retrieval+LM
https://acl2023-retrieval-lm.github.io/
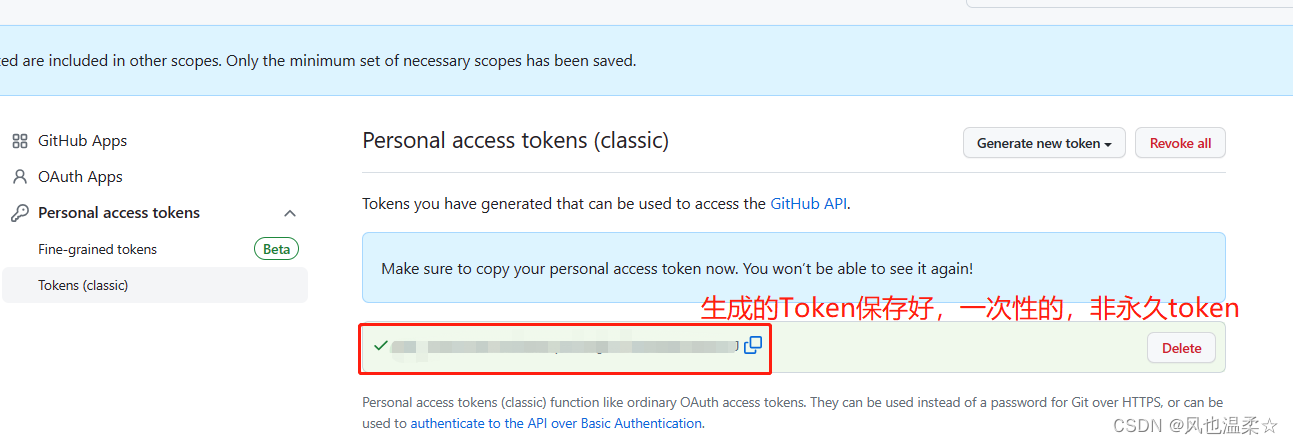
在input层利用retrieval信息
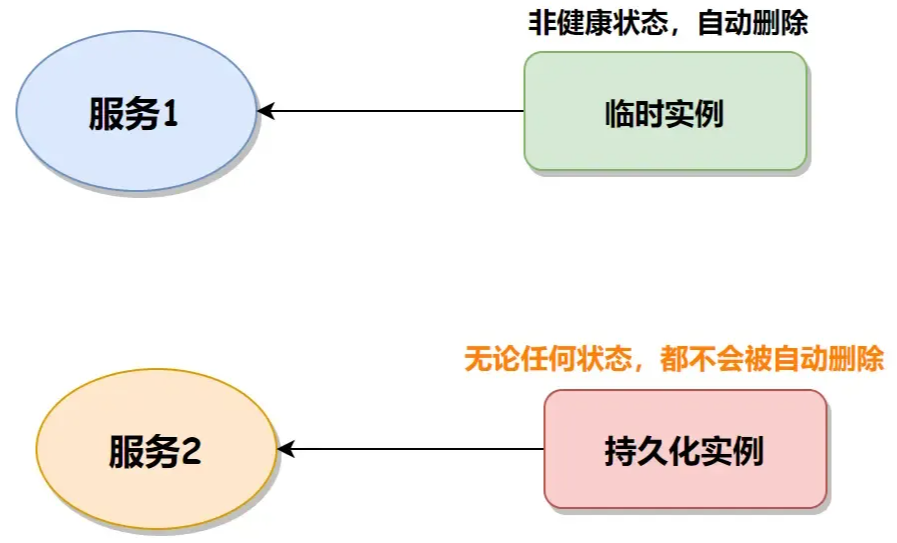
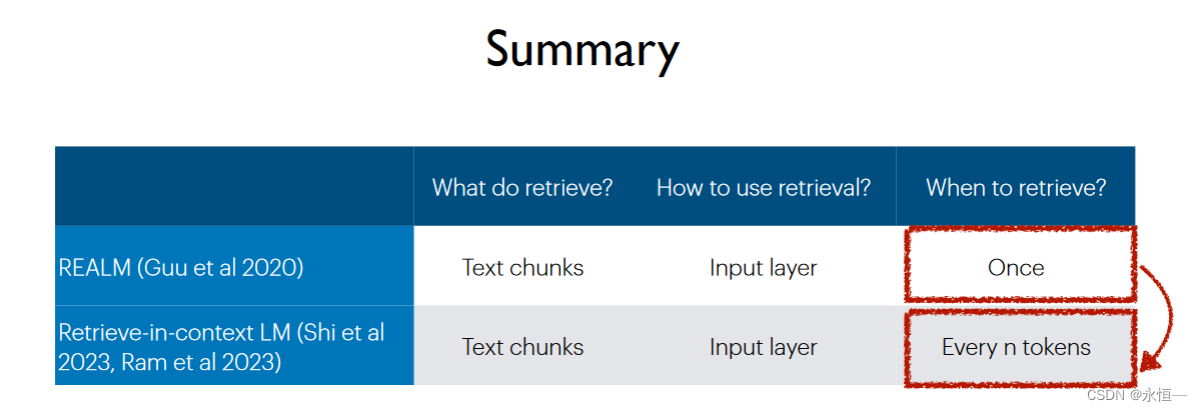 