痛点背景
业务场景
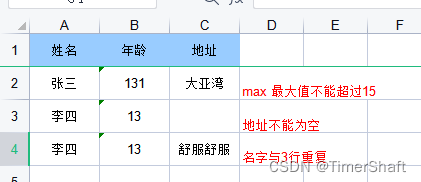
假设有这么一个需求,用户下单后如果30分钟未支付,则该订单需要被关闭。你会怎么做?
之前方案
最简单的做法,可以服务端启动个定时器,隔个几秒扫描数据库中待支付的订单,如果(当前时间-订单创建时间)>30分钟,则关闭订单。
方案评估
- 优点:是实现简单,缺点呢?
- *缺点:定时扫描意味着隔个几秒就得查一次数据库,频率高的情况下,如果数据库中订单总量特别大,这种高频扫描会对数据库带来一定压力,待付款订单特别多时(做个爆品秒杀活动,或者啥促销活动),若一次性查到内存中,容易引起宕机,需要分页查询,多少也会有一定数据库层面压力。
延时队列出现
- 能够在指定时间间隔后触发某个业务操作
- 能够应对业务数据量特别大的特殊场景
RocketMQ延时消息能够完美的解决上述需求,正常的消息在投递后会立马被消费者所消费,而延时消息在投递时,需要设置指定的延时级别(不同延迟级别对应不同延迟时间),即等到特定的时间间隔后消息才会被消费者消费,这样就将数据库层面的压力转移到了MQ中,也不需要手写定时器,降低了业务复杂度,同时MQ自带削峰功能,能够很好的应对业务高峰。
功能特点
- RocketMQ支持发送延迟消息,但不支持任意时间的延迟消息的设置,仅支持内置预设值的延迟时间间隔的延迟消息;
- 预设值的延迟时间间隔为:1s、 5s、 10s、 30s、 1m、 2m、 3m、 4m、 5m、 6m、 7m、 8m、 9m、 10m、 20m、 30m、 1h、 2h;
- 在消息创建的时候,调用 setDelayTimeLevel(int level) 方法设置延迟时间;
- *broker在接收到延迟消息的时候会把对应延迟级别的消息先存储到对应的延迟队列中,等延迟消息时间到达时,会把消息重新存储到对应的topic的queue里面。
Broker处理延迟消息
延时队列生产者端:
延时消息的关键点在于Producer生产者需要给消息设置特定延时级别,消费端代码与正常消费者没有差别。
public class Producer {
private String messageDelayLevel = "1s 5s 10s 30s 1m 2m 3m 4m 5m 6m 7m 8m 9m 10m 20m 30m 1h 2h";
public static void main(String[] args) throws MQClientException, InterruptedException {
