【论文研读】MARLlib: A Scalable Multi-agent Reinforcement Learning Library
和尚念经
多智能体强化学习框架研究。
多智能体强化学习库。
多智能体强化学习算法实现。
多智能体强化学习环境的统一化,标准化。
多智能体强化学习算法解析。
多智能体强化学习 算法性能比较。
3. MARLlib Architecture
在本节中,我们将主要阐述MARLlib如何解决两个主要挑战,即MARL算法的多样性和环境接口的不一致性。为了克服这些挑战,我们开发了一个新的代理级分布式数据流、一个统一的代理环境接口和一个有效的策略映射机制。其他特性,如框架可扩展性、特定于任务的技巧和文档可以在附录中找到。
3.1 agent级的分布式数据流,方便算法的统一
集中式训练分散执行(CTDE)是解决多智能体问题的常用框架,其中智能体维护自己的策略进行独立执行和优化,在训练阶段利用集中式信息协调智能体的更新方向。在这个框架下,现有的库将整个学习管道分为两个阶段:数据采样和模型优化。在模型优化阶段,数据采样阶段的所有数据都是可用的,使训练集中。然而,这样,选择合适的数据和使用这些数据来优化模型是在同一阶段耦合的。因此,扩展算法以适应其他任务模式(例如合作和竞争)变得更具挑战性,并且需要重新设计整个学习管道。
MARLlib 通过将原始分组数据流等效地分解为代理级分布式数据流来解决这个问题。本质上,在样本采集和优化过程中,它将多智能体训练中的每个智能体作为一个独立的单元,但在后处理阶段,智能体之间共享集中的信息(后处理是在模型优化之前处理采样数据的RLlib API;我们丰富它以适应不同的算法),以确保等价。在后处理中,代理与其他代理共享观察数据(从环境中采样的数据)和预测数据(策略或Q值所采取的操作)。所有代理都维护各自的数据缓冲区,其中存储了它们的经验和其他代理共享的必要信息。进入学习阶段后,agent之间不需要信息共享,可以独立进行自我优化。通过这种方式,我们将原始组合的数据流分发给代理,并将数据共享和优化完全解耦,从而允许相同的实现解决多种模式的任务。
如何实现解耦的呢?
在后处理阶段,处理采样数据,用代理级分布式数据流的方式。具体而言,所有代理都维护各自的数据缓冲区,其中存储了它们的经验和其他代理共享的必要信息。
