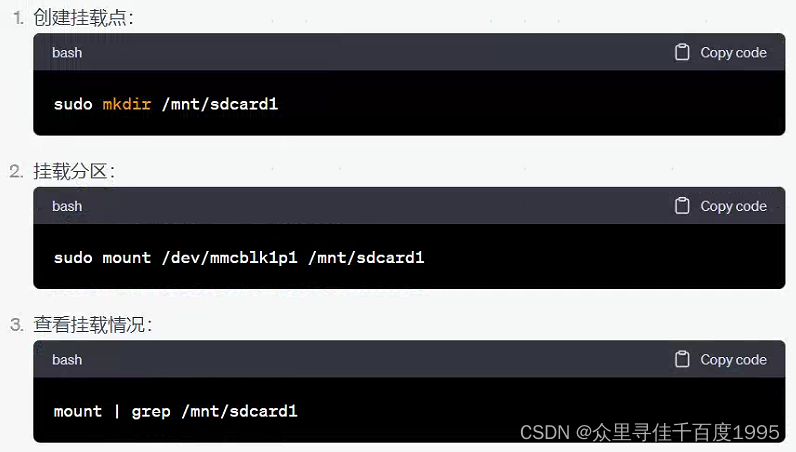
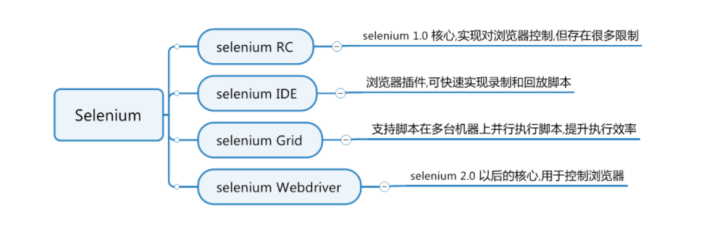
今天是HW第一天,下午运维人员说鉴权服务上不去了,看了眼天宫,结果重启了,后来的情况就是20多分钟半小时一重启,真么神奇。开始排查原因:
1、前两天发版换的agent版本发布,但是不知道有没有这个原因,Haox说到我这儿都发版第10个了,应该没啥问题。我就继续找原因。
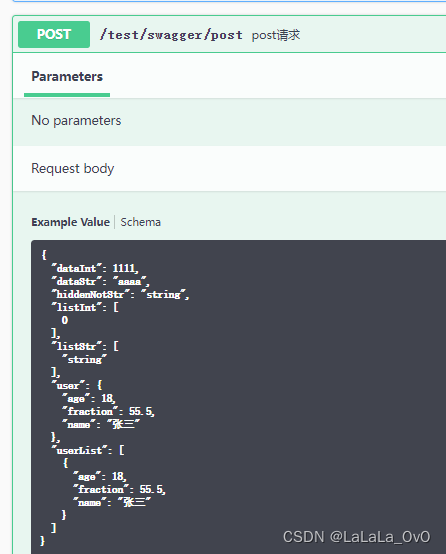
2、截了个图,说上次报错原因:
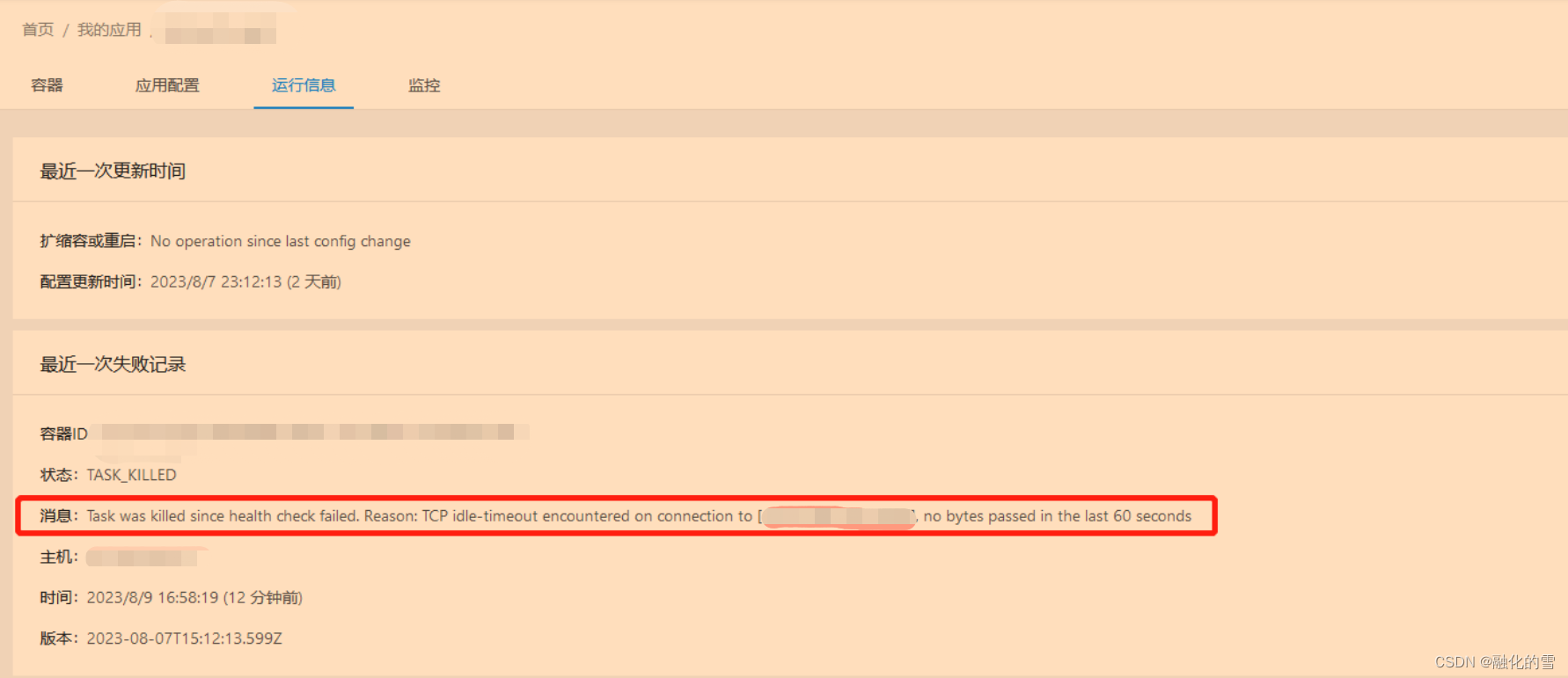
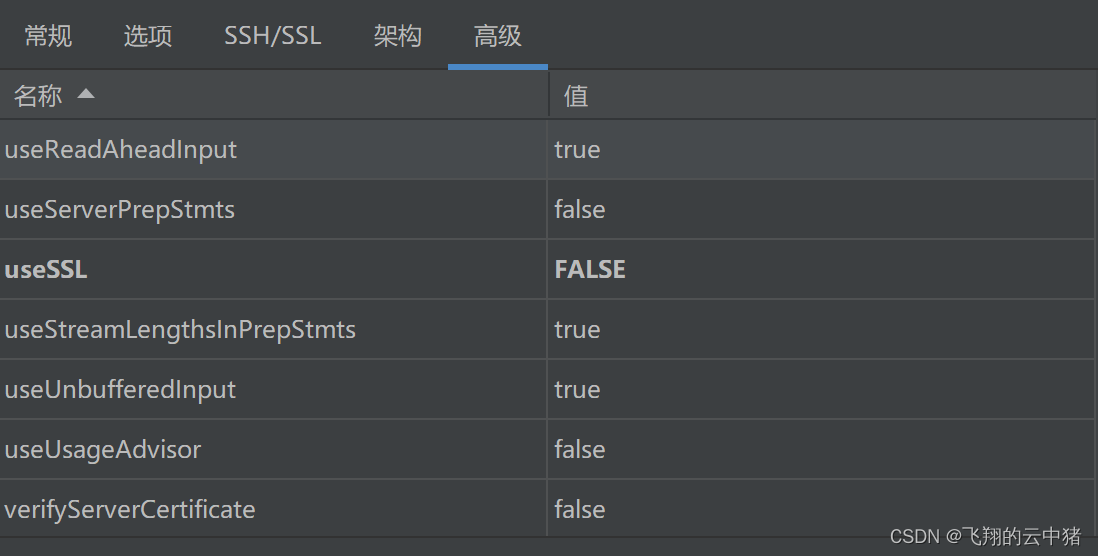
3、这么看的话就是健康检查突然不好使了,天G的问题?我就去群里问了问,天G那边的人也没说出个123来,还问我有没有业务报错,我说就是正常报错,也不至于健康检查不好使吧。
4、Haox说有可能是内存溢出导致的,我就去监控了一下内存,一直非常正常。然后就突然又不好使重启了,崩溃的时候 内存如图:
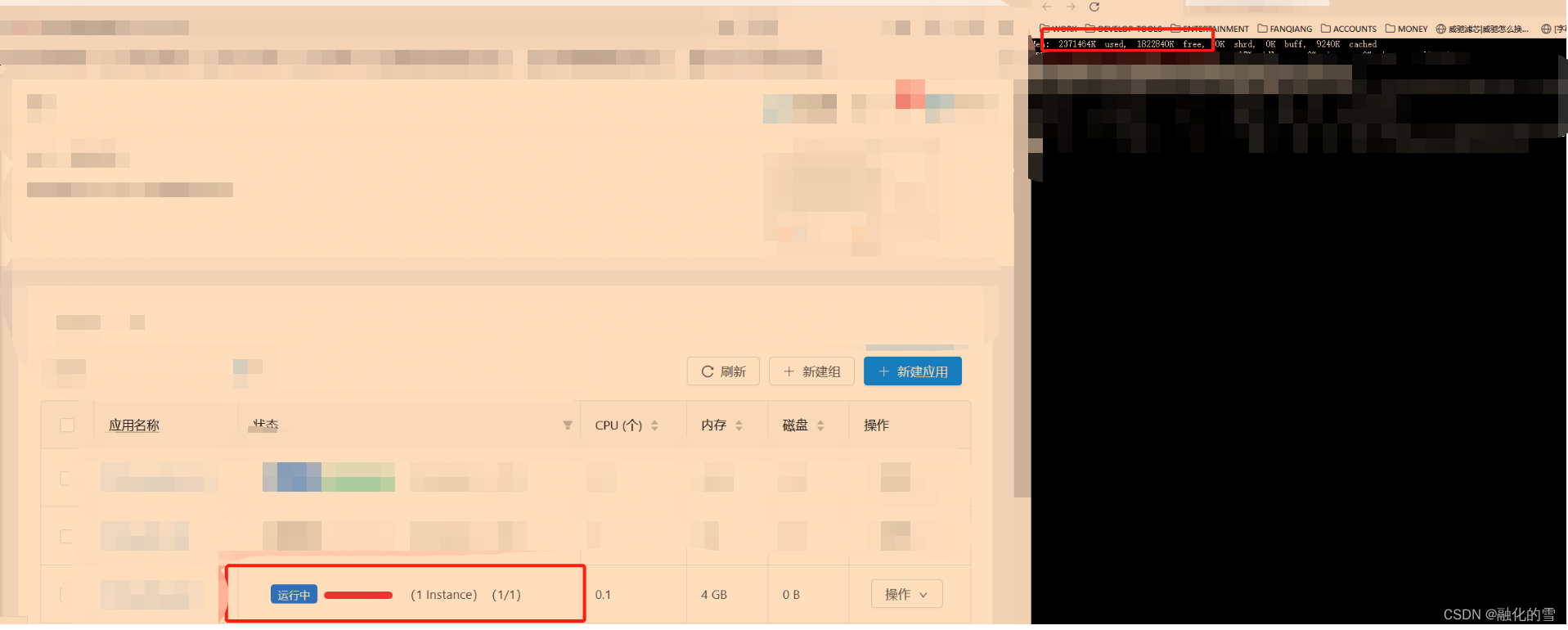
