0. 简介
最近作者希望系统性的去学习一下CUDA加速的相关知识,正好看到深蓝学院有这一门课程。所以这里作者以此课程来作为主线来进行记录分享,方便能给CUDA网络加速学习的萌新们去提供一定的帮助。
1. 基础矩阵乘法
下图是矩阵乘法的示意图,下面我们来看一下在CPU和GPU上是怎么表达的。
CPU代码示意流程:
// Matrix multiplication on the (CPU) host
void main(){
define A, B, C
for i= 0 to M-1 do
for j = 0 to N-1 do
/* compute element C(i,j) */
for k = 0 to K-1 do
C(i,j) <= C(i,j) + A(i,k) * B(k,j)
end
end
end
}
GPU代码示意流程:
void main(){
define A_cpu, B_cpu, C_cpuin the CPU memory
define A_gpu, B_gpu, C_gpuin the GPU memory
memcopyA_cputo A_gpu
memcopyB_cputo B_gpu
dim3 dimBlock(16, 16)
dim3 dimGrid(N/dimBlock.x, M/dimBlock.y)
matrixMul<<<dimGrid, dimBlock>>>(A_gpu,B_gpu,C_gpu,K)
memcopyC_gputo C_cpu
}
__global__ void matrixMul(A_gpu,B_gpu,C_gpu,K){
temp <= 0
i<= blockIdx.y* blockDim.y+ threadIdx.y// Row iof matrix C
j <= blockIdx.x* blockDim.x+ threadIdx.x// Column j of matrix C
for k = 0 to K-1 do
accu<= accu+ A_gpu(i,k) * B_gpu(k,j)
end
C_gpu(i,j) <= accu
}
在GPU中,一个线程负责计算C中的一个元素,其中A中的每一行从全局内存中载入N次,B中的每一列从全局内存中载入M次。总共的次数为2mnk的读取次数(因为在每一个k处都要从A和B中读取一次,所以要乘二),值得注意的是,可以将多次访问的数据放到共享内存中,减少重复读取的次数,并充分利用共享内存的延迟低的优势
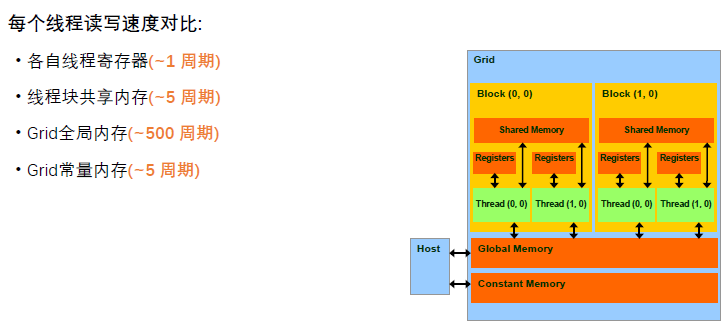
所以我们可以看到共享内存可以被然被内存访问指令访问,同时拥有更高的速度访问(延迟&吞吐)。在共享内存中存在有两种申请空间方式,静态申请和动态申请,但是共享内存的大小只有几十K,过度使用共享内存会降低程序的并行性,共享内存在使用时候需要注意的是:
- 使用__shared__关键字,同时有静态申请和动态申请两种方式;
- 将每个线程从全局索引位置读取元素,将它存储到共享内存之中;
- 注意数据存在着交叉,应该将边界上的数据拷贝进来;
- 块内线程同步:__syncthreads()
2. 线程同步函数
上面讲到了__syncthreads()函数,该函数是cuda的内建函数,用于块内线程通信。__syncthreads()函数是对线程进行同步,需要保证的是需要对所有的共享内存需要同步的线程都被同步到,下面是两个示例。

申请共享内存会存在有两种申请方式:
静态申请
__global__ void staticReverse(int *d, int n) {
__shared__ int s[64];
int t = threadIdx.x;
int tr = n-t-1;
s[t] = d[t];
__syncthreads();
d[t] = s[tr];
}
staticReverse<<<1,n>>>(d_d, n);

![[附源码]Python计算机毕业设计SSM基于WEB的网上零食销售系统(程序+LW)](https://img-blog.csdnimg.cn/14b51fdda325453e98e0de862627df09.png)



![[UE][UE5]零基础学习-学习记录1-UE5安装与基本使用方法](https://img-blog.csdnimg.cn/6bffaf72b6134e60a5c5676a758ff13f.png)