此外,虽然所有基于ctde的算法通常共享相似的代理级数据流,但它们仍然具有独特的数据处理逻辑。受EPyMARL[26]的启发,我们进一步将算法分为独立学习、集中批评和价值分解三类,以实现模块共享和可扩展性。总结如下(精华!!!):
- 独立学习算法让智能体独立学习;
- 集中式评价算法利用共享信息对评价者进行优化,进而指导分散行为者的优化;
- 价值分解算法学习一个联合的价值函数,并将其分解成单个的价值函数,然后代理在执行过程中使用它来选择动作。
根据它们的算法特性,我们在后处理阶段实现了合适的数据共享策略,如下面的图2所示。
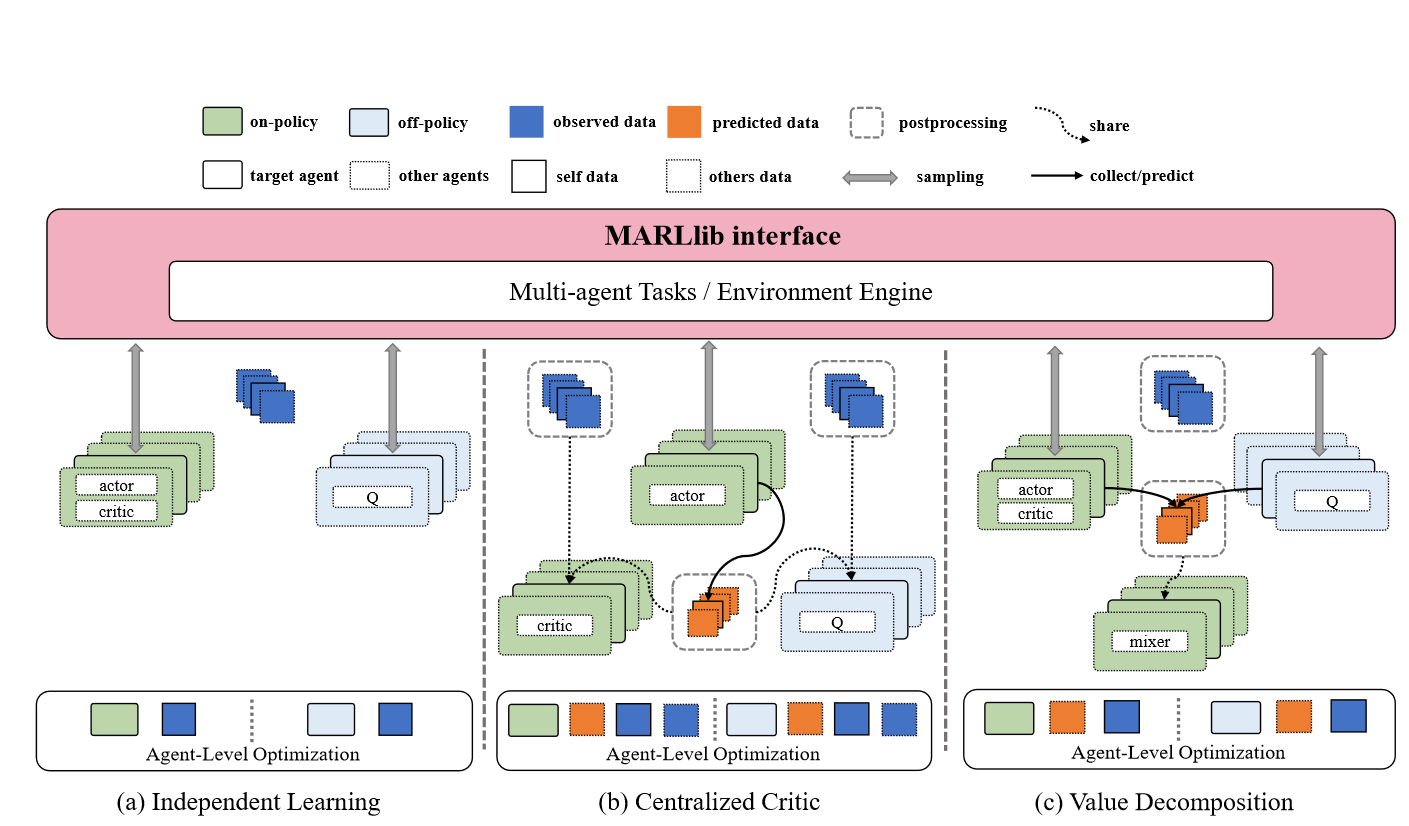
图2: MARLlib的代理级分布式数据流。
观察数据是指从环境中采样的数据,例如奖励或全局状态。
预测数据是指由代理生成的数据,例如Q值或选择的操作。
后处理是指数据共享过程。每个代理维护自己的学习管道,其中收集的数据用于优化代理本身的策略。
因此,数据流是代理级分布的。
数据流有独立学习、集中批判和价值分解三种类型[26],根据它们的中心信息利用方式进行了区分。
从单智能体的角度来看,独立学习算法(如IQL[36])本质上是分布式数据流,跳过了信息共享过程,如(a)所示。
对于集中式批评算法(如MAPPO[43]),在进入训练阶段之前,在后处理函数中收集并共享中心信息,包括观测数据和预测数据,以确保分布式数据流。如(b)所示。
在值分解类别(如FACMAC[27])中,所有agent的预测数据必须是共享的,而观测数据是可选的,这取决于算法的混合功能。相应的数据流如(c)所示。
3.2 Agent-environment 交互的通用接口
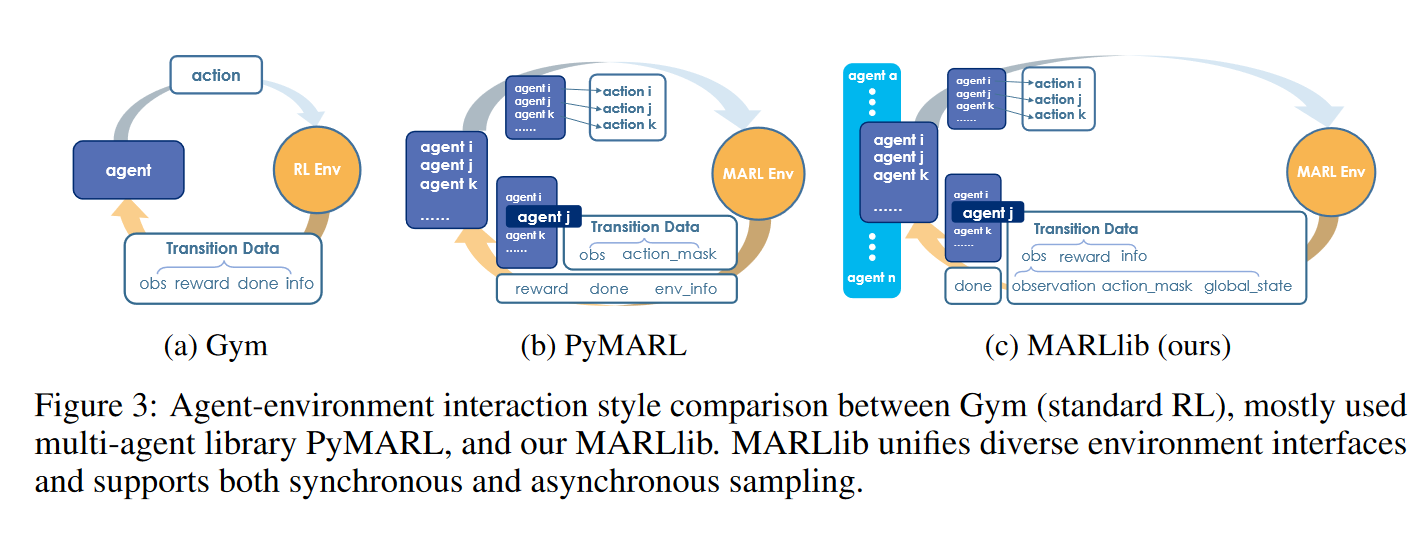
在许多RL库中,通常采用OpenAI Gym的观察、奖励、完成和信息接口。然而,这个标准化的接口不能简单地扩展到MARL。在MARL中,多个代理共存,每个代理都有自己的经验数据。额外的信息有时是可用的,比如动作掩码和全局状态。根据任务模式的不同,奖励可以是标量或字典。此外,代理可能无法与环境同步交互,这构成了另一个挑战。为了解决这些问题,MARLlib从两个方面统一了多代理接口。
