论文链接如下:
ReadPaper https://readpaper.com/pdf-annotate/note?pdfId=4558468783967051777¬eId=740712499546066944
https://readpaper.com/pdf-annotate/note?pdfId=4558468783967051777¬eId=740712499546066944
作者信息如下:


图1:YOLOX和其他最先进的物体探测器在移动设备上的精确模型的速度-精度权衡(上)和尺寸-精度曲线(下)。
摘要
在本报告中,我们对YOLO系列进行了一些有经验的改进,形成了一种新的高性能探测器-YOLOX。我们将YOLO探测器切换到无锚点的方式,并采用了其他先进的检测技术,即解耦头部和领先的标签分配策略Simota,以在大范围的模型上实现最先进的结果:对于仅有0.91M参数和1.08G Flop的YOLONano,我们在COCO上获得了25.3%的AP,比NanoDet高出1.8%AP;对于行业中使用最广泛的检测器之一YOLOv3,我们在COCO上将其提升到47.3%AP,超过当前最佳实践3.0%AP;对于与YOLOv4CSP、YOLOv5-L参数大致相同的YOLOX-L,我们在Tesla V100上以68.9 FPS的速度在COCO上获得了50.0%的AP,比YOLOv5-L高1.8%AP。此外,我们还使用一款YOLOX-L车型获得了流媒体感知挑战赛(CVPR 2021自动驾驶研讨会)的第一名。我们希望这份报告能为开发人员和研究人员在实际场景中提供有用的经验,我们还提供支持ONNX、TensorRT、NCNN和Openvino的Deploy版本。
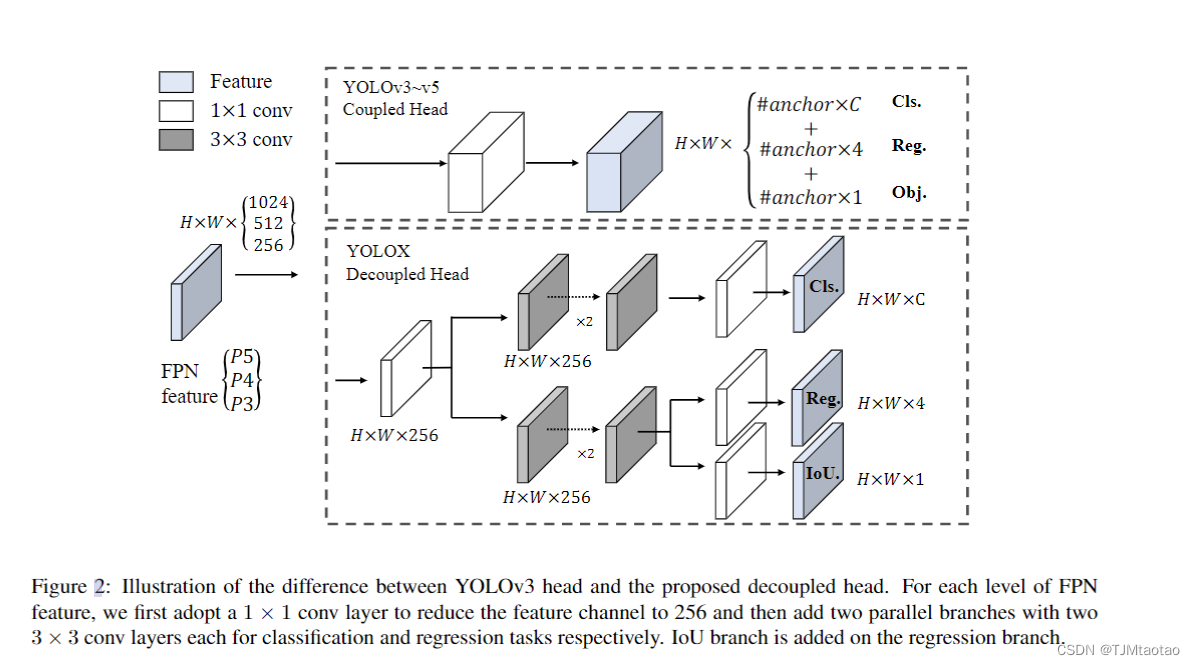
然而,在过去的两年中,目标检测学术界的主要进展集中在无锚检测器[29,40,14],高级标签分配策略[37,36,12,41,22,4],以及端到端(NMS-Free)检测器[2,32,39]。这些还没有像YOLOv4和YOLOv5那样整合到YOLO家族中仍然是基于锚的探测器,具有手工制定的训练分配规则。
