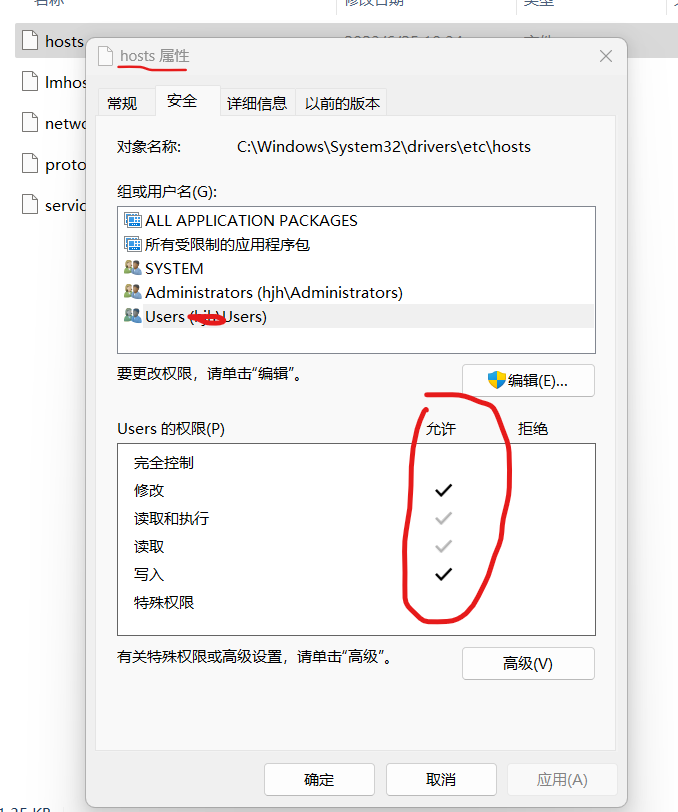
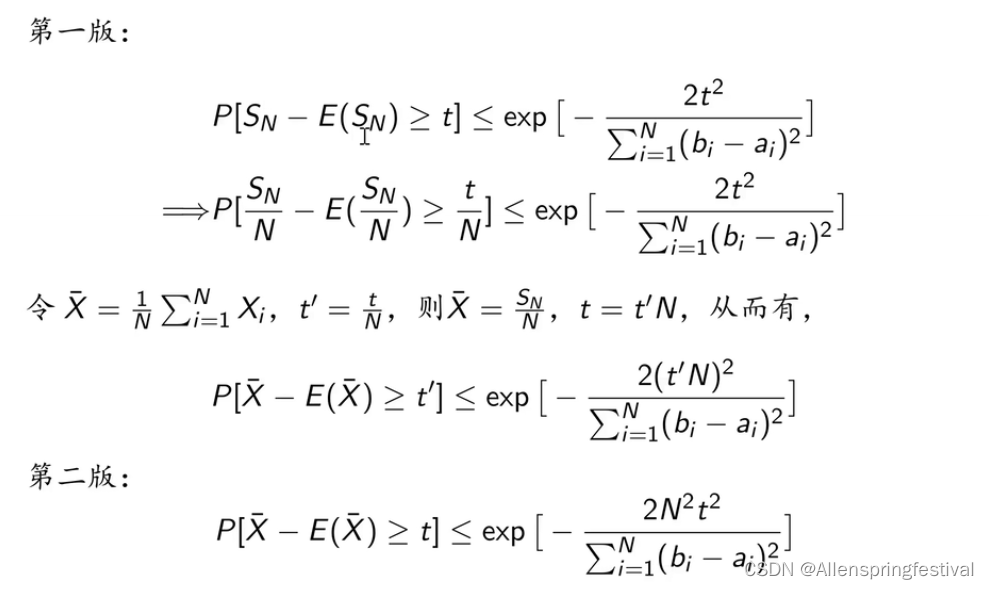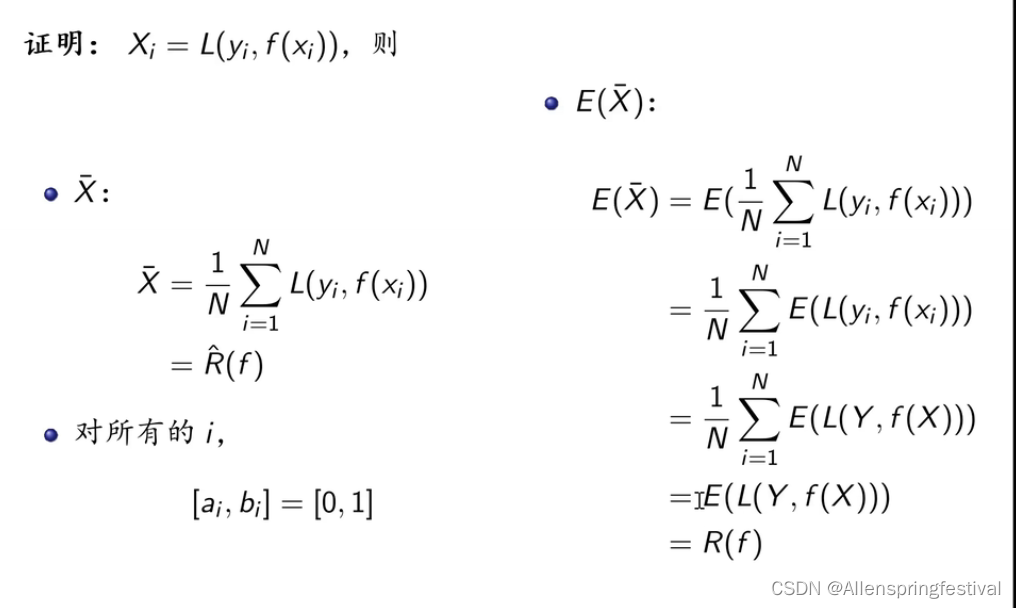一,模型评估与模型选择
1.训练误差与测试误差

