系列文章目录
PyTorch深度学习——Anaconda和PyTorch安装
Pytorch深度学习-----数据模块Dataset类
Pytorch深度学习------TensorBoard的使用
Pytorch深度学习------Torchvision中Transforms的使用(ToTensor,Normalize,Resize ,Compose,RandomCrop)
Pytorch深度学习------torchvision中dataset数据集的使用(CIFAR10)
Pytorch深度学习-----DataLoader的用法
Pytorch深度学习-----神经网络的基本骨架-nn.Module的使用
Pytorch深度学习-----神经网络的卷积操作
Pytorch深度学习-----神经网络之卷积层用法详解
Pytorch深度学习-----神经网络之池化层用法详解及其最大池化的使用
Pytorch深度学习-----神经网络之非线性激活的使用(ReLu、Sigmoid)
Pytorch深度学习-----神经网络之线性层用法
Pytorch深度学习-----神经网络之Sequential的详细使用及实战详解
Pytorch深度学习-----损失函数(L1Loss、MSELoss、CrossEntropyLoss)
Pytorch深度学习-----优化器详解(SGD、Adam、RMSprop)
文章目录
- 系列文章目录
- 一、常见的现有网络模型
- 二、VGG16模型
一、常见的现有网络模型
- AlexNet: AlexNet是一个经典的卷积神经网络模型,由Alex Krizhevsky等人提出。它是在ImageNet数据集上取得突破性性能的模型,具有8个卷积层和3个全连接层。
- VGG: VGG是由Karen Simonyan和Andrew Zisserman提出的一系列卷积神经网络模型。它以其简单而深层的架构而闻名,有16层或19层的变种。VGG模型以其强大的特征提取能力而受到广泛使用。
- ResNet: ResNet是由Kaiming He等人提出的深度残差网络。它通过引入残差连接解决了深层网络训练中的梯度消失和梯度爆炸问题。ResNet模型具有不同深度的变种,如ResNet-18、ResNet-34、ResNet-50等。
- DenseNet: DenseNet是由GaoHuang等人提出的一种密集连接卷积神经网络模型。它的特点是在网络中的每一层都与所有后续层进行连接,从而增加了信息传递和特征重用的效果。
- Inception: Inception是由ChristianSzegedy等人提出的一系列卷积神经网络模型,其中包含了多种并行的卷积分支。Inception模型以其高效的计算和强大的表示能力而受到广泛关注。
- MobileNet: MobileNet是一系列轻量级的卷积神经网络模型,旨在在计算资源受限的环境下实现高效的计算。MobileNet模型通过深度可分离卷积等技术来减少参数量和计算量。
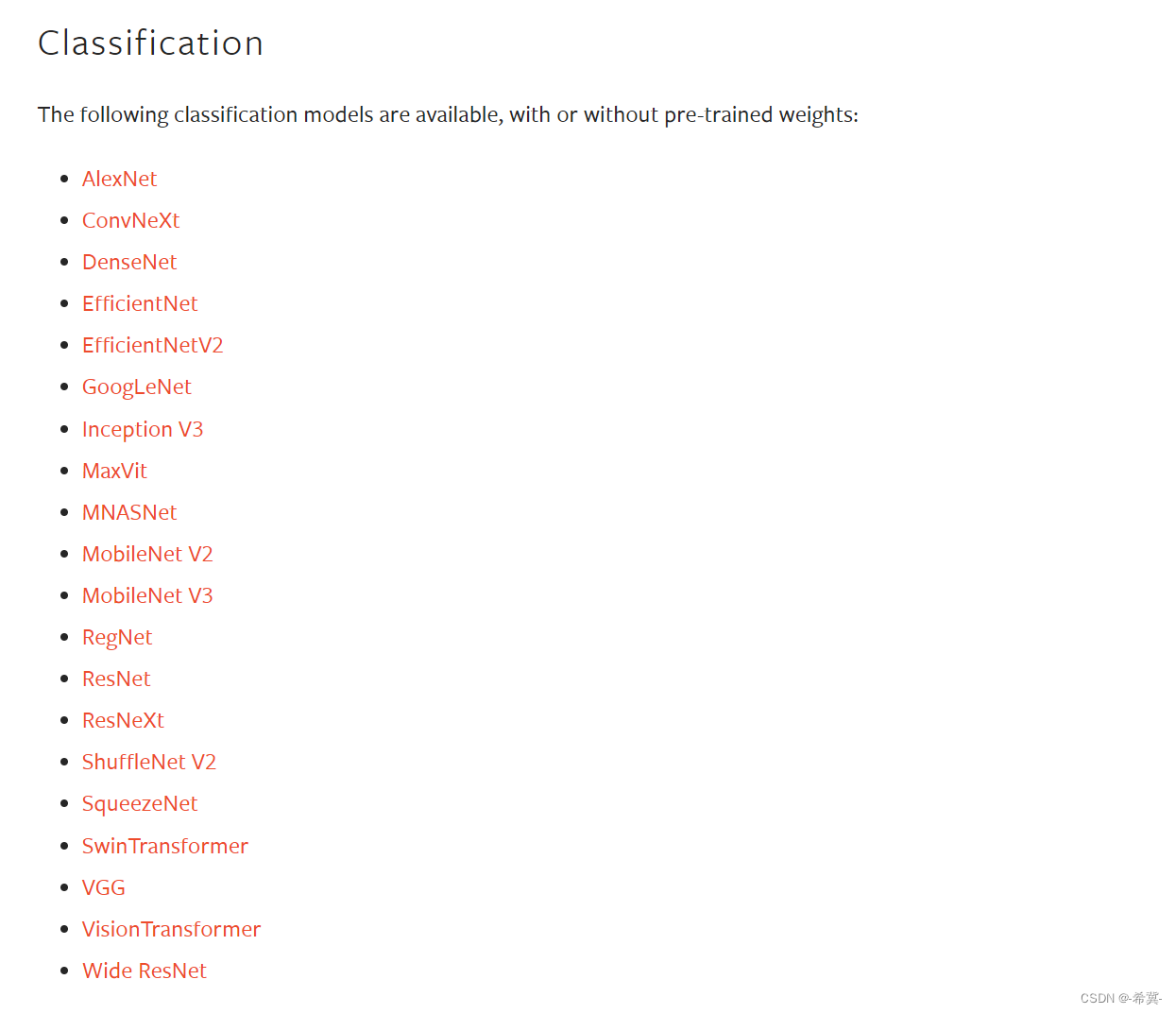
注意:PyTorch通过torchvision.models模块提供了更多的预训练模型.
官网的预训练模型有如下几种:
二、VGG16模型
torchvision.models.vgg16(*, weights: Optional[VGG16_Weights] = None, progress: bool = True, **kwargs: Any)
VGG-16是一种具有16个卷积层和3个全连接层的卷积神经网络模型,由Karen Simonyan和Andrew Zisserman在2014年提出。
参数如下:
weights(可选):指定要加载的预训练权重。可以是None(默认值)表示不加载预训练权重,或是指定为预定义的某个预训练权重标识符。
progress:指示下载进度条的显示设置,默认为True显示下载进度条。
**kwargs:其它可选参数,传递给VGG-16模型的基类torchvision.models.VGG。
创建VGG16模型并打印输出结果
VGG(
(features): Sequential(
(0): Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU(inplace=True)
(2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(3): ReLU(inplace=True)
(4): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(5): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(6): ReLU(inplace=True)
(7): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(8): ReLU(inplace=True)
(9): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(10): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(11): ReLU(inplace=True)
(12): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(13): ReLU(inplace=True)
(14): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(15): ReLU(inplace=True)
(16): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(17): Conv2d(256, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(18): ReLU(inplace=True)