1我们选择分辨率为640×640的YOLOv5-L模型,并在V100上以FP16精度和Batch=1测试模型,以使YOLOv4[1]和YOLOv4-CSP[30]的设置一致,以进行公平的比较。
这就是我们来到这里的原因,通过经验丰富的优化提供了YOLO系列的最新改进。考虑到YOLOv4和YOLOv5对于基于锚点的管道可能有点过度优化,我们选择YOLOv3[25]作为我们的起点(我们将YOLOv3-SPP设置为默认的YOLOv3)。事实上,由于有限的计算资源和在各种实际应用中软件支持的不足,YOLOv3仍然是业界使用最广泛的探测器之一。

以上YOLOX 论文阅读地址如下:ReadPaperhttps://readpaper.com/pdf-annotate/note?pdfId=4665305185141145601¬eId=740712499546066944
CSPNet论文阅读地址如下:
ReadPaperhttps://readpaper.com/pdf-annotate/note?pdfId=4500339911726620673¬eId=1908917253678481920CSPNet结构如下:
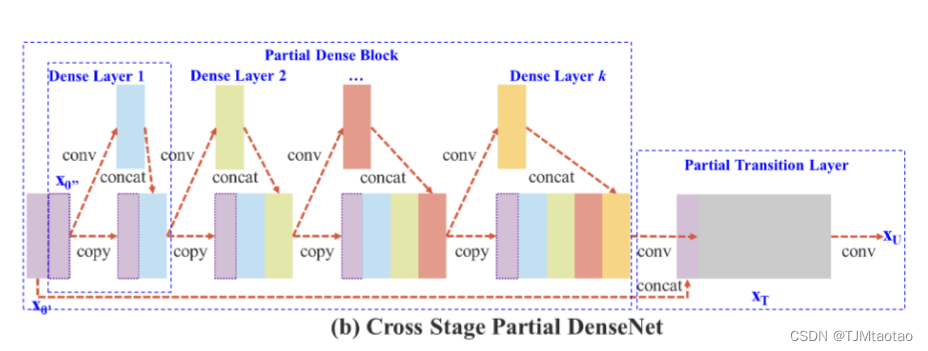
CSPNet将基层的特征图分为两部分,一部分将经过密集块和过渡层;然后将另一部分与传输的特征图组合到下一阶段。
跨阶段部分DenseNet。所提出的CSPDenseNet一阶段的体系结构如图2(B)所示。CSPDenseNet的一个阶段由部分密集块和部分过渡层组成。在部分密集块中,阶段基层的特征图通过通道 x0 = [x′0, x′′0 分为两部分。在 x′′0 和 x′0 之间,前者直接链接到阶段的末尾,后者将通过密集块。部分转换层中涉及的所有步骤如下:首先,密集层的输出 [x′′0 , x1,..., xk] 将经历一个过渡层。其次,该过渡层的输出 xT 将与 x′′0 连接并经历另一个过渡层,然后生成输出 xU。CSPDenseNet前馈传递和权值更新方程分别如式3和式4所示。

我们可以看到来自密集层的梯度是分开集成的。另一方面,没有经过密集层的特征图 x′0 也被单独集成。至于用于更新权重的梯度信息,双方不包含属于另一侧的重复梯度信息。