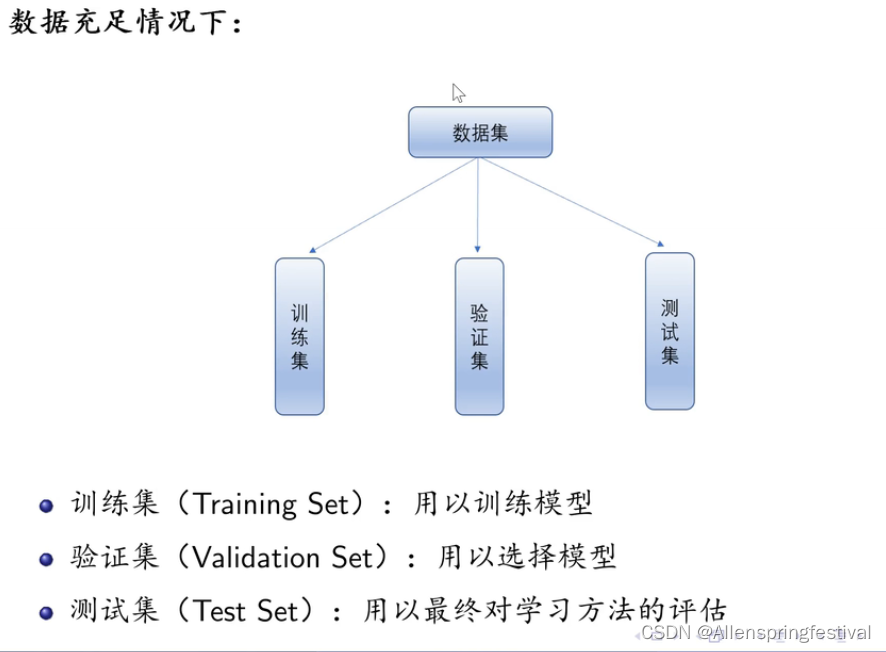
假如我们有100个数据。80条记录给训练集,10条记录给测试集,10条记录给验证集
先在训练集中训练模型,
再在验证集上测试看哪种模型更拟合
最后用测试集算出成绩