DefaultMQProducer producer = new DefaultMQProducer("please_rename_unique_group_name");
producer.setNamesrvAddr("111.231.110.149:9876");
producer.start();
for (int i = 0; i < 10; i++) {
try {
Message msg = new Message("TopicTest" ,
"TagA" ,
("test message" + i).getBytes(RemotingHelper.DEFAULT_CHARSET)
);
msg.setDelayTimeLevel(3);
SendResult sendResult = producer.send(msg);
System.out.printf("%s%n", sendResult);
} catch (Exception e) {
e.printStackTrace();
Thread.sleep(1000);
}
}
producer.shutdown();
}
}
复制代码
初始化
DefaultMessageStore在启动时,会调用ScheduleMessageService#load()方法来加载消息消费进度和初始化延迟级别对应map,然后调用ScheduleMessageService#start()方法来启动类
load方法
public boolean load() {
boolean result = super.load();
result = result && this.parseDelayLevel();
return result;
}
复制代码
ScheduleMessageService继承自ConfigManager类,super.load()方法对应
public boolean load() {
String fileName = null;
try {
fileName = this.configFilePath();
String jsonString = MixAll.file2String(fileName);
if (null == jsonString || jsonString.length() == 0) {
return this.loadBak();
} else {
this.decode(jsonString);
log.info("load " + fileName + " OK");