总体而言,所提出的CSPDenseNet保留了DenseNet的特征重用特性的优点,但同时通过截断梯度流来防止过多的重复梯度信息。这个想法是通过设计一个分层特征融合策略并在部分过渡层中使用来实现的。
部分密集块。设计部分密集块的目的是 1.) 增加梯度路径:通过拆分和合并策略,梯度路径的数量可以加倍。由于跨阶段策略,可以缓解使用显式特征图副本进行拼接带来的缺点; 2.) 每一层的平衡计算:通常,DenseNet 基础层中的通道数远大于增长率。由于部分密集块中密集层操作所涉及的基础层通道仅占原始数的一半,可以有效解决几乎一半的计算瓶颈; 3.) 减少内存流量:假设 DenseNet 中密集块的基本特征图大小为 w × h × c,增长率为 d,总共有 mdense 层。然后,该密集块的 CIO 是 (c × m) + ((m2 + m) × d)/2,部分密集块的 CIO 是 ((c × m) + (m2 + m) × d)/2。虽然 m 和 d 通常远小于 c,但部分密集块能够保存网络大部分内存流量的一半。

不同类型的特征融合策略。(a) 单个路径 DenseNet, (b) 提出了 CSPDenseNet:转换→连接→转换,(c) 连接→转换,以及 (d) 转换→连接
部分过渡层。设计部分过渡层的目的是最大化梯度组合的差异。部分过渡层是一种分层特征融合机制,它使用截断梯度流的策略来防止不同的层学习重复的梯度信息。在这里,我们设计了 CSPDenseNet 的两种变体来展示这种梯度流截断如何影响网络的学习能力。3 (c) 和 3 (d) 显示了两种不同的融合策略。CSP(首先融合)意味着连接两部分生成的特征图,然后进行转换操作。如果采用这种策略,将重用大量梯度信息。与CSP(融合最后)策略一样,密集块的输出将经过过渡层,然后与来自第1部分的特征映射进行拼接。如果采用CSP(融合最后)策略,由于梯度流被截断,梯度信息不会被重用。如果我们使用3所示的四种架构进行图像分类,则相应的结果如图4所示。可以看出,如果采用CSP(融合最后)策略进行图像分类,计算成本明显下降,但top-1准确率仅下降0.1%。另一方面,CSP(首先融合)策略确实有助于计算成本显着下降,但 top-1 准确率显着下降 1.5%。通过使用跨阶段的拆分和合并策略,我们能够有效地减少信息集成过程中重复的可能性。从图 4 所示的结果可以看出,如果可以有效减少重复的梯度信息,网络的学习能力将大大提高。