首先,MARLlib统一了接口数据结构。
MARLlib提出了一个新的接口,遵循Gym API, obs, reward, done, info,在实践中兼容不同的多智能体任务设置,涵盖数据结构和任务模式。
如图(3)所示,在MARLlib中,从环境返回的观测值是一个带有三个键的字典:observation、action_mask、global_state。该设计满足大多数情况,并与RLlib的数据处理逻辑兼容。其他与观测相关的信息包含在info中。
Reward是一个以agent id为键的字典。为了适应合作任务,将标量团队奖励转换为字典结构,复制代理数次。Done是一个包含单个键"all"的字典,它仅在所有代理终止时为真。
其次,MARLlib支持同步和异步代理-环境交互
在MARLlib之前的现有MARL库,如PyMARL,不支持异步采样,主要关注同步情况。然而,异步代理-环境交互在Go和Hanabi等多代理任务中很常见。
由于RLlib灵活的数据收集机制,MARLlib支持同步和异步代理与环境的交互:使用代理id收集和存储数据。只有当我们接收到完成的终端信号时,才会返回所有数据供后续使用。这个采样过程如图3所示。
3.3 高效的策略映射
在多智能体场景下,适当的参数共享策略可以提高算法的性能。尽管它很重要,但大多数现有工作对共享模式的支持不足,而且实现是重复的——MAPPO基准重写了共享和分离设置的所有内容,而EPyMARL重复模型结构以同时支持这两种设置。
在MARLlib中,我们通过实现RLlib的策略映射API,支持共享(所有代理共享参数)、分离(没有代理共享参数)和组(同一组内的代理共享参数)参数共享。直观地说,它将代理的虚拟策略映射到实际维护、使用和优化的物理策略。映射到相同物理策略的智能体共享参数。由于策略映射对代理是透明的,因此它们实际上对数据进行采样并使用物理策略进行优化。因此,可以在不影响算法实现的情况下实现不同类型的参数共享。在实践中,我们只需要为每个环境维护一个包含所有相关信息的策略映射字典,以支持多种共享模式。通过修改策略映射API以满足需求,可以实现更自定义的参数共享策略。
怎么理解策略映射呢?