 表示决策函数
表示决策函数
模型拟合的好坏(对已知数据的预测效果)我们可以通过训练集测出训练误差来衡量
对未知数据预测效果好坏可以利用测试集来衡量

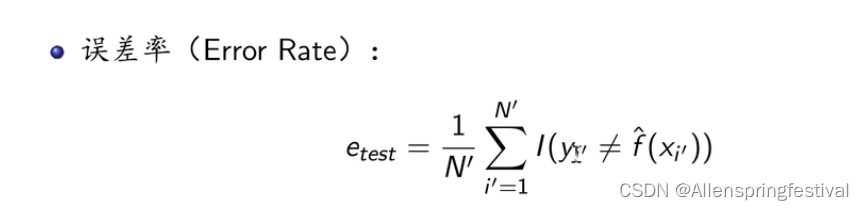 预测值和真实值不相等的个数占测试集样本总个数的比例
预测值和真实值不相等的个数占测试集样本总个数的比例
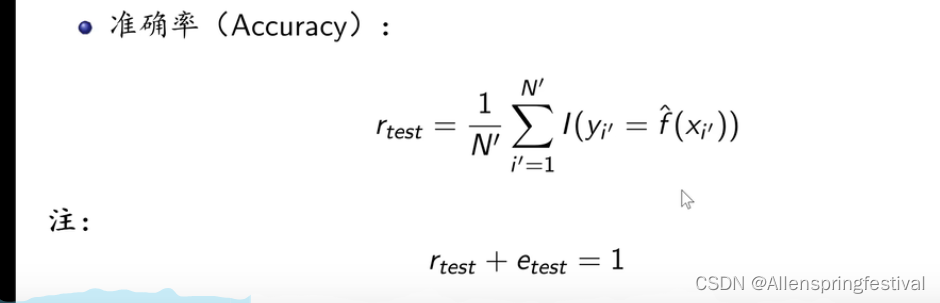
- 经过模型的预测值和真实值相等的占样本点的个数。
2.过拟合与模型选择
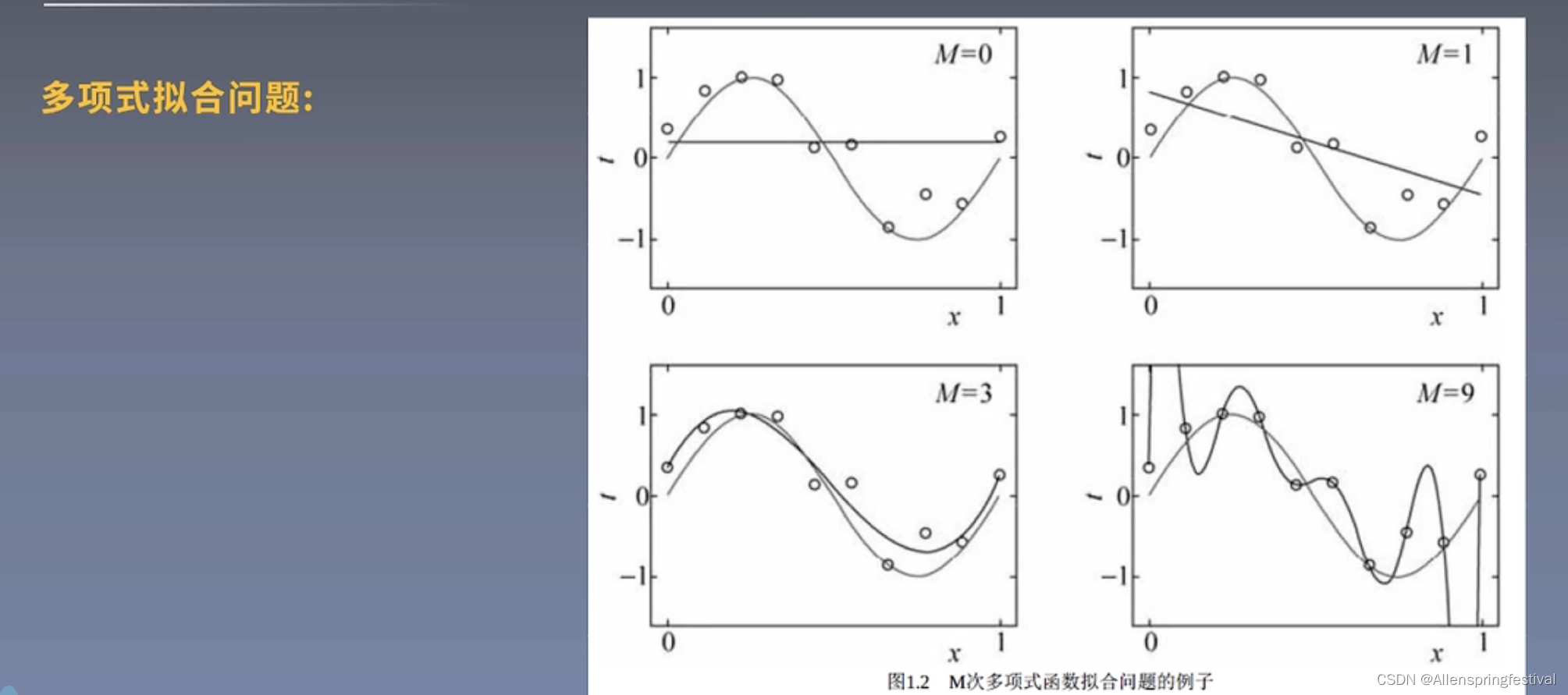
在多项式拟合问题中 :
就很好的解释了过拟合问题,我们想要去拟合一个正弦函数
我们去选择正弦函数上的点去拟合
当图像是三次函数时,拟合效果是非常不错的,但是为了抓住图像中的每一个细节
(哪怕噪音也不放过,就容易出现过拟合问题)