(19): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(20): ReLU(inplace=True)
(21): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(22): ReLU(inplace=True)
(23): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(24): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(25): ReLU(inplace=True)
(26): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(27): ReLU(inplace=True)
(28): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(29): ReLU(inplace=True)
(30): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(avgpool): AdaptiveAvgPool2d(output_size=(7, 7))
(classifier): Sequential(
(0): Linear(in_features=25088, out_features=4096, bias=True)
(1): ReLU(inplace=True)
(2): Dropout(p=0.5, inplace=False)
(3): Linear(in_features=4096, out_features=4096, bias=True)
(4): ReLU(inplace=True)
(5): Dropout(p=0.5, inplace=False)
(6): Linear(in_features=4096, out_features=1000, bias=True)
)
)
VGG(
(features): Sequential(
(0): Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU(inplace=True)
(2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(3): ReLU(inplace=True)
(4): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(5): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(6): ReLU(inplace=True)
(7): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(8): ReLU(inplace=True)
(9): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(10): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(11): ReLU(inplace=True)
(12): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(13): ReLU(inplace=True)
(14): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(15): ReLU(inplace=True)
(16): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(17): Conv2d(256, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(18): ReLU(inplace=True)
(19): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(20): ReLU(inplace=True)
(21): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(22): ReLU(inplace=True)
(23): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(24): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(25): ReLU(inplace=True)
(26): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(27): ReLU(inplace=True)
(28): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(29): ReLU(inplace=True)
(30): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(avgpool): AdaptiveAvgPool2d(output_size=(7, 7))
(classifier): Sequential(
(0): Linear(in_features=25088, out_features=4096, bias=True)
(1): ReLU(inplace=True)
(2): Dropout(p=0.5, inplace=False)
