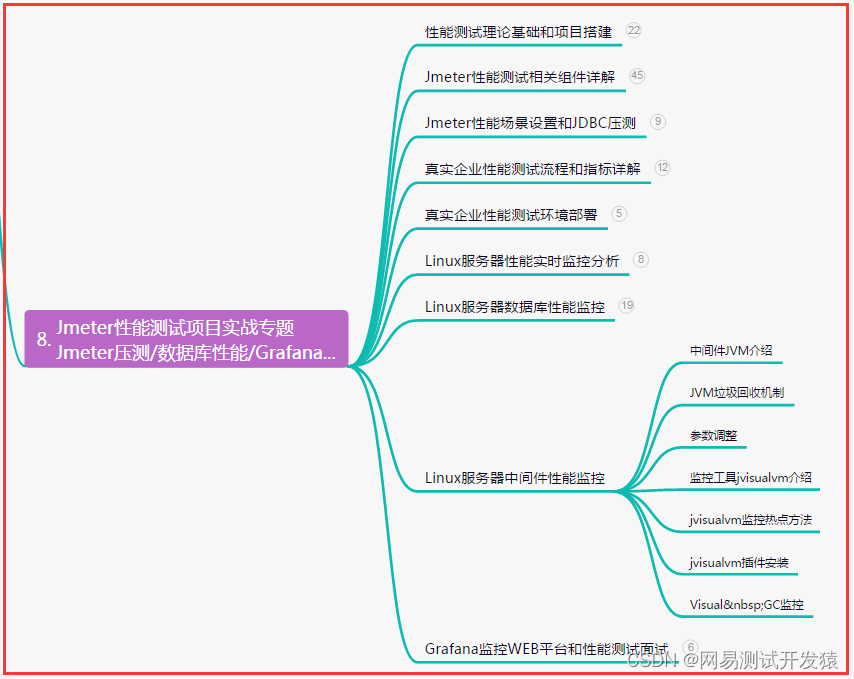
性能机制
应用端

应用端-选择节点
-
对于复制集读操作,选择哪个节点是由readPreference决定的
- primary/primaryPreferred
- secondary/secondaryPreferred
- nearest
-
如果不希望一个远距离节点被选择
- 将它设置为隐藏节点
- 通过标签(Tag)控制可选的节点
- 使用 nearest 方式;
应用端-排队等待
-
排队等待连接是如何发生
- 总连接数大于允许的最大连接数maxPoolSize
-
如何解决
- 加大最大连接数(不一定有用)
- 优化查询性能
应用端-连接与认证
- 如果一个请求需要等待创建新连接和进行认证,相比直接从连接池获取连接,它将 耗费更长时间
- 可能解决方案
- 设置 minPoolSize(最小连接数)一次性创建足够的连接
- 避免突发的大量请求
数据库端

数据库端-排队等待
- ticket 不足引起的排队等待,问题往往不在 ticket 本身,而在于为什么正在执行
的操作会长时间占用 ticket - 解决
- 优化 CRUD 性能可以减少 ticket 占用时间
- zlib 压缩方式也可能引起 ticket 不足,因为 zlib 算法本身在进行压缩、解压时需要的时 间比较长,从而造成长时间的 ticket 占用
数据库端-执行请求(读)
-
- 不能命中索引的搜索和内存排序是导致性能问题的最主要原因

数据库端-执行请求(写)
-
-
- 磁盘速度必须比写入速度要快才能保持缓存水位


数据库端-合并结果
-
- 如果顺序不重要则不要排序、
- 尽可能使用带片键的查询条件以减少参与查询的分片数

网络的考量

性能瓶颈总结

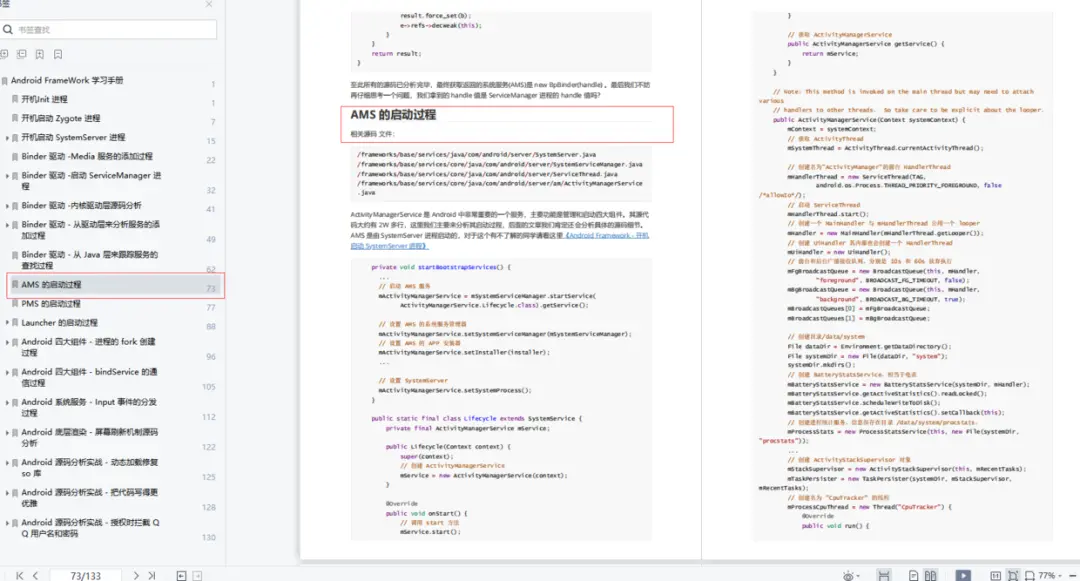
性能排查工具
mongostat
- mongostat: 用于了解 MongoDB 运行状态的工具
-

mongotop
- mongotop: 用于了解集合压力状态的工具
-

mongod 日志
- 日志中会记录执行超过 100ms 的查询及其执行计划
- 参考
mtools
- 常用指令:
- mplotqueries 日志文件:将所有慢查询
通过图表形式展现 - mloginfo --queries 日志文件:总结出
所有慢查询的模式和出现次数、消耗时
间等
- mplotqueries 日志文件:将所有慢查询
- https://github.com/rueckstiess/mto
ols








![P4381 [IOI2008] Island (求基环树直径)](https://img-blog.csdnimg.cn/9bad0e782a124e44921beff6fbc798b8.jpeg#pic_center)