将 CSPNet 应用于其他架构。CSPNet 也可以很容易地应用于 ResNet 和 ResNeXt,架构如图 5 所示。由于只有一小部分特征通道通过 Res(X)Blocks,因此不需要再引入瓶颈层。这使得FLoating-point OPerations (FLOPs)固定时内存访问成本(MAC)的理论下限。
精确融合模型
准确查看以完美地预测。我们提出了EFM,它为每个锚点捕获适当的视场(FoV),提高了单级目标检测器的精度。对于分割任务,由于像素级标签通常不包含全局信息,因此考虑更大的补丁以获得更好的信息检索[22]通常更可取。然而,对于图像分类和目标检测等任务,当从图像级和边界框级标签中观察到时,可能会模糊一些关键信息。Li等人[15]发现,当CNN从图像级标签中学习时,CNN可能会被分散注意力,并得出结论,两级目标检测器优于一级目标检测器的主要原因之一。
聚合特征金字塔。所提出的 EFM 能够更好地聚合初始特征金字塔。EFM基于YOLOv3[29],它在每个地面真值对象之前只分配一个边界框。每个ground truth边界框对应一个超过阈值IoU的锚框。如果锚框的大小等价于网格单元的FoV,那么对于第s个尺度的网格单元,对应的边界框将的下界为第(s−1)个尺度,上界为(s + 1)个尺度。因此,EFM 从三个尺度组装特征。
平衡计算。由于特征金字塔的连接特征图是巨大的,它引入了大量的内存和计算成本。为了缓解这个问题,我们结合了 Maxout 技术来压。

不同的特征金字塔融合策略。(a) 特征金字塔网络 (FPN):融合当前尺度和先前尺度的特征。(b) 全局融合模型 (GFM):融合所有尺度的特征。(c) 精确融合模型 (EFM):融合特征 dep 和锚点大小。
PAN网络结构如下论文:
ReadPaperhttps://readpaper.com/pdf-annotate/note?pdfId=4666789975266705409¬eId=1908928993552075776 PAN结构理解:
用于实例分割的路径聚合网络(Path Aggregation Network for Instance Segmentation)
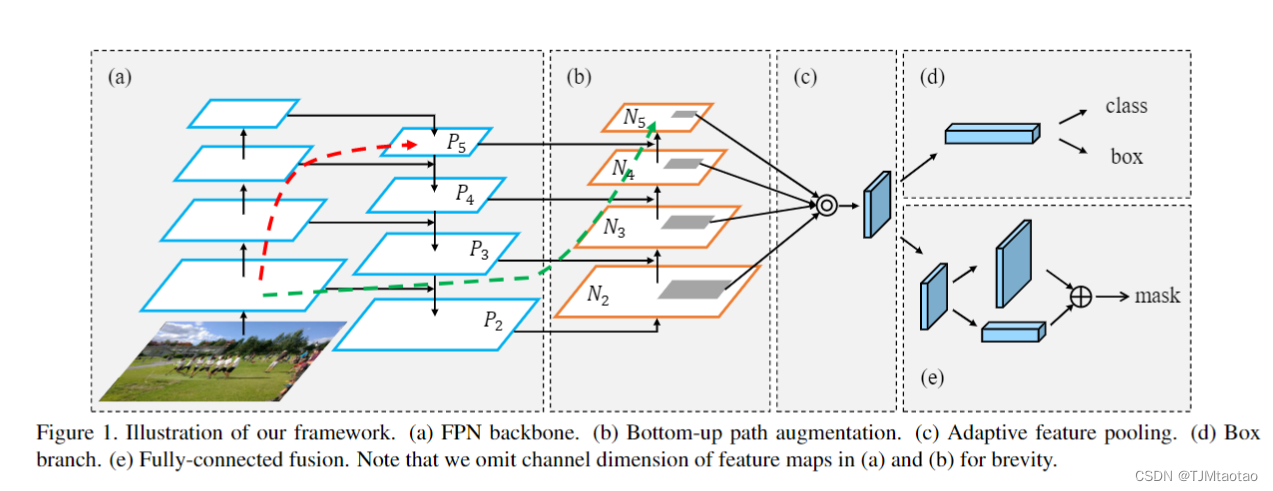
图 1 我们框架的示意图。(a) FPN 主干。(b) 自下而上的路径增强。(c) 自适应特征池。(d) Box 分支。(e) 全连接融合。请注意,为简洁起见,我们省略了 (a) 和 (b) 中特征图的通道维度。
PAN论文中的主要改进点主要是如下3点:
首先,为了缩短信息路径,1、增强特征金字塔,在低层存在精确定位信号,创建了自下而上的路径增强。事实上,[44,42,13,46,35,5,31,14]的系统中使用了低层的特征。但是没有探索传播低级特征以增强整个特征层次结构以进行实例识别。
其次,为了恢复每个提议与所有特征级别之间的损坏信息路径,我们开发了2、自适应特征池。聚合每个提案的所有特征级别的特征是一个简单的组件,避免了任意分配的结果。通过此操作,与 [4, 62] 的路径相比,创建了更清晰的路径。
最后,为了捕捉每个提案的不同视图,我们使用3、一个小的全连接 (fc) 层来增强掩码预测,该层具有与 Mask R-CNN 最初使用的 FCN 互补的属性。通过融合这两个视图的预测,产生了信息多样性的增加和质量更好的掩码。
PAN如上改进涉及的结构如下:
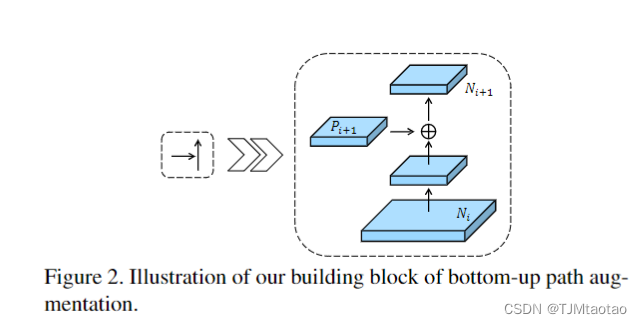
图 2. 自下而上路径增强的构建块的图示。
我们的方法旨在利用具有单尺度输入的网络内特征层次结构中所有特征级别的信息。启用端到端训练。
我们的框架如图1所示。为了提高性能,进行了路径增强和聚合。增强了自下而上的路径,使低层信息更容易传播。我们设计了自适应特征池,以允许每个提议访问来自所有级别的信息进行预测。将互补路径添加到掩码预测分支中。这种新结构导致了不错的性能。与FPN类似,改进与CNN结构无关,例如[57,32,23]。
1、自下而上的路径增强
动机 富有洞察力的点 [63] 高层中的神经元强烈响应整个对象,而其他神经元更有可能被局部纹理和模式激活,这表明增加自上而下的路径以传播语义强特征并提高所有特征在 FPN 中具有合理分类能力。