不同的智能体采取不同的策略,映射需要考虑某个智能体属于哪一类的人,能量有多大,从而给它分配合适的策略。
4. Python 包的调用举例
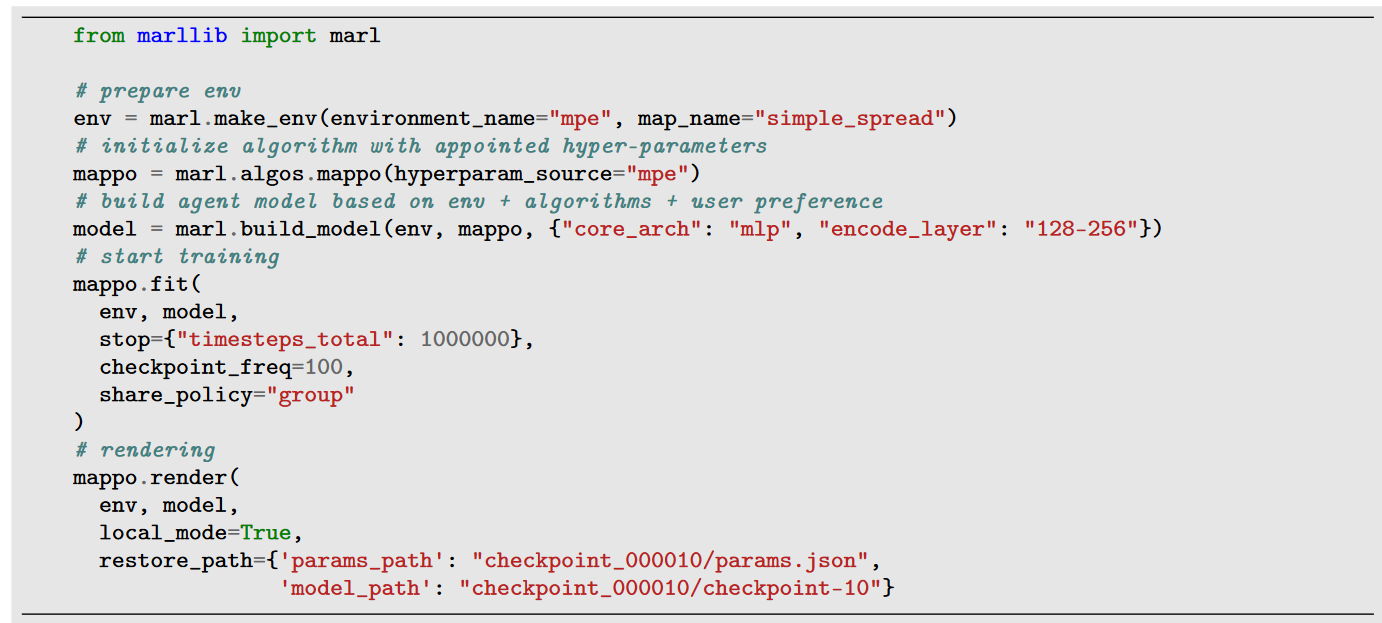
惊叹!实现一个多智能体的模型需要的代码如此的精简!