主要是通过通过相似度计算或者重要性计算在datasets中得到与询问x最相关的k个document,讲文档放在询问x前面组成新的LM的输入,获取额外知识以回答问题。
主要是通过通过相似度计算或者重要性计算在datasets中得到与询问x最相关的k个document,讲文档放在询问x前面组成新的LM的输入,获取额外知识以回答问题。
在intermediate layers层利用retrieval信息
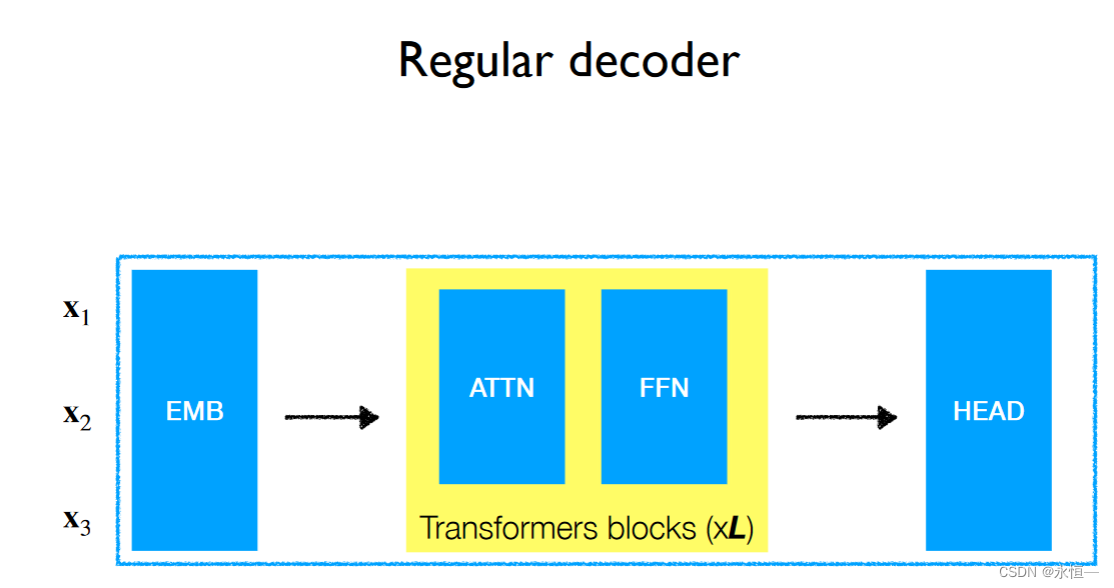