我们的框架通过传播低级模式的强响应进一步增强了整个特征层次结构的定位能力,因为对边缘或实例部分的高响应是准确定位实例。为此,我们构建了一个从低级到顶层具有干净横向连接的路径。因此,在这些级别上,有一个“快捷方式”(图 1 中的虚线绿线),它由少于 10 层组成。相比之下,FPN 中的 CNN 主干提供了一条长路径(图 1 中的红色虚线),通过从低层到最顶层的偶数 100+ 层。
增强自底向上结构 我们的框架首先完成自下而上的路径增强。我们遵循 FPN 来定义生成具有相同空间大小的特征图的层在同一个网络阶段。每个特征级别对应一个阶段。我们还将 ResNet [23] 作为基本结构,并使用 {P2, P3, P4, P5} 来表示 FPN 生成的特征级别。我们的增强路径从最低级别 P2 开始,并逐渐接近 P5,如图 1(b) 所示。从 P2 到 P5,空间大小以因子 2 逐渐下采样。我们使用 {N2, N3, N4, N5} 来表示对应于 {P2, P3, P4, P5} 的新生成的特征图。请注意,N2 是 simpleP2,没有任何处理。
如图2所示,每个构建块通过横向连接获取更高分辨率的特征映射Ni和较粗的映射Pi+1,生成新的特征映射Ni+1。每个特征映射Ni首先通过步长为2的3×3卷积层来减小空间大小。然后通过横向连接添加特征图 Pi+1 和下采样图的每个元素。然后将融合后的特征图由另一个 3×3 卷积层处理,为以下子网络生成 Ni+1。这是一个迭代过程,在接近 P5 后终止。在这些构建块中,我们始终使用 256 个通道的特征图。所有卷积层后面都有一个 ReLU [32]。然后将每个提案的特征网格从新的特征图汇集,即 {N2, N3, N4, N5}。
2、自适应特征池
在FPN[35]中,根据建议的大小,建议被分配到不同的特征级别。它使分配给低特征级别的小建议和大建议分配给更高的建议。尽管简单有效,但它仍然可以生成非最佳结果。例如,可以将两个具有 10 像素差异的提议分配给不同的级别。事实上,这两个建议非常相似
此外,特征的重要性可能与它们所属的级别密切相关。高级特征是用大的感受野生成的,并捕获更丰富的上下文信息。允许小建议访问这些特征可以更好地利用有用的上下文信息进行预测。同样,低级特征具有许多精细细节和高定位精度。让大型提案访问它们显然是有益的。有了这些想法,我们建议从每个级别汇集特征并将它们融合以进行以下预测。我们将此过程称为自适应特征池。