return true;
}
} catch (Exception e) {
log.error("load " + fileName + " failed, and try to load backup file", e);
return this.loadBak();
}
}
复制代码
延时队列源码分析:
先从延时消息延迟级别设置与broker端消息持久化入手。
具体实现
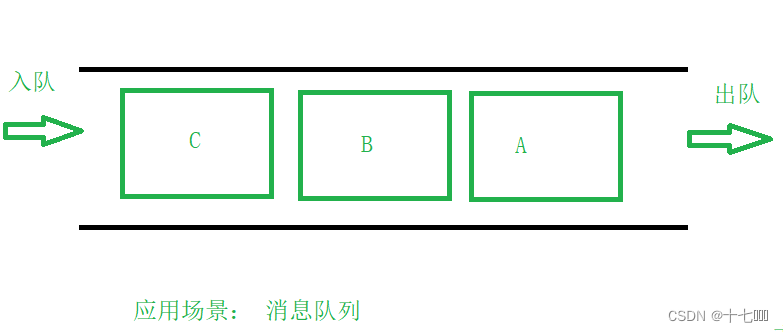
RocketMQ发送延时消息时先把消息按照延迟时间段发送到指定的队列中(rocketmq把每种延迟时间段的消息都存放到同一个队列中)然后通过一个定时器进行轮训这些队列,查看消息是否到期,如果到期就把这个消息发送到指定topic的队列中,这样的好处是同一队列中的消息延时时间是一致的,还有一个好处是这个队列中的消息时按照消息到期时间进行递增排序的,说的简单直白就是队列中消息越靠前的到期时间越早。
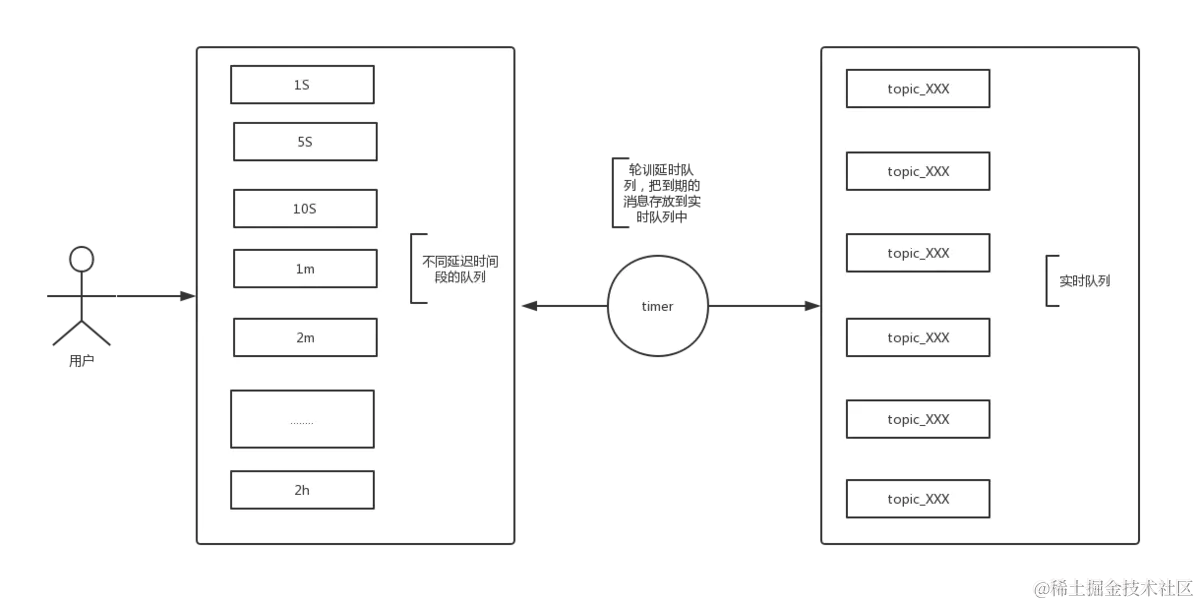
启动延迟消息定时任务
如果想要深入了解的可以看一下ScheduleMessageService这个类
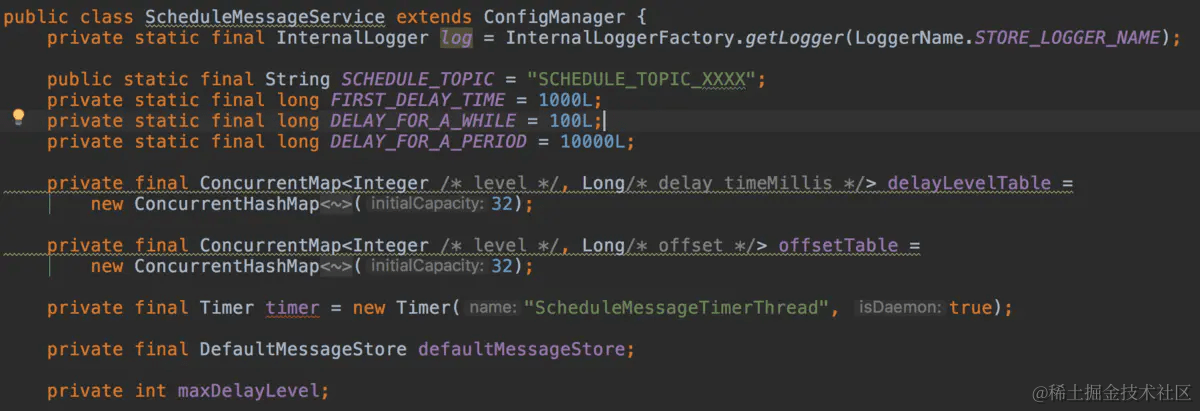
内部变量含义
延时消息定时投递相关具体实现代码在ScheduleMessageService中,先看下变量定义 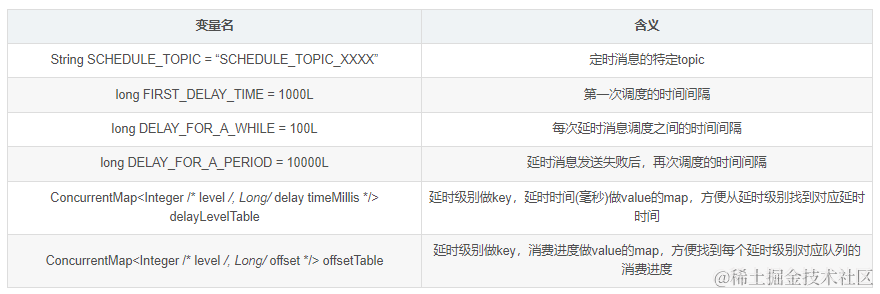
- delayLevelTable定义了延迟级别和延迟时间的对应关系
- *offsetTable存放延延迟级别对应的队列消费的offset
ScheduleMessageService.start()
复制代码
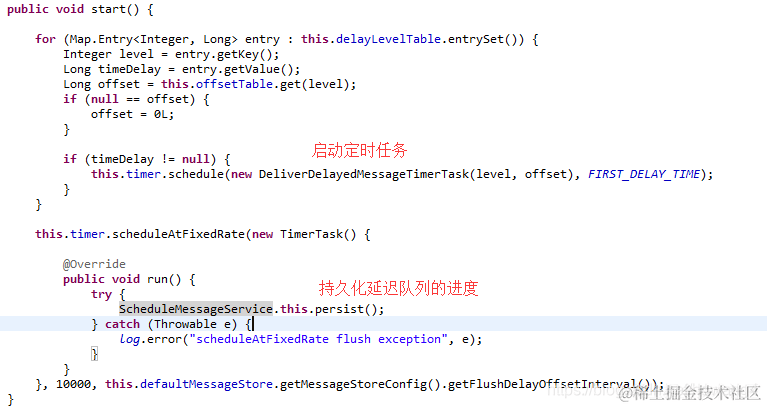
延迟消息投递

其中根据,delayLevel获取消费队列id的方法如下,即queueId = delayLevel-1
public static int delayLevel2QueueId(final int delayLevel) {
return delayLevel - 1;
}
复制代码

核心逻辑就是取出tagCode(延时消息持久化时,tagsCode存储的是消息投递时间),解析成消息投递时间,与当前时间戳做差,判断是否应该进行消息投递,具体进行消息投递的方法,在if (countdown
分享资源
获取以上资源请访问开源项目 点击跳转