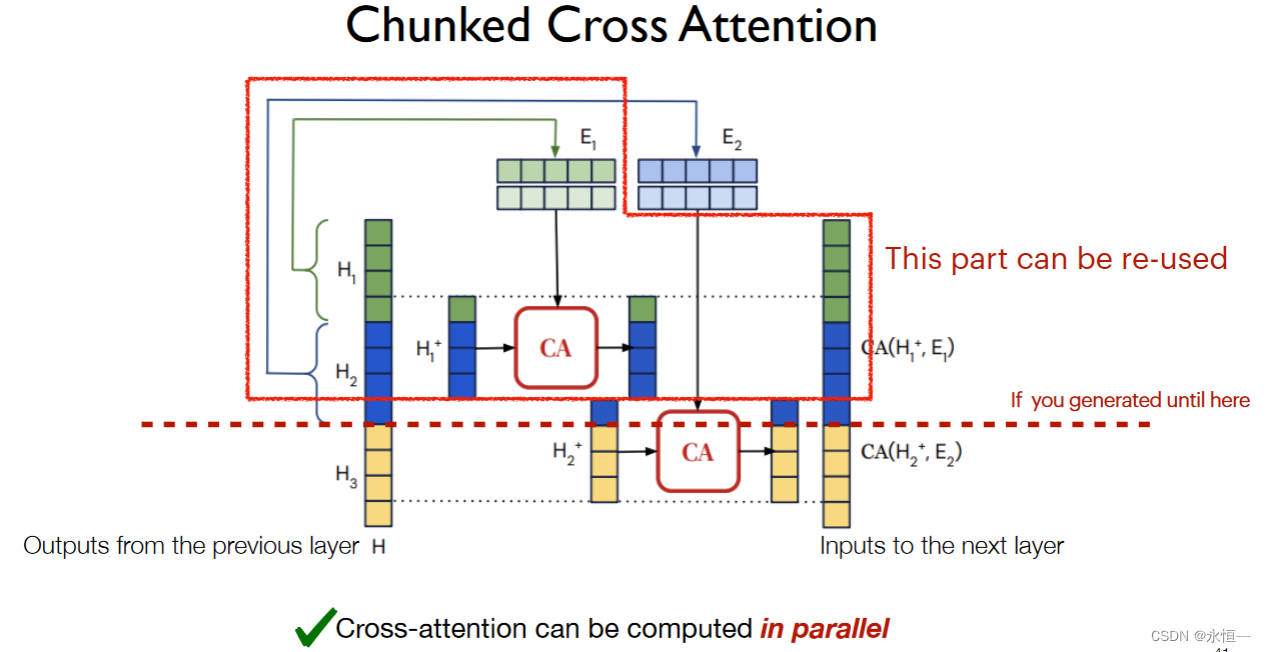
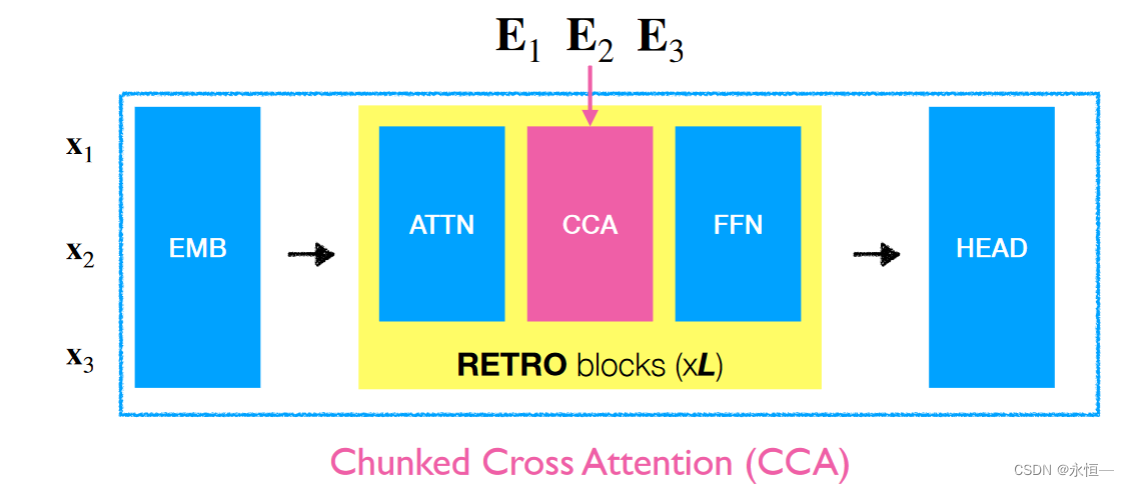 主要是将输入x截成多个小段xi,然后转化成对应emb向量,在模型中加入一层对上一层输出H和emb向量xi进行融合作为下一层新的输入,融入外部知识。
主要是将输入x截成多个小段xi,然后转化成对应emb向量,在模型中加入一层对上一层