5. 管道控制
MARLlib通过允许用户自定义配置文件提供了一个简化的训练管道。这些文件是完全解耦的,位置如 图4 所示。
为了在修改配置时提供更大的灵活性,MARLlib支持三种优先级,从低到高依次列出:1)基于文件的配置,包括所有默认的*。yaml文件。2)基于api的自定义配置,允许用户指定自己的偏好,如{“core_arch”:“mlp”,“encode_layer”:“128-256”}。3)命令行参数,如$python mappo.py -algo_args.num_sgd_iter =6。
如果在多个级别上设置一个参数,则较高级别的配置优先于较低级别的配置。通过提供多个级别的配置,MARLlib允许用户定制他们的培训管道,以满足他们的特定需求,促进更高效和有效的训练过程。
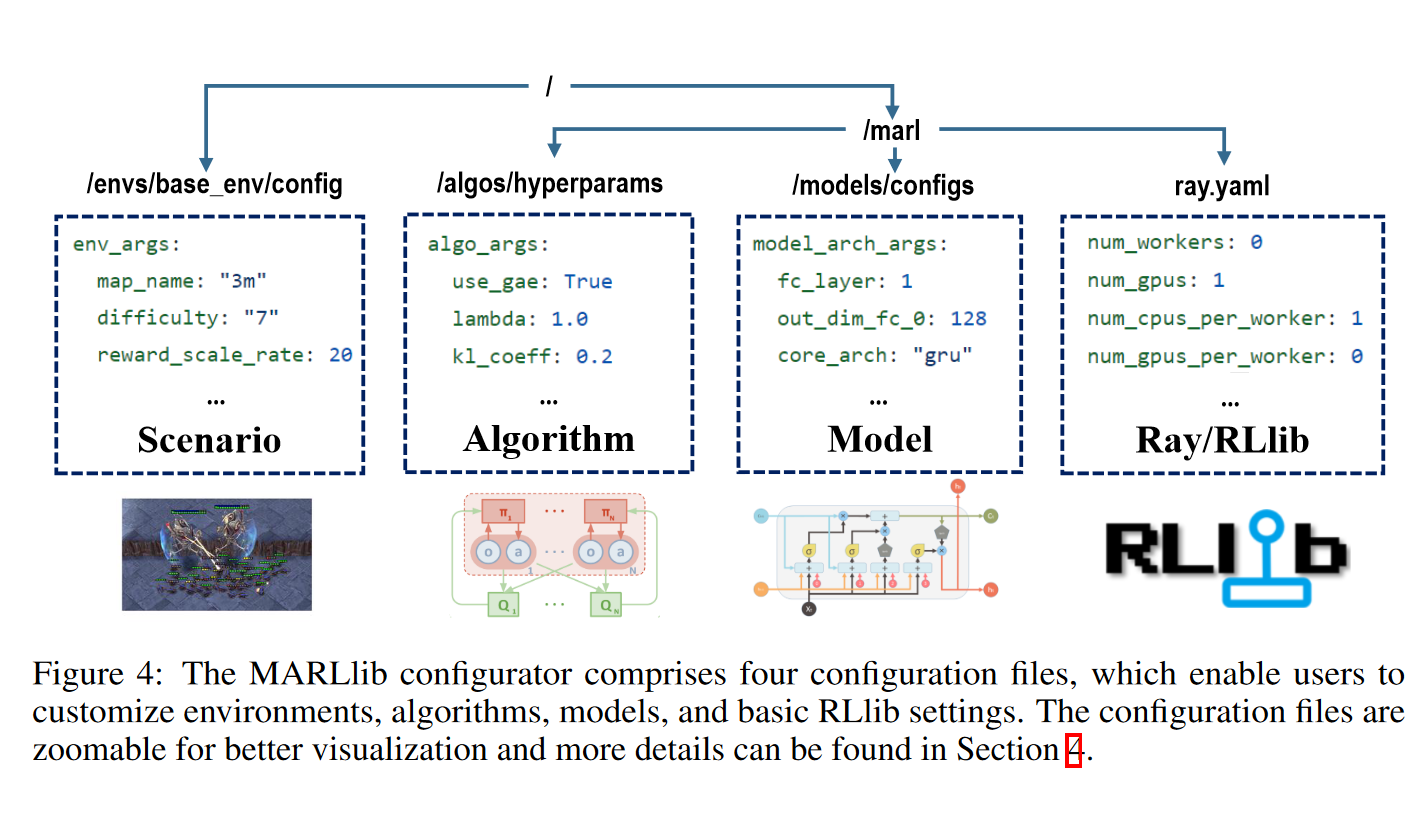
图4:MARLlib配置器包含四个配置文件,用户可以自定义环境、算法、模型和基本的RLlib设置。
6. 文档
文档分为了四个大块。
MARLlib Handbook, Navigate From RL to MARL, Algorithm Documentation, and Resources.