5、此时实例又突然不好使了,但是内存完全没有增长。那就不是内存的事儿。
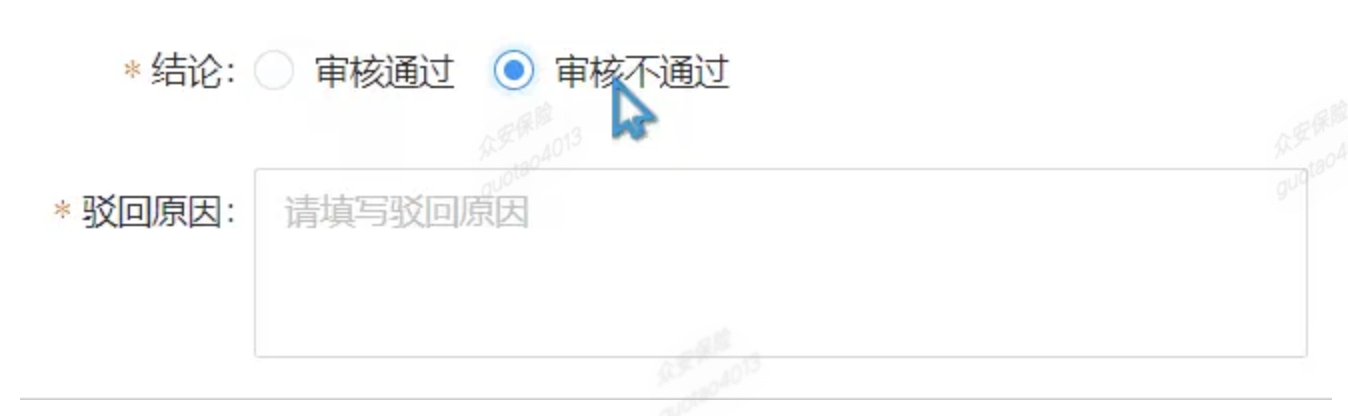
6、我就详细查了一下日志文件,发现报同步用户的接口报错,报超时的错误:
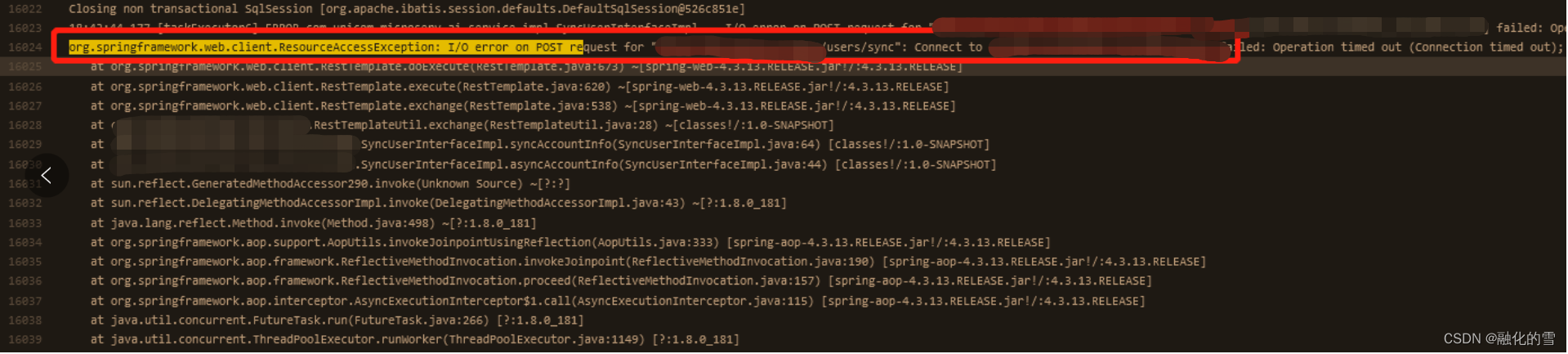
7、这个错误特别多,我数了一下,3分钟内报了34次,也就是说新增了34个人员,同步了34次接口,都没有访问通,平均1分钟10个,6秒钟一个超时。有没有可能是这个超时特别多,把tcp给堵了。
8、晚上回家本来准备扩容,结果我找总部修改了这个同步用户的地址。完全不报错了,而且也不自动重启了,截止到交稿时已经一个小时没重启了,之前20多分钟就重启一次。
9、前两天领导还找我谈话,说写代码,一定要做好预案,如果出了问题,如何在第一时间抢通,再排查问题,我感觉这个太重要了。反思了一下,如果之前做好预案,如何能不走这个接口,把判断配置文件中的url是否为空,如果为空就不走,这样是不是就可以做出预案了,而且能够及时响应排查。
10、以后写代码,都要想着,如果不走这儿,如果报错,的预案。

![[C初阶笔记]P1](https://img-blog.csdnimg.cn/16541d45b4934e33b959eeaad4aafe16.png)