06 实验结果
配置好模型参数后,启动模型开始进行训练,训练OCR模型主要分为生成中间权重文件以及验证实验结果二个部分。详细过程如下。
(1)生成权重文件。本章中设置每一次epoch生成一次权重文件,权重文件保存到工程项目的model路径下,权重文件的命名中包含epoch值,用来记录迭代的次数,在不发生梯度爆炸的情况下,随着不断地训练,损失值loss值不断减少,学习效果也更好,由于数据量大并且收敛速度较为缓慢,因此在设置保存间隔时可设置为较大的值,本文中设置的间隔为迭代1000次进行一次权重文件的保存。
(2)选择模型。训练过程中loss值越低代表在训练集上拟合效果越好,但并不代表对验证集效果也好,因此,除了要求训练过程中loss值不断减少之外,还要求保存中间产生的权重文件,保证验证集测试其模型既能够学习到足够的特征,也能保持更好的泛化能力。经过验证在epoch为4500时,准确率更高,loss也更低。测试部分图片的输出结果如图9所示。
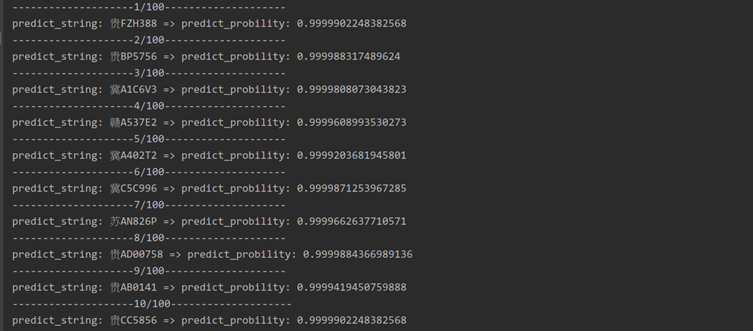
图9 OCR输出结果
从数据选择用来计算准确率的验证集200张,其中包含正常号牌一百张,半遮挡号牌一百张,其中包括各种情况下的号牌,例如蓝牌、黄牌、新能源等等。验证OCR算法的指标与目标检测的指标相同。
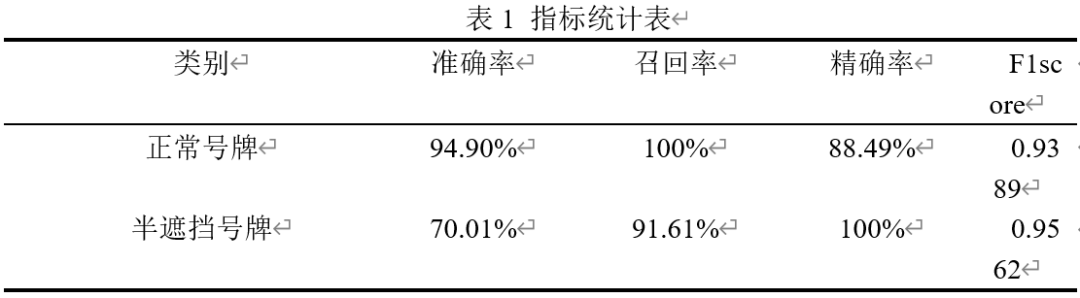
本次实验中使用的阈值为0.95来计算其验证集中的准确率、召回率等等指标,计算指标的数据分为两部分,一部分采用正常号牌,另外一部分为半遮挡号牌,分别计算其准确率(accuracy)、召回率(recall)、精确率(precision)和F1score三部分,从下表中可以得出,在准确率上识别正常号牌的准确率高达94.90%,远高于半遮挡号牌的准确率,但半遮挡号牌的精确率在召回率为91.61%的基础上可以达到100%的识别,从最后计算的F1score上来看,半遮挡号牌的识别效果要好于正常号牌。计算后的结果如表1所示。
测试平台的不同也会影响其运行效率,为了减少其他因素造成的影响,使对比效果更加具有可信度,本次采用的操作系统均为Ubuntu 16.04。其中GPU测试平台为NVIDIA GeForce GTX 1080 Ti显卡,使用的Cuda版本为10.0,并在测试的GPU平台上安装Cudnn加速库,CPU平台为AMD 3550H处理器。为了实现不同平台上的速度测试,分别在不同的平台上搭建环境,运行代码的测试除了根据硬件设施需要对环境进行安装之外还需要对代码进行重新编译。测试后的运行速率如表2所示。




![[附源码]Python计算机毕业设计SSM基于WEB的网上零食销售系统(程序+LW)](https://img-blog.csdnimg.cn/14b51fdda325453e98e0de862627df09.png)



![[UE][UE5]零基础学习-学习记录1-UE5安装与基本使用方法](https://img-blog.csdnimg.cn/6bffaf72b6134e60a5c5676a758ff13f.png)