文档,项目链接如下:
https://github.com/Replicable-MARL/MARLlib
说明:
- 阴影标注了 top 2
- SMAC的环境下,和 EPyMARL 做了对比。
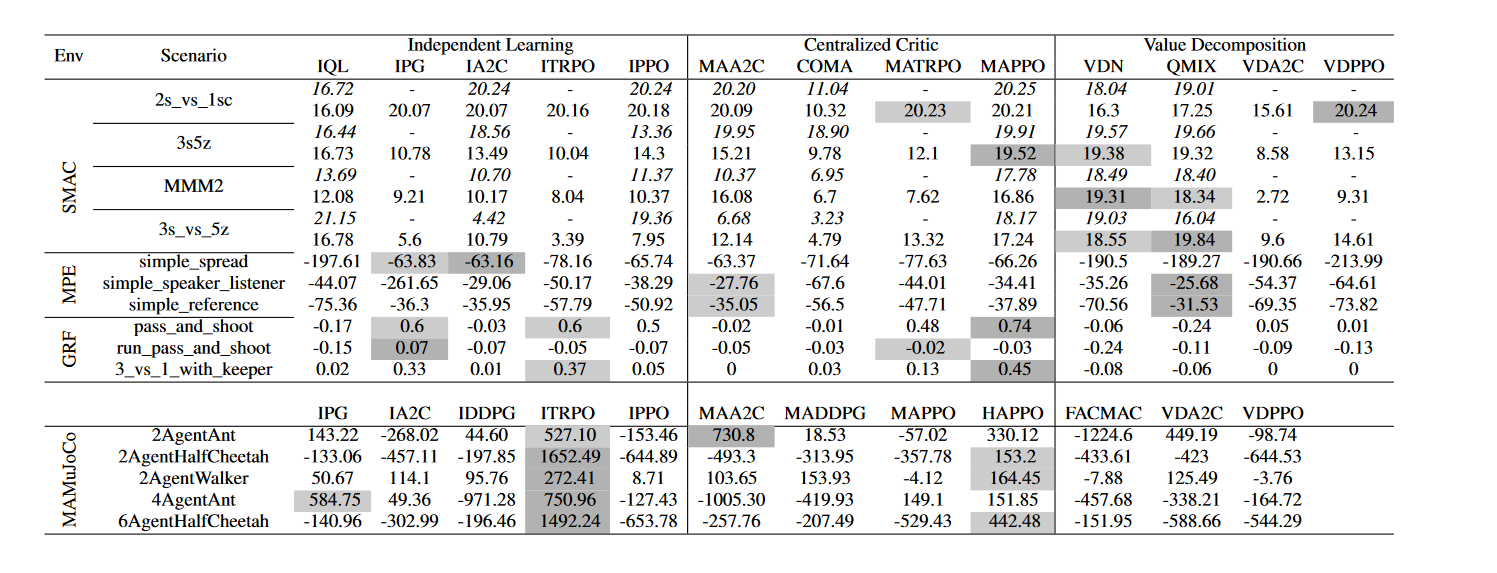
表 2 : 对于不同的合作任务,不同的算法的不同表现情况。
7. 实验
在本节中,我们评估了SMAC[33]、MPE[22]、GRF[19]、MAMuJoCo[27]和管理[46]等5个MARL测试平台23个任务上的17种算法,选择这些算法是因为它们在MARL研究中的受欢迎程度,以及它们在任务模式、观察形状、附加信息、动作空间、稀疏或密集奖励、同质或异构代理类型方面的多样性。我们报告了四种随机种子下实验的平均收益,总共有一千多个实验。实验结果如表2和图5所示。基于这些结果,我们证实了实施的质量,并提供了深刻的分析。
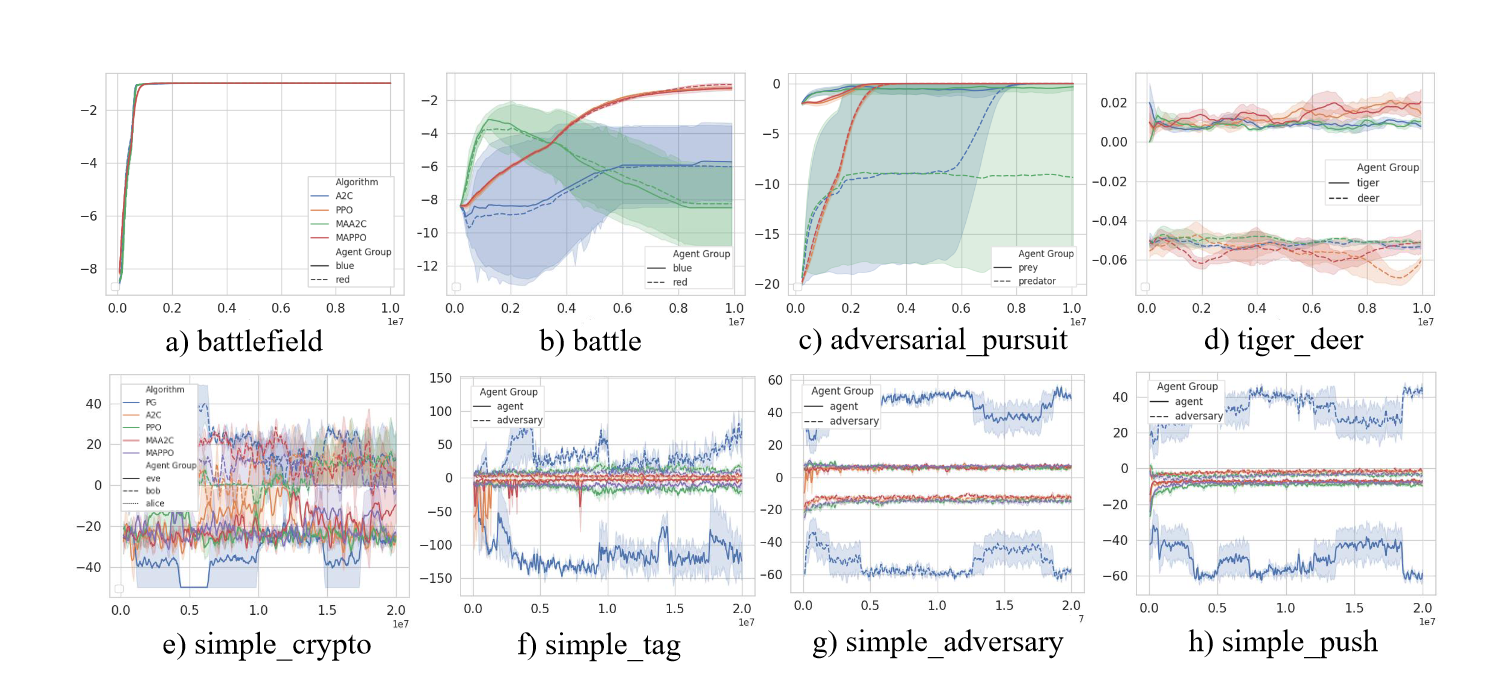
图5:在MAgent (a-d)和MPE (e-h)中8种混合场景(agent分组竞争)的收益曲线。不同风格的曲线代表不同的agent组。在学习过程中,竞争群体的收益曲线呈现动态平衡,平衡点取决于算法和任务。放大以获得更好的可视化。
7.1 实现的质量的分析
贡献1 收敛快速
为了证明MARLlib的正确性,我们在保持重要超参数不变的情况下,将MARLlib在SMAC上实现的性能与EPyMARL报告的性能进行了比较。EPyMARL的结果在策略上算法上消耗4000万步,在策略外算法上消耗400万步。MARLlib分别只消耗它们的一半,因为我们发现它足以使训练收敛。即使训练步骤更少,我们也能匹配EPyMARL报告的大部分性能,如表2所示。
贡献2 奖励高(return 高)
(注意,作者用百分比的方式掩盖自己对比实验的数量的少,哈哈哈)
对于所有可用于比较的性能对,MARLlib在63%的性能对上获得了相似的结果(总奖励差异小于1.0),在25%的性能对上获得了优异的结果,而在其余12%的性能对上出现了较差的结果。由于每种算法都表现出预期的性能、通用性和稳定性,因此我们不依赖于特定于任务的技巧。这些实验结果证实了实现的正确性。