输出H和emb向量xi进行融合作为下一层新的输入,融入外部知识。
在output层使用retrieval信息
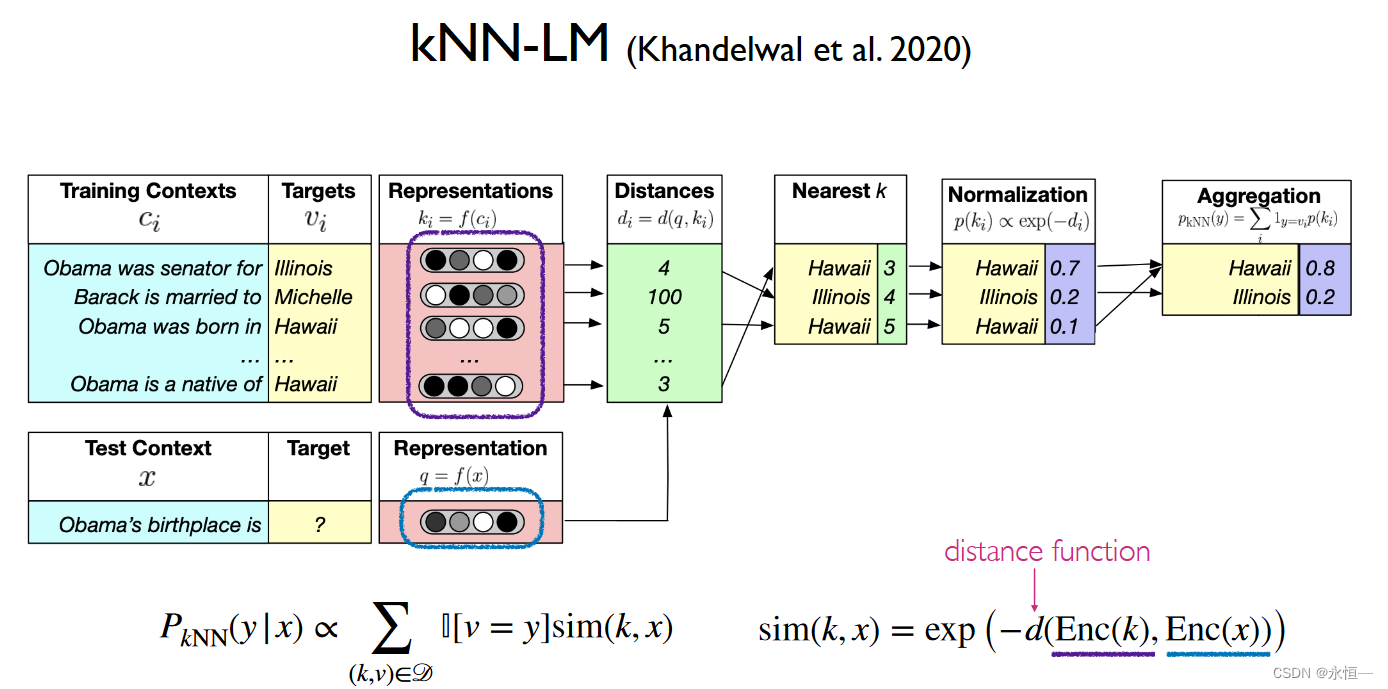
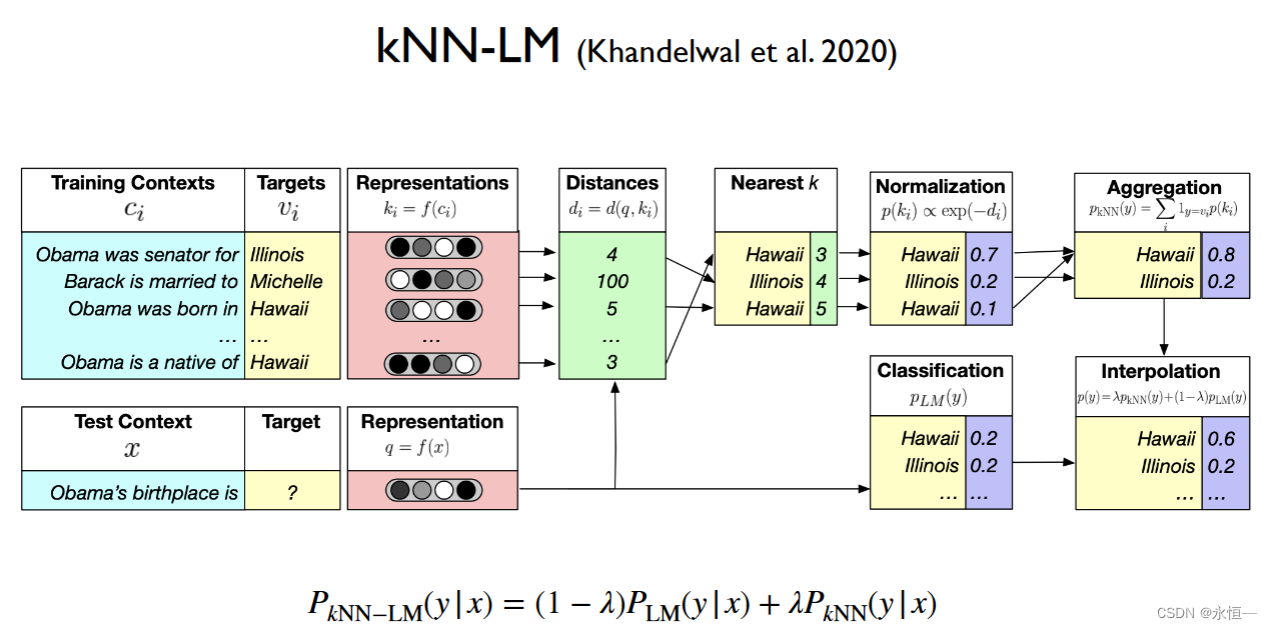 通过学习参数调节LM的输出概率和通过datasets得到与x相似度最近的句子(可以把句子滑动窗口切割)的概率分布,两者组合构成新的输出概率分布,以此来选择下一个字。 