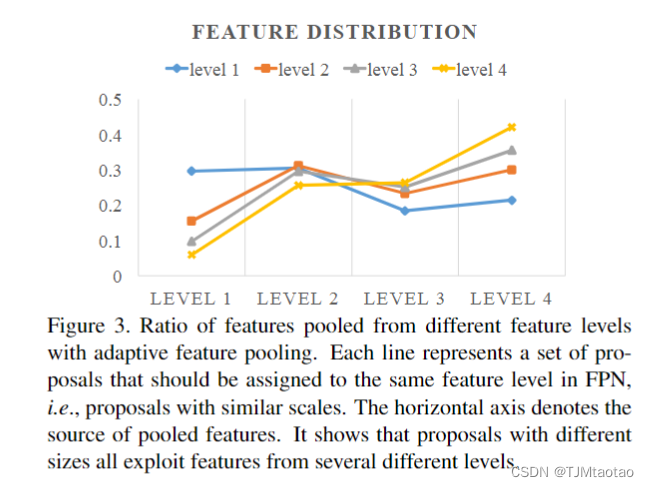
我们现在通过自适应特征池分析从不同级别汇集的特征的比率。我们使用 maxoperation 来融合来自不同级别的特征,这允许网络选择元素的有用信息。我们根据提案最初分配给 FPN 中的级别将提案聚类为四个类别。对于每组建议,我们计算从不同级别选择的特征的比率。在符号中,级别 1 - 4 表示低到高的水平。如图3所示,蓝线表示最初在FPN中分配给第1级的小建议。令人惊讶的是,近 70% 的特征来自其他更高级别的。我们还使用黄色线表示在 FPN 中分配给第 4 级的大型提案。同样,50%+ 的特征从其他较低级别汇集。这一观察清楚地表明,多个级别的特征一起有助于准确预测。这也是设计自底向上路径增强的有力支持。
自适应特征池结构 自适应特征池的实现实际上很简单,如图1(c)所示。首先,对于每个提议,我们将它们映射到不同的特征级别,如图 1(b) 中的深灰色区域所示。在 Mask R-CNN [21] 之后,ROIAlign 用于从每个级别汇集特征网格。然后使用融合操作(element-wise max或sum)来融合不同层次的特征网格。
在接下来的子网络中,池化的特征网格独立地通过一个参数层,然后是融合操作,使网络能够适应特征。例如,FPN 中的框分支中有两个 fc 层。我们在第一层之后应用融合操作。由于 Mask R-CNN 中的掩码预测分支中使用了四个连续的卷积层,我们在第一和第二卷积层之间放置了融合操作。融合特征网格被用作每个提案的特征网格,用于进一步预测,即分类、框回归和掩码预测。附录中的图 6 显示了框分支上自适应特征池的详细说明。
我们的设计侧重于融合来自网络内特征层次结构的信息,而不是来自输入图像金字塔的不同特征图的信息 [52]。与 [4, 62, 31] 的过程相比,它更简单,其中需要 L-2 归一化、连接和降维。
3、全连接融合