贡献3 更多的算法实现
在这个表中,我们还首次报告了5种算法在SMAC和MPE上的性能,12种算法在GRF上的性能,10种算法在MAMuJoCo上的性能,供社区参考。
7.2 性能表现的分析
经验表明,在强壮的强化学习算法的基础上开发单智能体强化学习算法是明智的选择。例如,PPO主要用于单代理RL,因为它比 vanilla PG 和A2C具有更好的经验性能。这种优势影响了多智能体的性能——MAPPO和VDPPO在大多数情况下都超过了MAA2C和VDA2C。
另一个证实这一结论的证据是值迭代方法的鲁棒性。与策略梯度方法相比,基于值迭代的算法具有较低的超参数敏感性和更高的样本效率。多智能体版本的Q学习(如IQL、VDN和QMIX)也继承了这一优势,并在大多数场景(如SMAC和MPE)中显示出强大的性能。
启发:
1. 要使用值迭代的方法,鲁棒性好。
2. 单智能体的开发要使用比较强的RL算法。比如PPO就比A2C要好。
其他
表2中的算法根据它们在具有相似任务模式的各种协作任务上的性能进行分类。根据我们的分析,我们观察到某些类型的算法在特定任务上表现出更好的性能。例如,当不需要中心信息时,独立学习算法是有效的,而集中式批评算法更适合于学习多种但协调的行为。
相比之下,价值分解算法在大多数协作基准测试中占主导地位。对于具有多种行为的合作任务,MAPPO和 HAPPO已成为强有力的基线。有关这些算法在协作任务上的性能的更详细分析,请参阅附录B.1。
除了合作任务,我们还评估了非合作任务中的算法,特别是竞争和混合任务。然而,在这些任务中的基准测试算法提出了一些挑战,因为代理可以表现出合作和竞争行为。我们将在附录B.2中更详细地讨论这些挑战。
附录
B.1 合作任务上算法的有效性的分析
当中心信息不是必需的时候,独立学习是有效的。虽然智能体之间的协调对于MARL算法至关重要,而独立学习在理论上是次优的,但已有的工作[10]指出,独立学习可以超越其他算法。在表2中,我们发现在simple_spread和pass_and_shoot等场景中,独立学习算法比集中式批评算法更好,在这些场景中,智能体的行为类似,中心信息对于策略优化是不必要的。同样,如果没有全局视图,独立学习也无法解决诸如simple_speaker_listener和simple_reference等协调任务。