通过计算xi对应向量与datasets中ci的向量距离di来算exp获得概率输出。
通过学习参数调节LM的输出概率和通过datasets得到与x相似度最近的句子(可以把句子滑动窗口切割)的概率分布,两者组合构成新的输出概率分布,以此来选择下一个字。 通过计算xi对应向量与datasets中ci的向量距离di来算exp获得概率输出。
adaptive retrieval for efficiency
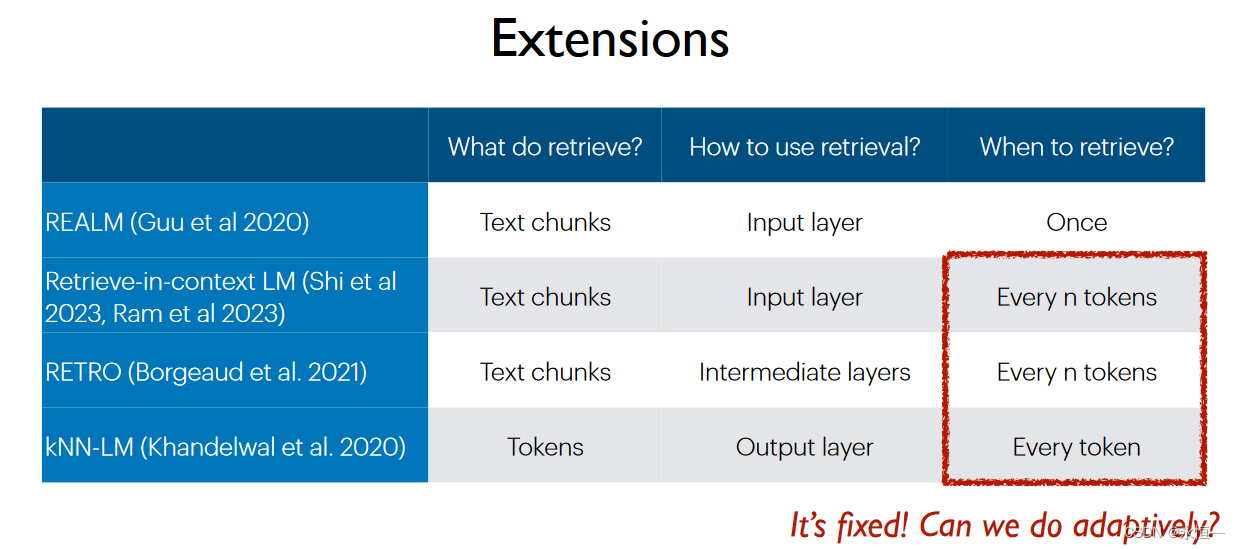
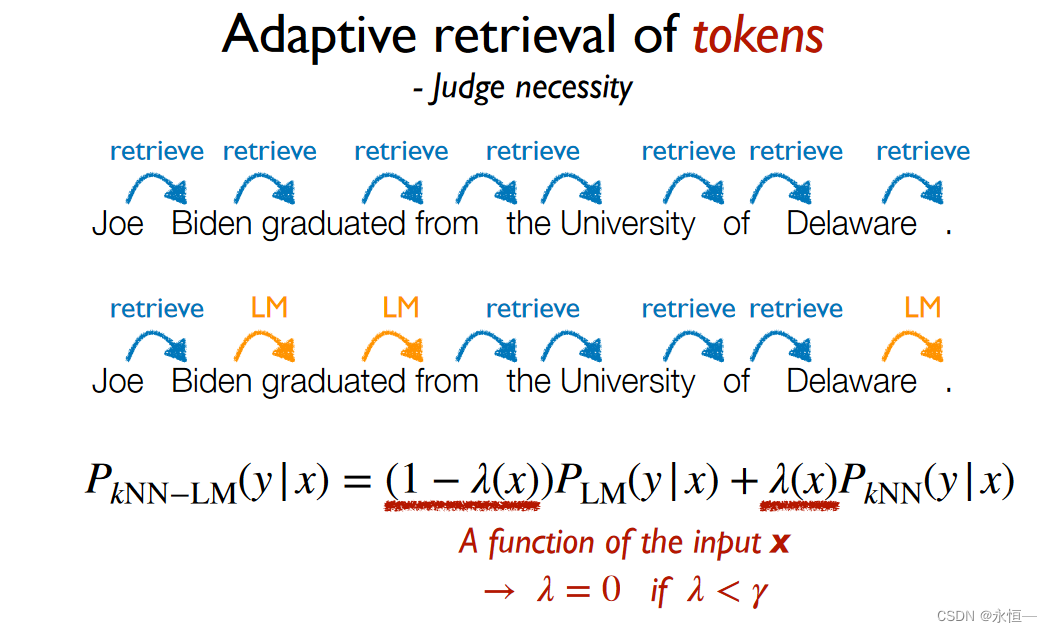
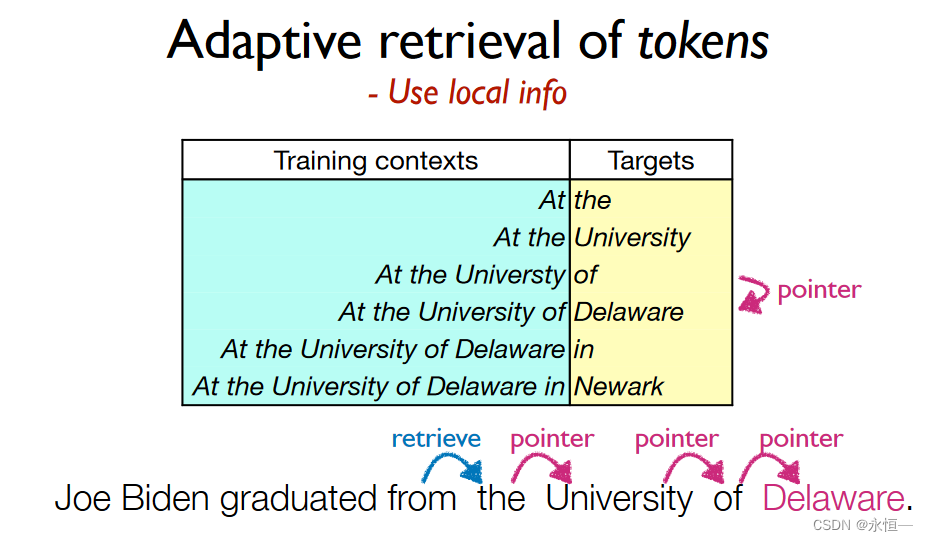
adaptive选择是retrieve继续pointer还是LM
对于retrieve的长度也可以adaptive,比如按照实体来划分,借助实体链接来替换Token的embdding