Python文本处理尝试
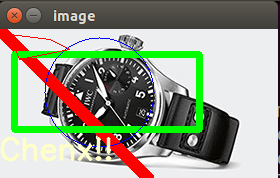
最近打算看CSAPP,GitHub上看到有英语字幕ass源文件,想把字幕提取出来提高学习效率,先把ass文件转成txt文件,发现是这样👇
都在Dialogue的后面,打算尝试提取一下

-
不太熟练,下面是随便想的思路
- 文件读入一整个字符串,然后从[Events]那里开始截断了,再做后续处理
- 文件逐行读入字符串列表,然后定位到[Events]那里,查看它的index,然后用切片把后面的取出来,然后再对每个dialogue用切片或者什么split啥的把后面的字幕取出来(切片也可以,因为前面的格式固定,好数的)
-
先试试上面第二种思路这种
参考教程:Python 逐行读取txt 文件并生成列表
txt_list = [] with open("Lecture 01.txt", "r", encoding="utf-8") as f: # 打开文件 # data = f.read() # 读取文件 # print(data) line = f.readline() while line: txt_list.append(line) line = f.readline() # print(txt_list) print(len(txt_list))打印行数是847,那应该问题不大
-
找出[Events]是第几个
参考:python查找列表元素位置
print(txt_list.index('[Events]\n'))是29,那么从31开始取

-
看看每句话的后面是从哪里开始切片
txt_filtered = txt_list[31:] # print(txt_filtered) print(txt_filtered[0][50:]) print(txt_filtered[1][50:])试了几次20,40,试出来是从50开始那么就好办了

-
接下来对txt_filtered每个元素进行相同切片操作就行了, for循环或lambda表达式,我选后者
参考:使用 lambda 表达式实现对列表中的元素求平方
txt_result = list(map(lambda x:x[50:-1],txt_filtered)) # print(txt_result) for item in txt_result: print(item)左闭右开,最右边是换行符
\n,-1是为了把换行符去掉芜湖!

-
接下来我要把这个列表写入文本文件
参考:Python学习-将list列表写入文件并读取方法汇总
-
试试
writelines()# https://blog.csdn.net/zwt0909/article/details/52268717 # https://blog.csdn.net/nanjunxiao/article/details/9086079 # https://blog.csdn.net/weixin_40973138/article/details/106209020?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522167090820216800192239538%2522%252C%2522scm%2522%253A%252220140713.130102334..%2522%257D&request_id=167090820216800192239538&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~all~top_positive~default-2-106209020-null-null.142^v68^js_top,201^v4^add_ask,213^v2^t3_control1&utm_term=python%E9%80%90%E8%A1%8C%E8%AF%BB%E5%8F%96txt%E6%96%87%E4%BB%B6&spm=1018.2226.3001.4187 txt_list = [] with open("Lecture 01.txt", "r", encoding="utf-8") as f: # 打开文件 # data = f.read() # 读取文件 # print(data) line = f.readline() while line: txt_list.append(line) line = f.readline() # print(txt_list) # print(len(txt_list)) print(txt_list.index('[Events]\n')) txt_filtered = txt_list[31:] # print(txt_filtered) print(txt_filtered[0][50:]) print(txt_filtered[1][50:]) txt_result = list(map(lambda x:x[50:-1],txt_filtered)) # print(txt_result) for item in txt_result: print(item) fp = open("lec01 course overview.txt","w") fp.writelines(txt_result) fp.close()不是想要的效果,全都挤在一坨了
-
writelines括号里修改一下
参考:python writelines换行_写入文件writelines 换行问题
txt_list = [] with open("Lecture 01.txt", "r", encoding="utf-8") as f: # 打开文件 # data = f.read() # 读取文件 # print(data) line = f.readline() while line: txt_list.append(line) line = f.readline() # print(txt_list) # print(len(txt_list)) print(txt_list.index('[Events]\n')) txt_filtered = txt_list[31:] # print(txt_filtered) print(txt_filtered[0][50:]) print(txt_filtered[1][50:]) txt_result = list(map(lambda x:x[50:-1],txt_filtered)) # print(txt_result) for item in txt_result: print(item) fp = open("提取字幕\lec01 course overview.txt","w") fp.writelines([line+'\n' for line in txt_result]) fp.close()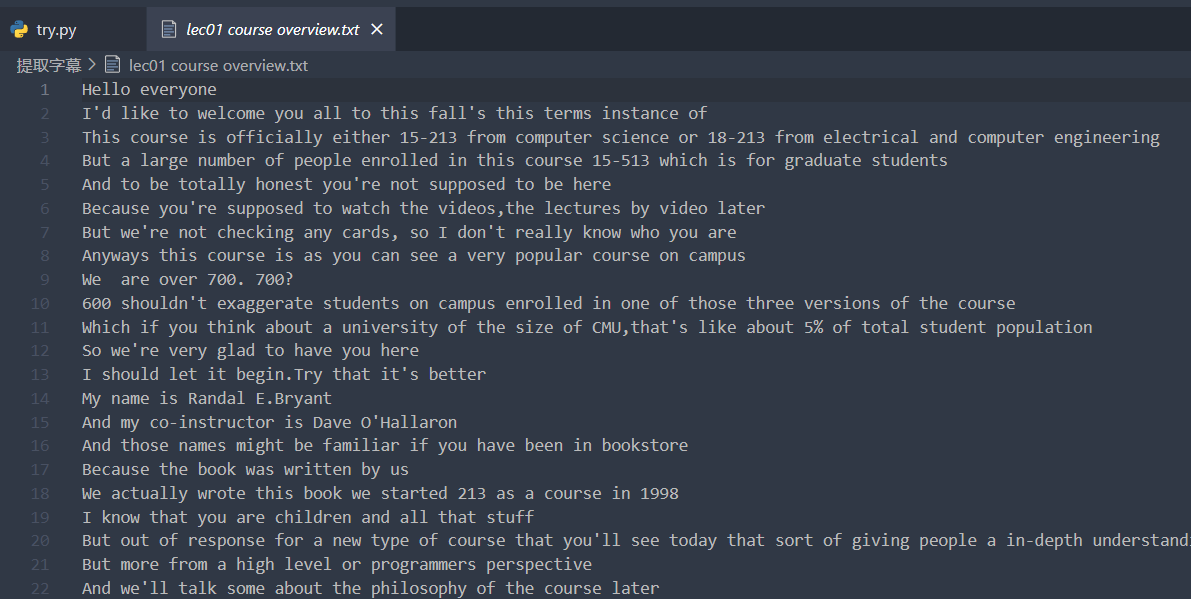
实现了,不过这样有点好玩哈哈哈😂,这样还不如之前切片的时候不去掉换行符,因为前面去掉了后面还要加上😂
-
-
还想再进一步处理,我想写入txt后,把后缀名改为.md,然后直接变成无序列表,那么就是在每一行前面加上
-和一个空格,改一行代码即可👇
fp.writelines(['- '+ line+'\n' for line in txt_result])好耶!

-
改为markdown👇

-
另外,直接复制markdown的源代码到CSDN编辑器好像比导入md文件更不容易丢失图床的图片还有格式???


![[附源码]Node.js计算机毕业设计订餐系统Express](https://img-blog.csdnimg.cn/cd6914ba84e44924a21598f43cd9d244.png)
![[附源码]Python计算机毕业设计电商后台系统Django(程序+LW)](https://img-blog.csdnimg.cn/6daebcca540b4c40b4aa8ad94e8f7442.png)