(3): Linear(in_features=4096, out_features=4096, bias=True)
(4): ReLU(inplace=True)
(5): Dropout(p=0.5, inplace=False)
(6): Linear(in_features=4096, out_features=1000, bias=True)
)
)
从上述运行结果可知:VGG16网络是由13层卷积层和3层全连接层组成,最后网络输出一共有1000个分类结果。
修改VGG16模型结构
使用add_module()方法在VGG16模型后增加一个线性层,实现将VGG16的1000个类别输出为类似CIFAR10的10个类别,代码如下:
import torchvision.models as models
from torch import nn
vgg16_true = models.vgg16(weights=True)
vgg16_false = models.vgg16(weights=False)
# print(vgg16_false)
vgg16_true.add_module("add_linear", nn.Linear(1000, 10))
print(vgg16_true)
运行结果如下:
VGG(
(features): Sequential(
(0): Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU(inplace=True)
(2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(3): ReLU(inplace=True)
(4): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(5): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(6): ReLU(inplace=True)
(7): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(8): ReLU(inplace=True)
(9): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(10): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(11): ReLU(inplace=True)
(12): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(13): ReLU(inplace=True)
(14): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(15): ReLU(inplace=True)
(16): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(17): Conv2d(256, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(18): ReLU(inplace=True)
(19): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(20): ReLU(inplace=True)
(21): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(22): ReLU(inplace=True)
(23): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(24): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(25): ReLU(inplace=True)
(26): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(27): ReLU(inplace=True)
(28): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(29): ReLU(inplace=True)
(30): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(avgpool): AdaptiveAvgPool2d(output_size=(7, 7))
(classifier): Sequential(
(0): Linear(in_features=25088, out_features=4096, bias=True)
(1): ReLU(inplace=True)
(2): Dropout(p=0.5, inplace=False)
(3): Linear(in_features=4096, out_features=4096, bias=True)
(4): ReLU(inplace=True)
(5): Dropout(p=0.5, inplace=False)
(6): Linear(in_features=4096, out_features=1000, bias=True)
)
(add_linear): Linear(in_features=1000, out_features=10, bias=True)
)
由上述可以知道,add_linear是在classifier外面的,如果要在classifier里面,可以将
vgg16_true.add_module("add_linear", nn.Linear(1000, 10))
替换为
vgg16_true.classifier.add_module("add_linear", nn.Linear(1000, 10))