集中式批评更擅长学习多样但协调一致的行为。 在多智能体任务中,智能体可以扮演不同的角色,并且它们的行为应该是特定于角色的[15,40]。集中式批评适合这些任务,因为局部观察和全局信息都得到了很好的利用。MAPPO就是一个很好的例子,它是集中式批评的代表性算法,在SMAC、MPE和GRF中的大多数协作任务上都表现良好。HAPPO是MAPPO的异构版本,在MAMuJoCo中实现了健壮的性能。MAPPO和HAPPO是具有不同行为的协作任务的强基线。
除了两种特定的情况外,价值分解在流行的合作基准中占主导地位。第一种情况是持续控制。众所周知的VDN、QMIX 等值分解算法不适合连续控制任务,VDA2C、VDPPO等算法也较差。第二种情况是具有稀疏奖励函数(如GRF)的长期规划问题。从经验上看,价值分解方法的性能明显差于ITRPO和MAPPO等其他类别的算法。我们确定了两个主要原因:1)VDN和QMIX使用的值迭代更倾向于密集的奖励函数;2)the mixer 几乎不能分解一个接近于零的Q函数。除了这两种情况外,值分解算法以最佳的样本效率实现了鲁棒性。
B.2 Algorithms Evaluation in Mixed Scenarios
在混合任务中对算法进行基准测试具有挑战性。混合任务中的智能体表现得既合作(与队友合作)又竞争(与对手竞争)。由于策略总是处于动态平衡状态,因此很难根据获得的奖励来证明哪种算法更好:当一个策略优化得更好时,其对手策略的性能就会下降。
在混合任务模式下,算法可以通过所有不同策略的奖励总和来评估。一个政策优化迫使竞争政策获得更高的回报。总奖励越高,算法越好(图5[a-d])。虽然不同策略的奖励总和通常用于评估混合任务模式下的算法,但需要注意的是,这并不是评估性能的唯一方法。事实上,这条规则也有例外(图5)。例如,某些任务可能具有恒定的总奖励值和策略,这些策略可以快速达到竞争策略之间镜像学习曲线的平衡。在这些情况下,评估算法的公平和通用标准仍然是一个活跃的研究领域。
Mixed Scenarios 的算法(又有敌人又有队友的情况),似乎并不适合我们的算力分配任务。