- 我们使用的是经验风险最小化的策略
- 经验风险使用的损失函数是平方损失
要求出最小值就需要求导,这里的二分之一只是为了抵消平方
那么如何去看是否过拟合呢?
- 他在训练集上拟合效果特别好(每个点集都在图像上)
- 但是在测试集和验证集上特别差
就是过拟合了!!!
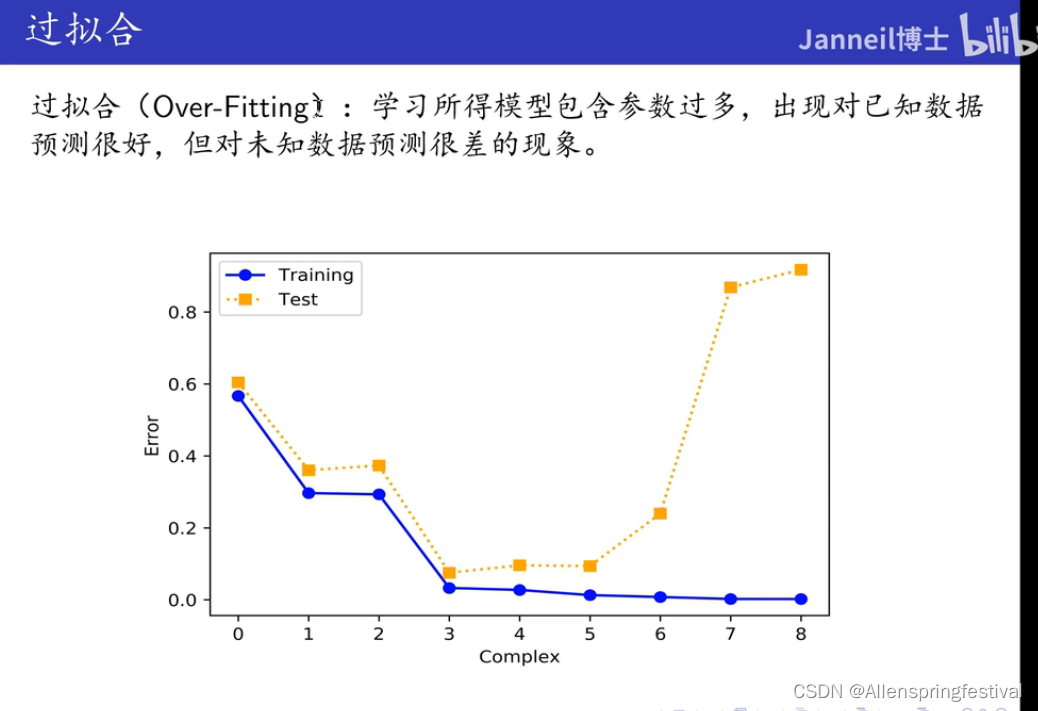
当M=9,训练误差极大,但测试误差极大
二,正则化与交叉验证
1.正则化
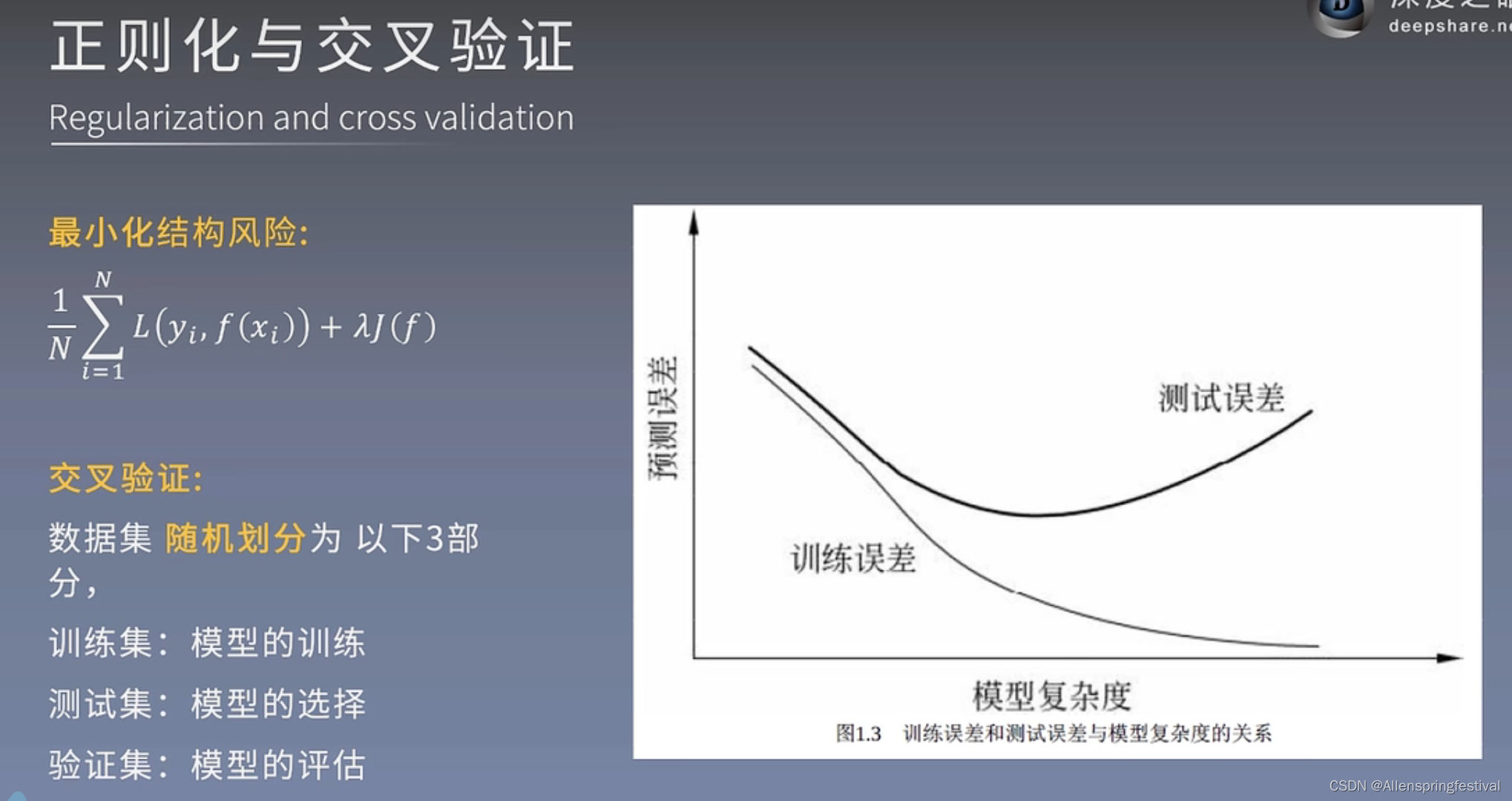
最小化结构风险中跟的就是正则项
目的:减少模型的复杂度,防止过拟合的