动机 全连接层或 MLP 广泛用于实例分割 [10, 41, 34] 和掩码提议生成 [48, 49] 中的掩码预测。[8, 33] 的结果表明,FCN 也能够预测实例的像素级掩码。最近,Mask R-CNN [21] 在池化特征网格上应用了一个微小的 FCN 来预测相应的掩码,以避免类之间的竞争。
我们注意到,与 FCN 相比,fc 层产生不同的属性,后者基于局部感受野对每个像素进行预测,并且参数在不同的空间位置共享。相反,fc 层是位置敏感的,因为不同空间位置的预测是通过不同的参数集实现的。所以它们有能力适应不同的空间位置。此外,利用整个提案的全局信息对每个空间位置进行预测。区分实例[48]并识别属于同一对象的单独部分是有帮助的。给定 fc 和卷积层的属性彼此不同,我们融合来自这两种类型的层的预测以获得更好的掩码预测。
掩码预测结构
我们的掩码预测组件是轻量级的,易于实现。掩码分支对每个提议的池化特征网格进行操作。如图 4 所示,主路径是一个小型 FCN,它由 4 个连续的卷积层和 1 个反卷积层组成。每个卷积层由256 3 × 3滤波器和反卷积层上采样特征组成,因子为2。它独立地预测每个类的二进制像素级掩码,以解耦分割和分类,类似于Mask R-CNN。我们进一步从层 conv3 到 fc 层创建一条短路径。有两个 3 × 3 卷积层,其中第二个将通道缩小到一半以减少计算开销。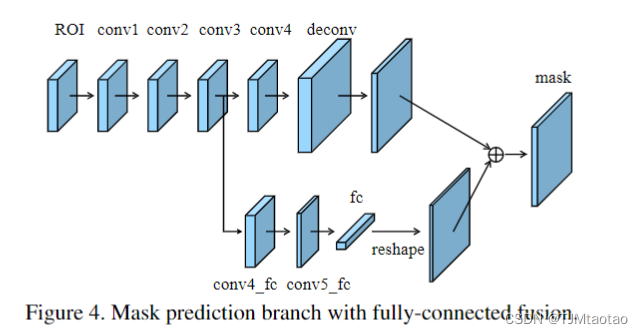
fc 层用于预测与类别无关的前景/背景掩码。它不仅是有效的,而且还允许用更多样本进行训练的 fc 层中的参数,从而获得更好的通用性。我们使用的掩码大小为28 × 28,使fc层产生784 × 1 × 1向量。该向量被重新整形为与 FCN 预测的掩码相同的空间大小。为了获得最终的掩码预测,添加了FCN中每个类的掩码和来自fc的前景/背景预测。仅使用一个fc层,而不是多个fc层进行最终预测,可以防止隐藏空间特征映射折叠成一个短特征向量的问题,从而丢失空间信息。
SiLu激活函数
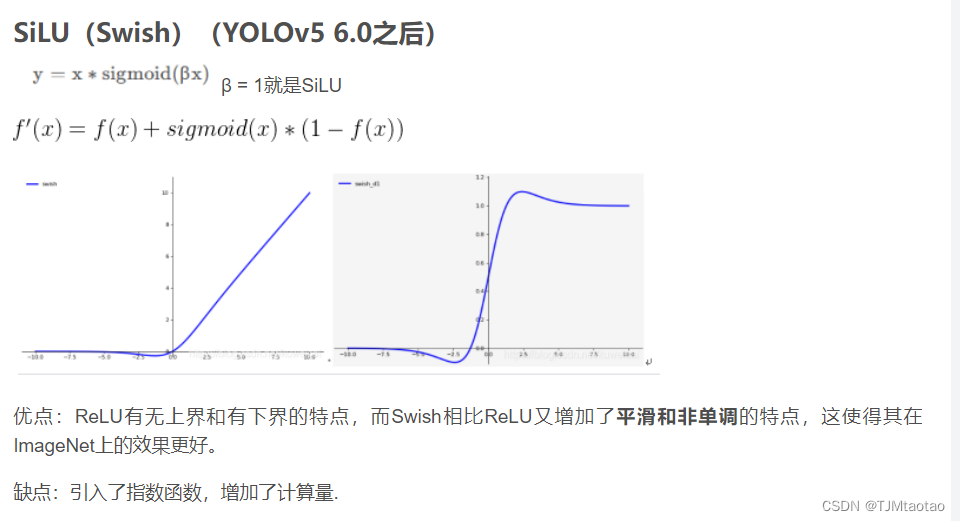
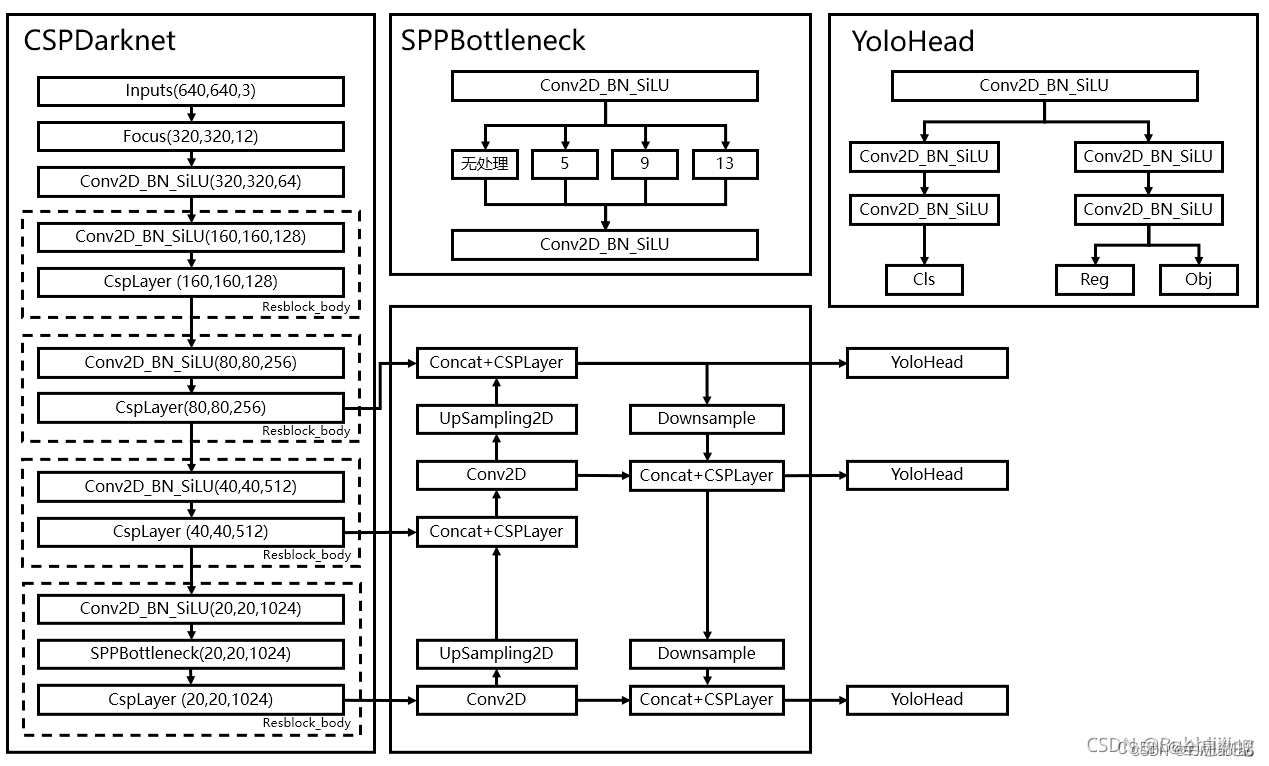
综上YOLOX结构:
YoloX的网络结构如下,除了YoloHead采用了回归和分类的解耦,其他网络结构和YoloV5相同,