正则化项有两种形式:
- L1范数和L2范数
- w这里叫作参数
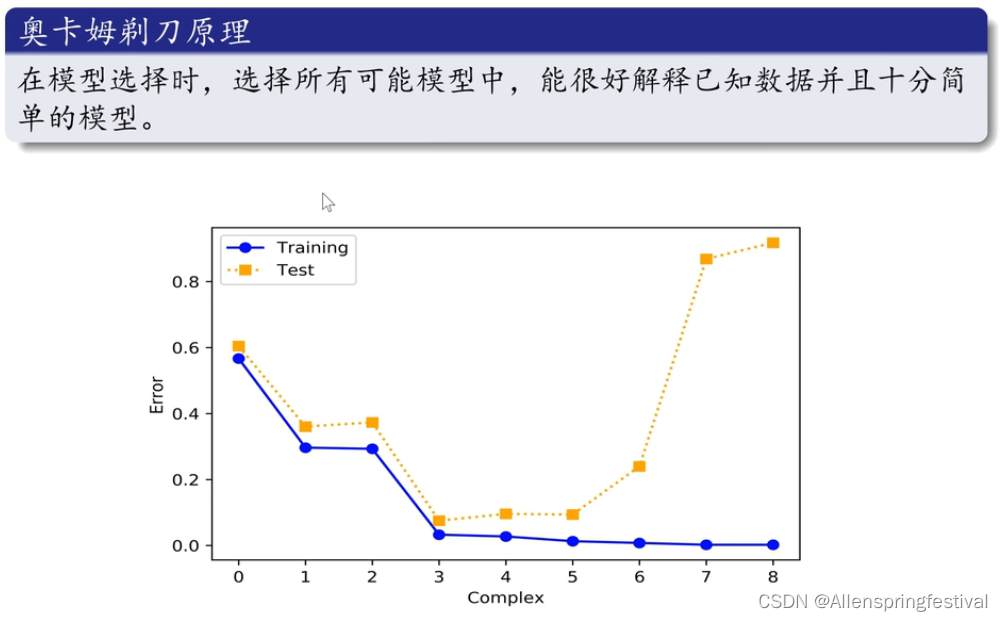
这里谈一个奥姆卡剃刀原理:
- 我们发现当模型复杂度大于等于3的时候,训练集都能很好的拟合,、
- 则选择最简单的模型
2.交叉验证
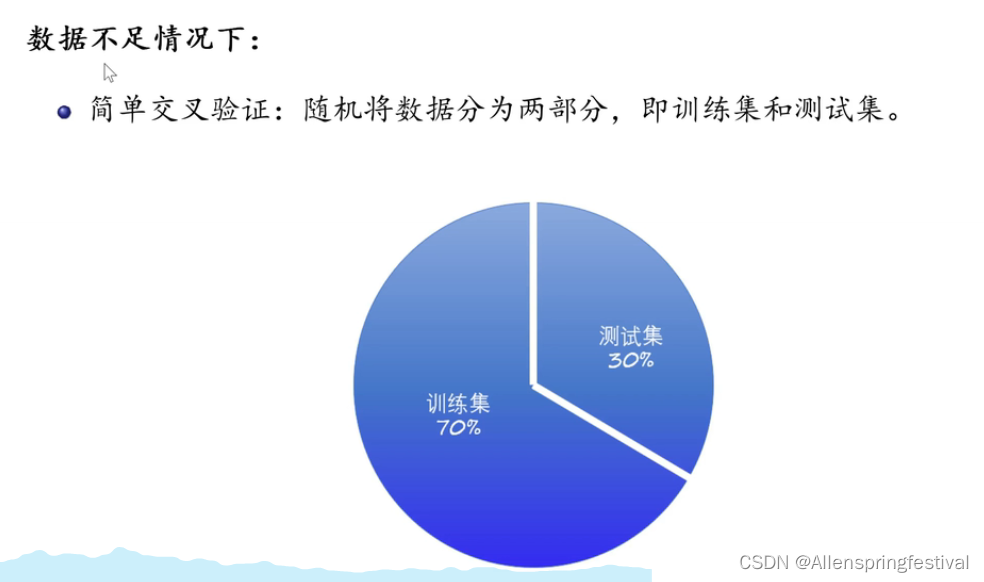
(1)简单交叉验证
(2)S折交叉验证
我们只有100个数据,一开始选择这80个数据作为训练集,剩下的是测试集和验证集
后来再随机选出80个,
选出来10种训练集进行模型训练。

选择不同的测试集去训练模型
(3)留一交叉验证
数据非常缺乏的情况下:

此时的N为数据的容量
三,泛化能力
1.泛化误差
- 泛化误差R(f)
- 就是对损失函数值loss求出其数学期望
- 泛化误差反映了学习方法的泛化能力,即所学习到的模型的期望风险。

f-hat(X)为预测值
这里我们之前学的策略里的损失函数的期望值
我们下面给出的红豆绿豆的实例
下面这个是经验风险。
2.泛化误差上界



函数f是从假设空间F中抽取出来的

那么这个泛化误差R(f)(期望风险)是有上界的。
- d代表的是假设空间中函数的个数
- N表示训练集中样本的个数
- 德尔塔则是概率
regulation
(1)当N->无穷大,样本容量增大,那么泛化误差上界就是趋向于0的。
(2)d越大,假设空间越来越复杂,那么泛化误差上界也会增大。
公式推导:
首先我们直到有以下
hoeffding不等式成立:

SN为随机变量求和
即可得: